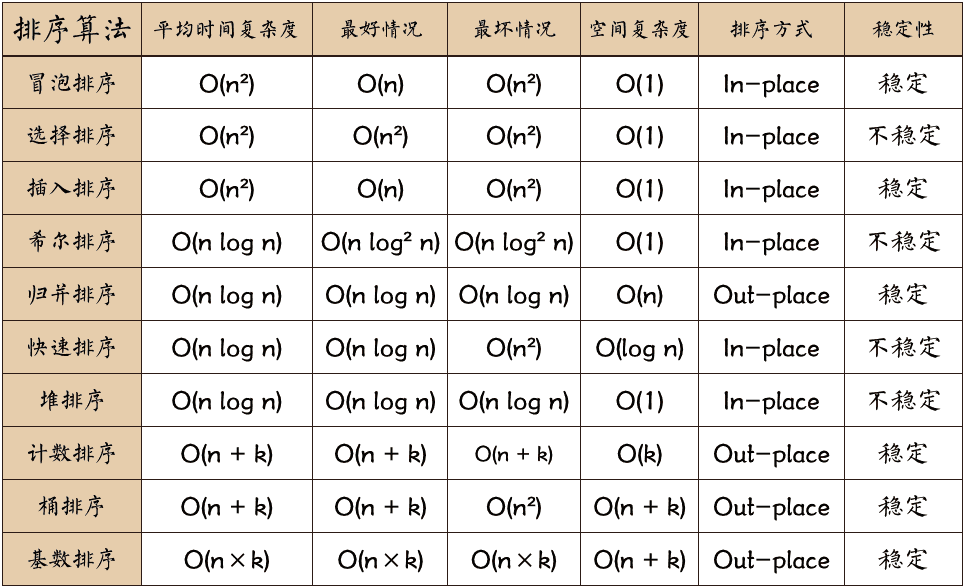
稳定排序:对于相等的元素,在排序后,原来靠前的元素依然靠前
相等元素的相对位置没有发生改变。(相对位置,左边右边)
1. 冒泡排序
描述:首先从数组的第一个元素开始到数组最后一个元素为止,对数组中相邻的两个元素进行比较,如果左边的元素比右边的元素大,则交换两个元素在数组中的位置。这样遍历一遍后数组最右端就是所有元素的最大值。接着对数组除最右端的n-1个元素进行同样的操作,以此类推,知道整个数组有序排列。算法时间复杂度为O(n^2)
思路:
- 从左到右遍历
- 比较相邻元素大小,交换位置,使得最大值到最右边
- 对剩下元素循环遍历
优化:
- 外层优化:左端未排序部分遍历一遍后如果没有swap过(bool),则可以提前退出循环。因为左侧可以确定已排序,而右侧本就是排序好的,整个序列排序完成
- 内层优化:对于左侧序列,最后swap的位置可能不在后边,可能在中间,那么最后一次swap之后的位置都可以确定已排序,所以下一次遍历可以以这个位置为遍历终点。
/* 冒泡排序 */void BubbleSort(int arr[], int length){for (int i = 0; i < length; i++){for (int j = 0; j < length - i - 1; j++){if (arr[j] > arr[j + 1]){int temp;temp = arr[j + 1];arr[j + 1] = arr[j];arr[j] = temp;}}}}// 优化void bubble_sort(std::vector<int>& vec, const int & size) {int last_swap_pos = size;int bubble_range = size;for (int i = 0; i != size; ++i) {bool have_swap = false;for (int j = i + 1; j != bubble_range - 1; ++j) {if (vec[j] > vec[j+1]) {std::swap(vec[j], vec[j + 1]);last_swap_pos = j + 1;}}bubble_range = last_swap_pos;if (have_swap == false) {break;}}}
2. 选择排序
描述:遍历数组,找到最小的元素,与第一个元素交换。对除最左侧的元素继续遍历,循环操作。
优化:
在遍历过程中,同时查找最大值和最小值,记录它们的位置,然后放到左边和右边。
假设左端和右端为最值,在中间部分遍历,并交换;
void select_sort(std::vector<int>& vec) {int min_index = 0;for (int i = 0; i != vec.size() - 1; ++i) {min_index = i;for (int j = i + 1; j != vec.size(); ++j) {if (vec[min_index] > vec[j]) {min_index = j;}}if (min_index != i) {std::swap(vec[i], vec[min_index]);}}}// 优化void select_sort(std::vector<int>& vec) {int left = 0, right = size - 1;while (left < right) {int min_index = left, max_index = right;for (int i = left + 1; i != right; ++i) {if (vec[min_index] > vec[i]) {min_index = i;}if (vec[max_index] < vec[i]) {max_index = i;}}if (min_index != left) {std::swap(vec[left], vec[min_index]);}if (max_index != right) {std::swap(vec[max_index], vec[right]);}++left;--right;}}
3. 插入排序
描述:基本思想是将无序序列插入到有序序列中。现将数组分为有序序列(第一个数字)和无序序列(剩余数字)。将无序序列的第一个数字向左进行比较,如果比他小,继续向左,如果比他大,插入右边。以此类推。
关键:
- 从左向右遍历i,设置待插值位置pos
- 将待插值从右向左比较
void insert_sort(std::vector<int>& vec, const int & size) {for (int i = 0; i != size - 1; ++i) {// pose 是待插入的值,从i+1开始int pose = i + 1;int temp = vec[pose];for (int j = pose - 1; j >= 0; --j) {if (vec[j] > temp) {vec[j + 1] = vec[j]; // 如果待插值比它小,则小值右移--pose; // pose左移} else {break; // 如果待插值比他大,则跳出循环并插入}}vec[pose] = temp; // 如果待插值比他大,则插入}}
4. 希尔排序
描述:希尔排序是插入排序的改进版。先·将待排序的序列分割成(等距离)若干子序列分别进行插入排序,待到整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。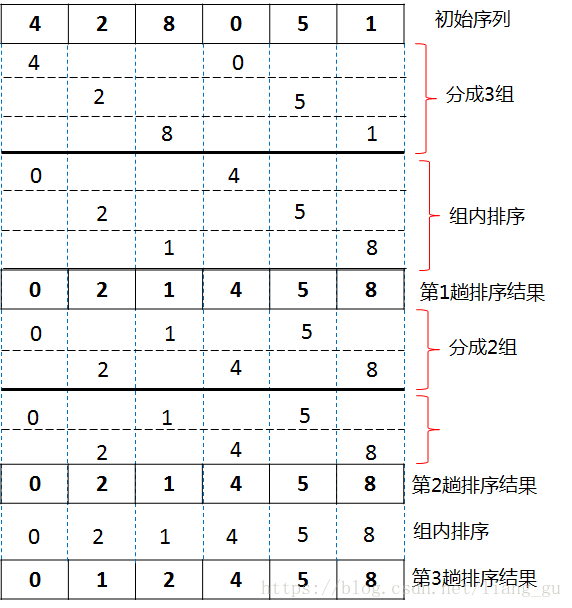
void shell_sort(std::vector<int>& vec, const int & size) {int gap = size / 2;while (gap >= 1) {for (int i = 0; i < size; ++i) {int pos = i + gap;if (pos >= size) break;int temp = vec[pos];for (int j = pos - gap; j >= 0; j -= gap) {if (vec[j] > temp) {vec[j + gap] = vec[j];pos -= gap;} else {break;}}vec[pos] = temp;}gap /= 2;}}
5. 归并排序
描述:归并排序是建立在归并操作上的一种O(nlogn)级别的算法。该算法是分而治之(Divide and Conquer)的一个典型应用。基本思想是将已经有序的子序列合并,得到完全有序的序列,然后再次合并,以此类推。
不管是自顶向下还是自底向上,都有一个基础函数merge归并操作。设置三个遍历点ijk并且创建保存当前序列的数组副本。
5.1 自顶向下归并法(递归)
所谓自顶向下就是从一个完整序列开始,不断的将序列分成两部分。当分裂的序列内数字≤1时,停止分裂,开始合并,逐个合并,最后得到一个完整的序列。
关键点:
- 在分裂时设置两个边界和一个中点。一个是left左边界,为闭区间,另一个是right右边界,为开区间,中点为mid。left和right是表示当前序列在总的序列的所在范围,mid用于将序列分为两半
- 在合并时设置三个遍历点i,j,k。i和j分别用于指向一半的序列,而k用于指向保存当前序列的副本。
优化方法:
- 在序列较短时用插入排序。因为插入排序对于有序数组很友好,对完全有序的数组排序复杂度是O(N),而越短的序列月可能有序。
- 在归并操作之前判断当前序列是否完全有序。如果左半边序列的最后一个数字≤右半边的第一个数字,则代表当前序列已经完全有序,无序合并,继续下一步操作。
void merge(std::vector<int>& vec, const int& l, const int& mid, const int& r) {
std::vector<int> aux(r - l, 0);
for (int i = l; i != r; ++i) {
aux[i - l] = vec[i];
}
int i = l, j = mid;
for (int k = l; k != r; ++k) {
if (i >= mid) {
vec[k] = aux[j - l];
++j;
} else if (j >= r) {
vec[k] = aux[i - l];
++i;
} else if (aux[i - l] <= aux[j - l]) {
vec[k] = aux[i - l];
++i;
} else {
vec[k] = aux[j - l];
++j;
}
}
}
// 插入排序对于近乎有序的数组速度特别快,插入排序最快的情况是O(n)即完全有序
// 而当序列越小,有序的可能性就越大,所以可以在归并的判断条件中,如果序列长度
// 小于某个定值,就使用插入排序,而后才使用归并排序
void merge_sort(std::vector<int>& vec, const int& l, const int& r) {
// 左闭右开
// 如果需要合并的序列,左边界大于等于右边界,则证明序列个数为0,不需要合并
if (l >= r - 1) {
return;
}
// 在小序列中使用插入排序
// if (r - l <= 16) {
// insert_sort(vec, l, r);
// }
// 防止两个int相加超过int的范围
long temp = l + r;
int mid = static_cast<int>(temp / 2);
merge_sort(vec, l, mid);
merge_sort(vec, mid, r);
// 因为是已经假设左半序列有序,右半序列有序,那么如果左边的最后一个数字比右边小
// 则没有必要进行merge操作浪费时间。这个优化对于近乎有序的序列有很大的提升效果
if (vec[mid - 1] > vec[mid]) {
merge(vec, l, mid, r);
}
}
5.2 自底向上归并法(非递归)
描述:所谓自底向上,就是从小序列开始(1个数字),然后归并,不断向上归并,最终得到完整的排序序列。
关键点:
- 设置stride,表示最短序列的长度。而后stride = stride + stride
- 设置遍历点i。使得整个序列分成了size / (stride + stride)个
- 对分好的序列进行归并。
- 要注意边界问题。保证mid在序列范围内i + stride < size。右边界不超范围std::min(i + stride + stride, size)
6. 快速排序
描述:通过一趟排序将序列分割为两个部分,一半≤比较值,另一半≥比较值。换句话说就是将对序列进行分割,然后将比较值插入到合适的位置,这个位置就是比较值最终的位置。然后接着对这些序列继续分割。
问题:这样不断的分割的方法用到了递归,由于比较值的选择问题,很可能序列会被分割成不均衡的两部分,使得算法复杂度逼近与O(n^2),比如当序列近乎有序的时候,序列中比较值重复多次的情况,都会导致分割不均衡。解决方法:① 随机选择比较值(在序列范围内随机与最左值swap);② 双路快排;③ 三路快排。
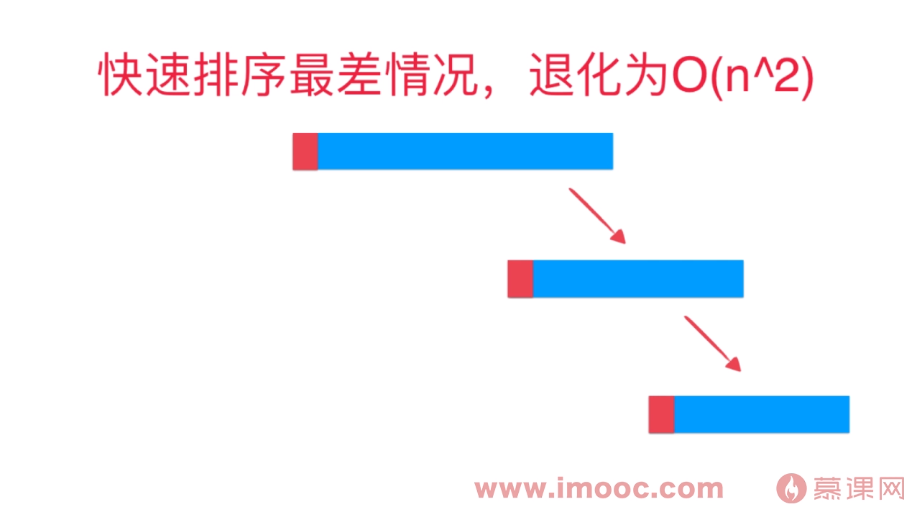
6.1 单路快排
关键点:
- 设置边界值left和right,左闭右开;
- 设置比较值,可以设置为vec[left];
- 设置遍历点i和分割点j = left。
- 在partition的过程中,i从left + 1开始遍历,如果值比它大,则值维持不动(遍历过的值比比较值大所以在分割点右边)。如果比他小,则使之前那些比他大的数字vec[j + 1]swap到vec[i]这个地方,然后++j。这个过程是保证小于比较值的数,在分割点j的左边,大于比较值的数在分割点右边。遍历完之后,再讲比较值和分割点处的值交换。
- 想想一个例子:[4, 5, 3, 2, 1],这个5要经过多次swap最后变成[4, 3, 2, 1, 5],再将比较值和分割点处的值交换[1, 3, 2, 4, 5]
int partition(std::vector<int>& vec, const int& l, const int& r) {
// 随机选择比较值,使得最终复杂度的期望为O(nlogn)
// std::srand(std::time(0));
int random_index = std::rand() % (r - l) + l;
// std::cout << l << " " << r << " " << test <<std::endl;
std::swap(vec[l], vec[random_index]);
int j = l;
int val = vec[l];
for (int i = l + 1; i != r; ++i) {
if (vec[i] < val) {
std::swap(vec[++j], vec[i]);
}
}
std::swap(vec[l], vec[j]);
return j + 1;
}
// 左闭右开
void quick_sort(std::vector<int>& vec, const int& l, const int& r) {
if (l >= r - 1) {
return;
}
// std::srand(std::time(0));
int p = partition(vec, l, r);
quick_sort(vec, l, p);
quick_sort(vec, p, r);
}
6.2 双路快排
描述:利用左右遍历,将=val的值均分到左右序列当中,可以更均衡的分割序列。
关键点:
- 设置边界值left和right,左闭右开;
- 设置比较值,可以设置为vec[left];
- 设置左遍历点le和右遍历点re。
- 左遍历点往右遍历,直到遇到一个≥比较值的地方停下。右遍历点往左遍历,直到遇到一个≤比较值的地方。交换le和re的元素。++le —re。
- le指向左序列还未排序的位置,re指向右序列还未排序的位置。当le > re的时候,re实际上指向左序列的最后一个元素,所以此时应该swap(vec[left], vec[re])
- 返回re + 1,比较值插入位置的右开边界
int partition2(std::vector<int>& vec, const int& l, const int& r) {
// int random_index = std::rand() % (r - l) + l;
// std::swap(vec[l], vec[random_index]);
int val = vec[l];
// le指向左序列还未排序的位置
// re指向右序列还未排序的位置
int le = l + 1, re = r - 1;
while (true) {
while (le < r && vec[le] < val) ++le; //跳出循环时le指向>=val的元素
while (re > l && vec[re] > val) --re; //跳出循环时re指向<=val的元素
if (le > re) break;
std::swap(vec[le], vec[re]);
++le, --re;
}
std::swap(vec[l], vec[re]);
return re + 1;
}
void quick_sort_2(std::vector<int>& vec, const int& l, const int& r) {
if (l >= r - 1) {
return;
}
int p = partition2(vec, l, r);
quick_sort_2(vec, l, p);
quick_sort_2(vec, p, r);
}
6.3 三路快排
描述:三路的意思是将数组通过partition分为3份。左边是小于比较值,中间等于,右边大于比较值。下次递归只从小于的部分或者大于的部分继续partition即可。所以partition返回的是=比较值的左右边界。
描述:实际上只有一个左遍历点,额外设置两个定位点lt和gt,lt指向>val的第一个位置也就是=val序列的第一个位置,gt指向>val的第一个位置也就是=val序列的后一个位置右开。而且不存在插入一说了,一旦发现=val的地方,就让左遍历点和lt交换位置,保证lt一直指向遍历过的元素中第一个=val的地方。下一次分割只要从left~lt和gt~right继续分割即可,省掉了=val的部分,对于有大量相等元素的序列速度特别快。
关键点:
- 设置边界值left和right,左闭右开;
- 设置比较值,可以设置为vec[left];
- 设置定位点lt和gt,less than和greater than。分别指向第一个满足要求的下一个位置。
- 设置左遍历点le。
- 遍历点从left往右遍历,如果小于比较值,和lt交换位置;
- lt指向左序列还未排序的位置,也就是=val的第一个位置,所以初始值为left
- gt指向右序列已经排序的第一个位置。当le = gt的时候,数组已经分类完全;
- 返回re + 1,比较值插入位置的右开边界
std::vector<int> partition3(std::vector<int>& vec, const int& l, const int& r) {
// int random_index = std::rand() % (r - l) + l;
// std::swap(vec[l], vec[random_index]);
int val = vec[l];
int i = l + 1;
int lt = l, gt = r;
// le是左遍历点,指向左序列还未排序的位置
// lt指向=val的第一个位置,gt指向>val的第一个位置
while (i < gt) {
if (vec[i] < val) {
std::swap(vec[i], vec[lt]);
++i, ++lt;
} else if (vec[le] > val) {
std::swap(vec[i], vec[--gt]);
} else {
++i;
}
}
return std::vector<int>({lt, gt});
}
void quick_sort_3(std::vector<int>& vec, const int& l, const int& r) {
if (l >= r - 1) {
return;
}
std::vector<int> p = partition3(vec, l, r);
quick_sort_3(vec, l, p[0]);
quick_sort_3(vec, p[1], r);
}
6.4 分治算法
顾名思义,分而治之,就是将原问题分割成同等结构的子问题,之后将子问题逐一解决后,原问题也就得到了解决。(归并和快排都是。归并是直接二分,然后花功夫在合并上。快排是花功夫用partition去分,无需特意合并)
6.5 应用
求逆序对:
- 暴力解法:匹配每一个数对,计数器+1
- 归并法:在归并排序的过程中求逆序对(加个计数器)。因为左右子序列都是排好序的,所以在归并过程中,只要右边序列的数比左边序列的数字小,就代表左边序列的数字的后面的数字都和它构成逆序对。这样可以一次匹配好几个逆序队,计数器一下加好几个。
取数组中第n大的元素:
- 排序:复杂度O(nlogn),然后直接索引
- 快排:复杂度O(n)
7. 堆排序
7.1 基础知识
二叉堆,堆中某个节点的值是不大于其父节点的值,堆总是一颗完全二叉树
完全二叉树:
因为堆是完全二叉树,则可以用数组存储堆
连续的swap可以用移动赋值来优化,类似于插入排序
将N个元素逐个插入到一个空堆中,算法复杂度是O(nlogn)
将一个N元素的数组heapify的过程,从2/n逐个遍历到第一个元素的shiftdown,算法复杂度是O(n)

data是原数组,没有排序没有堆,单纯的数组
index是索引堆,存放着data的索引,并且[data[index[0]], data[index[1]], …, data[index[n]]]构成一个最大堆
当我们想改变data里面的值的时候,比如data[i],我们可以直接data[i] = new_value,但是我们要维护index的堆性质,所以需要遍历index,找到index[j] == i,这个复杂度是O(N),为了使复杂度变为O(1),我们可以再建立一个rev索引,存放着data[i]这个索引i在index中的位置,index[j] = i,即找到j
data[i], index[j] = i, rev[i] = j
index存放着data在最大堆中应该存在的索引位置,index[j] = data[i], o <= i,j < size
rev[i]存放着data[i]在index中的索引。(index本身不是最大堆)
比如我们把data[i]修改了,我们就要相应的维护index的堆的性质,相应的我们也要修改rev中的值
7.2 关键点
- 创建MaxHeap类,构造函数可以有两种,一个是创建capacity容量的空堆,另一个是直接将数组赋值到data,然后对<=k/2的元素进行shift_down
- insert成员函数,在末尾插入元素后,count+1,并且shift_up
- shift_up,比较简单,子节点和父节点比大小,然后交换,循环。注意边界问题
- shift_down,比较子节点左右节点的大小,然后交换,循环。注意边界问题
- extract_max,提取出最大堆的第一个数字,再把最后一个元素赋值到第一个来,在shift_down
- heap_sort,可以让data[count - i - 1] = heap.extract_max()来获取从小到大排列的数组
7.4 堆的应用
使用堆实现优先队列:电脑动态选择优先级最高的任务执行。游戏里优先选择攻击哪个敌人。
topk问题:使用堆优先队列的复杂度为O(NlogM),而排序是O(nlogn)
多路归并排序:将序列分为大于2个子序列,再将它们合并,这样就要比较它们的值,可以一个一个比较,也可以将这几个子序列的第一个数字构建一个最小堆,找到最小的元素,再把这个元素所在的子序列的下一个元素替换到堆里来,在shiftdown,再合并。
以上说的是二叉堆,还可以有d叉堆,即每个元素最多可以有d个子元素,它同样是一颗完全二叉树。
最大堆 最大索引堆
最小堆 最小索引堆
堆的实现细节优化:
shiftup和shiftdown中使用赋值操作替换swap操作
表示堆的数组从0开始索引
没有capacity的限制,动态的调整堆中数组的大小
最大最小队列
堆的变种:二叉堆、索引堆、二项堆、斐波那契堆

若有收获,就点个赞吧
0 人点赞
