1. 线性表(linear list)
线性表:线性表(linear list)也称有序表(ordered list),它的每一个实例都是元素的一个有序集合。
若存在 ,则前者为ai的直接前趋,后者为ai的直接后继
,则前者为ai的直接前趋,后者为ai的直接后继
1.1 数组描述
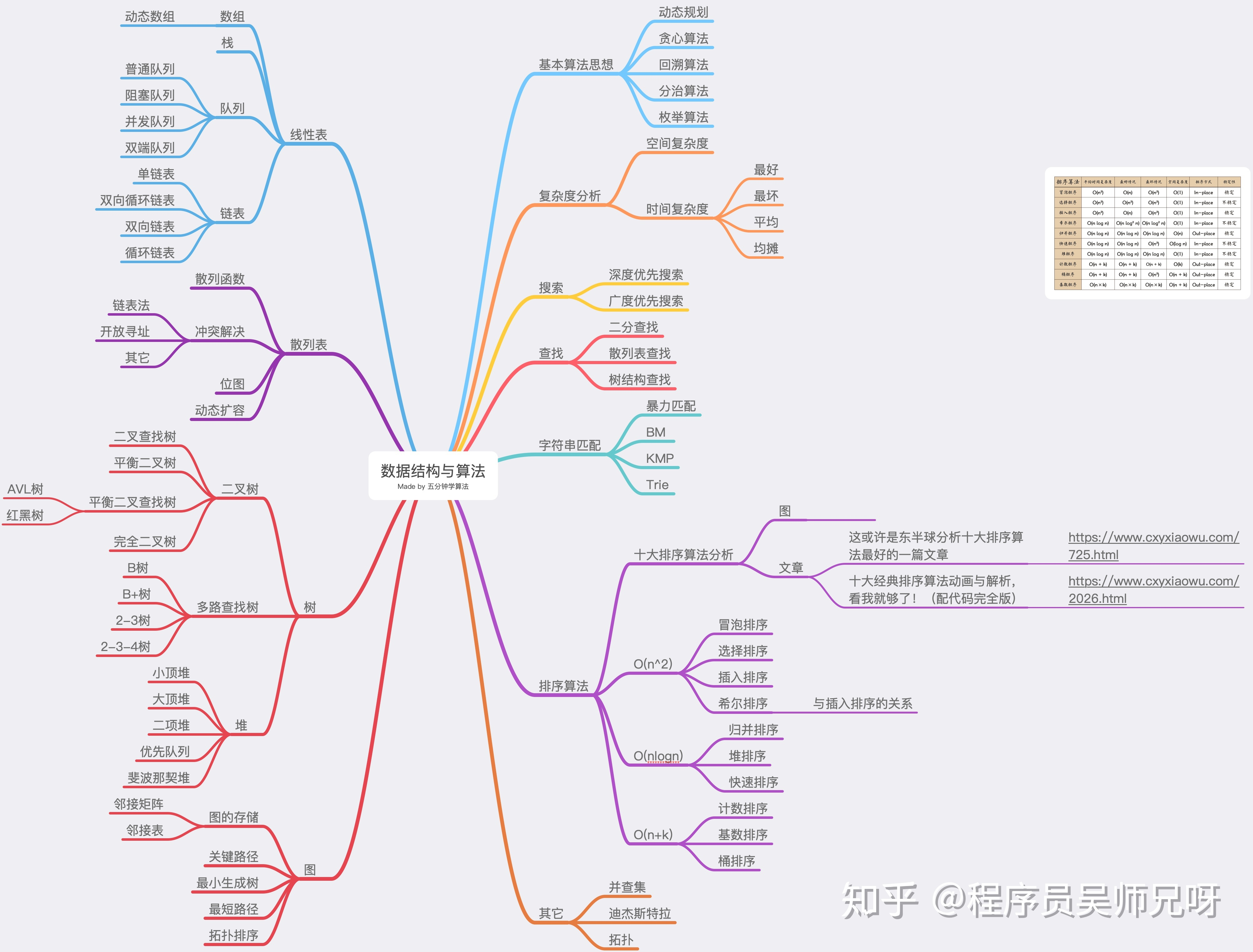
线性表:数组描述(array representation)就是用数组来存储线性表的元素,在内存中的存储位置是连续的。
1.2 链式描述
链表:在链式描述中,线性表的元素在内存中的存储位置是随机的。每个元素都有一个明确的指针或者链(指针或链是一个意思)指向线性表的下一个元素的位置(即地址)。
1.2.1 单向链表
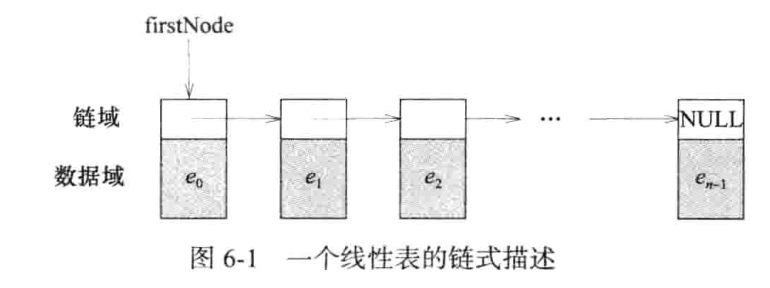
单向链表:每个节点只有一个链,最后一个节点的链域值为NULL
1.2.2 双向链表
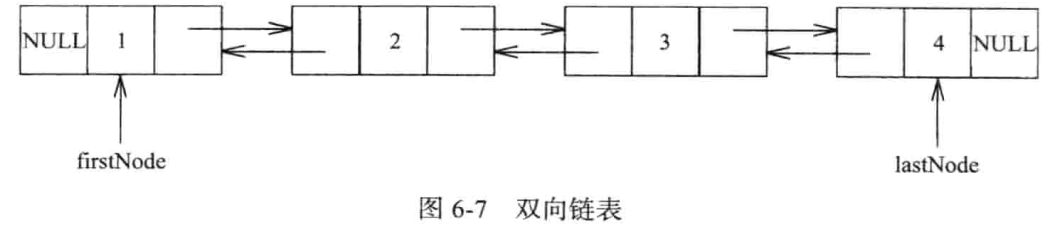
双向链表:链表中每个节点都有两个指针next和previous,next指向右节点,previous指向左节点,若左、右节点不存在则指针值为NULL
1.2.3 循环链表
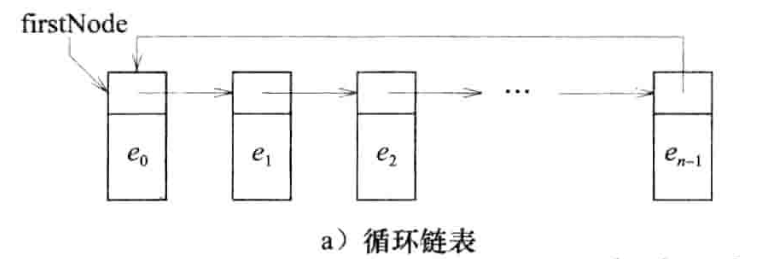
循环链表:链表的末端的指针不再指向NULL,而是指向另一端的节点的地址
1.2.4 带头结点的链表
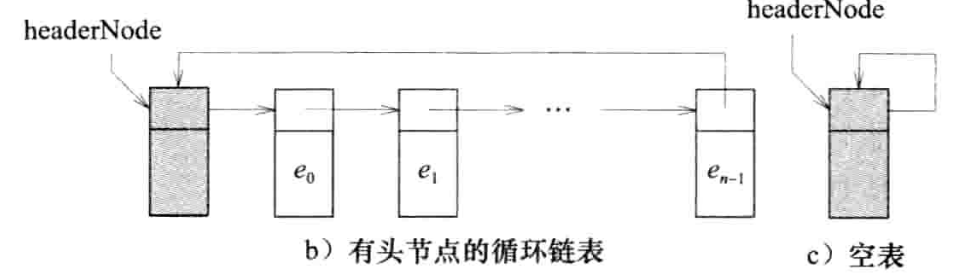
头结点:在链表的前面加一个附加节点,称为头结点(header node)。
优点:有了头结点,空表就不用作为特殊情况来处理了,程序因此变得简单。有了头结点,每个链表(包括空表)都至少包括一个节点(即头结点)
1.3 栈stack
栈(stack):栈是一种特殊的线性表,其插入(也称为入栈或压栈)和删除(也称为出栈或弹栈)操作都在表的同一端进行。操作的这一段称为栈顶(top),另一端称为栈底(bottom)。
1.4 队列queue
队列(queue):队列是一个线性表,其插入和删除操作分表在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一端称为队首(front)。
2. 散列表(hash)
散列表:散列表一般指哈希表(hash table),是根据关键值(key value)而直接进行访问的数据结构。也就是说,它通过把关键值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
字典的一种表示方式是散列(hashing),另一种是跳表。
简单理解:在键值对的存储中,通过把键进行散列函数映射,映射到一个散列表地址中,从而获取该键key所对应的value值。
2.1 散列函数和散列表
散列函数:哈希表中的映射函数称为散列函数。
一个简单的例子:现在有存放学生成绩的字典,学生id从1000到1099,现在通过一个理想散列函数 ,就可以把key值映射到0到99的范围中,如此我们查找、插入、删除学生的成绩的时间复杂度均为O(1)
,就可以把key值映射到0到99的范围中,如此我们查找、插入、删除学生的成绩的时间复杂度均为O(1)
散列表:哈希表中value值的数组就叫做散列表
- 桶与起始桶
当关键字的范围太大,不能用理想散列函数处理时,我们可以使用不理想的散列表和散列函数。散列表的位置比key值数量要少,散列函数也会将不同的关键字映射到散列表的同一个位置。- 除法散列函数
除法散列函数是最常用的,,其中D为除数,等于散列表的长度,%为求模操作
2.2 冲突(collision)和溢出(overflow)
冲突:不同的key键值映射到同一个散列表位置,就是冲突
溢出:散列表的一个位置没有空间存储新的键值对,就发生溢出
我们可以尽量保证每个位置存储的键值对数量差不多,就可以使用均匀散列函数,除法散列函数就是一种均匀散列函数。值得注意的是,使用素数作为除数D,可以获得良好的散列函数。(素数,也是质数,只能被1和自身整除的数,使用素数可以使得分布均匀)
2.3 冲突解决
溢出问题:将散列表的每一个桶bucket使用链表来表示,那么就不存在溢出问题了,因为这个桶链表可以容纳无限个记录。
冲突问题:首先计算关键字key值所对应的起始桶(散列表位置),再搜索该位置的链表。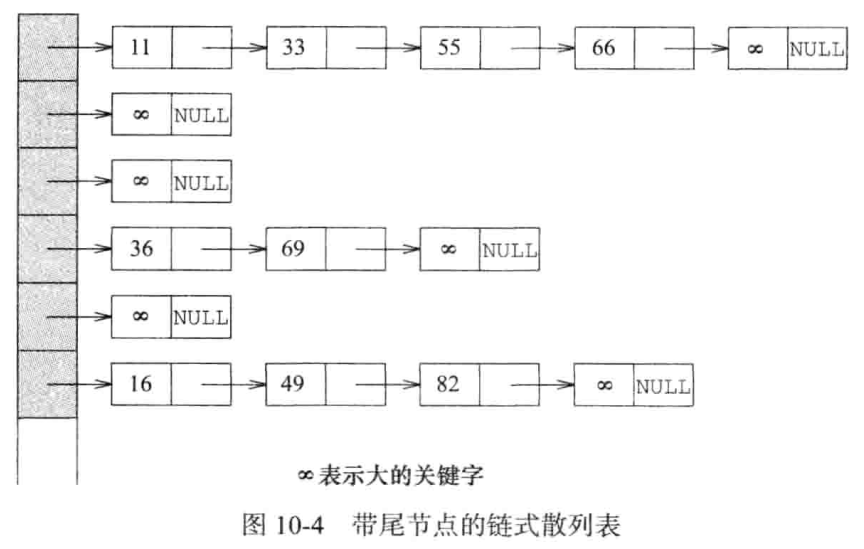
使用带尾节点的链表,实际上每个链表的尾节点可以公用同一个。
3. 树
树根据存储结构,可分为:① 顺序存储结构 ② 链式存储结构,如二叉链表、三叉链表
3.1 二叉树
二叉树(binary tree):二叉树是指树中节点的度不大于2(即≤2)的有序树。
一个元素的度:(degree of an element)是指其孩子的个数。叶子节点的度为0
有序树:树中任意节点的子节点之间有顺序关系,否则称为无序树
性质:
- 一颗二叉树有n个元素,n>0,它有n-1条边
- 一颗二叉树的高为h,h>=0,它最少有h个元素,最多有
个元素
- 一颗二叉树有n个元素,则它的高度最大为n,最小为
个,向上取整
- 满二叉树:当高度为h的二叉树恰好有
个元素时,称为满二叉树(full binary tree)
- 完全二叉树:前n-1层为满二叉树,最后一层所有元素都挤在最左边,元素之间没有空的位置
数组描述和链表描述:
- 数组描述:把二叉树看作是缺少了部分元素的完全二叉树,然后按照其编号存放在数组的相应位置。缺点是浪费空间,假如一棵n个元素的树只有左节点,那么所对应的数组空间有
- 链表描述:用指针是二叉树最常用的表示方法,一个节点包含left_child和right_child两个指针和一个element域。

遍历方式:(D访问根节点,L访问左子节点,R访问右子节点)
- 前序遍历(DLR):先访问一个节点,再访问该节点的左右子树。通过栈来保存每个访问节点的路径
- 中序遍历(LDR):先访问一个节点的左子树,在访问该节点,最后访问右子树
- 后序遍历(LRD):先访问一个节点的左右子树,再访问该节点
- 层次遍历:从顶层到底层,在同一层中,从左到右依次访问树的元素称为层次遍历。因为层次遍历需要队列而不是栈,所以编写递归程序很困难。额外创建一个队列,循环当队列不为空时,遍历queue.pop(),然后插入queue.push(node->left), queue.push(node->right),继续遍历
注意点:
- 前中后序遍历是深度优先遍历,层次遍历是广度优先遍历
- 对于前中后序遍历,关键点在于对每个节点进行一次DLR或者LDR,是否遍历到该节点,取决于DLR中D的位置。比如说DLR,则不管LR有没有,都先遍历该节点,D在LR前面;比如LDR,是否遍历该节点,要确保该节点已经没有左节点或者左节点已经遍历过了。
- 后序遍历适用于删除树的元素的时候,比如析构函数。

// 前序遍历DLRvoid pre_order(TreeNode* node) {if (node != nullptr) {visit(node->val);pre_order(node->left);pre_order(node->right);}}// 中序遍历LDRvoid in_order(TreeNode* node) {if (node != nullptr) {in_order(node->left);visit(node->val);in_order(node->right);}}// 后序遍历LRDvoid post_order(TreeNode* node) {if (node != nullptr) {post_order(node->left);post_order(node->right);visit(node->val);}}// 一个小tips:DLR也可以携程DRL,交换一下访问左或者右节点的顺序即可
3.2 二叉搜索树
二叉搜索树又称二叉查找树(binary search tree),是一颗二叉树,它满足以下特征:
- 每个元素有一个关键字,并且任意两个元素的关键字不同,也就是说所有的关键字都是唯一的(这个要求其实不一定,只要用小于等于代替3或大于等于代替2即可)
- 节点要大于其左子节点(如果存在)
- 节点要小于其右子节点(如果存在)
- 节点的左右子树都是二叉搜索树
相关性质:
- 二叉搜索树的的最小值,可以通过不断找左子节点的递归,当左子节点不存在时,当前节点就是最小值。
- 最大值,通过不断找右子节点的递归,当右子节点不存在时,当前节点就是最大值
- 当要删除最大值最小值时,可能会出现左子树或右子树断掉的情况,但是记住一个性质4,节点的左右子树都是二叉搜索树,所以只要把断掉的子树重新接上即可
- 如果需要实现有重复元素的二叉搜索树,可以更改node 的struct结构,增加一个count值,计算该元素有多少个
3.2.1 索引二叉搜索树
索引二叉搜索树(indexed binary search tree)源于普通二叉搜索树,只是在每个节点中添加一个left_size域。这个域的值是该节点左子树的元素个数。
left_size的意思是,比他小的元素有多少个。可以利用这个性质获取一个元素在二叉树中的rank即顺序排序的化排第几:
- 搜索该元素在二叉树中的位置
- 获取该元素的left_size
根据二叉搜索树的性质,节点比右子节点都要小,所以将该元素的left_size和父节点的left_size加起来就是该元素的rank
3.2.2 搜索
利用二叉搜索树的性质进行搜索,即节点大于左子节点,节点小于右子节点。那么从根节点开始比较,若小于根节点,则进入左子树,反之进入右子树,直到节点没有任何子树时搜索结束。
3.2.3 插入
插入之前,先进行一次搜索。若存在该key值的元素,则用插入元素更新该元素。若不存在该key值元素,则插入到二叉树相应位置,并且链接到一起father_node->right = new_node
3.2.4 删除
对于节点的删除,需要考虑三种情况:
节点是树叶:直接释放该叶节点的空间,并且令父节点的left或者right置nullptr
- 节点有一颗非空子树:释放该节点的空间,并且令父节点的left或者right链接到该删除节点的子节点上
- 节点有两个非空子树(重点):谨记二叉搜索树的性质,节点大于其左子节点的同时,大于其左子树的所有元素。删除元素的重点在于,删除元素后依然维持二叉搜索树的性质。假如删除节点D,就要保证重新连接后的二叉搜索树性质依然成立。当删除的节点有两个非空子树,只需要从该节点的右子树中找到最小值,替换到该节点。具体步骤: ```cpp s = min(d->right); // 从删除节点的右子树找到最小元素 s->right = del_min(d->right); // 删除右子树的最小元素,删除返回子树的根节点,令最小元素的右子节点为该根节点,则满足(节点小于右子节点的性质) s->left = d->left; // 最小元素的左节点直接等于删除元素的左节点 fahter->left = s; // 将父节点的子节点链接到最小元素,fahter->left = s;
当然除了在右子树找找最小值来代替该节点,也可以从左子树中找最大值来代替该节点,这两个操作之后都满足二叉搜索树的性质。
<a name="NgI3M"></a>
### 3.2.5 最大最小值、floor、ceil
利用二叉搜索树的性质,可以很方便的找到最大值和最小值。<br />最小值:不断地找左子树,当不再有左子树的时候,为最小值<br />最大值:不断的找右子树,当不再有右子树的时候,为最大值<br />floor:比查找值小但是最接近于查找值的元素<br />ceil:比查找值大但是最接近于查找值的元素
<a name="hIgKh"></a>
# 4. 堆(heap)
大(小)根树:每个节点的值都大于(小于)等于其子节点的值。<br />大(小)根堆:大(小)根树 & 完全二叉树<br />插入:在堆末尾插入元素,然后shift_up<br />删除:即删除根节点元素,然后把最后一个元素移到根元素这里来,再执行shift_down
<a name="yBWec"></a>
# 5. 动态规划
动态规划,dynamic programming,简称DP,如果一个问题有很多重叠的子问题,使用动态规划是最有效的。<br />原则:
1. 无论第一次的选择是什么,接下来的选择一定是当前状态下的最优选择,这是最优原则(principle of optimality)。它意味着一个最优选择序列是由最优选择子序列构成的。
动态规划5步走:
1. 确定dp数组(dp table)以及下标的含义
1. 确定递推公式
1. dp数组如何初始化
1. 确定遍历顺序
1. 举例推导dp数组
<a name="XMw59"></a>
# 6. 回溯法
回溯法也叫做回溯搜索法,它是一种搜索的方式。<br />回溯的本质是穷举,效率低下,但可以解决暴力法解决不了的问题。
1. 组合问题:N个数里面按一定的规则找出K个数(且满足条件)的集合
1. 切个问题:一个字符串按一定规则有几种切割方式
1. 子集问题:一个N个数的集合里有多少符合条件的子集
1. 排列问题:N个数按一定规则全排列,有几种排列方式
1. 棋盘问题:N皇后,解数独等等
<a name="Gp10d"></a>
## 6.1 如何理解回溯法
回溯法解决的问题都可以抽象为树形结构。因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,就构成了树的深度。<br />递归就要有终止条件,所以必然是一颗高度优先的树(N叉树)
<a name="TJaB9"></a>
## 6.2 回溯法模板
回溯三部曲:
1. 确定回溯函数返回值以及参数
1. 确定回溯函数终止条件
1. 回溯搜索的遍历过程
伪代码如下:
```cpp
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}

若有收获,就点个赞吧
0 人点赞
