链表(数组模拟)
为什么要模拟?
效率问题,第一种实现方式是指针+结构体的方式,面试题多,笔试题不多,因为每一次创建一个新的链表就要调用一下new函数来new一个新的节点,new一个新节点这个操作是非常慢的,一般在笔试题中,链表大小在10w~100w级别,但是new出这些节点基本就超时了,因此在平时笔试时基本不会采用动态链表方式,当然如果改进一下是可以用的,比如可以先初始化n各节点,不过本质跟我们模拟链表差不多了。
模拟两种链表:
- 单链表:单链表在算法或笔试题中用的最多的是邻接表(邻接表其实是n个链表,最主要应用是存储图和树)
- 双链表:用的比较多的情况是优化某些问题
单链表
每个节点有两个值,value和指向下一个节点的指针next,模拟时用e[N]和ne[N]表示,用下标进行关联
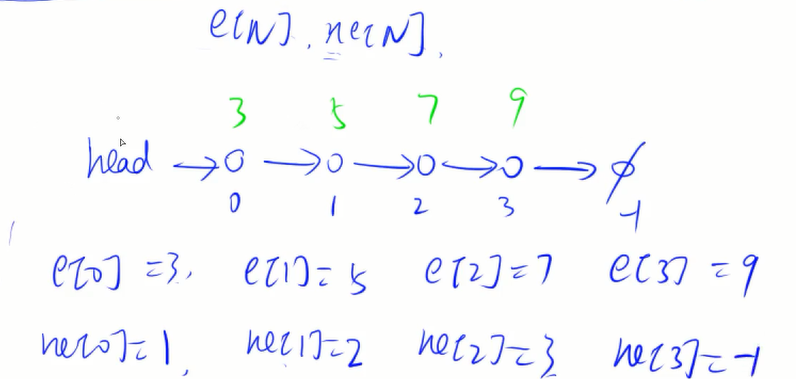


#include <iostream>using namespace std;const int N = 100010;//head表示头结点下标//idx存储当前用到了哪个地址int head, e[N], ne[N], idx;void init(){head = -1;idx = 0;}void add_to_head(int x){e[idx] = x;ne[idx] = head;head = idx;idx++;}//将x插入到下标k节点后面void add(int k, int x){e[idx] = x;ne[idx] = ne[k];ne[k] = idx;idx++;}//可以在任意位置插入,但是如果要在O(1)时间复杂度内插入,只能在某个点后面插入//将下标是k的点后面的点删掉void remove(int k){ne[k] = ne[ne[k]];}//删一个点这个题idx不用变,一般来说算法题是不用管的int main(){int m;cin >> m;init();while(m--){char op;int k, x;cin >> op;if(op == 'H'){cin >> x;add_to_head(x);}else if(op == 'D'){cin >> k;if(!k)head = ne[head];elseremove(k - 1);}else{cin >> k >> x;add(k - 1, x);}}for(int i = head; i != -1; i = ne[i]) cout << e[i] << ' ';cout << endl;return 0;}
双链表
之所以单链表要用head指向第一个点,是因为后面用的时候总会用一个变量存第一个点,双链表往往不需要,只需要用两个数来表示左右端点。




这题是循环双链表,五个操作只需要实现两个就可以,一个是在k节点右边插入一个点,一个是删除。left和right不是链表中的点,表示的是端点。
#include<iostream>using namespace std;const int N = 100010;int m;int e[N], l[N], r[N], idx;void init(){//0表示左端点,1表示右端点r[0] = 1, l[1] = 0;//开始为空,左端点指向右端点,右端点指向左端点idx = 2;}//在下标是k的节点右边插入一个节点,值为xvoid add(int k, int x){e[idx] = x;r[idx] = r[k];l[idx] = k;l[r[k]] = idx;r[k] = idx;idx++;}//在k节点左边插入//直接调用add(l[k], x);//在k节点左边节点的右边插入即可//删除第k个节点void remove(int k){r[l[k]] = r[k];l[r[k]] = l[k];}int main(){init();int m;cin >> m;while(m--){int k, x;string op;cin >> op;if(op == "L"){cin >> x;add(0, x);}else if(op == "R"){cin >> x;add(l[1], x);}else if(op == "D"){cin >> k;remove(k + 1);//第k个插入点的下标是k+1,因为idx是从下标2开始的}else if(op == "IL"){cin >> k >> x;add(l[k + 1], x);}else{cin >> k >> x;add(k + 1, x);}}for(int i = r[0]; i != 1; i = r[i]) cout << e[i] << ' ';cout << endl;return 0;}
栈与队列(数组模拟)
栈
先进后出,先插入的元素后被弹出。类似一个桶状。
#include <iostream>
using namespace std;
const int N = 100010;
//stk是栈,tt是栈顶下标,下标从0开始还是1开始看自己习惯
int stk[N], tt;
//栈顶加一个新元素
stk[++t] = x;
//删除,栈顶下标--
tt--;
//判断是否为空
if(tt > 0) not empty
else empty
//取出栈顶
stk[tt];
队列
先进先出,先进的元素先出。类似排队。

#include <iostream>
using namespace std;
const int N = 100010;
//hh表示队头,tt表示队尾,队尾插入,队头弹出
int q[N], hh, tt = -1;
//插入元素
q[++tt] = x;
//弹出元素
hh++;
//判断是否为空
if(hh <= tt) not empty
else empty
//取出队头元素
q[hh];
单调栈、单调队列
单调栈
Hash表
哈希表:
作用:
把一个比较庞大的空间或值域、复杂的数据结构映射到0~N(一般较小,106 )
存储结构(处理冲突的方式):
- 开放寻址法
- 拉链法
- 字符串哈希方式
离散化是极其特殊的哈希方式,离散化要求h(x)是单调递增的

哈希表是一种期望算法,虽然每个槽会拉一条链,但在平均情况下看,每条链长度可以看为常数,一般情况下时间复杂度都可以看为O(1),算法题里一般不需要删除操作,只需要添加和查找,如果要实现删除,不会真的删除,一般是开一个数组,在每个点打一个标记


拉链法
数组长度(模的数)一般要取质数,要离2的整次幂尽可能远,这样冲突概率小
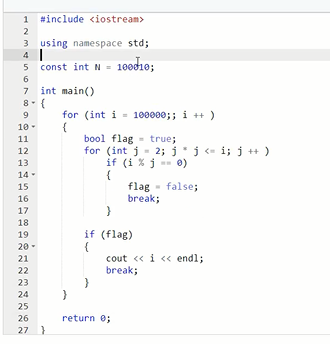
找出第一个质数,N改为100003
读入一个字符的话,如果用scanf最好读入一个字符串,他会自动把空格、回车、制表符忽略掉,可以减少出错的概率,所以一般不会读字符
开放寻址法
处理冲突的方法:
只开一个数组,所以形式看起来简单,但是一维数组长度一般要开到题目数据范围的2~3倍
数组大小同样是取质数。
字符串前缀哈希法
字符串看成一个p进制数,每一个字母(ASCII)看成数的一位数字,首先预处理出所有前缀的哈希

若将一个映射为0,那么就会将多个不同字符串映射出同样的数字,如:A=0,那么AA=0,AAA=0……
P=131或者13331,Q=2^64时,基本不会发生冲突
利用前缀哈希以及这种哈希方式,可以求出任意子串的哈希值

对于取模Q,可以用unsinged long long存所有h,就不需要取模了,溢出就相当于取模了
所有预处理完每一个前缀的哈希值后,就可以用O(1)的时间计算出任意子串的哈希值了,预处理前缀的哈希值也很简单:h(i)=h(i-1)*p+str[i],str[i]是第i位的字母

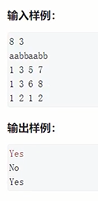
快速判断两个字符串是否相等,就可以用这个方法。个别题目只能用kmp来做,例如:求循环节,这个不行,其他好像都可以用哈希,而且不如哈希
STL





如果需要10^6的空间,那么大概copy 10^6次,平均下来,时间复杂度是O(1),申请空间的次数是logn
队列、堆、栈没有clear函数,想清空队列,可以重新构造一个
queue<int> q;
q = queue<int>();
堆默认是大根堆,有两种方式可以构造小根堆
- 插入一个数的时候插入它的负数
priority_queue<int> heap; heap.push(-x);
- 定义的时候直接定义小根堆
priority_queue<int, vector<int>, greater<int>> heap;
双端队列deque是加强版的vector,不过速度比较慢,所以用的不是很多,因为比一般数组慢好几倍
set是不能有重复元素的,插入一个重复元素,那么这个操作会被忽略掉,multiset可以,set所有操作时间复杂度都是logn,不过size()、empty()、clear()是O(1)的
map可以像数组一样用,但是时间复杂度是O(logn),数组直接取下标是O(1)的

若有收获,就点个赞吧
0 人点赞
