DFS/BFS
| 数据结构 | 空间 | ||
|---|---|---|---|
| DFS | stack | O(h) | 不具有最短性 |
| BFS | queue | O(2^h) | 最短路的概念 |

例如搜这个点,DFS要搜的步数比BFS多
DFS有两个重要概念:回溯、剪枝
DFS
#include <iostream>const int N = 10;using namespace std;int n;int path[N];bool st[N];void dfs(int u){if(u == n){for(int i = 0; i < n; i++) printf("%d", path[i]);puts("");return;}for(int i = 1; i <= n; i++)if(!st[i]){path[u] = i;st[i] = true;dfs(u + 1);st[i] = false;}}int main(){scanf("%d", &n);dfs(0);return 0;}



方法一:用全排列的方法,一行一行枚举,看每一行可以放在哪一列
#include <iostream>const int N = 20;//对角线是个数的二倍减一using namespace std;int n;char g[N][N];bool col[N], dg[N], udg[N];//dg、udg为两条对角线void dfs(int u){if(u == n){for(int i = 0; i < n; i++) puts(g[i]);puts("");return;}for(int i = 0; i < n; i++){// 两条对角线y = x + b,y = -x + b,对应的截距为b = y - x,b = y + x,但是y - x可能为负,所以要加上一个n,即y - x + nif(!col[i] && !dg[u + i] && ! udg[n - u + i]){g[u][i] = 'Q';col[i] = dg[u + i] = udg[n - u + i] = true;dfs(u + 1);g[u][i] = '.';col[i] = dg[u + i] = udg[n - u + i] = false;}}}int main(){scanf("%d", &n);for(int i = 0; i < n; i++)for(int j = 0; j < n; j++)g[i][j] = '.';dfs(0);return 0;}
疑惑:
为什么不是n + u - i,u不是行吗?不是对应的y坐标吗?
答:一样为什么全排列题没有在u==n时return
答:漏了剪枝体现在哪
方法二:一个格子一个格子枚举
#include <iostream>const int N = 20;//对角线是个数的二倍减一using namespace std;int n;char g[N][N];bool row[N], col[N], dg[N], udg[N];//dg、udg为两条对角线void dfs(int x, int y, int s)//分别为当前xy坐标、放了几个皇后{if(y == n) y = 0, x ++;if(x == n){if(s == n){for(int i = 0; i < n; i ++)puts(g[i]);puts("");}return;}//不放皇后dfs(x, y + 1, s);//放皇后if(!row[x] && !col[y] && !dg[x + y] && !udg[x - y + n]){g[x][y] = 'Q';row[x] = col[y] = dg[x + y] = udg[x - y + n] = true;dfs(x, y + 1, s + 1);g[x][y] = '.';row[x] = col[y] = dg[x + y] = udg[x - y + n] = false;}}int main(){scanf("%d", &n);for(int i = 0; i < n; i++)for(int j = 0; j < n; j++)g[i][j] = '.';dfs(0, 0, 0);return 0;}
两种方法的时间复杂度分别是:O(n*n!)、O(22),第二种效率差一些
BFS
深度搜索没有常用的框架,广度搜索有
只有边权值为1的最短路问题可以用广度搜索,而且一般不用BFS,因为时间复杂度较高,一般用专门的最短路算法来求,如dp


#include <iostream>#include <string.h>using namespace std;const int N = 110;typedef pair<int, int> PII;int n,m;int g[N][N];//存地图int d[N][N];//存每个点到起点的距离PII q[N * N];int bfs(){int hh,tt = 0;//注意tt=0,因为下面初始在队列加入了一个元素q[0] = {0, 0};memset(d, -1, sizeof(d));d[0][0] = 0;int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};while(hh <= tt){auto t = q[hh++];for(int i = 0; i <4; i++){int x = t.first + dx[i], y = t.second + dy[i];if(x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1){d[x][y] = d[t.first][t.second] + 1;q[ ++tt] = {x, y};}}}return d[n-1][m-1];}int main(){scanf("%d%d", &n, &m);for(int i = 0; i < n; i ++)for(int j = 0; j < m; j++)scanf("%d", &g[i][j]);printf("%d\n", bfs());return 0;}
图
树是一种特殊的图:有向无环图
图分为有向图和无向图
无向图可以看作是特殊的有向图,一条边a-b可以建立一条a到b的,再建立一条b到a的
有向图存储:
- 邻接矩阵(用得少),即一个二维数组,邻接矩阵不能存储重边,比较浪费空间,空间复杂度n^2,适合存储稠密图
- 邻接表(用的最多),就是单链表,如果有n个点就开了n个单链表
树和图的深度优先遍历、宽度优先遍历时间复杂度都是O(n+m)
图DFS
#include <iostream>#include <algorithm>#include <cstring>using namespace std;const int N = 100010, M = N*2;int n;int h[N], e[M], ne[M], idx;//h存n个链表头,e存每个节点的值,ne存next指针bool st[N];//存哪些点被遍历过void add(int a, int b){e[idx] = b, ne[idx] = h[a], h[a] = idx++;}void dfs(int u){st[u] = true;for(int i = h[u]; i != -1; i = ne[i]){int j = e[i];//存当前链表的节点对应图的标号是多少if(!st[j]) dfs(j);}}int main(){memset(h, -1, sizeof(h));dfs(1);return 0;}


#include <iostream>#include <algorithm>#include <cstring>using namespace std;const int N = 100010, M = N*2;int n;int h[N], e[M], ne[M], idx;//h存n个链表头,e存每个节点的值,ne存next指针bool st[N];//存哪些点被遍历过int ans = N;//结果void add(int a, int b){e[idx] = b, ne[idx] = h[a], h[a] = idx++;}int dfs(int u){st[u] = true;int sum = 1, res = 0;//sum表示当前子树的大小,初始为1,表示加入了当前节点//res表示把当前这个点删掉后每个连通块的最大值for(int i = h[u]; i != -1; i = ne[i]){int j = e[i];//存当前链表的节点对应图的标号是多少if(!st[j]){int s = dfs(j);//s表示存储当前子树大小res = max(res, s);//当前子树也是一个连通块,因此要与res进行比较sum += s;//当前子树是以u为根节点的子树的一部分}}//最后要算以u为根节点子树以外的连通图节点数res = max(res, n - sum);//最后res存储的就是删除当前节点后最大的连通图节点数,与当前最小结果进行比较ans = min(res, ans);return sum;}int main(){cin >> n;memset(h, -1, sizeof(h));//注意i < n-1 ,n-1条无向边for(int i = 0; i < n - 1; i++){int a, b;cin >> a >> b;add(a, b);add(b, a);}dfs(1);//从哪个点开始搜都可以,因为以哪个点为根都一样cout << ans << endl;return 0;}
图BFS


重边是指两个点之间有多条边,自环是指有指向自己的边
拓扑序列
图的宽搜很经典的应用就是求拓扑序
针对有向图,无向图没有拓扑序列
当把图按照拓扑序排好后,所有边都是从前指向后的
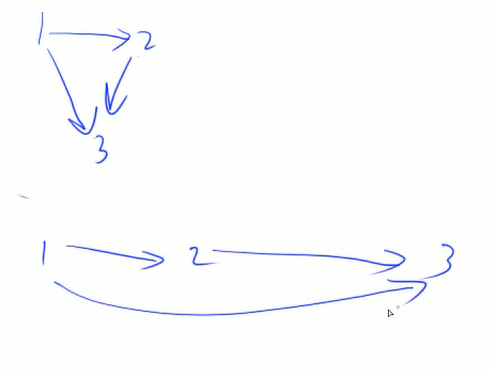
并不是所有图都有拓扑序列,有环就无论如何都不能摆成拓扑序
可证明,有向无环图一定存在拓扑序列,所以有向无环图也被称为拓扑图

一个有向无环图,一定至少存在一个入度为0的点


一个有向无环图的拓扑序不一定是唯一的

若有收获,就点个赞吧
0 人点赞
