索引的数据结构比较复杂 , 本文只希望针对实际中的数据格式所以对应建立的索引来进行尽可能精简的记录
普通查询
概念
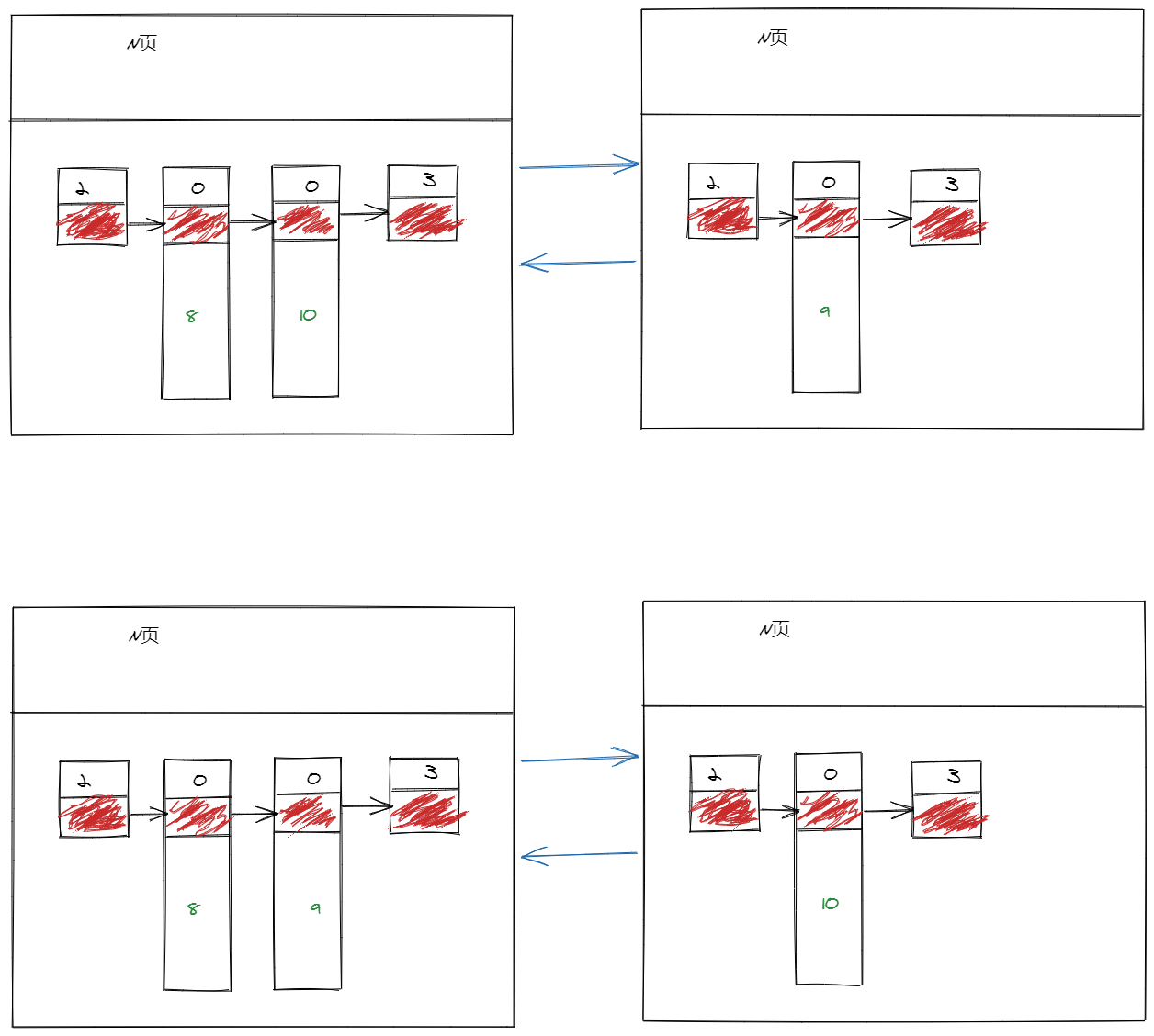
- 页分裂
- 一页中可存储的数据量有限 , 当到达临界值 , 需要采用新的页进行记录的存储
- 其中包含一个规则 : 下一页中的记录主键必须大于上一页中的记录主键 , 所以伴随带来的是记录可能会进行一定程度的移动
- 进行页分裂之后的两个关联页的页号可能不是连续的 , 他只是维护了一种关联关系
目录项
对应每个记录页的信息
- 记录了每页的最小记录的主键值和所在页的页号
- 这种记录格式也被称为索引

方案
伴随记录的插入 , 目录项的维护也会消耗查询性能
- 目录项记录
- 将记录了页号的目录项单独做为一个记录页来存储 , 用记录头中的record_type和min_rec_mask属性来区分
- 目录项记录的列依旧只有页号和对应页的最小记录主键值
- 除了存储的记录的数据内容不同 , 本质上跟页的存储方式一样
- 存储目录项记录的页
- 生成一个更高级的目录 , 用于记录目录项记录
- 记录存储方式跟目录项记录页的一样 , 记录页中的最小记录主键值和页号
B+树
通过上述方案所建立的数据结构就是B+树
- 最上边的结点称为根节点
- 用来存放目录项的记录称为内节点
- 只有在叶子节点才会存储真实完整的用户数据
聚簇索引
主键索引即为聚簇索引
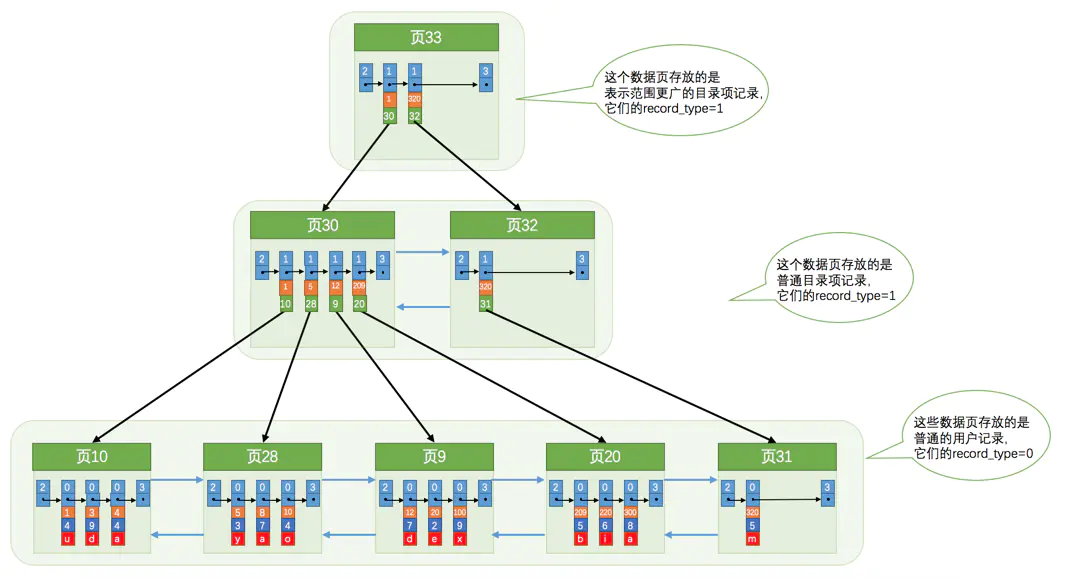
- 存储
- InnoDB会帮助我们隐式的创建
- 特点
- 页内的记录是按照主键的大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表
- 在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
- 叶子节点存储的是完整的用户记录
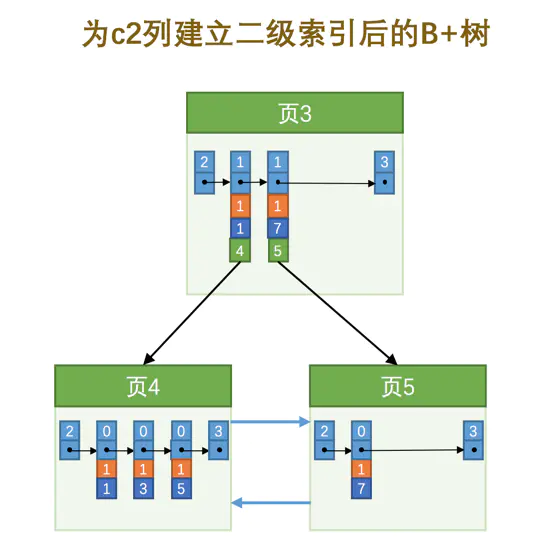
二级索引
当查询条件无法使用聚簇索引时(即为别的列)被创建
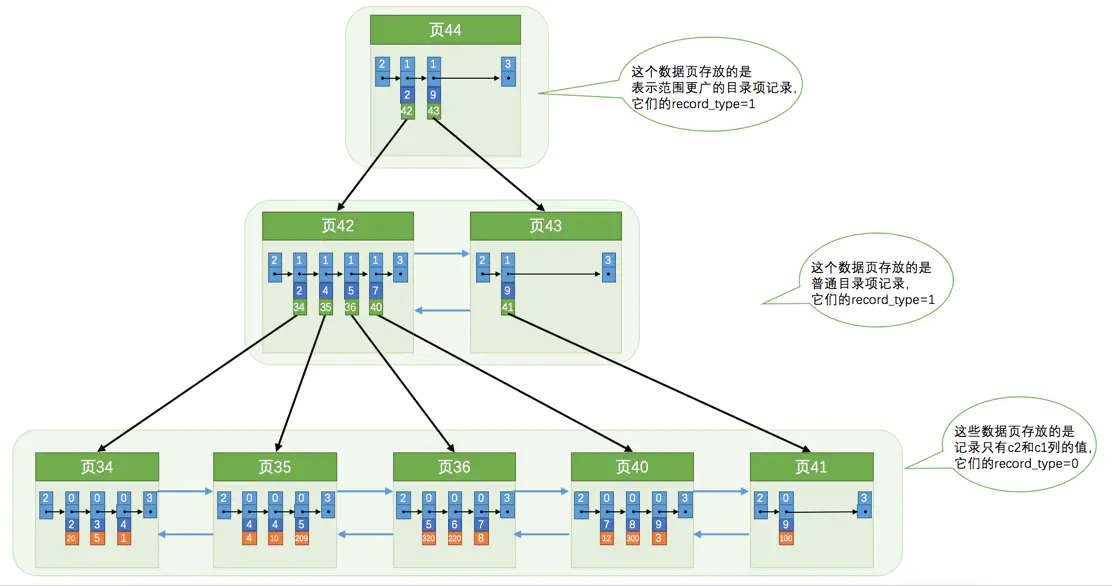
- 存储
- 在显式创建索引时创建
特点
加入查询列为column1
- 页内的记录是按照的column1大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中用户记录的column1大小顺序排成一个双向链表
- 在同一层次中的页也是根据页中目录项记录的column1大小顺序排成一个双向链表
- 叶子节点存储的是column1 和 主键的值
联合索引
以多个列的大小排序同时建立索引
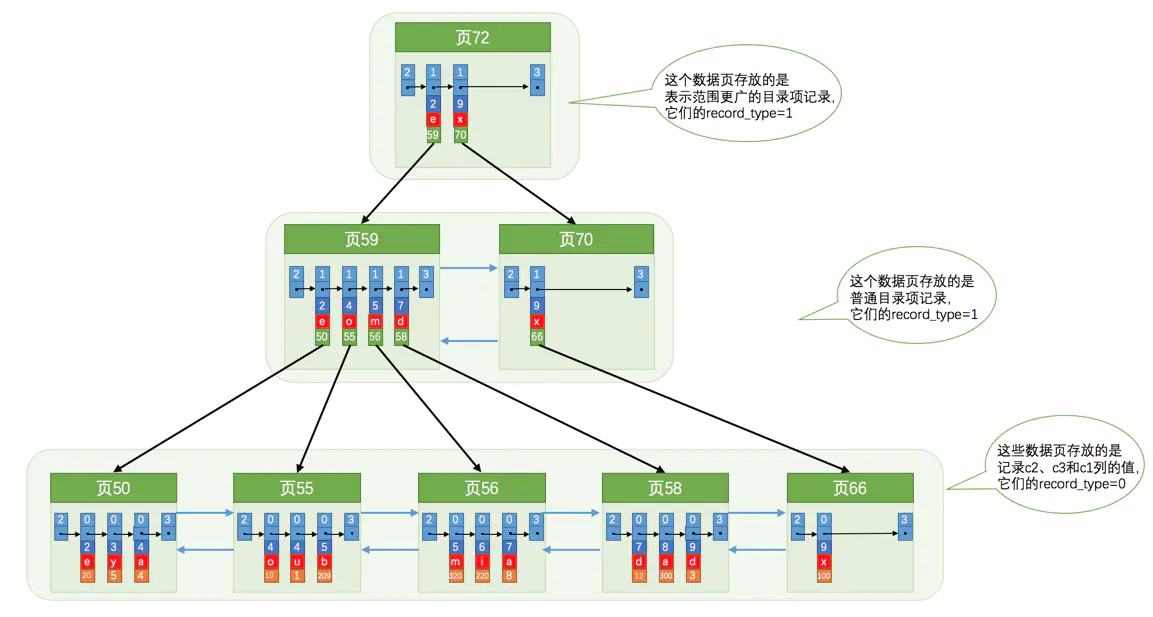
- 存储
- 在显式创建索引时创建
- 特点
- 每条目录项记录都由column1 , column2 , 页号这三个部分组成,各条记录先按照column1 列的值进行排序,如果记录的column1 列相同,则按照column2 列的值进行排序
- 叶子节点存储的是同时创建的两列和主键的值
- 本质上也是个二级索引
在无法直接使用聚簇索引的是情况下 , 使用二级索引是为了找到对应主键 , 再通过聚簇索引去查询叶子节点中用户的真实数据 , 这种操作也就是回表
**
内节点目录项记录的唯一性
我们需要保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的
所以实际上 , 二级索引的目录项记录是要由三部分构成的 :
- 索引列的值
- 主键值
- 页号

若有收获,就点个赞吧
0 人点赞
