重点
- 存储快照概念、使用与工作原理;
- 存储拓扑调度背景、概念、使用与工作原理。
一、基本知识
存储快照产生背景
在使用存储时,为了提高数据操作的容错性,我们通常有需要对线上数据进行snapshot,以及能快速restore的能力。另外,当需要对线上数据进行快速的复制以及迁移等动作,如进行环境的复制、数据开发等功能时,都可以通过存储快照来满足需求,而 K8s 中通过 CSI Snapshotter controller 来实现存储快照的功能。
存储快照用户接口-Snapshot
我们知道,K8s 中通过 pvc 以及 pv 的设计体系来简化用户对存储的使用,而存储快照的设计其实是仿照 pvc & pv 体系的设计思想。当用户需要存储快照的功能时,可以通过 VolumeSnapshot 对象来声明,并指定相应的 VolumeSnapshotClass 对象,之后由集群中的相关组件动态生成存储快照以及存储快照对应的对象 VolumeSnapshotContent。如下对比图所示,动态生成 VolumeSnapshotContent 和动态生成 pv 的流程是非常相似的。
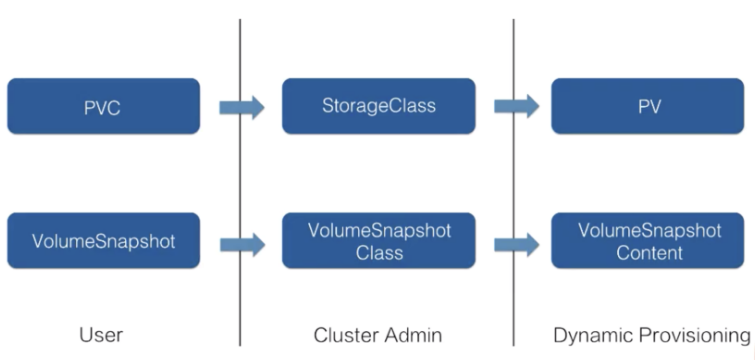
存储快照用户接口-Restore
有了存储快照之后,如何将快照数据快速恢复过来呢?如下图所示:
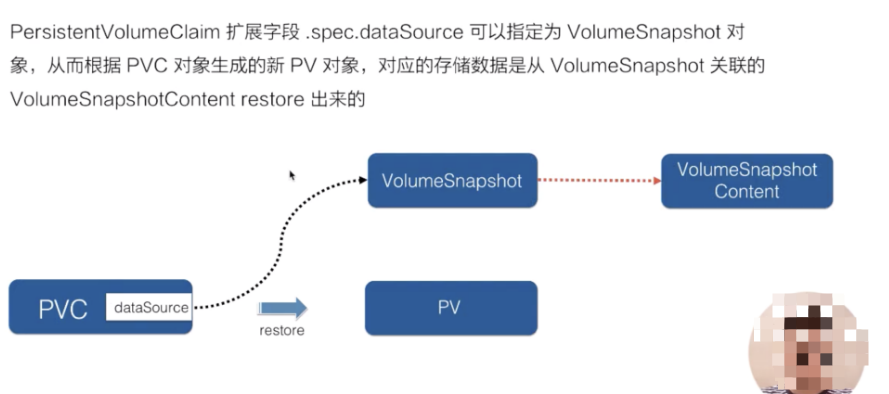
如上所示的流程,可以借助 PVC 对象将其的 dataSource 字段指定为 VolumeSnapshot 对象。这样当 PVC 提交之后,会由集群中的相关组件找到 dataSource 所指向的存储快照数据,然后新创建对应的存储以及 pv 对象,将存储快照数据恢复到新的 pv 中,这样数据就恢复回来了,这就是存储快照的restore用法。Topolopy-含义
首先了解一下拓扑是什么意思:这里所说的拓扑是 K8s 集群中为管理的 nodes 划分的一种“位置”关系,意思为:可以通过在 node 的 labels 信息里面填写某一个 node 属于某一个拓扑。
常见的有三种,这三种在使用时经常会遇到的:
- 第一种,在使用云存储服务的时候,经常会遇到 region,也就是地区的概念,在 K8s 中常通过 label failure-domain.beta.kubernetes.io/region 来标识。这个是为了标识单个 K8s 集群管理的跨 region 的 nodes 到底属于哪个地区;
- 第二种,比较常用的是可用区,也就是 available zone,在 K8s 中常通过 label failure-domain.beta.kubernetes.io/zone 来标识。这个是为了标识单个 K8s 集群管理的跨 zone 的 nodes 到底属于哪个可用区;
第三种,是 hostname,就是单机维度,是拓扑域为 node 范围,在 K8s 中常通过 label kubernetes.io/hostname 来标识,这个在文章的最后讲 local pv 的时候,会再详细描述。
上面讲到的三个拓扑是比较常用的,而拓扑其实是可以自己定义的。可以定义一个字符串来表示一个拓扑域,这个 key 所对应的值其实就是拓扑域下不同的拓扑位置。
举个例子:可以用 rack,也就是机房中的机架这个纬度来做一个拓扑域。这样就可以将不同机架 (rack) 上面的机器标记为不同的拓扑位置,也就是说可以将不同机架上机器的位置关系通过 rack 这个纬度来标识。属于 rack1 上的机器,node label 中都添加 rack 的标识,它的 value 就标识成 rack1,即 rack=rack1;另外一组机架上的机器可以标识为 rack=rack2,这样就可以通过机架的纬度就来区分来 K8s 中的 node 所处的位置。
接下来就一起来看看拓扑在 K8s 存储中的使用。
存储拓扑调度产生背景
上一节课我们说过,K8s 中通过 PV 的 PVC 体系将存储资源和计算资源分开管理了。如果创建出来的 PV有”访问位置”的限制,也就是说,它通过 nodeAffinity 来指定哪些 node 可以访问这个 PV。为什么会有这个访问位置的限制?
因为在 K8s 中创建 pod 的流程和创建 PV 的流程,其实可以认为是并行进行的,这样的话,就没有办法来保证 pod 最终运行的 node 是能访问到 有位置限制的 PV 对应的存储,最终导致 pod 没法正常运行。这里来举两个经典的例子:
首先来看一下 Local PV 的例子,Local PV 是将一个 node 上的本地存储封装为 PV,通过使用 PV 的方式来访问本地存储。为什么会有 Local PV 的需求呢?简单来说,刚开始使用 PV 或 PVC 体系的时候,主要是用来针对分布式存储的,分布式存储依赖于网络,如果某些业务对 I/O 的性能要求非常高,可能通过网络访问分布式存储没办法满足它的性能需求。这个时候需要使用本地存储,刨除了网络的 overhead,性能往往会比较高。但是用本地存储也是有坏处的!分布式存储可以通过多副本来保证高可用,但本地存储就需要业务自己用类似 Raft 协议来实现多副本高可用。
接下来看一下 Local PV 场景可能如果没有对PV做“访问位置”的限制会遇到什么问题?
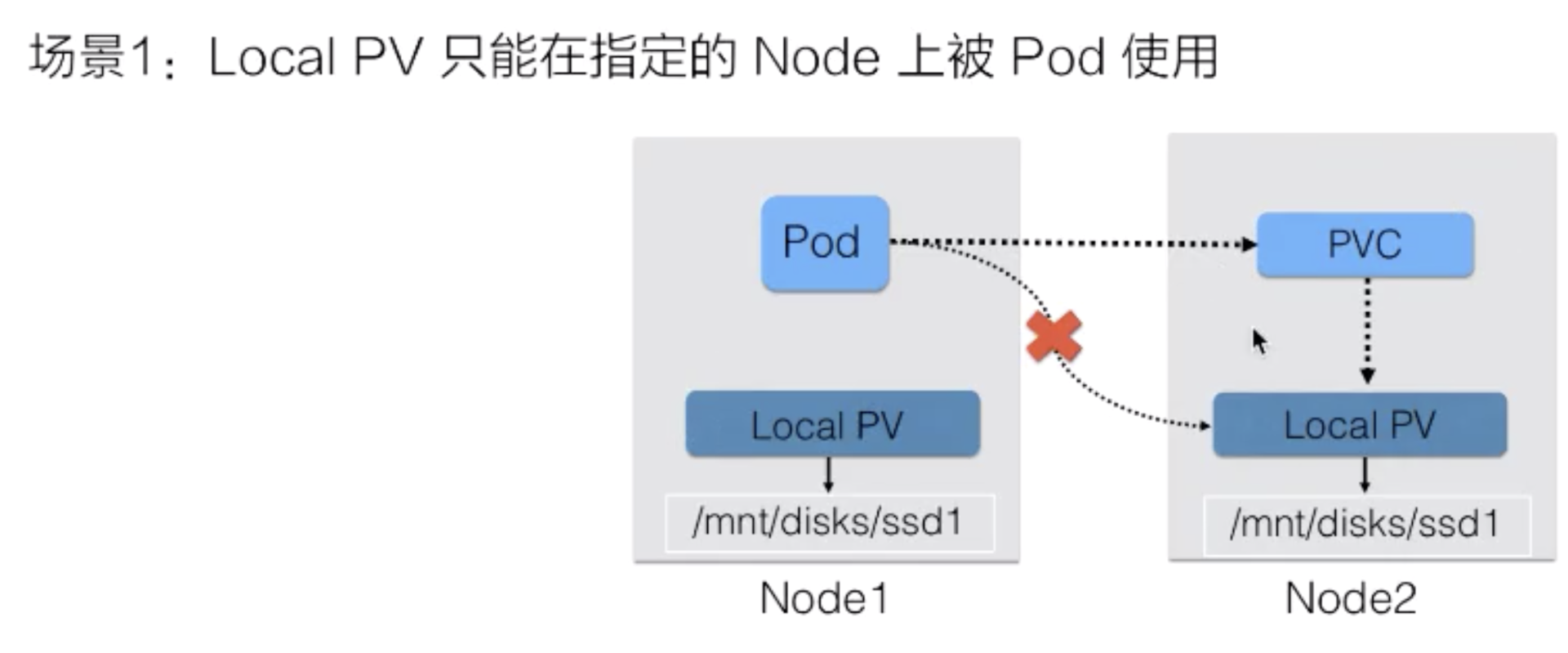
当用户在提交完 PVC 的时候,K8s PV controller可能绑定的是 node2 上面的 PV。但是,真正使用这个 PV 的 pod,在被调度的时候,有可能调度在 node1 上,最终导致这个 pod 在起来的时候没办法去使用这块存储,因为 pod 真实情况是要使用 node2 上面的存储。
第二个(如果不对 PV 做“访问位置”的限制会出问题的)场景:
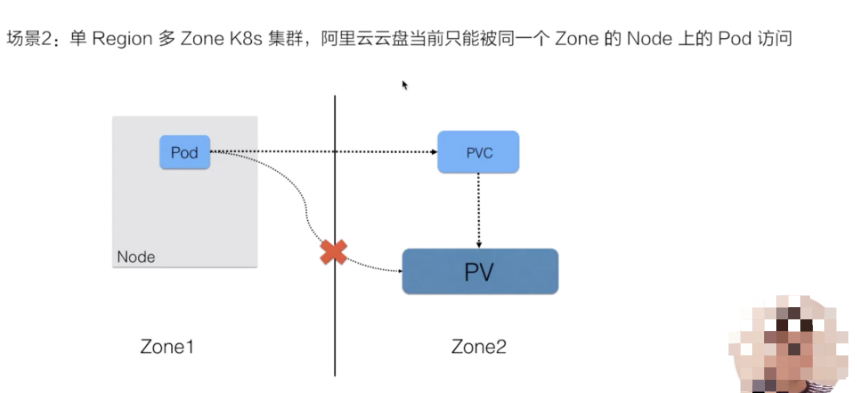
如果搭建的 K8s 集群管理的 nodes 分布在单个区域多个可用区内。在创建动态存储的时候,创建出来的存储属于可用区 2,但之后在提交使用该存储的 pod,它可能会被调度到可用区 1 了,那就可能没办法使用这块存储。因此像阿里云的云盘,也就是块存储,当前不能跨可用区使用,如果创建的存储其实属于可用区 2,但是 pod 运行在可用区 1,就没办法使用这块存储,这是第二个常见的问题场景。
接下来我们来看看 K8s 中如何通过存储拓扑调度来解决上面的问题的。
存储拓扑调度
首先总结一下之前的两个问题,它们都是 PV 在给 PVC 绑定或者动态生成 PV 的时候,我并不知道后面将使用它的 pod 将调度在哪些 node 上。但 PV 本身的使用,是对 pod 所在的 node 有拓扑位置的限制的,如 Local PV 场景是我要调度在指定的 node 上我才能使用那块 PV,而对第二个问题场景就是说跨可用区的话,必须要在将使用该 PV 的 pod 调度到同一个可用区的 node 上才能使用阿里云云盘服务,那 K8s 中怎样去解决这个问题呢?
简单来说,在 K8s 中将 PV 和 PVC 的 binding 操作和动态创建 PV 的操作做了 delay,delay 到 pod 调度结果出来之后,再去做这两个操作。这样的话有什么好处?
首先,如果要是所要使用的 PV 是预分配的,如 Local PV,其实使用这块 PV 的 pod 它对应的 PVC 其实还没有做绑定,就可以通过调度器在调度的过程中,结合 pod 的计算资源需求(如 cpu/mem) 以及 pod 的 PVC 需求,选择的 node 既要满足计算资源的需求又要 pod 使用的 pvc 要能 binding 的 pv 的 nodeaffinity 限制;
其次对动态生成 PV 的场景其实就相当于是如果知道 pod 运行的 node 之后,就可以根据 node 上记录的拓扑信息来动态的创建这个 PV,也就是保证新创建出来的 PV 的拓扑位置与运行的 node 所在的拓扑位置是一致的,如上面所述的阿里云云盘的例子,既然知道 pod 要运行到可用区 1,那之后创建存储时指定在可用区 1 创建即可。
为了实现上面所说的延迟绑定和延迟创建 PV,需要在 K8s 中的改动涉及到的相关组件有三个:
PV Controller 也就是 persistent volume controller,它需要支持延迟 Binding 这个操作。
- 另一个是动态生成 PV 的组件,如果 pod 调度结果出来之后,它要根据 pod 的拓扑信息来去动态的创建 PV。
第三组件,也是最重要的一个改动点就是 kube-scheduler。在为 pod 选择 node 节点的时候,它不仅要考虑 pod 对 CPU/MEM 的计算资源的需求,它还要考虑这个 pod 对存储的需求,也就是根据它的 PVC,它要先去看一下当前要选择的 node,能否满足能和这个 PVC 能匹配的 PV 的 nodeAffinity;或者是动态生成 PV 的过程,它要根据 StorageClass 中指定的拓扑限制来 check 当前的 node 是不是满足这个拓扑限制,这样就能保证调度器最终选择出来的 node 就能满足存储本身对拓扑的限制。
二、用例解读
Volume Snapshot/Restore示例

下面来看一下存储快照如何使用:首先需要集群管理员,在集群中创建 VolumeSnapshotClass 对象,VolumeSnapshotClass 中一个重要字段就是 Snapshot,它是指定真正创建存储快照所使用的卷插件,这个卷插件是需要提前部署的,稍后再说这个卷插件。
接下来用户他如果要做真正的存储快照,需要声明一个 VolumeSnapshotClass,VolumeSnapshotClass 首先它要指定的是 VolumeSnapshotClassName,接着它要指定的一个非常重要的字段就是 source,这个 source 其实就是指定快照的数据源是啥。这个地方指定 name 为 disk-pvc,也就是说通过这个 pvc 对象来创建存储快照。提交这个 VolumeSnapshot 对象之后,集群中的相关组件它会找到这个 PVC 对应的 PV 存储,对这个 PV 存储做一次快照。
有了存储快照之后,那接下来怎么去用存储快照恢复数据呢?这个其实也很简单,通过声明一个新的 PVC 对象并在它的 spec 下面的 DataSource 中来声明我的数据源来自于哪个 VolumeSnapshot,这里指定的是 disk-snapshot 对象,当我这个 PVC 提交之后,集群中的相关组件,它会动态生成新的 PV 存储,这个新的 PV 存储中的数据就来源于这个 Snapshot 之前做的存储快照。
Local PV 的示例
如下图看一下 Local PV 的 yaml 示例:

Local PV 大部分使用的时候都是通过静态创建的方式,也就是要先去声明 PV 对象,既然 Local PV 只能是本地访问,就需要在声明 PV 对象的,在 PV 对象中通过 nodeAffinity 来限制我这个 PV 只能在单 node 上访问,也就是给这个 PV 加上拓扑限制。如上图拓扑的 key 用 kubernetes.io/hostname 来做标记,也就是只能在 node1 访问。如果想用这个 PV,你的 pod 必须要调度到 node1 上。
既然是静态创建 PV 的方式,这里为什么还需要 storageClassname 呢?前面也说了,在 Local PV 中,如果要想让它正常工作,需要用到延迟绑定特性才行,那既然是延迟绑定,当用户在写完 PVC 提交之后,即使集群中有相关的 PV 能跟它匹配,它也暂时不能做匹配,也就是说 PV controller 不能马上去做 binding,这个时候你就要通过一种手段来告诉 PV controller,什么情况下是不能立即做 binding。这里的 storageClass 就是为了起到这个副作用,我们可以看到 storageClass 里面的 provisioner 指定的是 no-provisioner,其实就是相当于告诉 K8s 它不会去动态创建 PV,它主要用到 storageclass 的 VolumeBindingMode 字段,叫 WaitForFirstConsumer,可以先简单地认为它是延迟绑定。
当用户开始提交 PVC 的时候,pv controller 在看到这个 pvc 的时候,它会找到相应的 storageClass,发现这个 BindingMode 是延迟绑定,它就不会做任何事情。
之后当真正使用这个 pvc 的 pod,在调度的时候,当它恰好调度在符合 pv nodeaffinity 的 node 的上面后,这个 pod 里面所使用的 PVC 才会真正地与 PV 做绑定,这样就保证我 pod 调度到这台 node 上之后,这个 PVC 才与这个 PV 绑定,最终保证的是创建出来的 pod 能访问这块 Local PV,也就是静态 Provisioning 场景下怎么去满足 PV 的拓扑限制。
限制 Dynamic Provisioning PV 拓扑示例
再看一下动态 Provisioning PV 的时候,怎么去做拓扑限制的?

动态就是指动态创建 PV 就有拓扑位置的限制,那怎么去指定?
首先在 storageclass 还是需要指定 BindingMode,就是 WaitForFirstConsumer,就是延迟绑定。
其次特别重要的一个字段就是 allowedTopologies,限制就在这个地方。上图中可以看到拓扑限制是可用区的级别,这里其实有两层意思:
- 第一层意思就是说我在动态创建 PV 的时候,创建出来的 PV 必须是在这个可用区可以访问的;
第二层含义是因为声明的是延迟绑定,那调度器在发现使用它的 PVC 正好对应的是该 storageclass 的时候,调度 pod 就要选择位于该可用区的 nodes。
总之,就是要从两方面保证,一是动态创建出来的存储时要能被这个可用区访问的,二是我调度器在选择 node 的时候,要落在这个可用区内的,这样的话就保证我的存储和我要使用存储的这个 pod 它所对应的 node,它们之间的拓扑域是在同一个拓扑域,用户在写 PVC 文件的时候,写法是跟以前的写法是一样的,主要是在 storageclass 中要做一些拓扑限制。三、操作演示
本节将在线上环境来演示一下前面讲解的内容。
首先来看一下我的阿里云服务器上搭建的 K8s 服务。总共有 3 个 node 节点。一个 master 节点,两个 node。其中 master 节点是不能调度 pod 的。

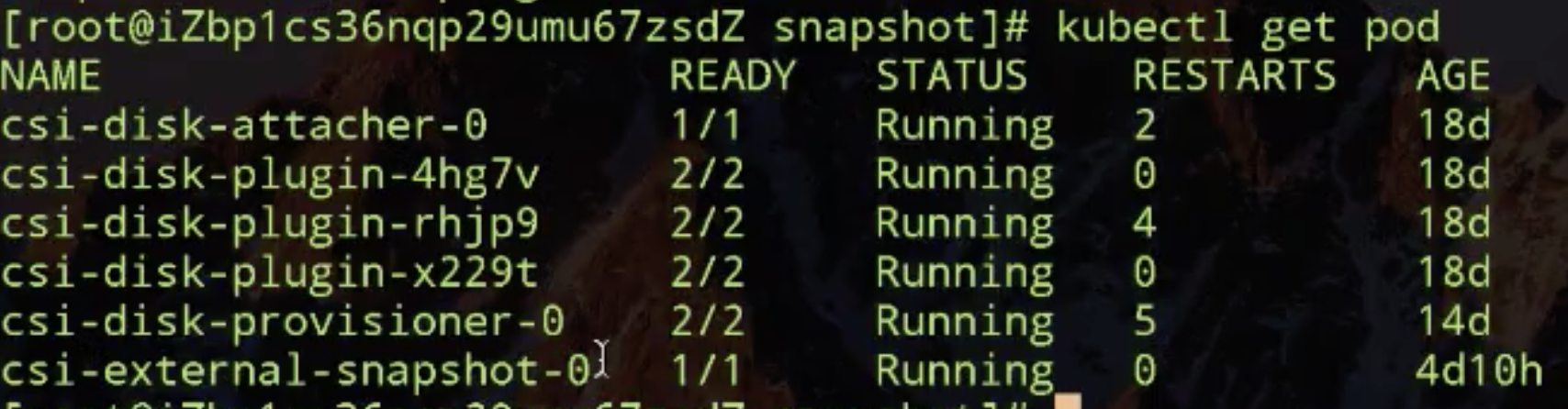
再看一下,我已经提前把我需要的插件已经布好了,一个是 snapshot 插件 (csi-external-snapshot),一个是动态云盘的插件 (csi-disk)。
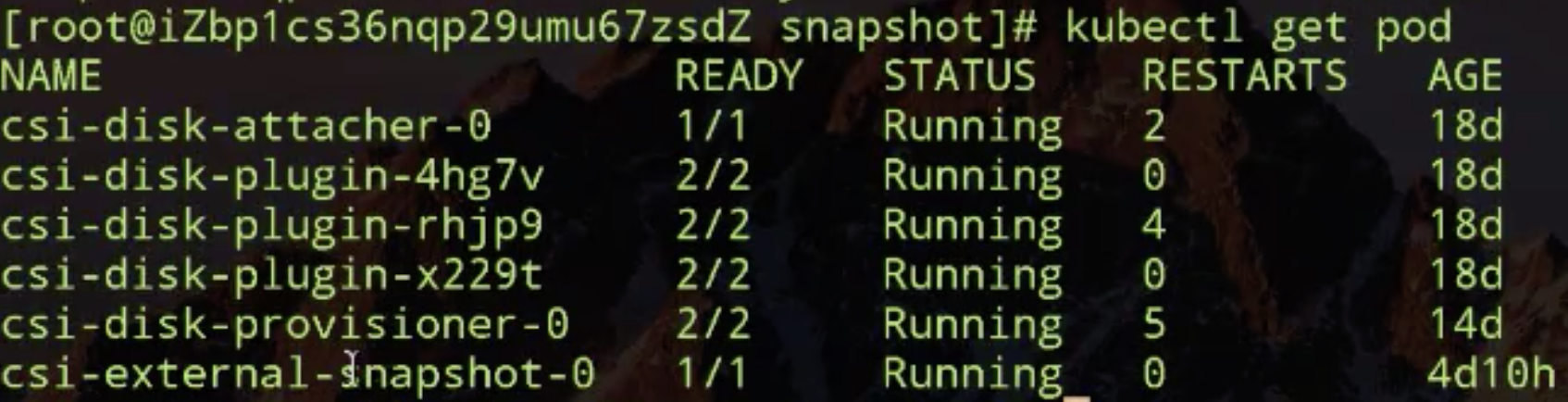
现在开始 snapshot 的演示。首先去动态创建云盘,然后才能做 snapshot。动态创建云盘需要先创建 storageclass,然后去根据 PVC 动态创建 PV,然后再创建一个使用它的 pod 了。
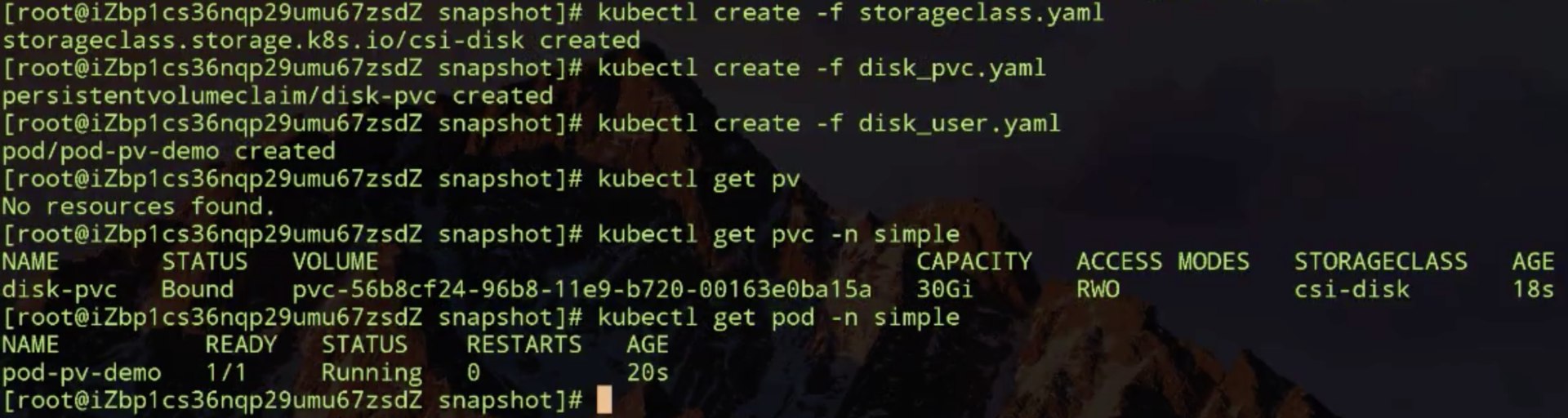
有个以上对象,现在就可以做 snapshot 了,首先看一下做 snapshot 需要的第一个配置文件:snapshotclass.yaml。

其实里面就是指定了在做存储快照的时候需要使用的插件,这个插件刚才演示了已经部署好了,就是 csi-external-snapshot-0 这个插件。
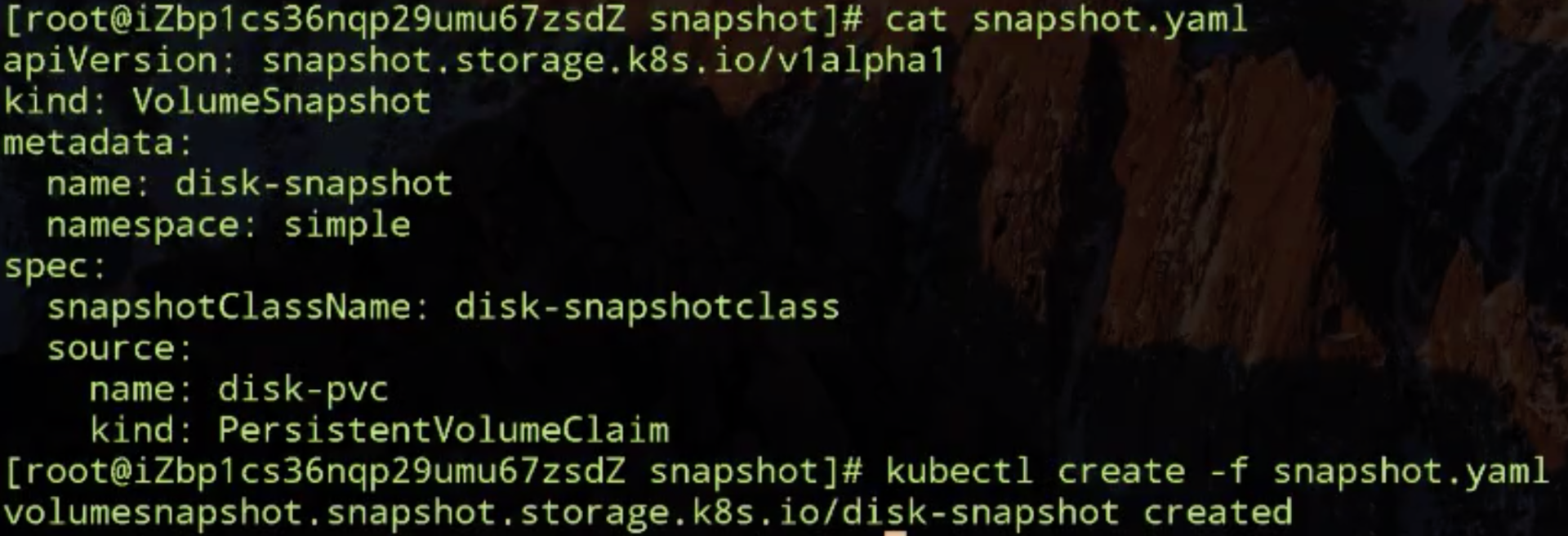
接下来创建 volume-snapshotclass 文件,创建完之后就开始了 snapshot。

然后看 snapshot.yaml,Volumesnapshot 声明创建存储快照了,这个地方就指定刚才创建的那个 PVC 来做的数据源来做 snapshot,那我们开始创建。
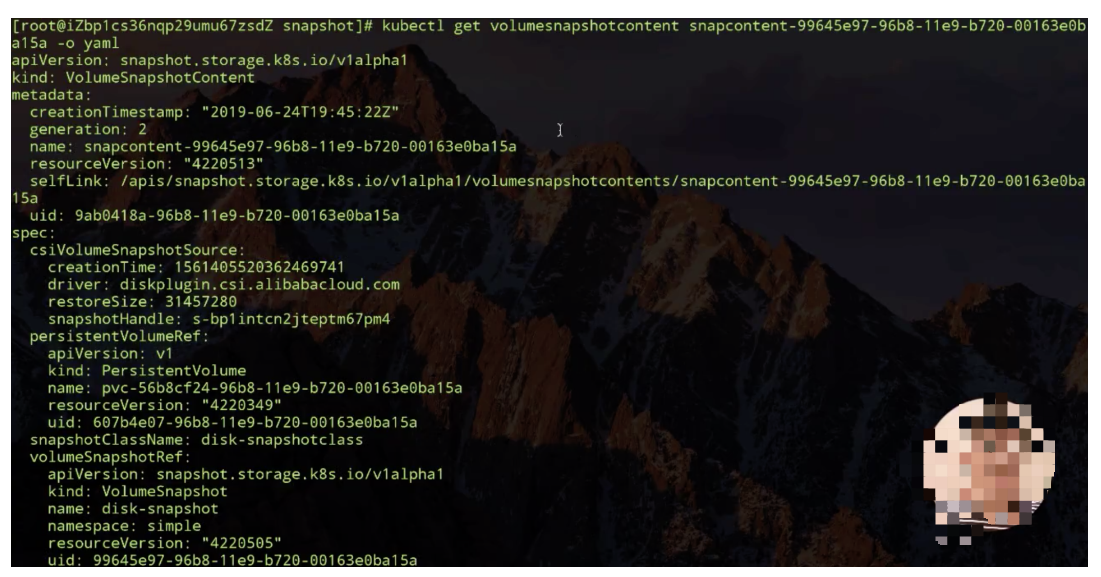
我们看一下 Snapshot 有没有创建好,如下图所示,content 已经在 11 秒之前创建好了。

可以看一下它里面的内容,主要看 volumesnapshotcontent 记录的一些信息,这个是我 snapshot 出来之后,它记录的就是云存储厂商那边返回给我的 snapshot 的 ID。然后是这个 snapshot 数据源,也就是刚才指定的 PVC,可以通过它会找到对应的 PV。
snapshot 的演示大概就是这样,把刚才创建的 snapshot 删掉,还是通过 volumesnapshot 来删掉。然后看一下,动态创建的这个 volumesnapshotcontent 也被删掉。

接下来看一下动态 PV 创建的过程加上一些拓扑限制,首先将的 storageclass 创建出来,然后再看一下 storageclass 里面做的限制,storageclass 首先还是指定它的 BindingMode 为 WaitForFirstConsumer,也就是做延迟绑定,然后是对它的拓扑限制,我这里面在 allowedTopologies 字段中配置了一个可用区级别的限制。

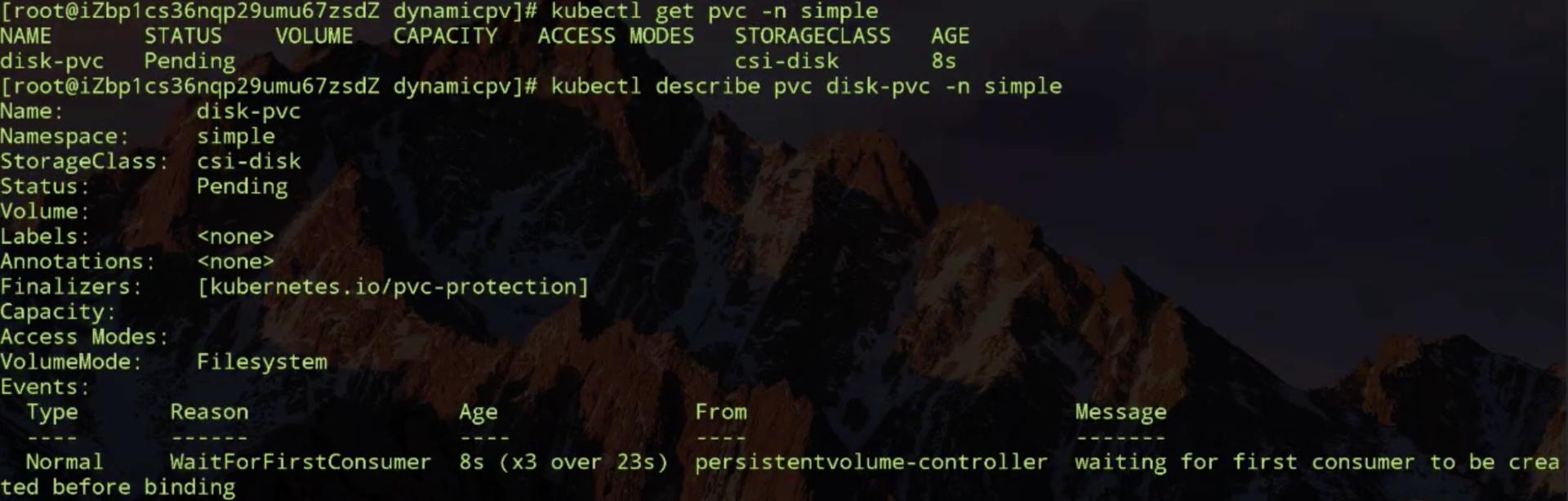
来尝试创建一下的 PVC,PVC 创建出来之后,理论上它应该处在 pending 状态。看一下,它现在因为它要做延迟绑定,由于现在没有使用它的 pod,暂时没办法去做绑定,也没办法去动态创建新的 PV。
接下来创建使用该 pvc 的 pod 看会有什么效果,看一下 pod,pod 也处在 pending了。
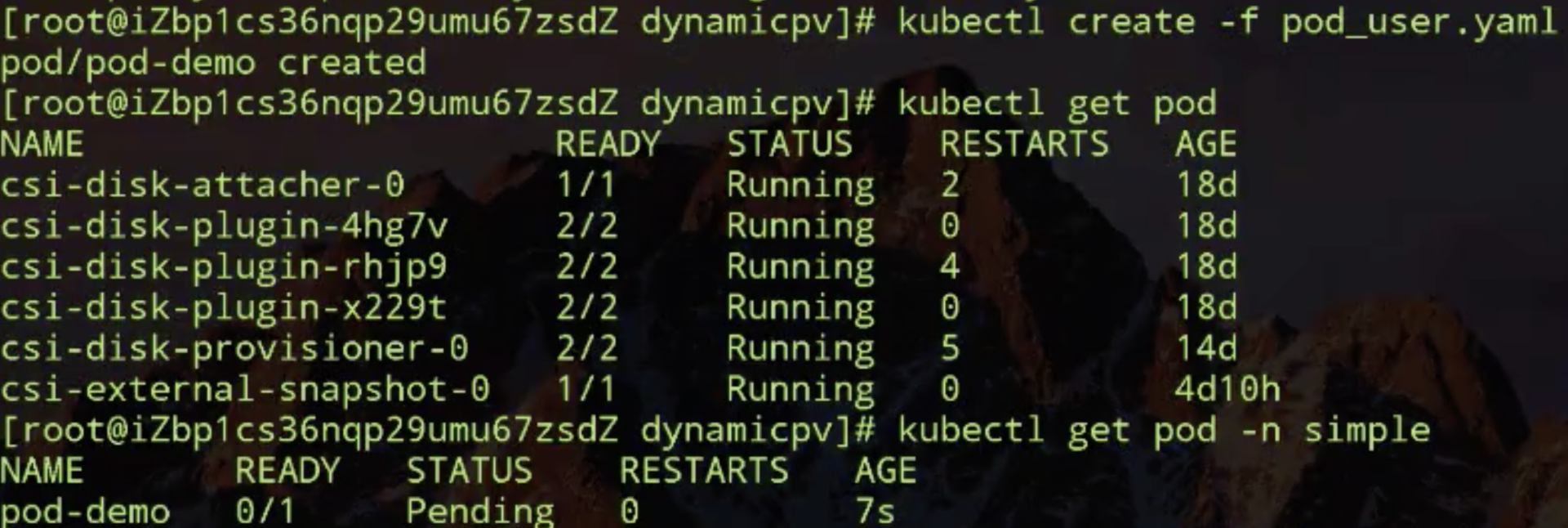
那来看一下 pod 为啥处在 pending 状态,可以看一下是调度失败了,调度失败原因:一个 node 由于 taint 不能调度,这个其实是 master,另外两个 node 也是没有说是可绑定的 PV。

为什么会有两个 node 出现没有可绑定的 pv 的错误?不是动态创建么?
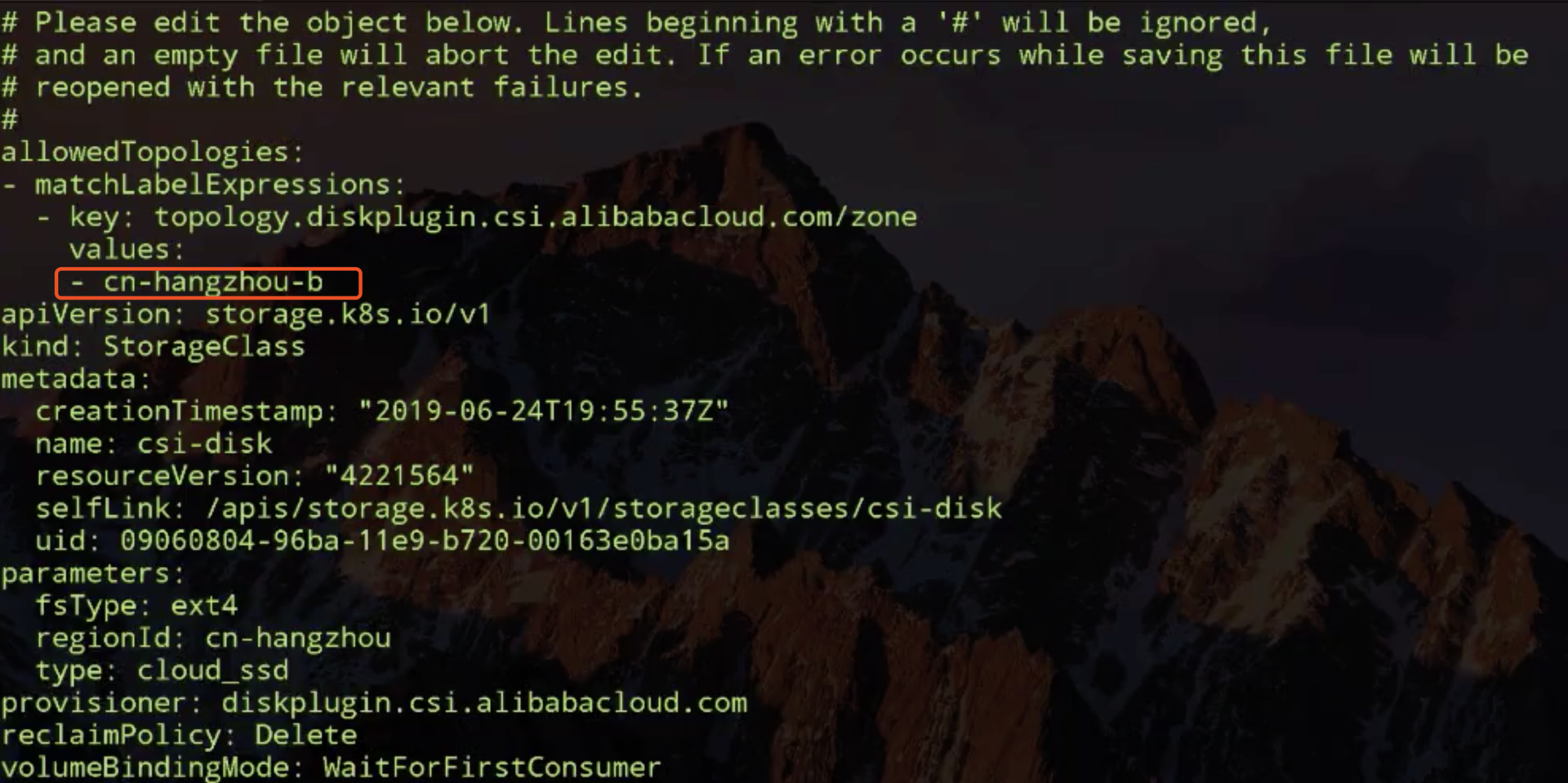
我们来仔细看看 storageclass 中的拓扑限制,通过上面的讲解我们知道,这里限制使用该 storageclass 创建的 PV 存储必须在可用区 cn-hangzhou-d 可访问的,而使用该存储的 pod 也必须调度到 cn-hangzhou-d 的 node 上。

那就来看一下 node 节点上有没有这个拓扑信息,如果它没有当然是不行了。
看一下第一个 node 的全量信息吧,主要找它的 labels 里面的信息,看 lables 里面的确有一个这样的 key。也就是说有一个这样的拓扑,但是这指定是 cn-hangzhou-b,刚才 storageclass 里面指定的是 cn-hangzhou-d。

那看一下另外的一个 node 上的这个拓扑信息写的也是 hangzhou-b,但是我们那个 storageclass 里面限制是 d。

这就导致最终没办法将 pod 调度在这两个 node 上。现在我们修改一下 storageclass 中的拓扑限制,将 cn-hangzhou-d 改为 cn-hangzhou-b。
改完之后再看一下,其实就是说我动态创建出来的 PV 要能被 hangzhou-b 这个可用区访问的,使用该存储的 pod 要调度到该可用区的 node 上。把之前的 pod 删掉,让它重新被调度看一下有什么结果,好,现在这个已经调度成功了,就是已经在启动容器阶段。
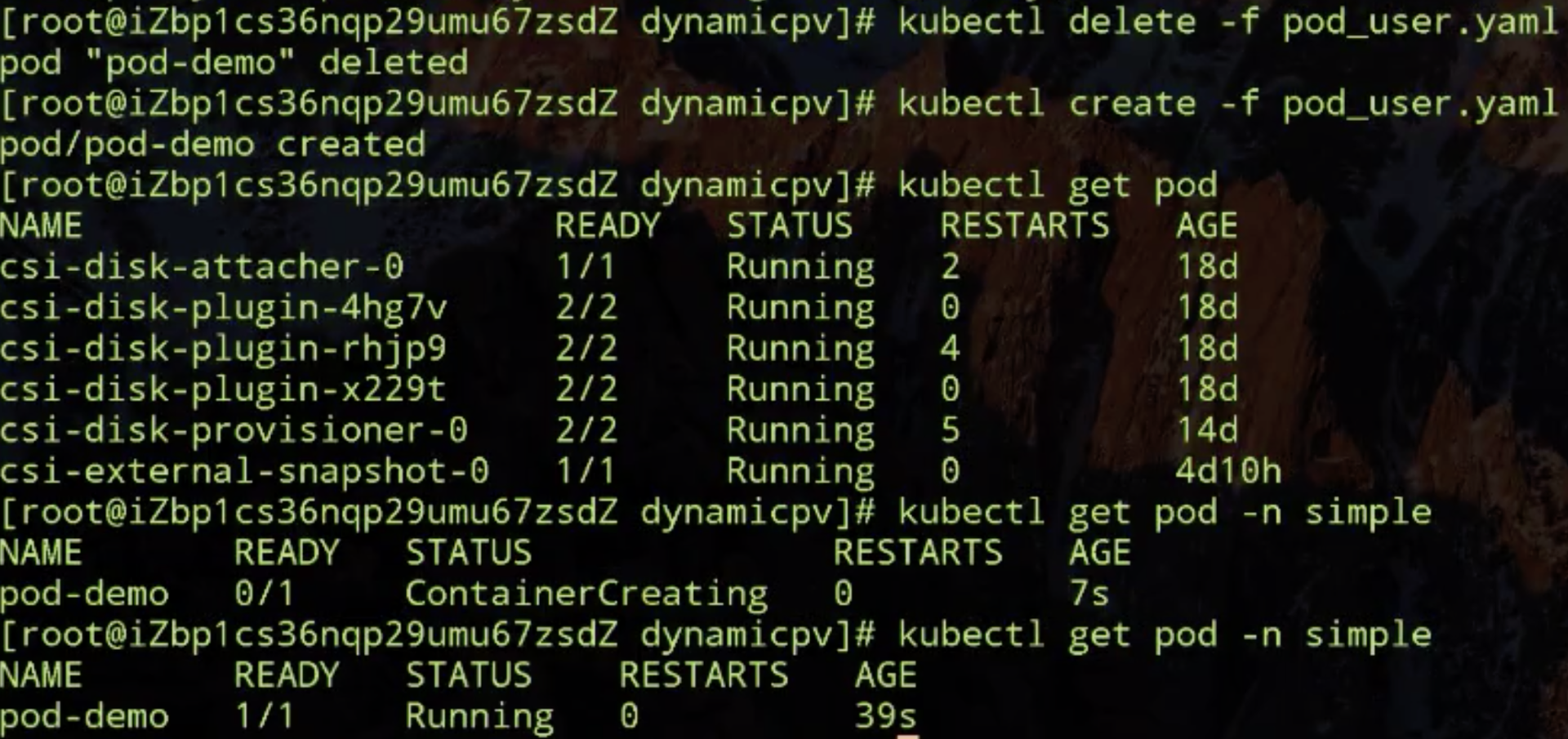
说明刚才把 storageclass 它里面的对可用区的限制从 hangzhou-d 改为 hangzhou-b 之后,集群中就有两个 node,它的拓扑关系是和 storageclass 里要求的拓扑关系是相匹配的,这样的话它就能保证它的 pod 是有 node 节点可调度的。上图中最后一点 Pod 已经 Running 了,说明刚才的拓扑限制改动之后可以 work 了。
四、处理流程
kubernetes 对 Volume Snapshot/Restore 处理流程
接下来看一下 K8s 中对存储快照与拓扑调度的具体处理流程。如下图所示:
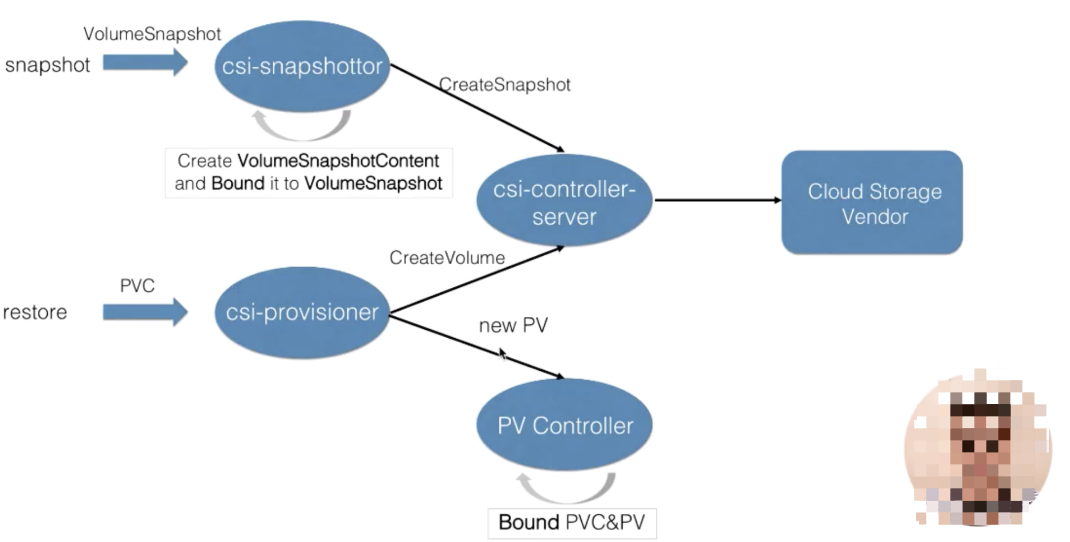
首先来看一下存储快照的处理流程,这里来首先解释一下 csi 部分。K8s 中对存储的扩展功能都是推荐通过 csi out-of-tree 的方式来实现的。
csi 实现存储扩展主要包含两部分:
- 第一部分是由 K8s 社区推动实现的 csi controller 部分,也就是这里的 csi-snapshottor controller 以及 csi-provisioner controller,这些主要是通用的 controller 部分;
另外一部分是由特定的云存储厂商用自身 OpenAPI 实现的不同的 csi-plugin 部分,也叫存储的 driver 部分。
两部分部件通过 unix domain socket 通信连接到一起。有这两部分,才能形成一个真正的存储扩展功能。
如上图所示,当用户提交 VolumeSnapshot 对象之后,会被 csi-snapshottor controller watch 到。之后它会通过 GPPC 调用到 csi-plugin,csi-plugin 通过 OpenAPI 来真正实现存储快照的动作,等存储快照已经生成之后,会返回到 csi-snapshottor controller 中,csi-snapshottor controller 会将存储快照生成的相关信息放到 VolumeSnapshotContent 对象中并将用户提交的 VolumeSnapshot 做 bound。这个 bound 其实就有点类似 PV 和 PVC 的 bound 一样。
有了存储快照,如何去使用存储快照恢复之前的数据呢?前面也说过,通过声明一个新的 PVC 对象,并且指定他的 dataSource 为 Snapshot 对象,当提交 PVC 的时候会被 csi-provisioner watch 到,之后会通过 GRPC 去创建存储。这里创建存储跟之前讲解的 csi-provisioner 有一个不太一样的地方,就是它里面还指定了 Snapshot 的 ID,当去云厂商创建存储时,需要多做一步操作,即将之前的快照数据恢复到新创建的存储中。之后流程返回到 csi-provisioner,它会将新创建的存储的相关信息写到一个新的 PV 对象中,新的 PV 对象被 PV controller watch 到它会将用户提交的 PVC 与 PV 做一个 bound,之后 pod 就可以通过 PVC 来使用 Restore 出来的数据了。这是 K8s 中对存储快照的处理流程。
kubernetes 对 Volume Topology-aware Scheduling 处理流程
接下来看一下存储拓扑调度的处理流程:
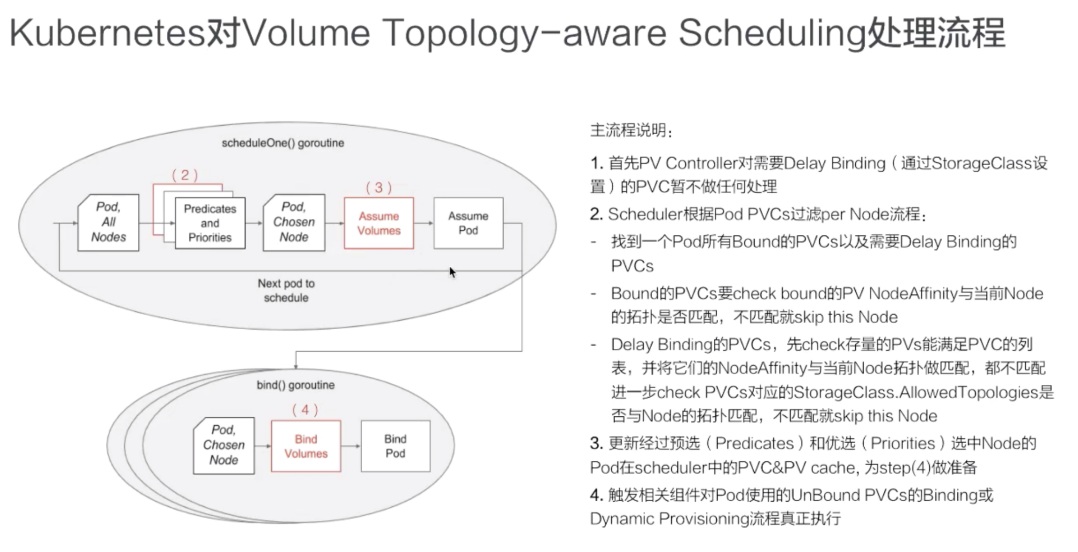
第一个步骤其实就是要去声明延迟绑定,这个通过 StorageClass 来做的,上面已经阐述过,这里就不做详细描述了。
接下来看一下调度器,上图中红色部分就是调度器新加的存储拓扑调度逻辑,我们先来看一下不加红色部分时调度器的为一个 pod 选择 node 时,它的大概流程:
首先用户提交完 pod 之后,会被调度器 watch 到,它就会去首先做预选,预选就是说它会将集群中的所有 node 都来与这个 pod 它需要的资源做匹配;
- 如果匹配上,就相当于这个 node 可以使用,当然可能不止一个 node 可以使用,最终会选出来一批 node;
- 然后再经过第二个阶段优选,优选就相当于我要对这些 node 做一个打分的过程,通过打分找到最匹配的一个 node;
之后调度器将调度结果写到 pod 里面的 spec.nodeName 字段里面,然后会被相应的 node 上面的 kubelet watch 到,最后就开始创建 pod 的整个流程。
那现在看一下加上卷相关的调度的时候,筛选 node(第二个步骤)又是怎么做的?
先就要找到 pod 中使用的所有 PVC,找到已经 bound 的 PVC,以及需要延迟绑定的这些 PVC;
- 对于已经 bound 的 PVC,要 check 一下它对应的 PV 里面的 nodeAffinity 与当前 node 的拓扑是否匹配 。如果不匹配, 就说明这个 node 不能被调度。如果匹配,继续往下走,就要去看一下需要延迟绑定的 PVC;
对于需要延迟绑定的 PVC。先去获取集群中存量的 PV,满足 PVC 需求的,先把它全部捞出来,然后再将它们一一与当前的 node labels 上的拓扑做匹配,如果它们(存量的 PV)都不匹配,那就说明当前的存量的 PV 不能满足需求,就要进一步去看一下如果要动态创建 PV 当前 node 是否满足拓扑限制,也就是还要进一步去 check StorageClass 中的拓扑限制,如果 StorageClass 中声明的拓扑限制与当前的 node 上面已经有的 labels 里面的拓扑是相匹配的,那其实这个 node 就可以使用,如果不匹配,说明该 node 就不能被调度。
经过这上面步骤之后,就找到了所有即满足 pod 计算资源需求又满足 pod 存储资源需求的所有 nodes。
当 node 选出来之后,第三个步骤就是调度器内部做的一个优化。这里简单过一下,就是更新经过预选和优选之后,pod 的 node 信息,以及 PV 和 PVC 在 scheduler 中做的一些 cache 信息。
第四个步骤也是重要的一步,已经选择出来 node 的 Pod,不管其使用的 PVC 是要 binding 已经存在的 PV,还是要做动态创建 PV,这时就可以开始做。由调度器来触发,调度器它就会去更新 PVC 对象和 PV 对象里面的相关信息,然后去触发 PV controller 去做 binding 操作,或者是由 csi-provisioner 去做动态创建流程。
五、总结
- 通过对比 PVC&PV 体系讲解了存储快照的相关 K8s 资源对象以及使用方法;
- 通过两个实际场景遇到的问题引出存储拓扑调度功能必要性,以及 K8s 中如何通过拓扑调度来解决这些问题;
- 通过剖析 K8s 中存储快照和存储拓扑调度内部运行机制,深入理解该部分功能的工作原理。

若有收获,就点个赞吧
0 人点赞
