一、Babel处理流程
babel的处理流程如下图:


1、词法解析
词法解析器(Tokenizer)在这个阶段将字符串形式的代码转换成Tokens(令牌)。Tokens可以视作是一些语法片段组成的数组。例如for (const item of items) { },词法解析后的结果如下图:

2、语法解析
语法解析这个阶段语法解析器(Parser)会把Tokens转换为抽象语树(AST)。AST它是一棵对象树,用来表示代码的语法结构。例如console.log(‘hello world’)会解析为如下图片内容:

Program、CallExpression、Identifier这些都是节点的类型,这些节点类型定义了一些属性来描述节点信息。AST是Babel转移的核心数据结构,后续的操作都是基于AST。
3、转换和生成
转换(transform)阶段会对AST语法树进行遍历,在这个过程中会对节点进行增删改查的操作。所有的Babel插件都是工作在这个时间段的,比如语法转换、压缩代码。最后阶段会将AST语法树转换成字符串形式的Javascript代码,同时这个阶段还会生成sourceMap。
二、Babel架构
Babel为适应复杂的定制需求和频繁的功能变化,都使用了微内核的架构风格。也就说babel的内核非常小,大部分功能都是通过插件扩展实现的。下图为babe的基本机构图:
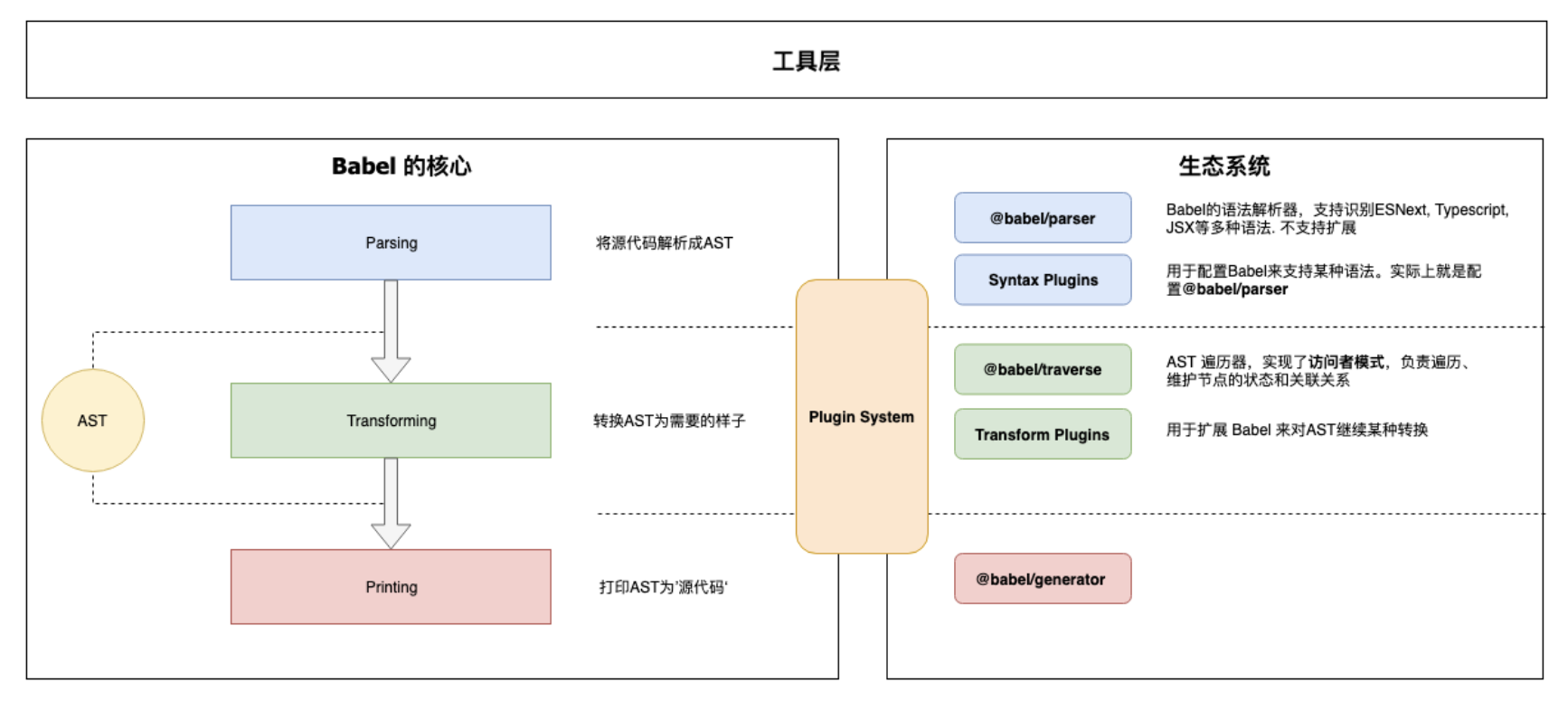
1、babel核心(@babel/core)
@babel/core就是微内核架构中的内核,对于babel来说这个内核主要干了如下几件事:
- 加载和处理配置参数。
- 加载插件。
- 调用Parser进行词法分析和语法分析,生成AST语法树。
- 调用Traverser遍历语法树,并使用访问者模式应用插件对AST语法树进行转换。
-
2、核心周边支撑
Parser(@babel/core):将源代码解析为AST。它内置了支持了许多语法。
- Traverser(@babel/traverse):实现了访问者模式,对AST语法树进行遍历,转换插件会获取他对应的AST节点,对节点继续操作,下文会详细介绍访问者模式。
Generator(@babel/generator):将AST语法树转换成源代码,并生成SourceMap。
3、插件
语法插件(@babel/plugin-syntax-*):@babel/parser已经支持了很多javascript的新特性,Parser也不支持扩展。因此syntax-plugin插件就是用于开启或者配置Parser的某个功能的特性。
- 转换插件:对AST语法树进行转换,实现转换为ES5代码、压缩、功能增强等目的。babel将转换插件分成两种(只有命名上的区别):@babel/plugin-transform-为普通的转译插件,@babel/plugin-prpposal-为提案阶段的插件。
预定义集合(@babel/presets-*):插件集合或者分组,主要方便用户对插件进行管理和使用。比如preset-env包含所有的标准的最新特性。
4、插件开发辅助
@babel/template:某些场景直接操作AST语法树太麻烦,所以babel实现了一个模版引擎,可以将字符串专成AST语法树。
@babel/types:AST节点构造器和断言,插件开发时使用频繁。
三、访问者模式
转换器遍历AST语法树,找出自己能够匹配的节点类型,在进行转换操作。这个过程和我们操作DOM树差不多,只不过目的不太一样。AST遍历和转化一般会使用访问者模式。
转换器操作AST都会使用访问者模式,有这个访问者能进行以下操作:
进行统一的遍历操作。
- 提供节点的操作方法。
响应式维护节点之间的关系,而插件只需要定义自己感兴趣的节点类型,当访问者访问到对应的节点时,就会调用插件的访问方法。
1、节点的遍历
假设我们的代码如下:
function hello(v) {console.log('hello' + v + '!')}
以上代码被解析成AST树的结构如下:
FileProgram (program)FunctionDeclaration (body)Identifier (id) #helloIdentifier (params[0]) #vBlockStatement (body)ExpressionStatement ([0])CallExpression (expression)MemberExpression (callee) #console.logIdentifier (object) #consoleIdentifier (property) #logBinaryExpression (arguments[0])BinaryExpression (left)StringLiteral (left) #'hello'Identifier (right) #vStringLiteral (right) #'!'
访问者会以深度优先的顺序,或者说是递归的方式对AST进行遍历。我们可以通过以下的方式获取AST节点的信息:
const babel = require('@babel/core')const traverse = require('@babel/traverse').defaultconst ast = babel.parseSync(code)let depth = 0traverse(ast, {enter(path) {console.log(`enter ${path.type}(${path.key})`)depth++},exit(path) {depth--console.log(` exit ${path.type}(${path.key})`)}})
当访问者进入第一个节点时就会调用enter方法,反之当离开的时候就会调用exit方法。一般情况下,插件不会直接使用enter方法,只是关注少数的几个类型,所以具体的访问者的声明访问方法如下:
traverse(ast, {Identifier(path) { // 访问标识符console.log(`enter Identifier`)},CallExpression(path) { // 访问调用表达式console.log(`enter CallExpression`)},// 上面是enter的简写,如果要处理exit,也可以这样BinaryExpression: { // 二元操作符enter(path) {},exit(path) {},},"ExportNamedDeclaration|Flow"(path) {} // 更高级的, 使用同一个方法访问多种类型的节点})
babel插件会按照定义的顺序来应用访问,当进入一个节点的时候,这些插件会按照注册的顺序执行。大部分插件不关心定义的顺序,只有少数插件之中有相互依赖的关系需要注意先后顺序。
{"plugins": [// 必须在plugin-proposal-class-properties之前"@babel/plugin-proposal-decorators","@babel/plugin-proposal-class-properties"]}
2、节点的上下文
访问者在访问第一个节点时,会无差别的调用enter方法,每个visit方法都接收一个path对象,可以将它当作一个上下文对象,它里面包含了很多信息。
当前节点信息。
- 节点关联信息。父节点、子节点、兄弟节点信息等。
- 作用域信息。
- 上下文信息。
- 节点操作的方法。节点的增删改查。
- 断言方法。
下面是它的主要结构信息:
export class NodePath<T = Node> {constructor(hub: Hub, parent: Node);parent: Node;hub: Hub;contexts: TraversalContext[];data: object;shouldSkip: boolean;shouldStop: boolean;removed: boolean;state: any;opts: object;skipKeys: object;parentPath: NodePath;context: TraversalContext;container: object | object[];listKey: string; // 如果节点在一个数组中,这个就是节点数组的键inList: boolean;parentKey: string;key: string | number; // 节点所在的键或索引node: T; // 🔴 当前节点scope: Scope; // 🔴当前节点所在的作用域type: T extends undefined | null ? string | null : string; // 🔴节点类型typeAnnotation: object;// ... 还有很多方法,实现增删查改}
3、副作用的处理
实际上访问者的工作比我们想象中的复杂的多。AST转换本身是有副作用的,比如插件将旧节点替换了,那么访问者就没必要再向下访问旧节点了,而是继续访问新的节点,代码如下:
traverse(ast, {ExpressionStatement(path) {// 将 `console.log('hello' + v + '!')` 替换为 `return ‘hello’ + v`const rtn = t.returnStatement(t.binaryExpression('+', t.stringLiteral('hello'), t.identifier('v')))path.replaceWith(rtn)},}
我们可以对AST进行任意的操作,比如删除节点等等操作。这些操作污染了AST树后,访问者需要记录这些状态,更新path对象的关联关系,保证正确的遍历顺序,从而获取正确的结果。
4、作用域的处理
访问者可以确保正确地遍历和修改节点,但是对于转换器来说,另一个比较棘手的是对作用域的处理。插件开发者必须非常谨慎地处理作用域,不能破坏现有代码的执行逻辑。
这就是转换器需要考虑的作用域问题,AST 转换的前提是保证程序的正确性。 我们在添加和修改引用时,需要确保与现有的所有引用不冲突。Babel本身不能检测这类异常,只能依靠插件开发者谨慎处理。
Javascript采用的是词法作用域, 也就是根据源代码的词法结构来确定作用域:
在词法区块(block)中,由于新建变量、函数、类、函数参数等创建的标识符,都属于这个区块作用域. 这些标识符也称为绑定(Binding),而对这些绑定的使用称为引用(Reference)。
在Babel中,使用Scope对象来表示作用域。 我们可以通过Path对象的scope字段来获取当前节点的Scope对象。
Scope 对象和 Path 对象差不多,它包含了作用域之间的关联关系(通过parent指向父作用域),收集了作用域下面的所有绑定(bindings), 另外还提供了丰富的方法来对作用域仅限操作。
我们可以通过bindings属性获取当前作用域下的所有绑定(即标识符)。

若有收获,就点个赞吧
0 人点赞
