基本介绍
字典树又称Trie树,前缀树(事实上前缀树这个名字就很好的解释了Trie的储存方式)。
这是一种树形结构,典型用于统计、排序、和保存大量字符串。所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
一个字典树的应用场景:在搜索框输入部分单词下面会有一些神关联的搜索内容,你有时候都很神奇是怎么做到的,这其实就是字典树的一个思想。
来一张图理解一下Trie的储存方式: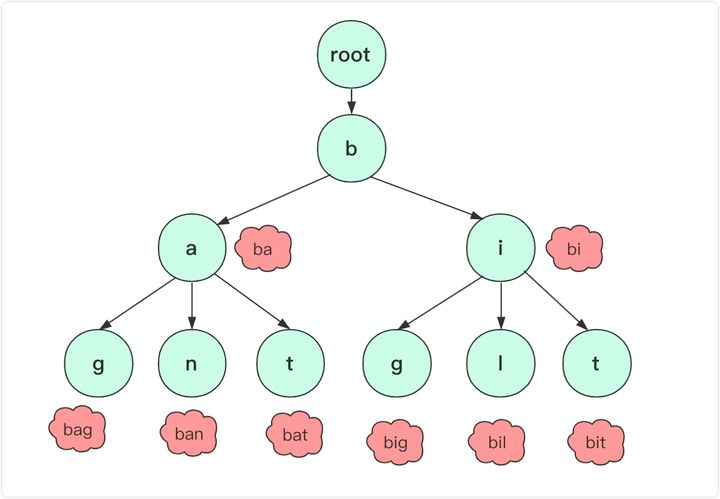
字典树有以下几个性质:
- 根节点不包含字符,除了根节点每个节点都只包含一个字符。可以把root节点理解成一个哨兵节点。
- 从根节点到某一个叶子节点,路过字符串起来就是该节点对应的字符串。
- 每个节点的子节点字符不同,也就是找到对应单词、字符是唯一的。
常见操作
我们假定字典树存的只有26个小写英文字母组成的字符串。首先定义Trie树节点结构体:
typedef struct ss{int son[27];} node;node trie[NMAX]; //存储所有字典树的节点int total_node = 0; //节点总数(不算根节点)
Trie树两个常见操作:插入和查找(删除实在少见,就不讲了)。
插入
代码如下:
void insert(const char[] str){int pos = 0, len = strlen(str);for(int i = 0; i < len; i++){if(!trie[pos].son[str[i] - 'a'])trie[pos].son[str[i] - 'a'] = ++total_node;pos = trie[pos].son[str[i] - 'a'];}}
从根节点开始,我们遍历待插入的字符串 。对于当前被遍历到的字符
。对于当前被遍历到的字符 ,我们定位到当前节点
,我们定位到当前节点 的子节点在
的子节点在 节点数组的下标
节点数组的下标 ,如果下标有效(不为0),那么说明字符串当前字符已经存在,可继续往下遍历,更新
,如果下标有效(不为0),那么说明字符串当前字符已经存在,可继续往下遍历,更新 ;否则,则说明字符串当前字符不存在需要插入,给当前树节点
;否则,则说明字符串当前字符不存在需要插入,给当前树节点 设置新的子节点位置
设置新的子节点位置 并更新
并更新 。
。
查找
代码如下:
void insert(const char[] str){int pos = 0, len = strlen(str);for(int i = 0; i < len; i++){if(!trie[pos].son[str[i] - 'a'])return false;pos = trie[pos].son[str[i] - 'a'];}return true;}
和插入代码唯一的不同:对于某个当前被遍历到的字符 ,如果当前节点
,如果当前节点 对应子节点下标
对应子节点下标 为0,说明子节点不存在,即待查找的字符串不存在,直接返回false。
为0,说明子节点不存在,即待查找的字符串不存在,直接返回false。
例题
原题链接
AC代码:
#include <iostream>#include <cstring>using namespace std;typedef struct ss{int son[27];int num; //字符串最后一个字符对应节点的num表示被搜索的次数} node;node trie[500000];int total_node = 0;void insert(const char str[]){int pos = 0, len = strlen(str);for(int i = 0; i < len; i++){if(!trie[pos].son[str[i] - 'a'])trie[pos].son[str[i] - 'a'] = ++total_node;pos = trie[pos].son[str[i] - 'a'];}}int search(const char str[]){int pos = 0, len = strlen(str);for(int i = 0; i < len; i++){if(!trie[pos].son[str[i] - 'a']) return 0;pos = trie[pos].son[str[i] - 'a'];}return ++trie[pos].num;}int main(void){char str[51];int n, m;scanf("%d", &n);for(int i = 0; i < n; i++){scanf("%s", str);insert(str);}scanf("%d", &m);for(int i = 0; i < m; i++){scanf("%s", str);int ans = search(str);if(ans == 0) printf("WRONG\n");if(ans == 1) printf("OK\n");if(ans >= 2) printf("REPEAT\n");}return 0;}

若有收获,就点个赞吧
0 人点赞
