纲领篇总结的二叉树解题总纲:
二叉树解题的思维模式分两类: 1、是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。 2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。 无论使用哪种思维模式,你都需要思考: 如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
思路篇(114、116、226、剑指27)讲的是「遍历」和「分解问题」两种思路,本文讲的是二叉树的构造类问题。
二叉树的构造类问题,一般用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。
654. 最大二叉树
每个节点都可以认为是一个子树的根节点,对于根节点,首先是想办法把自己构造出来,然后再构造自己的左右子树。
所以,首先遍历数组找到最大值 maxVal, 从而把根节点root做出来 ,然后对 maxVal 左边的数组和右边的数组进行递归构建,作为 root 的左右子树。
当前 nums 中的最大值就是根节点,然后根据索引递归调用左右数组构造左右子树即可。
明确了思路,我们可以重新写一个辅助函数 build,来控制 nums 的索引
//主函数public TreeNode constructMaximumBinaryTree(int[] nums) {return build(nums, 0, nums.length-1);}//定义:将nums[lo..hi]构成符合条件的树,返回根节点TreeNode build(int[] nums, int lo, int hi){//base caseif(lo > hi) return null;//找到数组中最大值和对应的索引int index = -1;int maxVal = Integer.MIN_VALUE;for(int i = lo; i <= hi; i++){if(maxVal < nums[i]){index = i;maxVal = nums[i];}}//先构造出根节点TreeNode root = new TreeNode(maxVal);//递归构造左右子树root.left = build(nums, lo, index-1);root.right = build(nums, index+1, hi);return root;}
105. 从前序与中序遍历序列构造二叉树
首先思考,根节点应该做什么。类似上一题,我们要先确定根节点的值,把根节点构造出来,然后递归构造左右子树即可。
先回归一下,前序遍历和中序遍历的特点。
前序遍历数组的第一个元素就是根节点。
中序遍历的代码是写在traverse(root.left)和traverse(root.right)中间。
void traverse(TreeNode root) {// 前序遍历preorder.add(root.val);traverse(root.left);traverse(root.right);}void traverse(TreeNode root) {traverse(root.left);// 中序遍历inorder.add(root.val);traverse(root.right);}
因为遍历的顺序不同,导致前序和中序数组的元素分布有如下的特点:
找到根节点是很简单的,前序遍历的第一个值 preorder[1] 就是根节点的值。
但是如何将 preorder 和 inorder 数组划分成两半,构造根节点的左右子树。
// 存储 inorder 中值到索引的映射HashMap<Integer, Integer> valToIndex = new HashMap<>();/* 主函数 */public TreeNode buildTree(int[] preorder, int[] inorder) {// 根据函数定义,用 preorder 和 inorder 构造二叉树return build(preorder, 0, preorder.length - 1,inorder, 0, inorder.length - 1);}/*build 函数的定义:若前序遍历数组为 preorder[preStart..preEnd],中序遍历数组为 inorder[inStart..inEnd],构造二叉树,返回该二叉树的根节点*/TreeNode build(int[] preorder, int preStart, int preEnd,int[] inorder, int inStart, int inEnd) {// root 节点对应的值就是前序遍历数组的第一个元素int rootVal = preorder[preStart];// 避免 for 循环寻找 rootValint index = valToIndex.get(rootVal);TreeNode root = new TreeNode(rootVal);// 递归构造左右子树root.left = build(preorder, ?, ?,inorder, ?, ?);root.right = build(preorder, ?, ?,inorder, ?, ?);return root;}
对于代码中的 rootVal 和 index 变量,就是下面的图的情况: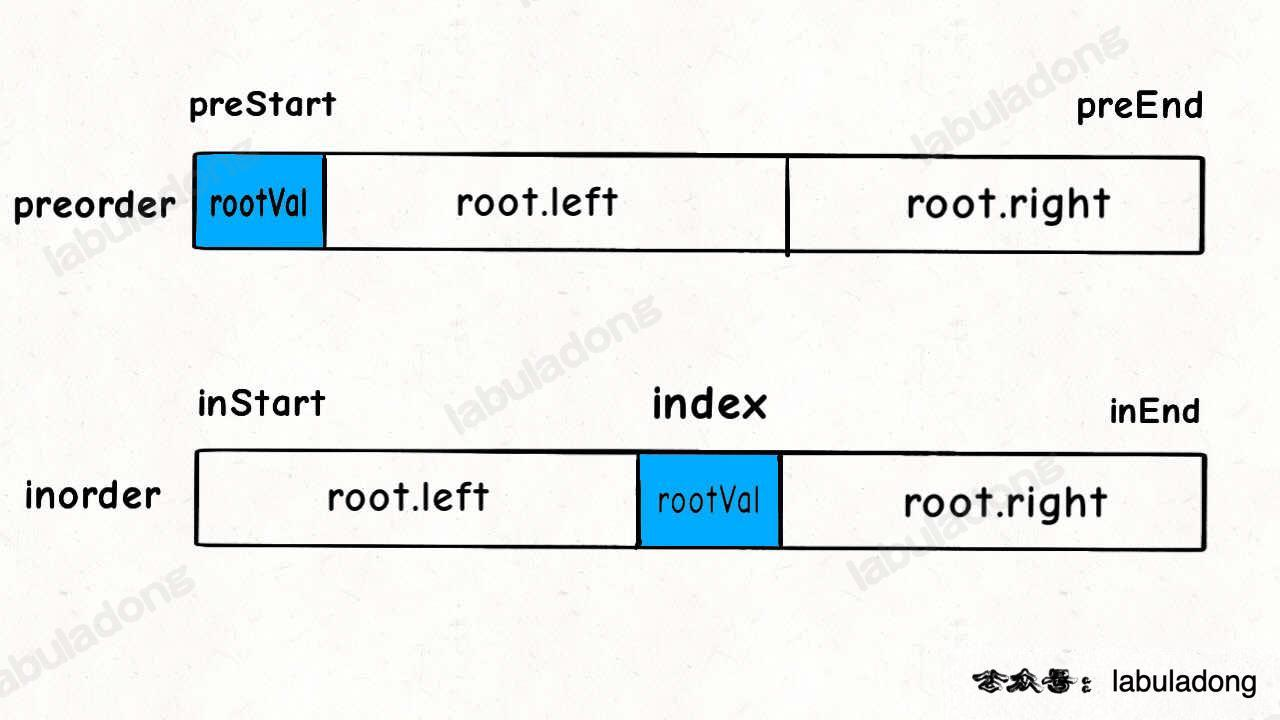
现在的问题就是,下面这几个问号该填什么:
root.left = build(preorder, ?, ?,
inorder, ?, ?);
root.right = build(preorder, ?, ?,
inorder, ?, ?);
首先左右子树的 inorder 数组的起始索引和终止索引比较容易确定:
root.left = build(preorder, ?, ?,
inorder, inStart, inStart+index-1);
root.right = build(preorder, ?, ?,
inorder, inStart+index+1, inEnd);
对于 preorder 数组,可以通过左子树的节点数推导出来,假设左子树的节点数为 leftSize, 那么 preorder 数组的索引情况是这样的:
看着这个图,先把 leftSize 算出来,然后把 preorder 对应的索引写进去:
int leftSize = index - inStart;
root.left = build(preorder, preStart+1, preStart+leftSize,
inorder, inStart, inStart+index-1);
root.right = build(preorder, preStart+leftSize+1, preEnd,
inorder, inStart+index+1, inEnd);
分解解法
// 存储 inorder 中值到索引的映射
HashMap<Integer, Integer> valToIndex = new HashMap<>();
/* 主函数 */
public TreeNode buildTree(int[] preorder, int[] inorder) {
for (int i = 0; i < inorder.length; i++) {
valToIndex.put(inorder[i], i);
}
// 根据函数定义,用 preorder 和 inorder 构造二叉树
return build(preorder, 0, preorder.length - 1,
inorder, 0, inorder.length - 1);
}
/*
build 函数的定义:
若前序遍历数组为 preorder[preStart..preEnd],
中序遍历数组为 inorder[inStart..inEnd],
构造二叉树,返回该二叉树的根节点
*/
TreeNode build(int[] preorder, int preStart, int preEnd,
int[] inorder, int inStart, int inEnd) {
//base case
if(preStart > preEnd) return null;
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// 避免 for 循环寻找 rootVal
int index = valToIndex.get(rootVal);
int leftSize = index - inStart;
//先构造出根节点
TreeNode root = new TreeNode(rootVal);
// 递归构造左右子树
root.left = build(preorder, preStart+1, preStart+leftSize,
inorder, inStart, index-1);
root.right = build(preorder, preStart+leftSize+1, preEnd,
inorder, index+1, inEnd);
return root;
}
我们的主函数只要调用 build 函数即可,你看着函数这么多参数,解法这么多代码,似乎比我们上面讲的那道题难很多,让人望而生畏,实际上呢,这些参数无非就是控制数组起止位置的,画个图就能解决了。
106. 从中序与后序遍历序列构造二叉树
这道题和105非常详细,在做之前,先回顾一下中序遍历和后序遍历的特点:
可以发现,后序遍历是在两次 「traverse」之后。
中序遍历是在两次「traverse」之间。
void traverse(TreeNode root) {
traverse(root.left);
traverse(root.right);
// 后序遍历
postorder.add(root.val);
}
void traverse(TreeNode root) {
traverse(root.left);
// 中序遍历
inorder.add(root.val);
traverse(root.right);
}
分布特点如下: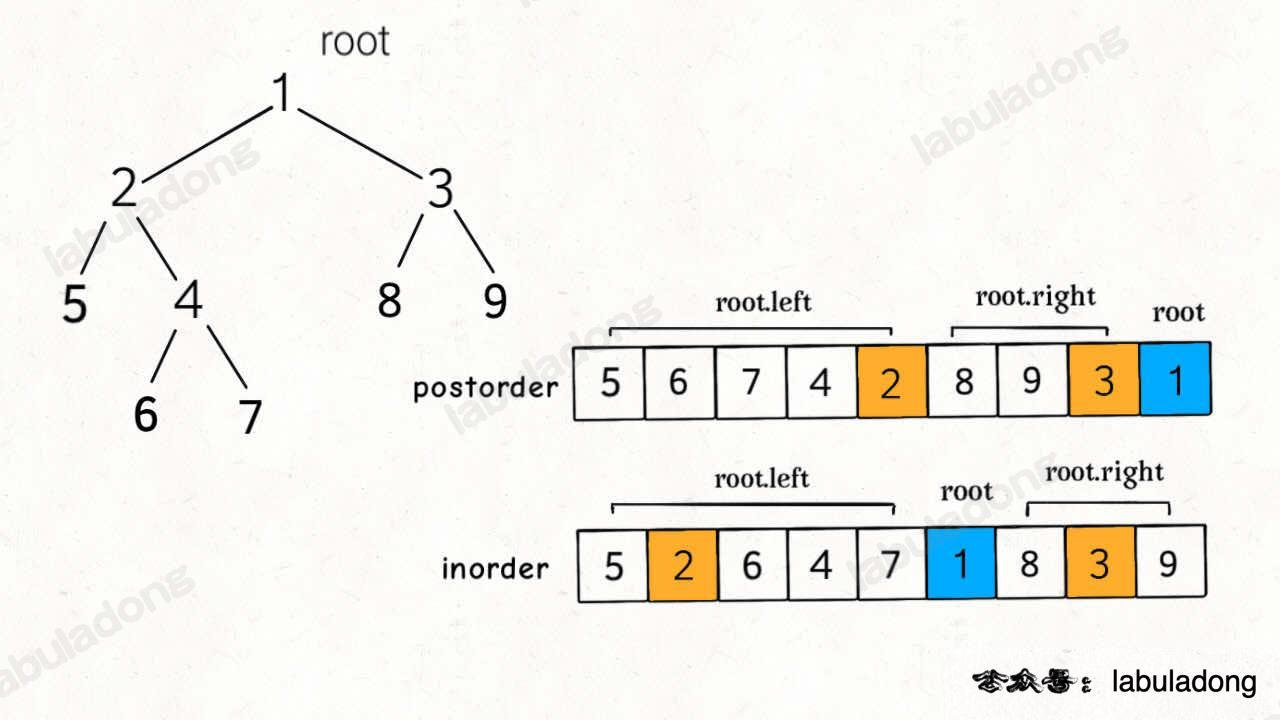
这道题和上道题的关键区别是,后序遍历和前序遍历相反,根节点对应的值为 postorder 最后一个元素。
框架和上道题基本相似,还是计算出 leftSize 之后找出左右子树,然后递归构造左右子树。
但是这里需要注意,如果build函数中 postorder 或者 inorder 的范围搞错了,就会报 「Stackoverflow」的错误。这里我也踩了一次坑,比如在 postorder中,左子树的范围是从 postStart 到 postStart + leftSize -1, 这里是需要-1的。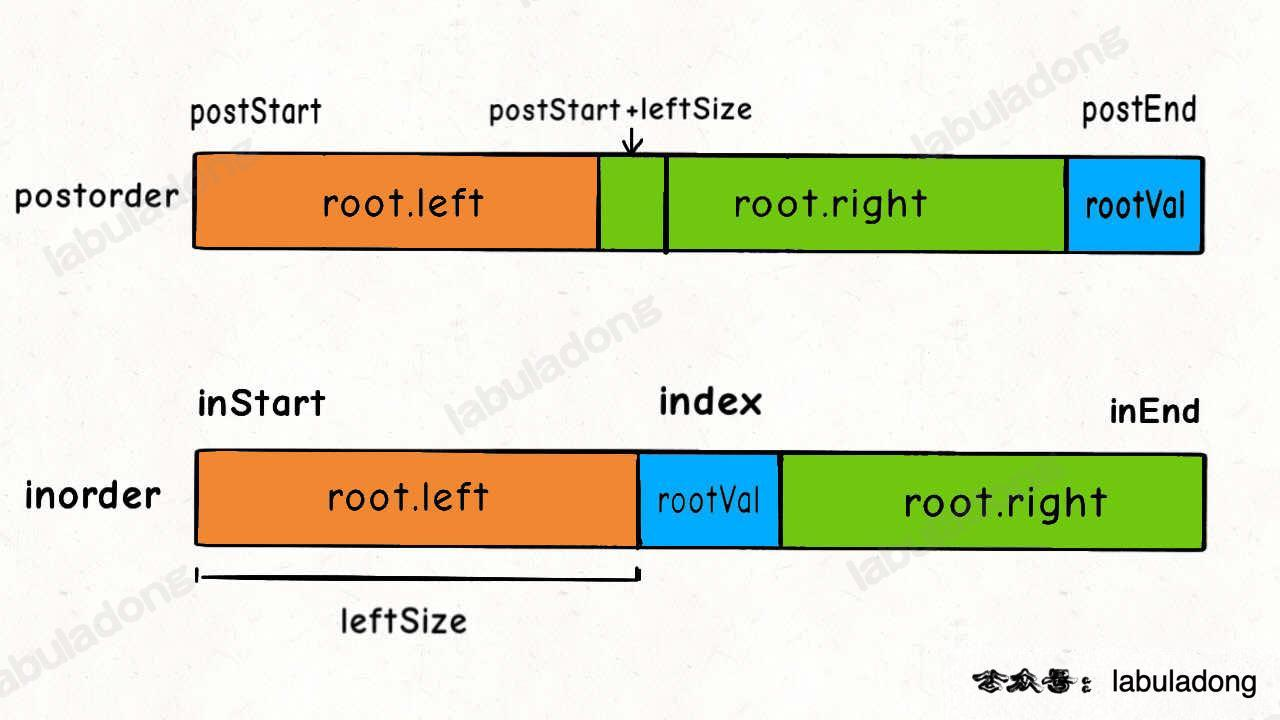
分解解法
//存储 inorder 中的值到索引的映射
HashMap<Integer, Integer> valToIndex = new HashMap<>();
public TreeNode buildTree(int[] inorder, int[] postorder) {
for(int i = 0; i < inorder.length; i++){
//键值对为:inorder元素值 - 对应索引
valToIndex.put(inorder[i], i);
}
return build(inorder, 0, inorder.length - 1,
postorder, 0, postorder.length - 1);
}
/*
build函数的定义:
如果后序遍历数组为 postorder[postStart...postEnd],
中序遍历数组为 inorder[inStart...inEnd],
构造二叉树,返回该二叉树的根节点
*/
TreeNode build(int[] inorder, int inStart, int inEnd,
int[] postorder, int postStart, int postEnd) {
//base case
if(inStart > inEnd) return null;
//root根节点是后序遍历数组的最后一个元素
int rootVal = postorder[postEnd];
//rootVal在中序遍历数组中的index
int index = valToIndex.get(rootVal);
//左子树的节点个数
int leftSize = index - inStart;
//构造根节点
TreeNode root = new TreeNode(rootVal);
//递归构造左右子树
root.left = build(inorder, inStart, index - 1,
postorder, postStart, postStart + leftSize - 1);
root.right = build(inorder, index + 1, inEnd,
postorder, postStart + leftSize, postEnd - 1);
return root;
}
889. 根据前序和后序遍历构造二叉树
这道题和上面两道题有一个本质的区别:
通过前序中序,或者中序后序遍历结果可以确定唯一一颗原始二叉树,但是通过前序后序遍历结果无法确定唯一的原始二叉树。
题目也说了,如果有多重可能得还原结果,可以返回任意一种。
前面两道题中,我们在前序或者后序遍历结果中找到根节点,然后根据中序遍历结果确定左右子树。
但是在这道题中,我们可以确定根节点,但是无法确切知道左右子树有哪些节点。
用后序遍历和前序遍历还原二叉树,解法逻辑上跟上面两道题差不多,也是通过控制左右子树的索引来构造:
- 首先把前序遍历结果的第一个元素,或者后序遍历结果的最后一个元素确定为根节点
- 然后把前序遍历结果的第二个元素作为左子树的根节点的值
- 在后序遍历结果中寻找左子树根节点的值,从而确定了左子树的索引边界,进而确定右子树的索引边界,递归构造左右子树即可。
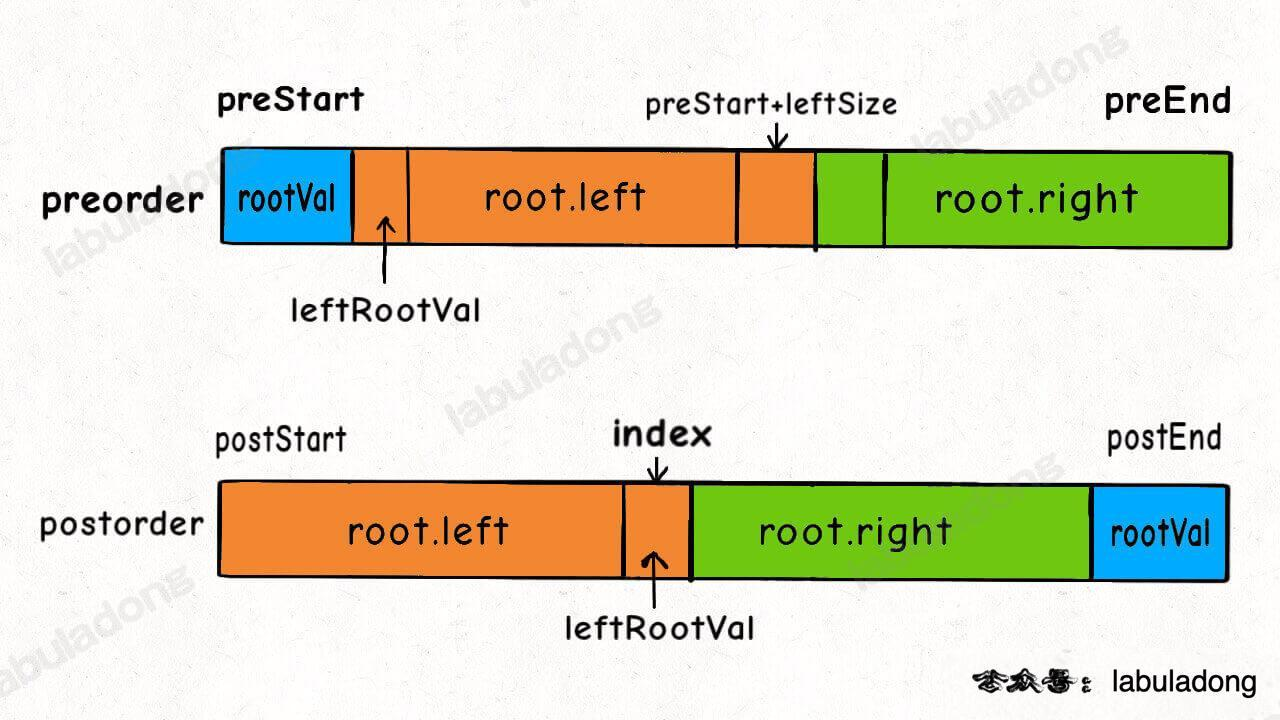
分解解法
//存储 postorder 中的值到索引的映射
HashMap<Integer, Integer> valToIndex = new HashMap<>();
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
for(int i = 0; i < postorder.length; i++){
valToIndex.put(postorder[i], i);
}
return build(preorder, 0, preorder.length - 1,
postorder, 0, postorder.length - 1);
}
/*
build函数的定义:
如果前序遍历数组为 preorder[preStart...preEnd],
中序遍历数组为 postorder[postStart...postEnd],
构造二叉树,返回该二叉树的根节点
*/
TreeNode build(int[] preorder, int preStart, int preEnd,int[] postorder, int postStart, int postEnd) {
//base case
if(preStart > preEnd) return null;
if(preStart == preEnd) return new TreeNode(preorder[preStart]);
//root根节点是前序遍历的第一个元素
int rootVal = preorder[preStart];
//root.left也就是左子树的根节点是前序遍历的第二个元素
int leftRootVal = preorder[preStart + 1];
//左子树根节点在后序遍历中的索引
int index = valToIndex.get(leftRootVal);
//左子树节点个数
int leftSize = index - postStart + 1;
//先构造出根节点
TreeNode root = new TreeNode(rootVal);
//递归构造左右子树
root.left = build(preorder, preStart + 1, preStart + leftSize,
postorder, postStart, index);
root.right = build(preorder, preStart + leftSize + 1, preEnd,
postorder, index + 1, postEnd - 1);
return root;
}
代码和前两道题非常类似,我们可以看着代码思考一下,为什么通过前序遍历和后序遍历结果还原的二叉树可能不唯一呢?
关键在这一句:
int leftRootVal = preorder[preStart + 1];
我们假设前序遍历的第二个元素是左子树的根节点,但实际上左子树有可能是空指针,那么这个元素就应该是右子树的根节点。由于这里无法确切进行判断,所以导致了最终答案的不唯一。
至此,通过前序和后序遍历结果还原二叉树的问题也解决了。
最后呼应下前文,二叉树的构造问题一般都是使用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。先找出根节点,然后根据根节点的值找到左右子树的元素,进而递归构建出左右子树。

若有收获,就点个赞吧
0 人点赞
