1.基本数据结构
1.string
1.1.比较小时使用embstr,超出后使用raw
- embstr:redis通用对象头和数据存储采用顺序存储,只需要分配一次内存即可
- raw为redis对象头有指针指向数据内存块,需要分配两次内存
为何不都使用embstr?和内存分配方式jemelloc实现有关
1.2.所有涉及到字符串的存储,底层都为sds结构
字节数组,二进制安全
- 记录长度,加快strlen操作
-
1.3.扩容
当size小于1m时,采用翻倍策略,大于1m时,扩容只会多分配1m
-
1.4.应用
存开关、序列化之后的对象等
- 存数字,并支持原子增加操作
- 存二进制数,支持一系列二进制操作(额外有计算1的个数)
2.list
2.1.(3.2)之前比较小时ziplist,增多时升级为linkedlist
ziplist
- 由于linkedlist为双向链表,每个节点之间都有两个4字节指针(32位),比较费空间
- ziplist采用数组结构,省去了指针空间,并对内部数据使用一定规范进行压缩
- 由于ziplist没有多余空间,每次增加元素都需要扩容,remelloc(如果旁边有连续空间则不需要copy)
-
2.2.(3.2)之后,统一使用quicklist
quicklist
结合ziplist和linkedlist
- 一段使用ziplist,每一段之间用指针连接
2.3.应用
简易消息队列
3.hash
3.1.数量较少使用ziplist,达到一定大小后升级为类似Java HashMap结构 数量较少时,ziplist反而会快
3.2.扩容
- 当元素数量等于数组长度时,会触发扩容 遇到bgsave延迟扩容,防止过多页面分离(COW),当元素数量为数组长度5倍时,强制扩容
- 当元素数量不足数组长度10%,会触发缩容
渐进式rehash
(1). 扩容比较耗费资源,为了较少操作卡顿,采用部分迁移,查的时候先查旧后查新<br /> (2). 再次触发部分扩容时机<br /> ①. 用户每次查询该hash会触发部分迁移<br />②. redis会起定时任务去触发扩容
3.3.应用
redisson 分布式锁
缓存整个页面的数据
4.set
4.1.底层使用hash,value为空
4.2.当元素都为int时,并且数量较少,结构优化为intset,采用紧凑存储
4.3.应用
粉丝列表
5.zset
5.1.底层由skiplist和hash实现
5.1.1.skiplist
skiplist vs 红黑树
- skiplist修改结构的时候,添加指针即可,不需要大范围改动,而红黑树可能会触发reblance
skiplist缺点
(1). 比树消耗更多的指针内存<br /> (2). 通常来说,由于缓存局部性较差,查询性能不如红黑树
作者发话
(1). 调整随机级别的概率,会使得比树消耗更小的内存(redis采用每往上一层概率25%,比原生更加扁平)<br /> (2). ZRANGE和ZREVRANGE使用频率较高,这样缓存局部性和其他平衡树相差不多<br /> (3). skiplist实现更简单,方便调试,也方便社区共同维护<br />**结构图**<br />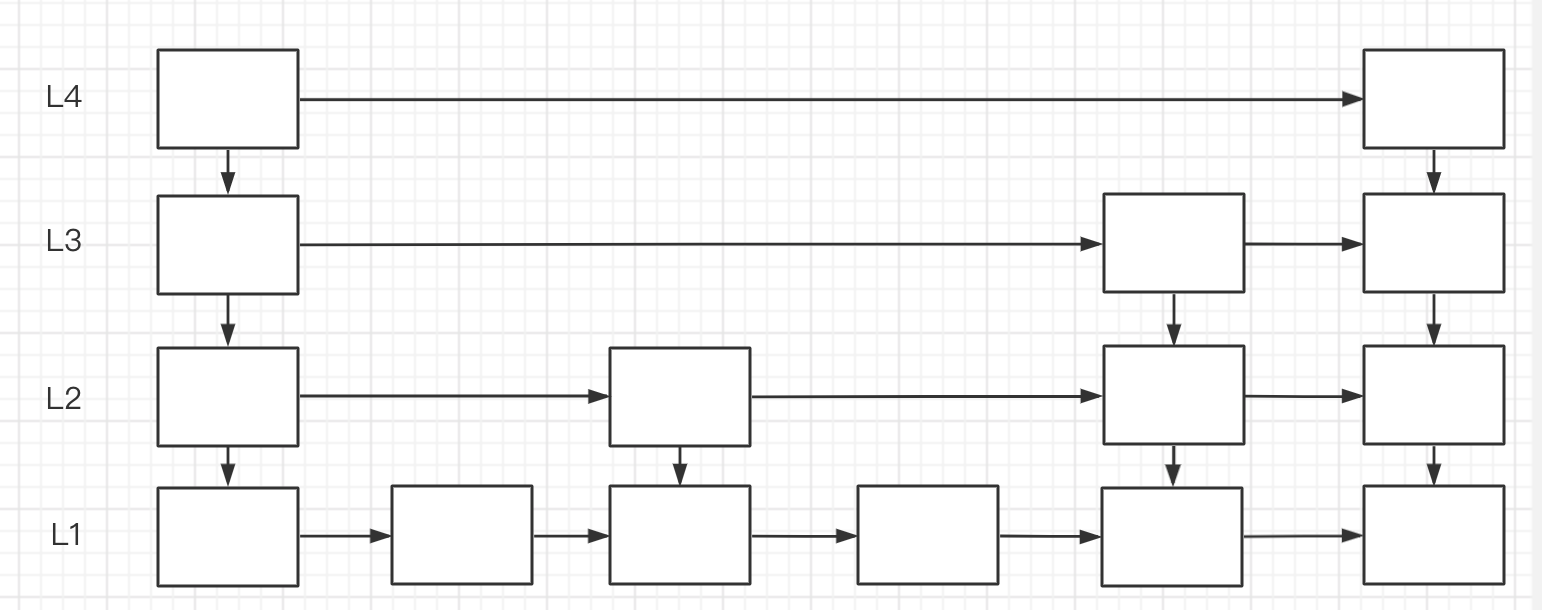<br />**分层结构,每上一层,数据越少,第二层25%概率,往上12.25%,以此类推,一共64层**<br />**查询元素从上往下比对,找到每一层score小于查询值且最大的节点,进入下层继续同理查找**<br />**ZREVRANK原理 每个节点存一个span,记录该层据后一个节点相对底层跨越了几个节点,算排名只需要将查询路径的span加起来即可**
5.1.2.hash存value和score对应关系
5.2.应用
排行榜
滑动窗口
延时队列
2.特殊数据类型
1.地理位置geo
1.1.可对地理位置进行处理,添加,获取坐标,求hash,算距离,获取坐标附近的元素等
1.2.底层使用zset实现
2.pub/sub
2.1.发布订阅,消息队列
2.2.支持多个消费者同时消费一组数据
2.3.比较鸡肋,消费者必须先在线,如果消费者离线,会丢失消息
3.stream
3.1. 5.0新增的持久化发布订阅
3.2.狠狠的借鉴了kafka
4.用来做基数统计的算法hyperloglog
4.1.海量数据去重计数
4.2.精准性换取空间
4.3.应用
4.4.底层实际使用string(bitmap)
5.布隆过滤器(位存储)
5.1.海量数据判断是否不存在
5.2.不存在一定不存在,存在有可能不存在
5.3.精准性换取空间
5.4.通过位数组和hash实现,对数据hash后取模存入位数组

若有收获,就点个赞吧
0 人点赞
