课程简介
本文主要是通过Python的图表制作“专家”Seaborn模块,对股票浦发银行(代码600000)的一年的数据进行了可视化展示,利用了各种图形展示了浦发银行股票数据,并根据图形简单分析了浦发银行股票的一些特点。
密密麻麻的数据看得人头大,数据图形化专家 Seaborn来帮忙!!!!
通过本课程的学习你将了解可视化图表模块Seaborn的基本信息,学会绘制引人入胜且内容丰富的统计图形,比如矩阵图、关系图、分类图、分布图等等。
为了帮助你更好的掌握这些绘图方法,老师会通过案例对股票浦发银行(代码600000)一年的数据进行可视化展示,利用了各种图形展示浦发银行股票数据,并根据图形简单分析浦发银行股票的一些特点。
课程导学
Hi~ 同学,你好啊~ ,很高兴和你一起通关学习,我是本门课程的老师,加法老师。
你有没有发现这样一件事,我们的日常生活与日常工作好像越来越离不开数据分析,比如平常汇报工作,家庭中记个账单,销售人员分析业绩,新生代的股民查看股票基金走向等等。
在做数据分析的时候,最基本的工具应该是表格,加法老师平时喜欢炒炒股,从网上下载了浦发银行的一年的股票数据,经过一些处理,数据存在表格里是这样的: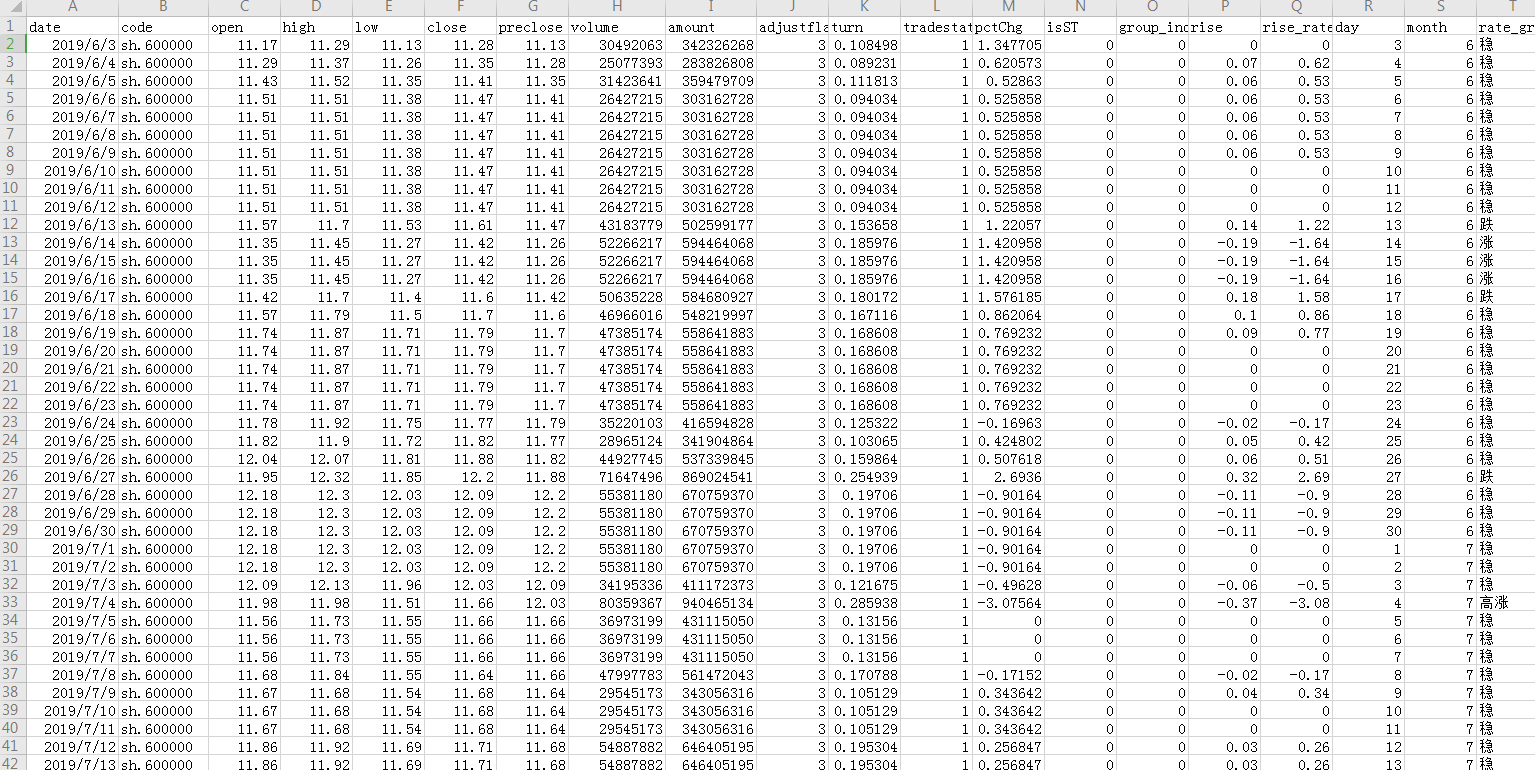
小白同学:哎呀老师,这密密麻麻的数据,什么都看不出来呀,我的头都要大了~~~
加法老师:确实如此,单纯通过表格好像不能很快的获取信息,老师通过一些技术手段对数据做了一些处理,你看一下老师对这些数据处理后的结果。
小白同学:好像一下就清晰了很多,而且看起来五彩斑斓很绚丽啊,比起枯燥的表格数据,看起来心情要好很多了呢,如何才能做出这种图表呢(期盼表情)?
加法老师:这里加法老师要向你隆重介绍Python的可视化专家——Seaborn模块,利用Seaborn做出的图片就是这种效果,很漂亮吧(鼓掌表情)!!
那在本课程中老师将向你介绍Python的可视化图表模块Seaborn,学习绘制引人入胜且内容丰富的统计图形,比如矩阵图、关系图、分类图、分布图等等。
为了帮助你更好的掌握这些绘图方法,老师会通过一个小案例:对浦发银行的股票数据进行各个方面的可视化展示,每一个关卡独立介绍一类效果图,学过之后呢,你会对股票的各种特点有一个直观的感觉。
前置知识
本课程主要通过Python的可视化图表模块Seaborn,对中国股市股票“浦发银行”的数据进行了可视化展示,在展示的过程中需要借助Pandas 和Matplotlib模块的知识,因此需要你对”Pandas模块”与”Matplotlib模块”有一定的了解。
课程中用到的练习数据,加法老师已经下载好并做了简单处理,练习数据以及生成数据的代码已经上传在右侧的资料包中,点击下载即可使用。如果你想要下载股票数据自己分析,建议移步《股票数据分析的好搭档——Pandas》课程,在这门课程中,老师详细介绍了股票数据的下载与处理方法。
注:上传资料处deal_data.py
学习目标
通过本门课程的学习,希望你能够对可视化图表模块Seaborn有一个简单的了解,掌握Seaborn中比较常用的几个图形以及他们的特点:
- 矩阵图:热力图
- 关系图:散点图、折线图
- 分类图:条形图、计数图
- 分布图:直方图、核函数密度估计图
Python的数据可视化图表模块将会是你进行数据分析的有效工具,老师希望你在学习的过程中,了解不同图像的特点与适用场景,针对不同的情况选取不同的图表,并且能够根据某一制图得出自己对数据的分析结果。
我们的课程将从了解Seaborn开始,点击进入第一关:Seaborn的概述。
第一关 Seaborn概述
通过导学部分,相信你已经了解了,Seaborn是Python提供的数据可视化库,在这一关老师将继续对Seaborn做一个简单的介绍,并为后几关的图形学习做好准备工作。
1、青出于蓝而胜于蓝——Seaborn背景
Seaborn是基于Matplotlib的图形可视化Python包,它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
~~
Matplotlib是非常优秀的可视化绘图工具,但是使用的时候过于复杂,有大量的函数与参数,可以这样来理解,“Matplotlib可以做任何事,但是又好像无从下手”。Seaborn是在Matplotlib的基础上进行了更高级的API封装,有很多默认的主题,从而使得作图更加容易,在大多数情况下使用Seaborn能做出更具有吸引力的图,配色更加舒服,图形元素的样式更加细腻。
Seaborn把用户常用到的可视化绘图过程进行了函数封装,形成一个一个“快捷方式”,Seaborn相比Matplotlib的好处是代码更简洁,可以用一行代码实现一个清晰好看的可视化输出。
但是事物总是具有两面性,基于刚才说的,虽然Seaborn制图更绚丽,但是它的缺点也很明显,就是定制化能力会比较差,只能实现固化的一些可视化模板类型,要实现更个性化更高难度的图形,还是会用到Matplotlib。
Matplotlib可以实现高度定制化绘图,高度定制化可以让你获得最符合心意的可视化输出结果,但也因此需要设置更多的参数,因而代码更加复杂一些。
小白同学:老师,你说了这么多,Seaborn和Matplotlib好像各有优缺点,我到底该怎么选择呢(问号表情)?
加法老师:老师推荐给你一种符合学习规律的学习步骤:上手学习用Seaborn,能满足日常的需求,作图简单美观;当你感觉Seaborn在制图的时候有点力不从心,或者要深入研究更复杂的制图,可以学习Matplotlib,Matplotlib虽然使用稍许复杂,但功能更加强大。
通过与Matplotlib的对比介绍,相信你Seaborn已经有了一定的了解,在Python当中还有一个Pandas模块,这三者之间有什么联系与区别呢?
Pandas和Seaborn都是使用了Matplotlib来作图,但是有非常不同的设计差异:
- 在只需要简单地作图时直接用Pandas,但要想做出更加吸引人,更丰富的图就可以使用Seaborn
- Pandas的作图函数并没有太多的参数来调整图形,所以你必须要深入了解Matplotlib
- Seaborn的作图函数中提供了大量的参数来调整图形,所以在初学Seaborn的时候并不需要太深入了解Matplotlib
- Pandas可以利用自己强大的数据处理能力为Seaborn和Matplotlib 提供作图的数据来源
加法老师再啰嗦一下,这些数据分析库只是工具,你要学会根据不同需求选取不同的工具,不要被局限于工具中。
2、Seaborn的安装
Seaborn作为Python的第三方库,在使用之前需要先安装。
Seaborn包依赖于scipy包,所以要先装scipy,都是用我们熟悉的pip来安装。如果你的电脑上没有安装scipy,也别担心,安装Seaborn的时候会自动安装scipy。
pip3 install seaborn
敲入安装代码之后,如果出现如下图所示的运行效果,说明你已经成功安装了Seaborn:
小白同学:“老师。。。你看我安装的,出现了红色的错误提示,为什么我安装了几次都失败了,我要精神安慰(哭泣表情)—”
加法老师:“哦,这是因为网速原因导致的,你看你的下载速度,才44k,老师教你一招,速度飞上天,看下图:”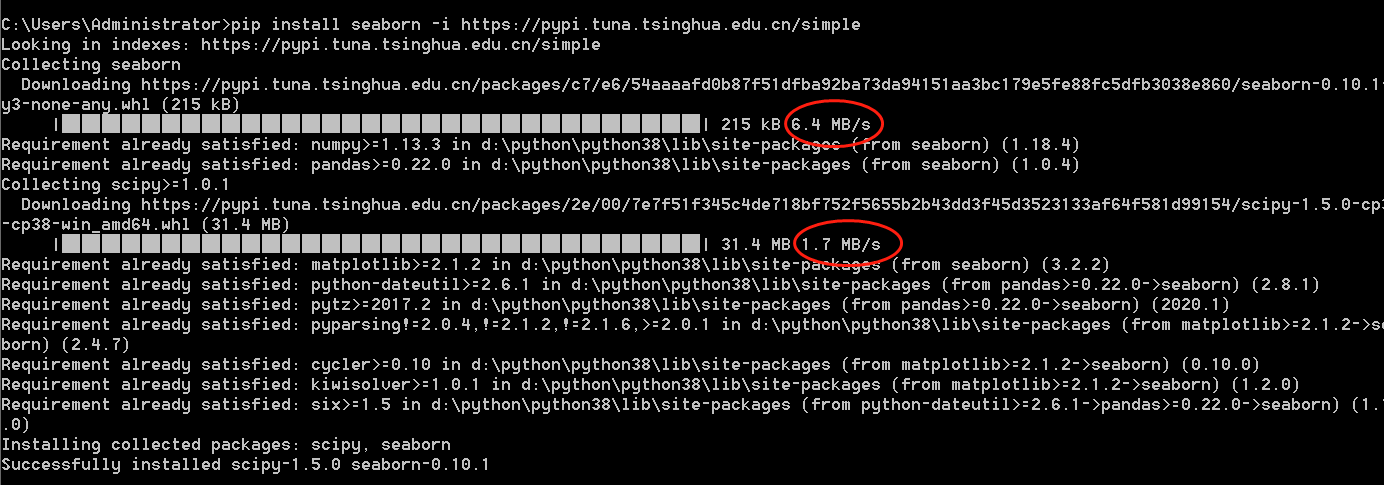
看到红圈里的网速了吗,6.4M 啊,提高了整整两个数量级,有没有被吓到,哈哈,关键是后面的这一参数 :
注意到 ‘-i ’后面的链接了吗,是不是很熟悉,对啦,是清华大学的网址,这个参数的意思就是我们去清华大学的服务器上下载安装Seaborn的哦,都是国内的网,当然速度快的不讲理啦。
小贴士: 国内的Python安装库还有阿里、豆瓣,大家自己去发掘一下吧。
4、通关练习
请你在自己的机器上安装Seaborn,建议使用国内源,体验飞一般的感觉。
注:如果你忘记了如何安装Python与pip,建议移步《使用 Requests 爬取网页》课程,在这门课程中,老师详细介绍了如何安装Python与pip__。
在安装的过程中,遇到问题,可以在右侧的提问区提问,会有老师帮助你解答问题。
5、本关总结
本关轻易的就通过了,全是理论性的知识,很easy嘛。
 在这一关,老师首先介绍了一下Seaborn的“身世”,它是基于Matplotlib而诞生的,使用更简易更友好,Matplotlib虽然复杂,却是你在Python可视化道路上必须要经过的大boss,更强大哦。它们俩都可以用Pandas的数据格式,兼容性不错,三者关系很好。最后老师还教了你安装模块的一个技巧,就是用国内源,速度飞起哦。
在这一关,老师首先介绍了一下Seaborn的“身世”,它是基于Matplotlib而诞生的,使用更简易更友好,Matplotlib虽然复杂,却是你在Python可视化道路上必须要经过的大boss,更强大哦。它们俩都可以用Pandas的数据格式,兼容性不错,三者关系很好。最后老师还教了你安装模块的一个技巧,就是用国内源,速度飞起哦。
理论学完了,从下一关开始一个图一个图开始学习吧(冲的表情)。
第二关 矩阵图
矩阵图就是从多维问题的事件中,找出成对的因素,排列成矩阵图,然后根据矩阵图来分析问题,确定关键点的方法。它是一种通过多因素综合思考,探索问题的好方法。
概念有点专业,不太好懂,老师给你通俗的说一下,矩阵图,它的图形是矩阵形状,数据组成了x轴y轴和空间内容。
1、数据介绍
在我们要利用数据进行制图前,首先要理解数据内容。你可以打开老师提供给你的数据表(如果在课程导学部分没有下载,在本关的“资料包”也可下载),老师把下载的数据给你介绍一下。后面的关卡练习都是用这一组数据来做练习,所以这部分要认真看呦~
seaborns_600000_stock_data.csv
先看下数据的内容: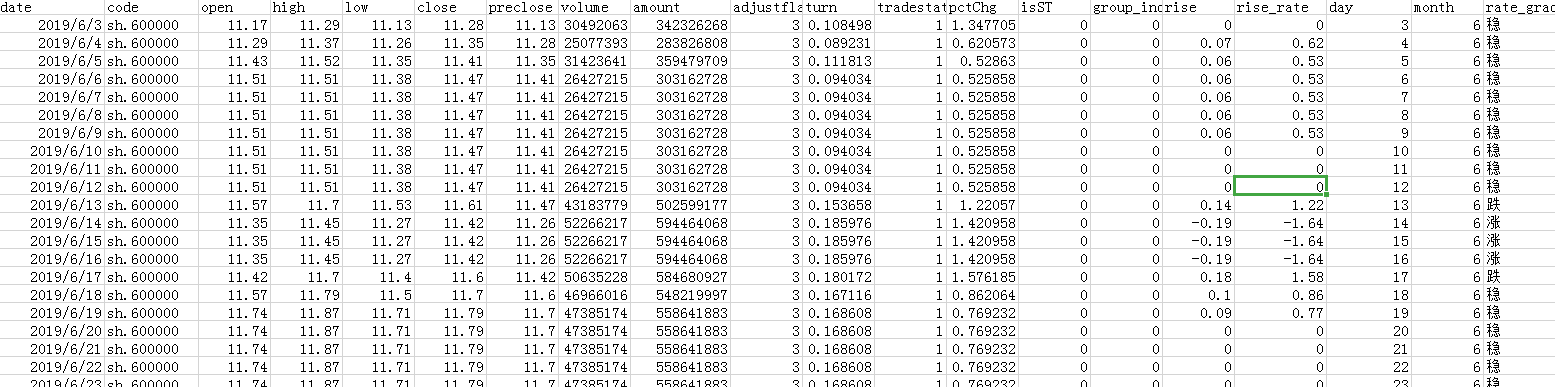
可以看出,这个数据表包含的数据与字段非常丰富,由于涉及到股票相关,如果你不是一个炒股发烧友的话,可能会有点儿看不懂,老师把每一个参数的含义整理成了一个表格,请往下看:**
对数据的字段了解过了,数据要怎么看呢,太多了,如果直接看的话一定会看花眼的,下面老师会用不同的图对不同的数据字段做展示。
这一关,我们先用热力图来看会有什么效果呢,先来看下收盘价(close)和交易量(volume)的情况。
2、热力图
热力图是矩阵图的一种,对某一数据进行全部的展示,通过颜色的深浅表示数据的或多或少、或大或小,下图是一个简单的热力图。

下面我们举一个例子,对收盘价(close)通过热力图进行展示,最终实现的效果:x轴为月份,y轴为日,内容为收盘价(close)的全量数据。
代码如下:
#以下三行是本文所有程序必须要先做的,后续的代码展示中老师将这一部分省略import seaborn as sns #导入seaborn模块import pandas as pd #导入pandas模块import matplotlib.pyplot as plt #导入matplotlib模块CSV_GM_PATH=".\\seaborns_600000_stock_data.csv" #数据的路径df=pd.read_csv(CSV_GM_PATH,error_bad_lines=False) #读取出数据,保存在变量df中#从数据源里获取需要的字段组成新的数据源df1df1=df.pivot(index='day',columns='month',values='close')#对新的数据源进行热力图展示ax=sns.heatmap(df1,annot=True)#显示热力图plt.show()
上面代码有两个关键函数,第一个是 pivot(),它是用来重塑数据的。函数格式:
- index: 可选参数。设置新dataframe的行索引,如果未指明,就用当前已存在的行索引。
- columns:必选参数。用来设置作为新dataframe的列索引。
- values:可选参数。在原dataframe中选中某一列的值,使其在新dataframe的列里显示。
df1=df.pivot(index='day',columns='month',values='close')
在这行代码里,老师用 ‘day’ 这一列作为新dataframe的索引,’month’ 为列索引,’close’ 这一列为值,形成了新的dataframe —> df1 。
第二个函数是heatmap() ,它是构造热力图的函数,函数格式: **
**
- data:矩阵数据集,可以是numpy的数组(array),也可以是pandas的DataFrame。
- annot(annotate的缩写):默认取值False;如果是True,在热力图中每个方格会写入数据。
ax=sns.heatmap(df1,annot=True)
在这行代码里,老师把新生成的数据df1作为第一关参数,annot为True,即在方格里显示数据。
在新的数据源df1中,索引为列“day”,列为“month”, values为“close”,生成热力图则自动转换,day为y轴,month为x轴,close为展示的数据。
运行之后,效果图如下: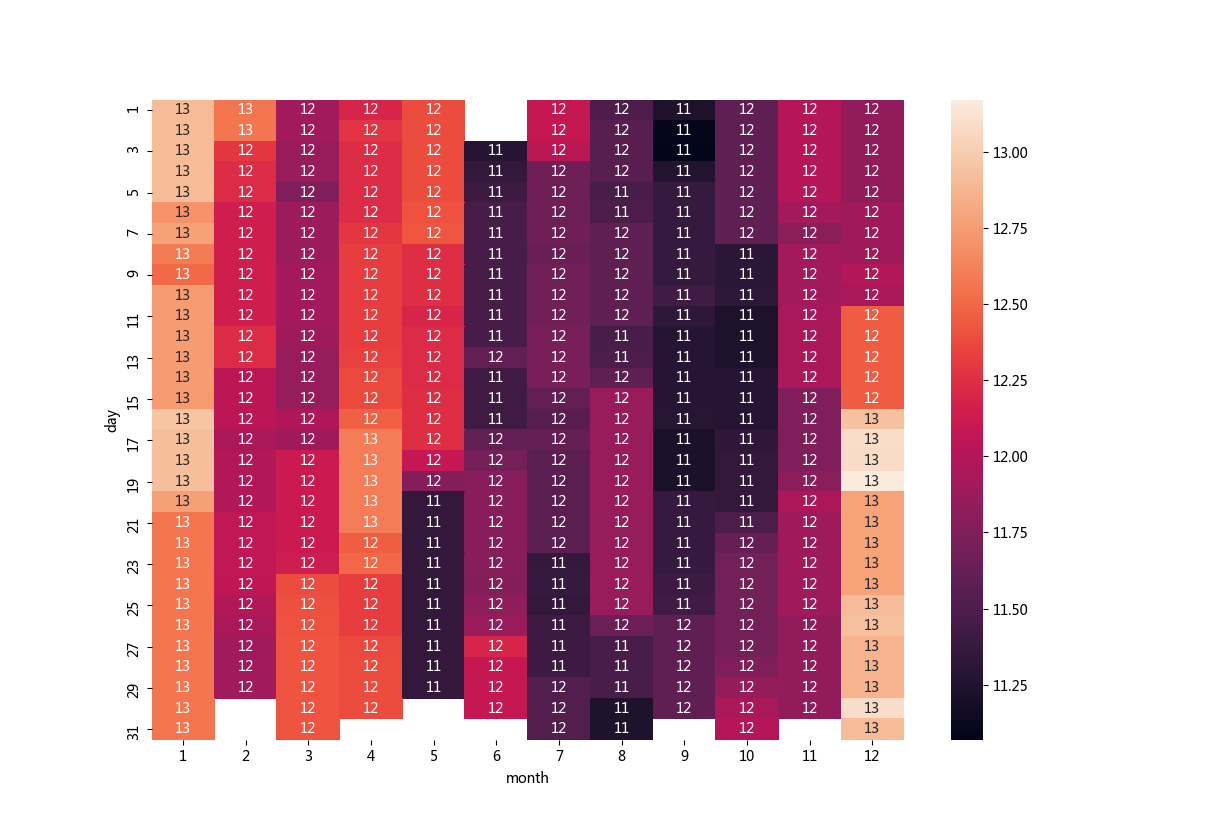
通过热力图的展示,所有的close(收盘价)都直观的展现在我们面前,x轴表示month(月份),y轴表示day(日),收盘价越低颜色越深。从图中可以看出,这一年的收盘价波动很小,上下围绕着12元波动1元左右的样子,最贵的是在1月份,整体颜色较浅,基本上都在13元左右,6-10月份的颜色较深,说明这段时间的股票收盘价较低。我们从这个图也可以看出来这只股票是波动很小的股票。
热力图的绘制非常简单,我们再对交易量(volume)做一个直观的展示,看看交易量里能看出什么玄机。
你试着做一下,代码和上面的例子差不多,参照上面代码,把第七行和第九行填上,看看结果。
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltCSV_GM_PATH=".\\seaborns_600000_stock_data.csv" #数据的路径df=pd.read_csv(CSV_GM_PATH,error_bad_lines=False) #读取出数据#利用day 、month、volume三个值生成新的数据源#****此处填写你的代码*****#热力图展现#****此处填写你的代码*****plt.show()
你做出来的热力图是什么样的,对照一下和老师做的是不是一样?老师的代码是这样写的:
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltCSV_GM_PATH=".\\seaborns_600000_stock_data.csv" #数据的路径df=pd.read_csv(CSV_GM_PATH,error_bad_lines=False) #读取出数据#利用day 、month、volume三个值生成新的数据源df2=df.pivot(index='day',columns='month',values='volume')#热力图展现ax=sns.heatmap(df2,annot=True)plt.show()
老师运行处的热力图如下所示:
上图中,x轴表示月份(month),y轴表示日(day),内容为全年的交易量(volume),尽收眼底。
小白同学:“老师,这红红恍恍惚惚的我怎么看不懂啊,这有什么用啊”
加法老师:“嗯,仁者见仁,智者见智,这里展示的是股票交易量,作为一名韭菜。。。额。。。股票交易者,我还是能看出点门道的”
小白同学:“老师您讲讲呗”
加法老师:“嗯,从颜色变化程度可以看出交易量变化的快慢,同一颜色的长度可以看出交易量稳定多久,一个图不能看出太多信息,但是你对一只股票采用多种可视化的图进行分析,就能挖掘出这只股票的更多特点,了解的越深,也能更好把握这只股票特点,从而大概率获得收益。”
小白同学:“那老师我们快进行一关的讲解吧”
3、通关练习
通过热力图可以看某一指标的全部状态,请你利用我们的数据,把开盘价(open)全年的数据,利用热力图展示出来吧。
老师准备了一份参考答案,上传在右侧的资料包中,如果你完成了本关的通关练习,可以下载资料包与老师的代码进行比较。如果你在写代码的过程中遇到了困难,可以在提问区留言,老师会回答你的问题哦。
4、本关总结
本关对案例中采用的原始数据做了简单的介绍,详细讲解了股票数据的每个字段的信息,这也是我们每次做数据分析之前的首要任务:了解数据。
这些数据数量巨大,通过表格的形式查看很难看出规律,通过热力图可以看某一指标的全量数据,非常直观,通过颜色的深浅可以看出一些规律。
热力图的函数格式:
heatmap(data,annot=‘bool’)
第一个参数是数据集,第二个参数表示是否在图中显示值。
 虽然从热力图中得到了一些信息,但还是远远不够的,让我们继续作图获取更多的信息。
虽然从热力图中得到了一些信息,但还是远远不够的,让我们继续作图获取更多的信息。
第三关 关系图
关系图是指依靠数据之间关系所作出的图,目的是进一步找出更深层次的数据关系。常见的关系图包括:散点图、折线图等。
1、散点图
讲授思路:概念(文字结合图)>>适用场景等>>函数格式说明(统一样式)>>举例说明(代码,效果图,结合代码与效果图对关键代码做说明)>>对效果图的分析结果做简单说明,不要太深入,浅说即可
散点图是各种示意图中影响力最广、信息量最大、功能最多的一类图,它可以直接向用户传递信息,无需太多额外工作。

适用场景:显示若干数据系列中各数值之间的关系(类似XY轴),判断两变量之间是否存在某种关联。
优势:对于处理值的分布和数据点的分簇,散点图都很理想。如果数据集中包含非常多的点,那么散点图便是最佳图表类型。比如上图中我们可以仅凭肉眼就能看出“one”的大致分布,即使包含在很多其他的点中。
劣势:在点状图中显示序列如果过多会看上去有些混乱。
散点图可以显示观察数据的分布,描述数据的相关性,下面就介绍一下如何用scatterplot()函数方法绘制散点图:**
- x,y:输入的待做比较的绘图数据,在散点图中,dataframe[‘列名1’]将作为x轴,dataframe[‘列名2’]将作为y轴 注:必须是数值型数据
- hue:对输入数据进行分组的序列,使用不同颜色对各组的数据加以区分
- style:对输入数据进行分组的序列,使用不同点标记对各组的数据加以区分
这样去讲解你可能还是有点儿懵,举个栗子:比较成交数量(volume)和收盘价(close)的关系。
#生成数据源dfdf=pd.read_csv(CSV_GM_PATH)#散点图展示sns.scatterplot(df['close'],df['volume'],hue=df['rate_grade'],style=df['rate_grade'])#显示热力图plt.show()
运行之后,散点图如下: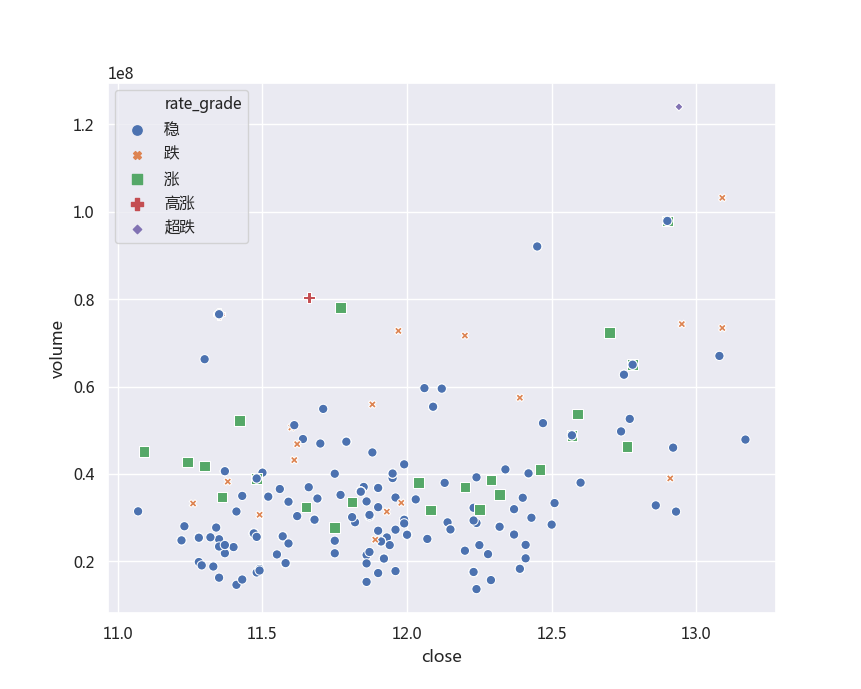
对于其中的关键函数scatterplot(),老师通过这个例子做一下解释:
sns.scatterplot(df['close'],df['volume'],hue=df['rate_grade'],style=df['rate_grade'])
- df[‘close’],df[‘volume’]:输入的需要做比较的数据,因为我们要比较的是成交数量与收盘价的关系,所以列名1=close(收盘价),列名2=volume(成交数量),在散点图中分别为图的x轴和y轴,即分析y轴与x轴的关系。
- hue=df[‘rate_grade’]:图中显示的不同颜色标示则为列 ‘rate_grade’ (涨跌分类)的不同的值。
- style=df[‘rate_grade’]:图中’rate_grade’ (涨跌分类)采用了不同形状的标记,有圆、正方形、十字等等
从图中也可以看出来:股价波动小时,交易量也普遍小;股价价格高时,交易量也大,高涨、超跌的次数极少。说明了这只股票波动很小。
2、折线图
折线图也是一种关系图,数据表的列或行中的数据都可以绘制到折线图中,通过折线的上升或下降表明数据的增减变化。
适用场景:如果分类标签是文本并且代表均匀分布的数值(如月、季度或财政年度),则应该使用折线图。
优势:可以显示随时间而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势,在这一关老师也主要分析数据与时间的关系。
在折线图中,时间数据沿x轴均匀分布,待分析的数据沿y轴均匀分布,下面就介绍一下如何用lineplot()函数方法绘制散点图。 **
**
- x,y:数据中变量的名称,输入的需要做比较的数据,在折线图中分别为x轴和y轴,即分析y轴与x轴的关系
- data:DataFrame类型,表示待分析的数据来源
举个栗子:分析一下6月这一个月间收盘价(close)的变化趋势:
#我们只取30天的数据,从第1列开始取df2=df[:30]#展示折线图ax = sns.lineplot(x = "date", y = "close",data = df2)plt.xticks(rotation=45) #x轴的日期倾斜45度显示
运行之后,折线图如下图所示:
对于其中的关键函数,老师结合代码与运行出的折线图做一下说明:
ax = sns.lineplot(x = "date", y = "close",data = df2)
这行代码表示以df2这个数据集合中两个列名“date”、“close”为x轴和y轴,绘制折线图。
plt.xticks(rotation=45)
这行代码对x轴的显示倾斜角度进行设定,在本例中老师设置为45°。
老师再设置一个90度的,你来看看不同:
plt.xticks(rotation=90)
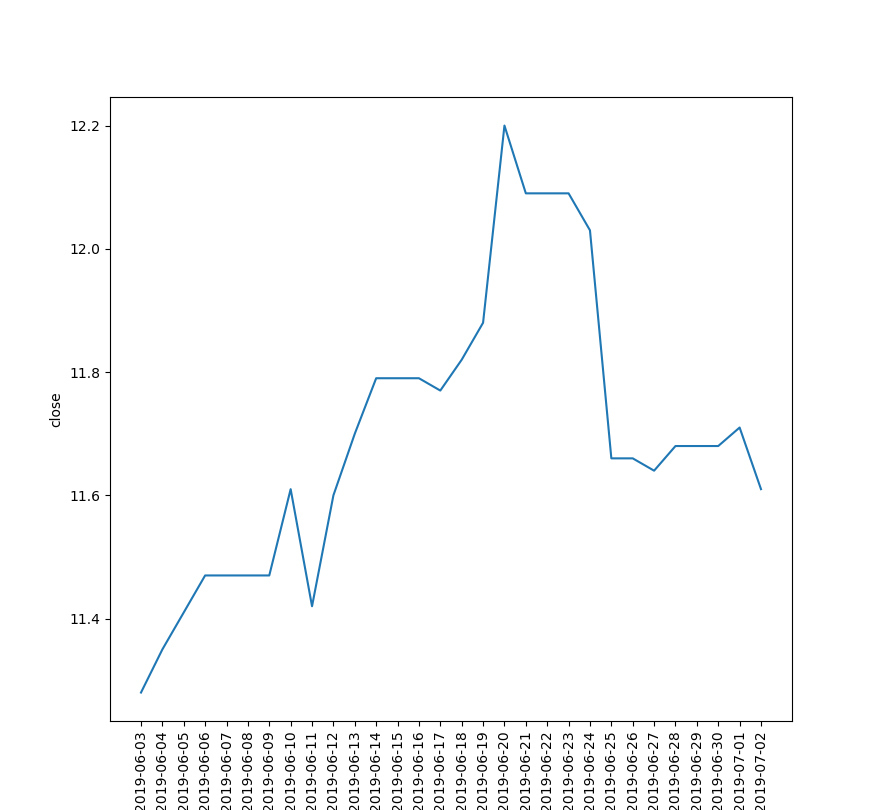
通过这两幅图的比较,可以看出这行程序的作用。
这个折线图呈现的是6月份收盘价的30天的走势图,可以看出在6月这一个月内,股价在11元8角附近上下波动,最高12元2角,最低11元。
3、通关练习
请你利用本文数据源的数据,做出七月开盘价(open)的折线图,要用到“date”和“open”这两列。
老师准备了一份参考答案,上传在右侧的资料包中,如果你完成了本关的通关练习,可以下载资料包与老师的代码进行比较。如果你在写代码的过程中遇到了困难,可以在提问区留言,老师会回答你的问题哦。
4、本关总结
本关介绍了两种关系图:散点图和折线图,两种图都反映了两组数据的关系,不同的是散点图中x轴与y轴都是数值型数据,而折线图中x轴是类别数据,比如日期,y轴是数值型数据。
 关系图简单给同学介绍完了,后面还有更有用的制图等着我们,一起去看看吧。
关系图简单给同学介绍完了,后面还有更有用的制图等着我们,一起去看看吧。
第四关 分类图
分类图可以更好更明确的展示内容,对展示的内容进行分类展示,从而通过数据整合运用图像形式来展现,达到表达目的的效果。在本关,老师将重点介绍2种分类图:条形图与计数图。
1、条形图
见名思义,条形图就是一条一条柱状组成的图形,如下图。
条形图用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来。从条形统计图中很容易看出各种数量的多少。
适用场景:显示各个项目之间的比较情况。
优势:每个条都清晰表示数据,直观。
条形图也叫长条图或直条图,代码也相当简单,一个函数barplot()就搞定了。**
- x,y:数据中变量的名称,输入的需要做比较的数据,在条形图中分别为x轴和y轴,即分析y轴与x轴的关系
- data:DataFrame类型,表示数据来源。
举个栗子:如果想看涨跌幅的五种分类(稳、跌、涨、高涨、超跌)他们的交易量的平均值,可以用下面的代码
#展示条形图sns.barplot(x='rate_grade',y='volume',data=df)plt.show()
这段代码里我们以类别数据涨跌幅’rate_grade’为x轴,y轴为交易量’colume’的平均值。
运行之后,效果图如下所示: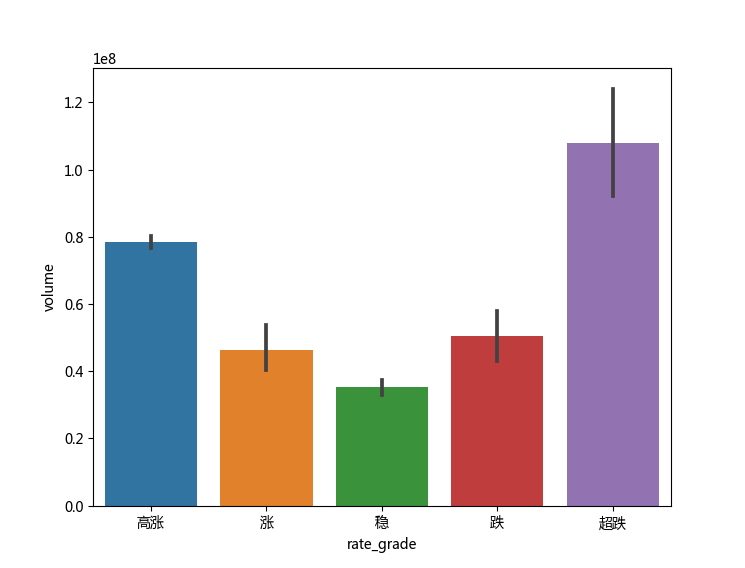
类别数据rate_grade共有五个值:“高涨”“涨”“稳”“跌”“超跌”,对应五个柱子,y轴是五种情况下的交易量平均值,通过图形的展示,可以看出结果太明显了,高涨和超跌的时候交易量要大于其他三种情况,尤其是“稳”的情况下,交易量最小,这正验证了普通人炒股的心理:“恐惧和贪婪”,超跌的时候恐惧心理占据上风,抛售股票的也多了,高涨的时候贪婪心理占据上风,买入股票的人也多了。
小白同学:“老师,这太有趣了,原来数据也会说话啊”
加法老师:“对啊,只要你用好工具,股票的特征就会一点一点呈现在你面前的。”
2、计数图
故名思意,计数图,可将它认为一种统计数量的图形,也可认为它是用以比较类别间计数差。

适用场景:离散型特征可使用,描述样本点出现的次数。
计数图调用count函数的barplot,所用函数是 countplot(),实现代码也相当简单。 **
**
- x,hue:数据变量的名称,在图中x表示x轴,hue表示y轴。
- data: DataFrame类型数据,表示数据来源,数组或数组列表用于绘图的数据集。
举个栗子:老师把一年的数据分成了8组(最后一组数据量不够,没有参考意义,在判断的时候予以抛弃),然后用计数图对每一组内的五种涨跌情况进行了对比:
#展示计数图sns.countplot('group_index',hue='rate_grade',data=df)plt.show()
呈现在眼前的图就是既可以组为单位比较,所有单位也可以作为整体来进行比较。x轴为组号,y轴为涨跌类别的数量。
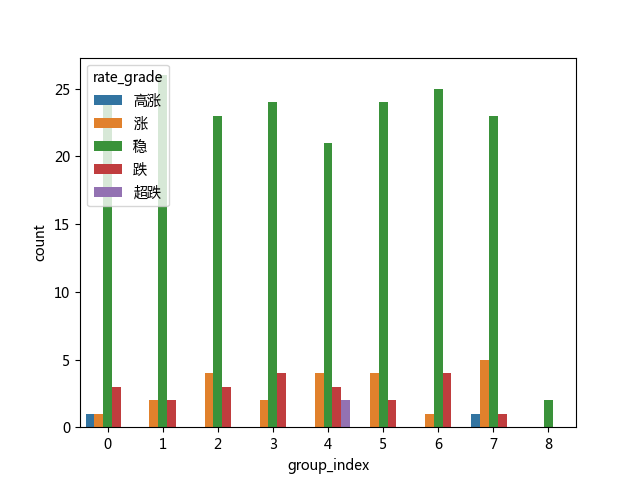
小白同学:“老师我来总结下吧,从这个图中我看到每组代表稳定的绿棒占据着绝大多数,其他情况都很少,说明这只股票很稳,波动小”
加法老师:“嗯嗯,总结的不错,很容易吧。看起来枯燥的数据,用Seaborn这么一展示,就变的很好理解了,加油,小白”
3、通关练习
请你利用本文数据源的数据,做出交易额(volume)的条形图。
老师准备了一份参考答案:barplot.py,上传在右侧的资料包中,如果你完成了本关的通关练习,可以下载资料包与老师的代码进行比较。如果你在写代码的过程中遇到了困难,可以在提问区留言,老师会回答你的问题哦。
4、本关总结
本关介绍了分类图中的两种图:条形图和计数图,从外观上看,两者都是有一根根柱子组成,很类似,但细细看就能看出他们的区别,条形图的x轴为类别数据,y轴为类别数据对应的数值数据的平均值。计数图x轴y轴都为类别数据,表现的是x轴的数据范围内y轴数据的数量。
 还有最后一大类图,分布图,向着胜利前进!
还有最后一大类图,分布图,向着胜利前进!
第五关 分布图
分布图是表现一些现象空间分布位置与范围的图型,它的制图会给人视觉上的直观结果。在本关,老师将重点介绍2种分类图:直方图与核函数密度估计图。
1、直方图
直方图是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。
适用场景:数据有分组,并且有展示数据变化的需求。
在Seaborn中使用distplot()函数制作直方图,直方图的函数displot()的格式如下:
- x,y:数据变量的名称,在图中分别表示x轴与y轴。
- data: DataFrame数据类型,表示数据来源,数组或数组列表用于绘图的数据集。
举个栗子:如果想直观的看一个月的交易量并做比较,可以用直方图表示出来,看下面的程序。
df5=df[:30] #取前三十行数据sns.barplot(x=df5['date'], y=df5["volume"], data=df5) #取df5的‘date’‘volume’这两列作为xy轴plt.xticks(rotation=45) #倾斜45度角plt.show()
代码也和其他图形一样,相当的简洁。因为日期数据太多,本文展示不开,本例只取了前三十行数据。第二行代码就开始作图了,x轴设为日期,y轴设为交易量,数据源为我们取的前三十行数据,日期稍作处理,倾斜45度角,显示时就不会互相重叠在一起了。
运行之后直方图如下所示:从图中可以得到交易量的简单特征,比如7月4日交易量最大,6月4日交易量最小。
小白同学:“不对,老师,这不是条形图吗,别以为画的像钢琴谱一样就能骗过我,我可是好好学习过的呢。”
加法老师:“小白同学,这回是你错了,仔细看看例子里两种图形的x轴y轴,数值和类别都是不一样的特点呢,如果要快速的分辨它们,那就是直方图的x轴数据是有前后关系,不可颠倒顺序,而条形图的x轴的数据是可以随便更换位置,不会影响图的含义的,明白了吧。”
2、核函数密度估计图
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。
大白话就是核密度图显示数值变量的分布,用来估计密度的,如果你有一系列空间点数据,那么核密度估计往往是比较好的可视化方法。
在Seaborn中使用kdeplot()函数制作核函数密度估计图,密度曲线函数的函数kdeplot()的格式如下:
- shade :是否填充与坐标轴之间的
- cdbar :是否显示颜色图例
- cmap:设置调色盘
- shade_lowest:最外围颜色是否显示
- n_levels:曲线个数
举个栗子: 本例中是对两个数值型数据做了关系图,通过kdeplot()这个函数,把收盘价(close)和涨跌比例(rise_rate)这两列的数值的密度分布情况显示在图形中。
sns.kdeplot(df['close'],df['rise_rate'],cbar = True, # 是否显示颜色图例shade = True, # 是否填充cmap = 'Reds', # 设置调色盘shade_lowest=False, # 最外围颜色是否显示n_levels = 10 # 曲线个数(如果非常多,则会越平滑))# 两个维度数据生成曲线密度图,以颜色作为密度衰减显示plt.show()
根据代码中分析的,我们都可以在下图中找到参数设置所起作用的地方。
从上图中可以得到什么信息呢? 直观的看,在12元是密度对大的地方,说明股票在12元的时间是最长的,涨跌幅以0 为中心,上下方向坡度较陡,说明了在0周边集中度较高,也就是涨跌幅在0附近的时间长,这正好和我们前面分析的特点有些吻合。
3、通关练习
这是本文最后一关,请同学利用本文数据,制作出收盘价(close)的直方图。
参考答案:见附件bar.py
4、本关总结
本关讲解的是分布图,分布图是方便我们来看数据分布情况的,本例中的直方图我们可以清晰的看到每一天具体的交易量,另外一例子是核函数密度估计图,从图中可以看到收盘价和涨跌幅的密度分布,从而对我们两组数据的整体关系有一个直观的展示。

课程总结
到这里,我们已经把主要的图形学习了一遍,老师给你再总结梳理一下本文的内容。分类图
首先呢,我们介绍了Seaborn模块的背景已及它和Matplotlib模块、Pandas模块的关系,它的安装也很传统,用pip就可以了,这里老师给你介绍了一个安装小技巧,对了,就是通过国内源安装速度会快很多。
再往下呢我们逐步讲解了矩阵图、关系图、分类图、分布图这四大类图,每大类图又还有小的分类,老师通过思维导图做了汇总:
 ~~
~~
老师在这里强调一下,老师只是取了浦发银行最近一年的数据,所以分析出来的结果一定会有时间上的局限性,仅仅作为短期参考,如果要通过这种方式深入研究股票,一定要下载多年的数据,这样才能把握全局,看的更高、更远。

若有收获,就点个赞吧
0 人点赞
