课程简介
本课程主要通过数据分析高手Pandas,辅助以Numpy、Matplotlib模块,对中国股市股票之王“贵州茅台”一年的数据进行了下载、分析,并以这些数据为基础,做了几个经典指标的代码实现,以图像的形式直观展示。
案例分析
课程导学
Hi~ 同学,你好啊~ ,很高兴和你一起通关学习,我是本门课程的老师,加法老师。
你即将要学习的课程——《股票数据分析的好搭档——Pandas》是一门实战课程!课程中主要是用Pandas这门技术对股票数据进行了分析,学过之后呢,你会对Pandas的使用有一个非常直观的了解,同时也会对股票数据有一个更深入的认识。
不知道你有没有接触过股票或者未来是否计划接触股票,如果想在股市上淘金,分析股票是必不可少的,但是A股股票多达三千多只,时间跨度长达十年,股票数据量之大可想而知,想要人工去分析数据,嗯,还是放弃幻想吧。
这时,万能的Python上场了(厉害表情)!!!不错,Python可以分析数据,战斗力强悍,而Python专业的数据分析模块就是Pandas。Pandas,为数据分析而生的战士,正式亮相啦~~
有没有很想学?那加法老师将在接下来的关卡中给你详细介绍一下如何用Pandas来分析股票数据!
前置知识
本课程主要通过数据分析高手Pandas,对中国股市股票之王“贵州茅台”的数据进行了分析,在分析的过程中需要借助Numpy、Matplotlib模块的知识,因此需要你对”Numpy模块”与”Matplotlib模块”有一定的了解。
最终效果展示
对于股票爱好者来说,要想分析一只股票是否值得投资,必须要关注数据就是收盘价和交易量。
以”贵州茅台”股票为例,从相关网站下载后的数据可以多种形式存储,本文是以Excel表格的形式呈现,比如下面这张图,是close(收盘价)和volume(交易量)两列值的部分数据截图。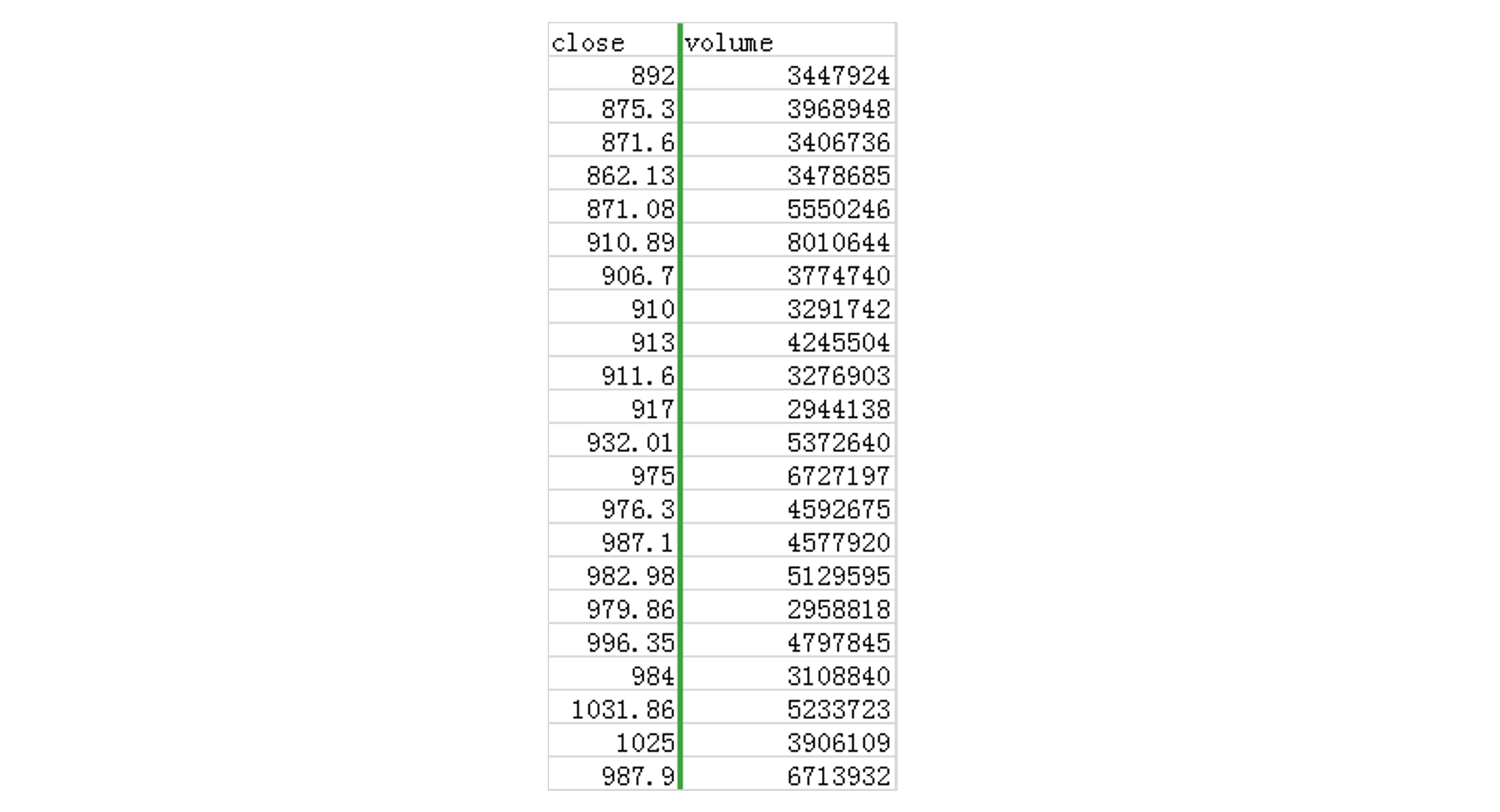
经过Pandas处理后,收盘价和交易量的关系就很直观的展现在我们面前: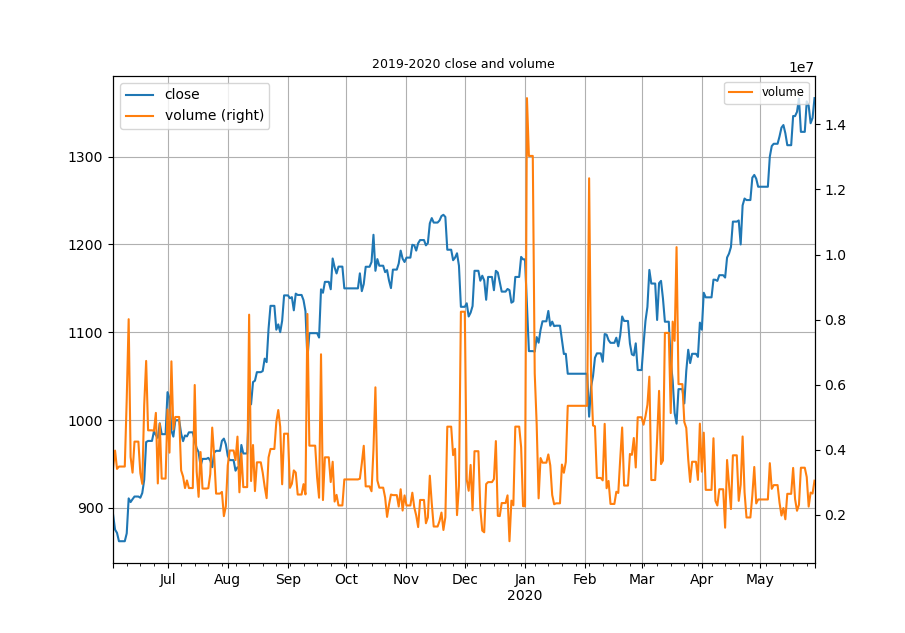
是不是一下子就一目了然,清晰的很呢。通过Pandas对数据处理后,再通过图片展示出来,股票的相关信息就很直观的呈现在我们面前,从而为我们分析这只股票的量价关系提供了很好的方法。
核心思路拆解
要想实现从0数据到清晰明朗的数据图片展示,我们需要完成以下的三个步骤,这也是你以后完成任何数据分析工作所要遵守的步骤。

学习目标
要想实现上图的呈现效果,需要用到以下的几个知识点,这也是老师希望你能够在学习完这门课程之后获得的技能点:
- Python的Pandas模块
- 股票数据下载的baostock模块
- 股票分析的talib模块
以上几个模块就构成了我们发财方阵啦,想要发财的同学们,跟上节奏,开始我们的第一关吧。
第一步 不打无准备之战——数据分析准备工作
正式闯关之前,再跟着老师回忆一下,我们的目标是~~~没有蛀牙(什么什么呀)!
我们本门课程的核心目标是用数据分析工具Pandas分析股票数据,帮助你走上人生巅峰。那要想实现这一目标,我们得先做一些准备工作,了解什么是数据分析,什么是Pandas,掌握安装所需要的工具。
加法老师从不打无准备之战,你也是,让我们马上开始吧!
1、数据分析的概念
想要用Pandas来分析股票数据,数据分析这个概念是必须要搞清楚的。
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
股票数据当然也是数据的一种。股票市场中起起落落的股价,吸引着大量的人们投身其中,他们都报有一个目的——发财。但现实是,他们也有一个共同的名字——韭菜。
如何在股市中找到发财真经就成了诸多股民的终极梦想。股票数据的分析就成为其中一条可以探索的道路,而Pandas的出现,犹如股票数据分析道路上出现的一辆跑车,极大的提高了股票数据分析的效率和速度,利用它,可以快速准确的从海量股票数据中找出价值、规律。。。。
“呯。。。”,一块砖头飞过。
小白同学:“老师,别说概念了,快讲Pandas,我要发财,不,,我要学习进步”
加法老师:“哦,哦,好的,先把砖头放下,别砸坏花花草草”
2、Pandas模块的用途
说起Pandas,它的功能可不简单。Pandas承担Python的强大功能之一——数据处理分析功能,可以解决数据的预处理工作,如数据类型的转换、缺失值的处理、描述性统计分析和数据的汇总等,正因为它的功能多,所以有着瑞士军刀的称号。
Pandas是基于Numpy的一种工具,或者说他们俩是铁哥们,俩个在一起可是1+1>2的效果。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。同时,Pandas也提供了大量能使我们快速便捷地处理数据的函数和方法。
Pandas的存在,使Python成为了强大而高效的数据分析环境,可以说,Pandas为Python的编程地位的提高贡献颇多。
你可能不知道,Pandas最初是被作为金融数据分析工具而开发出来,因此,Pandas为时间序列分析提供了很好的支持。所以,今天我们讲的股票数据分析,用Pandas作为工具是没错啦。
3、Pandas的安装
了解了Pandas的强大功能,接下来就需要安装Pandas。
Pandas的安装和Python惯有的安装方式一样,简单容易操作,通过pip命令就欧克了。
安装命令:pip install Pandas【备注:标红框】
如果要验证安装是否成功,可以引入Pandas库,如果没有报错就是安装成功啦。
当你输入后结果和上图一样时候,就是安装成功,可以使用这个模块了。
小白同学:“。。。。。。”
加法老师:“哈哈,小白同学,我可没有骗学费啊,真的就这么简单啊”
4、通关练习
这一关的知识非常简单,主要就是概念的介绍,还有一个简单的操作,安装Pandas,所以说,作业也很简单,就是大家在自己的机器上把Pandas安装好,并检查安装成功否,因为我们后面几关要用,加油哦。
5、本关总结
简单给大家总结一下本关所学内容,如图所示:
 学习完有些枯燥的概念,做完了准备工作,让我们来开始真正实战吧,万里长征第一步——数据的下载。
学习完有些枯燥的概念,做完了准备工作,让我们来开始真正实战吧,万里长征第一步——数据的下载。
第二步 巧妇难为无米之炊——数据的下载与处理
要想分析数据,首先得有数据,老人常说,巧妇难为无米之炊,那我们这一关的目标就是获取“米”——数据,顺便“洗一洗米”——简单处理数据。
先看一下加法老师下载下来的数据,成果丰硕啊,这也是在这一关我们要完成的目标——实现数据下载并做简单处理。

1、数据下载方式
股票数据的下载方式还是多种多样的,可以用我们以前学过的爬虫技术,从各大金融网站上扒取股票数据,很多网站也有提供比较友好的下载方式。
有一些收费的平台可以提供股票历史数据,比如tushare(原先不收费,我经常用,现在学坏了)。也有一些免费提供股票数据的平台,比如证券宝www.baostock.com。
鉴于我们的现实情况(没钱),当然要选择免费的平台——证券宝了,加法老师给你简单介绍下它。
证券宝是一个免费、开源的证券数据平台:**
- 提供大量准确、完整的证券历史行情数据、上市公司财务数据等。
- 通过Python API获取证券数据信息,满足量化交易投资者、数量金融爱好者、计量经济从业者数据需求。
- 返回的数据格式:
- Pandas DataFrame类型,以便于用Pandas/NumPy/Matplotlib进行数据分析和可视化。
- 同时支持通过BaoStock的数据存储功能,将数据全部保存到本地后进行分析。
- 支持语言:目前版本BaoStock.com目前只支持Python3.5及以上(暂不支持Python 2.x)
最最重要的,它将一如既往的以免费、开源的形式分享出来,大家的最爱啊。
2、数据的下载
要想顺利下载数据,首先要做的是安装证券宝。
我们还是用Python那简单的不要不要的方式来安装它,走起。
安装命令:pip install baostock
安装好之后就可以下载股票数据了(有点小激动呢,感觉离爆发户不远了),那么多支股票,真是挑花眼了啊,到底下载哪支股票的数据来分析呢?还是下载大A股最贵的股票—“贵州茅台”吧(名字里就带个‘贵’,怪不得贵),A股之王,市值、股价均第一啊!当前价格一千四百多了一股,一手(100股)要14万元!
我们要获取的数据为历史A股K线数据,这里老师要隆重介绍一个获取数据的关键函数,没有之一(是考点哦)。
获取历史A股K线数据:query_history_k_data_plus()
- 方法说明:通过这个API接口获取A股历史交易数据,可以通过参数设置获取日k线、周k线、月k线,以及5分钟、15分钟、30分钟和60分钟k线数据,适合搭配均线数据进行选股和分析。
- 返回类型:Pandas的DataFrame类型。
- 数据范围:能获取2006-01-01至当前时间的数据。
下面这段代码下载了贵州茅台2019年6月-2020年5月一年的数据,并把结果命名为“600519_stock_k_data.csv”,然后保存在D盘。
import baostock as bsimport pandas as pd#### 登陆系统 ####lg = bs.login()#### 获取上证指数19-20 K线数据 ####rs = bs.query_history_k_data_plus("sh.600519","date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST",#adjustflag:复权类型,默认不复权:3;1:后复权;2:前复权。start_date='2019-06-01', end_date='2020-05-31',#start:开始日期(包含),格式“YYYY-MM-DD”,frequency="d", adjustflag="3")#frequency:数据类型,默认为d,日k线;d=日k线#### 打印结果集 ####data_list = []while (rs.error_code == '0') & rs.next():# 获取一条记录,将记录合并在一起data_list.append(rs.get_row_data())result = pd.DataFrame(data_list, columns=rs.fields)#### 结果集输出到csv文件 ####result.to_csv("D:\\600519_stock_k_data.csv", index=False)print(result)#### 登出系统 ####bs.logout()
关于其中的关键函数query_history_k_data_plus(),加法老师做一下重点讲解:下图“返回类型”不太准确,最好改为“返回数据的列名 ” 
参数说明:
- 股票代码:sh或sz.+6位数字代码,代表要下载的股票数据,”sh.600519”表示我们要下载的贵州茅台;
- 返回类型:填写的参数表示我们想要哪些数据,那加法老师想要的数据是这些:

- start:开始日期(包含),格式“YYYY-MM-DD”;
- end:结束日期(不包含),格式“YYYY-MM-DD”;
- frequency:数据类型,默认为d,日k线;d=日k线、w=周、m=月、5=5分钟、15=15分钟、30=30分钟、60=60分钟;
- adjustflag:复权类型,默认不复权,1:后复权,2:前复权,3:不复权。
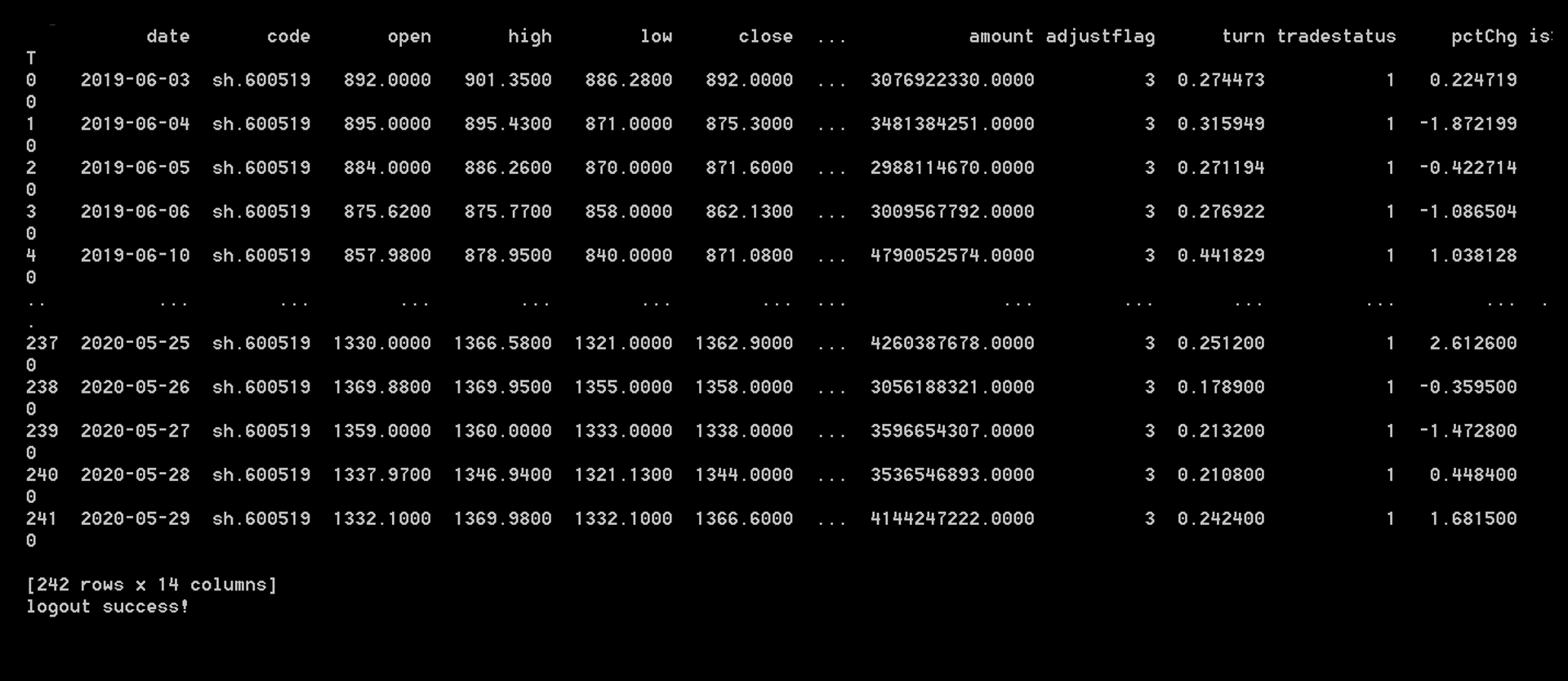
3、数据的处理
观察上面的数据我们发现,2019-06-07、2019-06-08和2019-06-09这三天是没有数据的,原因是端午节、周末两天不进行股票交易, 所以是没有数据的,但是在我们分析数据时需要连续的数据,所以我们对缺失的数据进行填充。
填充的原则是将周末的交易量和金额填充0,价格使用前一天的数据进行填充。
对缺失的数据进行填充,要用到一个函数:reindex()

以下是代码:
CSV_GM_PATH="D:\\600519_stock_k_data.csv" #我们前面的代码已经把数据下载到了这个文件里,这里直接读取df1=pd.read_csv(CSV_GM_PATH) #读取数据# 填充数据:生成日期索引idx = pd.date_range(start="2019-06-03", end="2020-05-29") #根据起始日期生成新的日期索引,包含了周末两天,日期连续df_date=df1.set_index("date") #把“date”这一列设置为索引df_date = df_date.set_index(pd.to_datetime(df_date.index)) #设置索引类型为日期型df_date_new=df_date.reindex(idx,method="ffill") #把生成的连续日期的索引引入进来,#保证日期连续,空值用前一天的填充
下图是没处理前的,缺少周末的日期和数据,是不连续的:
下图是处理后的数据,日期连续了,数值也用前一天的填充了:
小白同学:“这么几步就处理完数据了,这也太简单了,毛毛雨嘛!”
加法老师:“既然简单,老师就给你出道题目做做。”
小白同学:“当我没说”
4、通关练习
既然是实战课,老师就出道实战题,上面是处理的贵州茅台的股票数据,请同学们自己找到一只股票,把它的股票数据下载下来,并把间断日期的数据填充起来。<br />参考答案:【给学生一个参考答案,也就是代码文件,最后我们以资料包形式把代码上传到平台上,给到学生做参考】<br />参考程序:<br />见资源库 答案
5、本关总结
数据处理是数据分析很重要的一步,有一个流行的说法是“错误的数据产生错误的结果,垃圾的数据产生垃圾的结果”,如果数据是没经过处理的,那用这种数据来做分析,结果也可能会产生不理想的结果。所以一般数据在被用来分析前,一般都要经过处理。
 这一关学习了数据分析前的两大步骤,数据下载和数据处理,Pandas都提供了相应的接口来实现相应的功能。数据准备好了,开始分析数据吧。
这一关学习了数据分析前的两大步骤,数据下载和数据处理,Pandas都提供了相应的接口来实现相应的功能。数据准备好了,开始分析数据吧。
第三步 股神修炼第一步——-股票波动率
1、波动率的概念与含义
股票每天的价格都是起起伏伏,每天都会有一个最高价和最低价。

为了通过数据来记录股票每天的波动情况,我们引入了一个概念——股票波动率。股票波动率就是在一定时间周期内,以最高价/最低价来作为股票波动的指标。
其实当股票出现了波动时,并不一定就是坏事。若是一只股票经常都很活跃,却突然变得波动比较小,那么它就有可能会跌。若是一只股票长期都很平稳,却突然有了波动,那么这只股票倒是有涨的可能。所以股票的波动其实是非常正常的现象,是股票的一种特点,利用好了,可以打价格差来赚钱哦。
2、通过程序计算一只股票的波动率
了解了波动率的概念,我们开始着手来编程实现它,以我们上一关的数据为基础,实现代码如下,是不是看着有点多啊!
def get_grouping(total,group_len): #按30天分组group_count=total//group_lengroup_index=np.arange(total)for i in range(group_count):group_index[i * group_len:(i+1)*group_len]=igroup_index[(i+1) * group_len:]=i+1return group_index.tolist() #返回结果转为列表#根据索引分组计算成交额、最低价和最高价#为负表示先出现最高价再出现最低价,即下跌波动def get_ceiling_price(price):return price.idxmax() > price.idxmin() and np.max(price) or (-np.max(price)) #idxmax计算能够获取到最大值的索引位置(整数),如果是上升的取正值,如果是下降的取负值#根据索引分组计算,取出最低价和最高价,符号仅仅表示上升还是下降。period=30 #选择计算波动率的周期group_index=get_grouping(len(df_date_new),period)df_date_new['group_index']=group_index # 将分组的结果作为“group_index”一列加入到数据集里去group=df_date_new.groupby('group_index').agg({'volume':'sum','low':'min','high':get_ceiling_price})data_col=pd.DataFrame({'group_index':group_index,'date':idx}) #创建一数据集,有两列 group_index dategroup['date']=data_col.groupby('group_index').agg('first') #取出data_col 每一个数据集的第一个日期给group 作为新一列group['ripples_ratio']=group.high/group.low #计算波动率 赋值给新的一列 ripples_ratioripples=group.sort_values('ripples_ratio',ascending=False) #对波动率这一列排序,降序
小白同学:“老师,你不是说Python很简单吗,用起来节约生命吗,怎么这么长的代码,我不干了,退学费!”
加法老师:“Python当然简单了,但是股票赚钱可不简单哦,要不然股市里怎么出那么多百万富翁啊”
小白同学(精神一震):“老师,别说了,为了钱,,不不,为了进步,这点代码难不到我,快讲”
为了更好的理解,下面老师将对代码进行分解,分段介绍。
1.波动率要选择一个周期,我们选择30天为一单位
period=30
2.设计一个函数 get_grouping(),用来以30为单位把数据分组
group_index=get_grouping(len(df_date_new),period) #调用这个函数,参数为数据的行数和周期数30def get_grouping(total,group_len): #按30天分组group_count=total//group_len #数据总行数除以周期数30,得到分组数group_countgroup_index=np.arange(total) # 用numpy 生成一组索引 group_index,长度为数据的长度for i in range(group_count): #进行一个for循环,对group_index进行修改,每30个元素改成相同的一个值,这个值就是组号。group_index[i * group_len:(i+1)*group_len]=igroup_index[(i+1) * group_len:]=i+1return group_index.tolist() #返回结果转为列表
3.将函数的结果作为数据的一列加入到数据,这样每一行数据都有了自己的组号。
df_date_new['group_index']=group_index
4.以刚加的组号作为分组已经,对数据进行处理
group=df_date_new.groupby('group_index').agg({ #以group_index 来分组'volume':'sum', #‘volumn’ 分组内求和'low':'min', #‘low’是当天最低价,这是找出组内最低的low值'high':get_ceiling_price #high是每天最高值,这里调用了 get_ceiling_price 函数})
5.使用get_ceiling_price 函数,作用是找出分组内的最高值,并且对价格上升还是下降判断并返回结果
def get_ceiling_price(price):return price.idxmax() > price.idxmin() and np.max(price) or (-np.max(price))#idxmax计算能够获取到最大值的索引位置(整数),如果是上升的取正值,如果是下降的取负值
6.有了前面的数据处理,就可以计算波动率了
data_col=pd.DataFrame({'group_index':group_index,'date':idx})#创建一数据集,有两列 group_index、 dategroup['date']=data_col.groupby('group_index').agg('first')#取出data_col 每一个数据集的第一个日期给group 作为新一列group['ripples_ratio']=group.high/group.low#计算波动率 赋值给新的一列 ripples_ratioripples=group.sort_values('ripples_ratio',ascending=False) #对波动率这一列排序,降序
程序运行后的部分结果如下图:
最右边一列就是我们算出来的波动率。
3、通关练习
到了练习时间了,上一关老师让你们下载了一只股票的数据并处理了,这一关老师让你们继续处理你们的数据,以20天为周期,计算出你手里股票的波动率。
参考答案 见资源库答案
4、本关总结
总体来讲,波动率的计算稍微有些费力,但这个指标可以很好的帮助股民来掌握一支股票的特征,在学习编程的过程中,也可以掌握一些Python有用的函数,比如tolist 把一维numpy数组转为列表,sort_values对元素进行排序,groupby对数据进行分组,idxmax、idxmin是分别找出最大值和最小值的id位置,在数据分析中,这些都是很有用的函数。
 经过这一大波程序的洗礼,我们来点小清新的程序,下一关走起。
经过这一大波程序的洗礼,我们来点小清新的程序,下一关走起。
第四步 集各派秘籍于一身——股票数据的花式玩法
要真正得出股票的走势,要多方面去了解股票的特性,仅仅知道股票的波动率是远远不够的,还要根据实际情况来分析股票的多个特征,本关就介绍几个提取股票特征的方法,多多学习这些方法,会让你分析股票的时候有更完整视野。
1、计算股票涨跌幅的方式
涨跌幅定义为今日收盘价减去昨日收盘价,该怎么写这个程序呢?好像有点复杂,其实对于Pandas来说,早就把这个常用指标定义好了,就是diff()函数。
自动计算出今天和前一天的数据差值:diff()。
采用diff()函数,对close这一列的值进行了差值计算,就是每一个元素减去前一个元素所得到的值,把得到的值作为一列元素加入到现数据中:
rise=df_date_new.close.diff() #diff函数,对close这一列的值进行了差值计算,就是每一个元素减去前一个元素所得到的值df_date_new['rise']=rise #把得到的值作为一列元素加入到现数据中df_date_new['rise_rate']=df_date_new['rise']/(df_date_new['close']-df_date_new['rise']) #计算涨跌幅的百分比df_date_new['rise_rate']=round(df_date_new['rise_rate']*100,2) #改成百分之几的格式
采用diff()这个既有的函数,可以省去了很多功夫,结果如下,最右边两列分别是差值和差值的百分比: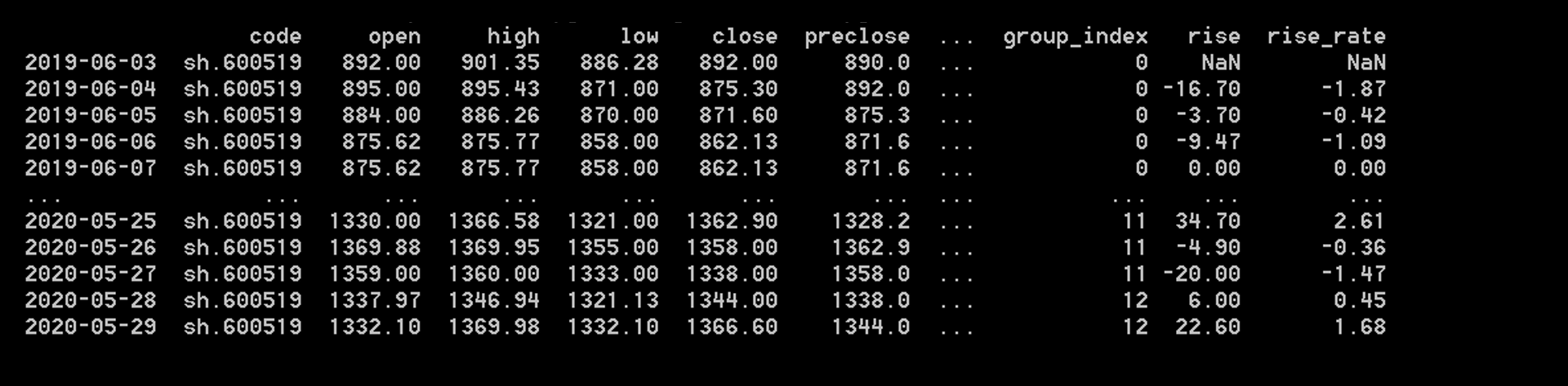
从上图中的rise_rate这一列数据可以简单得出一个结论,它的涨跌幅都在2%以下波动,振幅并不大,不适合做波段。
2、编写股票指标MACD
MACD可是一个大名鼎鼎的指标,没有哪个股票软件不把它放在第一个指标位置,它又被称为异同移动平均线,是从双指数移动平均线发展而来的,计算两条不同速度(长期与中期)的异同移动平均线(EMA)的差离状况来作为研判行情的基础。依据MACD指标衍生出很多买卖股票的技术,比如经典的“金叉买,死叉卖”等等。具体计算方法有些复杂,我们也不去管它的具体计算方法,因为第三方库talib已经写好了这个函数,拿来直接用就可以了。
1、首先要引入这个talib包,如果没有,要先安装,还是老方法。
安装代码:pip install talib
import talib as ta
2、通过ta.MACD()这个函数,就可以得出macd的几项指标:

通过MACD函数对close值进行计算,得出几项结果放入到df_date_new数据里:
close = [float(x) for x in df_date_new['close']] #把“close”的值变为浮点型df_date_new['macd'],df_date_new['macdsignal'],df_date_new['macdhist']=ta.MACD(np.array(close),fastperiod=12,slowperiod=26,signalperiod=9)#通过MACD函数对close值进行计算,得出几项结果放入到df_date_new数据里
下面是程序运行后df_date_new的显示结果,因为是取了12 天和26天的平均值,所以前12行和前26行是部分没有结果的:
下图将MACD结果数据绘制成图,更加直观。
通过图片展示的形式就可以用指标来理解股票了,比如“金叉买,死叉卖”来解释这个图的话,可以找到金叉点(红圈)买、死叉点(黄圈)卖,本图只是抛砖引玉,更多的 内容需要你来解密。
3、绘制成交量和收盘价的关系时间序列图
加法老师:“股票里有一个非常可值得挖掘信息就是交易量和股价的关系。。。”
小白同学:“量增价涨,短期买入信号、量增价平,持股待涨信号、量增价跌,弃卖观望信号。。。。”
加法老师:“小白同学表现不错嘛,量价关系口诀背的这么好,今天我们就来把他们的关系画出来,分析起来就更方便了”
以下程序用了Matplotlib模块的知识,以收市价close 和交易量volume两个元素为内容进行了绘图,时间跨度为2019.6-2020.5。
df_date_new[['close','volume']].plot(secondary_y='volume',grid=True,label="maotai")plt.title('2019-2020 close and volume',fontsize='9')plt.legend(loc='best',fontsize='small')plt.show()
图片显示的结果如下图所示,是不是一眼看去看不出来什么逻辑啊,如果要分析出量价关系,还需要有学习一定的股票知识才可以,这里展现出了图片的显示方式,个股的分析技术还需要自己多学习啊,像小白同学那样,至少量价关系的口诀要背会看懂哦。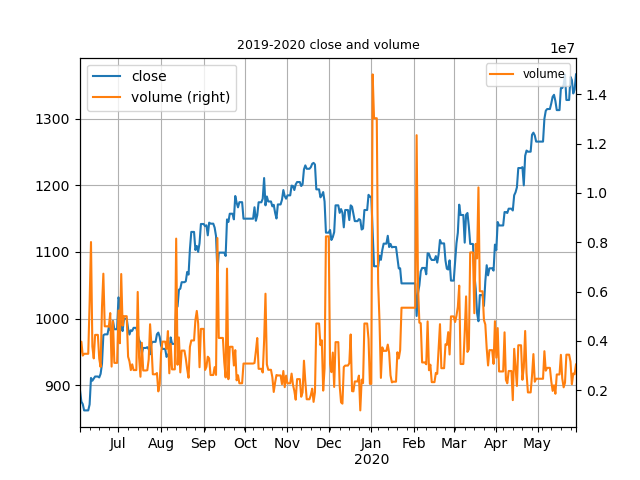
4、通关练习
本关讲了几个Pandas里的股票函数,diff函数、 MACD函数,本节的作业就是利用这两个函数,根据你前面下载的股票数据,算出它 的涨跌幅和MACD 数据,并利用matplotlib模块把它画出来。
参考答案:见资源库答案
除了本章讲的股票函数,还有很多股票函数需要大家自己去探索,本关只是给大家起个引子,让大家了解Python在股票数据分析上的强大,很多复杂的指标都已经给封装好了。
 要分析好股票数据,Python还有其他模块可以辅助Pandas做好数据分析,如Numpy 、talib、Matplotlib等等。
要分析好股票数据,Python还有其他模块可以辅助Pandas做好数据分析,如Numpy 、talib、Matplotlib等等。
总结与拓展
课程总结
好了,这门课程到这里就结束了,鉴于股票数据和指标的复杂和繁多,Python上支持股票数据分析的函数也是相当的多,要全部掌握还是不小的工作量呢,对股票数据分析有兴趣的同学课后要努力学习啊,本门课学习的知识点也不少,加法老师帮大家总结了重点知识树,往下看:
 结合这张重点知识树,老师带领大家,按照数据分析的流程,回忆一下我们所学的知识。
结合这张重点知识树,老师带领大家,按照数据分析的流程,回忆一下我们所学的知识。
- 数据下载:数据分析首先要有数据,我们用了免费下载股票数据的平台——证券宝,它的网址是www.baostock.com。安装baostock模块的方式也很简单,pip install baostaock 这个命令就可以了。
- 数据处理:下载好的数据一般要经过数据处理(也叫数据清洗)这道程序,通常是对残缺的和不连续的数据进行处理,处理的方式有很多种,本文用的是前值填充法,经过处理的数据,就是健康的可以用的数据了。
- 股票数据分析:股票分析的方法有很多很多,前人已经总结了很多公式和例子,本文讲解了几个经典指标,MACD、涨跌幅、波动率,这些指标Python也有相应的函数来计算它,比如talib.MACD() ,diff(), 还有Pandas的分组函数groupby,排序函数 sort_values(),定位函数idxmax()等等。
- ps:Python还有numpy模块 matplotlib模块,都是对数据分析很好的助手,因为是其他课程的知识点,本文没有过多介绍。
知识拓展
本文只是对“贵州茅台”这么一只股票做了分析,如果同学掌握好了本文所有内容,也可以下载“上证指数”的股票信息,这个指数的样本股是在上海证券交易所全部上市股票,是整体股票市场情况的体现,通过把它和个股进行对比,可以得出个股是否强于大盘,从而为你买股票得出一个依据。如果你有兴趣的话,可以通过本节的知识点去分析分析。
小白同学:“老师,学了这么多,我都感觉自己是股神了,我要去驰骋股场了,还有什么话叮嘱我吗?”
加法老师:“为师唯一的希望,就是,发财了别忘记老师啊。。”

若有收获,就点个赞吧
0 人点赞
