- 并发下 ArrayList 不安全
- CopyOnWrite 写入时复制 COW
set不安全">
set不安全- Map不安全
- Callable接口
- 常用的辅助类
- volatile
- ReadWriteLock(读写锁)
- 阻塞队列
- SynchronousQueue 同步队列
- OOM
- 线程池:
">三大方法
7大参数">
7大参数- 四种拒绝策略:
- 池的最大的大小如何去设置!
- 理解 HashMap 加载因子 loadFactor
- 必须掌握的hashcode()方法
- 四大函数式接口(必需掌握)
- springboot配置集成log4j
- java stream中Collectors的用法">java stream中Collectors的用法
- 一、什么是泛型
并发下 ArrayList 不安全
出现 java.util.ConcurrentModificationException 并发修改异常!
/*** 解决方案;* 1、List<String> list = new Vector<>();* 2、List<String> list = Collections.synchronizedList(new ArrayList<>());* 3、List<String> list = new CopyOnWriteArrayList<>();*/// CopyOnWrite 写入时复制 COW 计算机程序设计领域的一种优化策略;// 多个线程调用的时候,list,读取的时候,固定的,写入(覆盖)// 在写入的时候避免覆盖,造成数据问题!// 读写分离// CopyOnWriteArrayList 比 Vector Nb 在哪里?
CopyOnWrite 写入时复制 COW
1.什么是COW?
Copy-On-Write简称COW。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。
2COW的应用场景
3.COW的缺陷
很明显,在写场合,复制整个数组的开销是很大的,因此需要注意
package cn.maidaotech.java07.syncaddlock.listunsafe;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.UUID;import java.util.Vector;import java.util.concurrent.CopyOnWriteArrayList;import java.util.concurrent.TimeUnit;//java.util.ConcurrentModificationException 并发修改异常!public class ListTest {public static void main(String[] args) {// !并发下 ArrayList 不安全// List<String> list = new ArrayList<>();//java.util.ConcurrentModificationException并发修改异常// for (int i = 1; i <=10; i++) {// new Thread(()->{// list.add(UUID.randomUUID().toString().substring(0,5));// System.out.println(list);// }).start();// }// System.out.println(list.size());/*** 解决方案:* 1、List<String> list = new Vector<>();*/// List<String> list = new Vector<>();// for (int i = 1; i <=10; i++) {// new Thread(()->{// list.add(UUID.randomUUID().toString().substring(0,5));// System.out.println(list);// },String.valueOf(i)).start();// }// try {// TimeUnit.SECONDS.sleep(1);// System.out.println(list.size());// } catch (Exception e) {// e.printStackTrace();// }/*** 解决方案:* 2. List<String> list = Collections.synchronizedList(new ArrayList<>());*/// List<String> list = Collections.synchronizedList(new ArrayList<>());// for (int i = 0; i < 10; i++) {// new Thread(()->{// list.add(UUID.randomUUID().toString().substring(0, 5));// System.out.println(list);// },String.valueOf(i)).start();// }// try {// TimeUnit.SECONDS.sleep(1);// System.out.println(list.size());// } catch (Exception e) {// e.printStackTrace();// }/*** 解决方案:* 3.List<String> list = new CopyOnWriteArrayList<>(); COW(写时复制)*/// CopyOnWrite 写入时复制 COW 计算机程序设计领域的一种优化策略;// 多个线程调用的时候,list,读取的时候,固定的,写入(覆盖)// 在写入的时候避免覆盖,造成数据问题!// 读写分离// CopyOnWriteArrayList 比 Vector Nb 在哪里?List list = new CopyOnWriteArrayList<>();for (int i = 0; i < 10; i++) {new Thread(()->{list.add(UUID.randomUUID().toString().substring(0, 5));System.out.println(list);},String.valueOf(i)).start();}try {TimeUnit.SECONDS.sleep(1);System.out.println(list.size());} catch (Exception e) {e.printStackTrace();}}}
CopyOnWriteArrayList 比 Vector Nb 在哪里?
CopyOnWriteArrayList 使用的lock锁的机制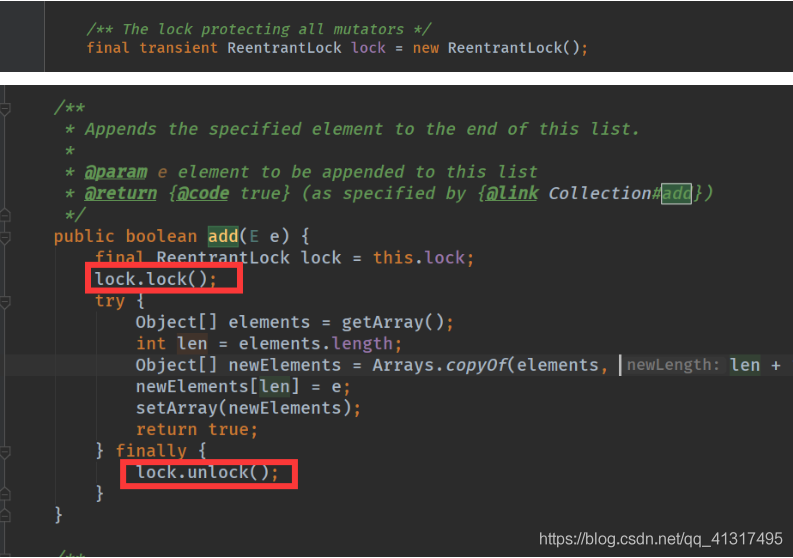
Vector 使用的是synchronized锁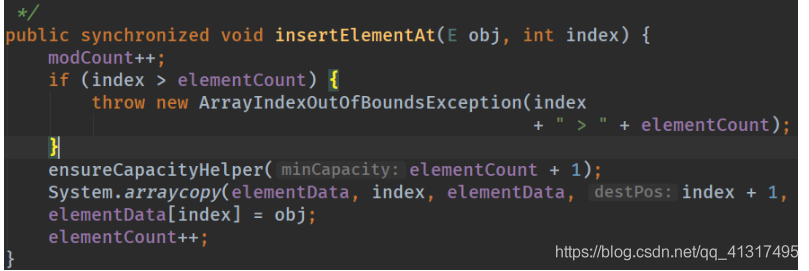
synchronized 和 lock锁的区别
synchronized 是java内置的关键字,lock是一个java类
synchronized 无法获取锁的状态,lock 可以判断是否获得了锁
synchronized 会自动释放锁,lock不会自动释放锁,需要自己手动释放锁,如果不释放锁,会造成死锁
synchronized 线程一(获得锁,然后锁阻塞了),线程二(等待,然后还是傻傻的等待),lock锁就不一定会等待下去
synchronized 可重入锁,不可以被中断,非公平,lock 可重入锁,可判断锁,是否为公平锁,可以自行设置
synchronized 适合少量的代码同步问题,lock适合大量的代码同步问题
Vector 和 CopyOnWriteArrayList
Vector 的曾删改查方法都加上了synchronized锁,保证同步的情况下,因为每个方法都要去获得锁,所以性能就会大大下降。
CopyOnWriteArrayList 方法只是在增删改方法上增加了ReentrantLock锁,但是他的读方法不加锁,所以在读的方面就要比Vector性能要好,CopyOnWriteArrayList适合读多写少的并发情况,读写分离,在写的时候复制出一个新的数组,完成插入、修改、删除操作,在完成操作后,将这个新的数组赋值给一个array。
set不安全
package cn.maidaotech.java07.syncaddlock.listandsetunsafe;import java.util.Collections;import java.util.HashSet;import java.util.Set;import java.util.UUID;import java.util.concurrent.TimeUnit;/*** 同理可证 : ConcurrentModificationException* 1、Set<String> set = Collections.synchronizedSet(new HashSet<>());* 2、*///java.util.ConcurrentModificationException 并发修改异常public class SetTest {public static void main(String[] args) {// Set set = new HashSet<>();// for (int i = 0; i < 10; i++) {// new Thread(()->{// set.add(UUID.randomUUID().toString().substring(0, 5));// System.out.println(set);// },String.valueOf(i)).start();// }// System.out.println(set.size());/*** 解决方案* 1.Set set = Collections.synchronizedSet(new HashSet<>());*/// Set set = Collections.synchronizedSet(new HashSet<>());// for (int i = 0; i < 10; i++) {// new Thread(()->{// set.add(UUID.randomUUID().toString().substring(0, 5));// System.out.println(set);// },String.valueOf(i)).start();// }// try {// TimeUnit.SECONDS.sleep(1);// System.out.println(set.size());// } catch (Exception e) {// e.printStackTrace();// }}}
HashSet的底层:
public HashSet() {map = new HashMap<>();}// add set 本质就是 map key是无法重复的!public boolean add(E e) {return map.put(e, PRESENT)==null;}private static final Object PRESENT = new Object(); // 不变得值
Map不安全
package com.kuang.unsafe;import java.util.Collections;import java.util.HashMap;import java.util.Map;import java.util.UUID;import java.util.concurrent.ConcurrentHashMap;// ConcurrentModificationExceptionpublic class MapTest {public static void main(String[] args) {// map 是这样用的吗? 不是,工作中不用 HashMap// 默认等价于什么? new HashMap<>(16,0.75);// Map<String, String> map = new HashMap<>();// 唯一的一个家庭作业:研究ConcurrentHashMap的原理Map<String, String> map = new ConcurrentHashMap<>();for (int i = 1; i <=30; i++) {new Thread(()->{map.put(Thread.currentThread().getName(),UUID.randomUUID().toString().substring(0,5));System.out.println(map);},String.valueOf(i)).start();}}}
Callable接口
1、可以有返回值 2、可以抛出异常 3、方法不同,run()/ call()
package cn.maidaotech.java07.syncaddlock.callable;import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import java.util.concurrent.FutureTask;public class CallableTest {public static void main(String[] args) throws InterruptedException, ExecutionException {MyThread thread =new MyThread();FutureTask futureTask = new FutureTask<>(thread);//适配类new Thread(futureTask,"A").start();new Thread(futureTask,"B").start();// 结果会被缓存,效率高Integer o = (Integer) futureTask.get();//这个get 方法可能会产生阻塞!把他放到最后// 或者使用异步通信来处理!System.out.println(o);}}class MyThread implements Callable<Integer>{@Overridepublic Integer call() throws Exception {System.out.println("call()");//耗时操作return 1024;}}
细节: 1、有缓存 2、结果可能需要等待,会阻塞!
常用的辅助类
CountDownLath(倒计时锁)

package cn.maidaotech.java07.syncaddlock.assistclass;import java.util.concurrent.CountDownLatch;public class CountDownLathDemo {public static void main(String[] args) throws InterruptedException {// 总数是6,必须要执行任务的时候,再使用!CountDownLatch countDownLatch = new CountDownLatch(6);for (int i = 1; i <=6; i++) {new Thread(()->{System.out.println(Thread.currentThread().getName()+"====>go out");countDownLatch.countDown();//数量-1},String.valueOf(i)).start();}countDownLatch.await(); // 等待计数器归零,然后再向下执行System.out.println("Close door");// 等待计数器归零,然后再向下执行//每次有线程调用 countDown() 数量-1,假设计数器变为0,countDownLatch.await() 就会被唤醒,继续//执行!}}
原理:
countDownLatch.countDown(); // 数量-1
countDownLatch.await(); // 等待计数器归零,然后再向下执行 每次有线程调用 countDown() 数量-1,假设计数器 变为0,countDownLatch.await() 就会被唤醒,继续 执行!
CyclicBarrier (可用于加法计数器)

加法计数器
package cn.maidaotech.java07.syncaddlock.assistclass;import java.util.concurrent.BrokenBarrierException;import java.util.concurrent.CyclicBarrier;public class CyclicBarrirDemo {public static void main(String[] args) {/*** 集齐7颗龙珠召唤神龙*/// 召唤龙珠的线程CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {System.out.println("召唤神龙成功");});for (int i = 1; i < 8; i++) {final int temp = i;new Thread(() -> {System.out.println(Thread.currentThread().getName() + "召唤了第" + temp + "颗龙珠");try {cyclicBarrier.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}},String.valueOf(i)).start();}}}
Semaphore (信号量)

抢车位! 6车—-3个停车位置
package cn.maidaotech.java07.syncaddlock.assistclass;import java.util.concurrent.Semaphore;import java.util.concurrent.TimeUnit;public class SemaphoreDemo {public static void main(String[] args) {// 抢车位Semaphore semaphore = new Semaphore(3);for (int i = 1; i < 7; i++) {new Thread(() -> {try {semaphore.acquire();// 得到System.out.println(Thread.currentThread().getName()+"抢到车位");TimeUnit.SECONDS.sleep(2);System.out.println(Thread.currentThread().getName()+"离开车位");} catch (InterruptedException e) {e.printStackTrace();}finally{semaphore.release();//释放}}).start();}//原理:semaphore.acquire() 获得,假设如果已经满了,等待,等待被释放为止!//semaphore.release(); 释放,会将当前的信号量释放 + 1,然后唤醒等待的线程!//作用: 多个共享资源互斥的使用!并发限流,控制最大的线程数!}}
volatile
在Java并发编程中常用于保持内存可见性和防止指令重排序。
ReadWriteLock(读写锁)

package cn.maidaotech.java07.syncaddlock.readwritelock;import java.util.HashMap;import java.util.Map;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReadWriteLock;import java.util.concurrent.locks.ReentrantLock;import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadWriteLockDemo {public static void main(String[] args) {// MyCahe myCahe = new MyCahe();MyCaheLock myCahe = new MyCaheLock();//写入for (int i = 1; i < 6; i++) {final int temp = i;new Thread(()->{myCahe.put(temp+"", temp+"");},String.valueOf(i)).start();}//读取for (int i = 1; i < 6; i++) {final int temp = i;new Thread(()->{myCahe.get(temp+"");},String.valueOf(i)).start();}}}/*** 自定义缓存 加锁*/class MyCaheLock{private volatile Map<String,Object> map = new HashMap<>();// 读写锁: 更加细粒度的控制private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();private Lock lock = new ReentrantLock();//存,写入的时候,只希望同时只有一个线程写public void put(String key,Object value){readWriteLock.writeLock().lock();try {System.out.println(Thread.currentThread().getName()+"写入"+key);map.put(key, value);System.out.println(Thread.currentThread().getName()+"写入ok");} catch (Exception e) {e.printStackTrace();}finally{readWriteLock.writeLock().unlock();}}//读,取public void get(String key){readWriteLock.readLock().lock();try {System.out.println(Thread.currentThread().getName()+"读取key");map.get(key);System.out.println(Thread.currentThread().getName()+"读取ok");} catch (Exception e) {e.printStackTrace();}finally{readWriteLock.readLock().unlock();}}}/*** 自定义缓存*/class MyCahe{private volatile Map<String,Object> map = new HashMap<>();//存,写public void put(String key,Object value){System.out.println(Thread.currentThread().getName()+"写入"+key);map.put(key, value);System.out.println(Thread.currentThread().getName()+"写入ok");}//读,取所有人都可以读!public void get(String key){System.out.println(Thread.currentThread().getName()+"读取key");Object o = map.get(key);System.out.println(Thread.currentThread().getName()+"读取ok");}}
阻塞队列
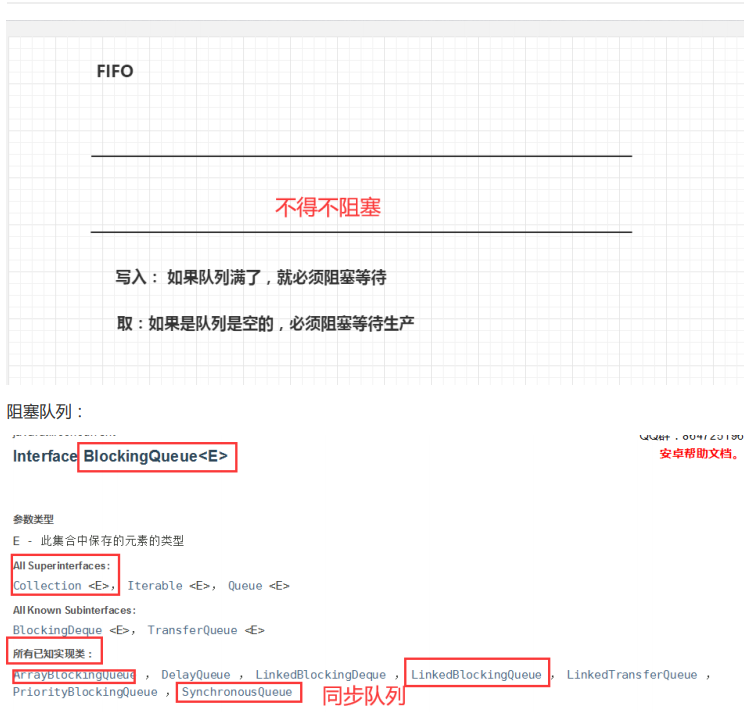
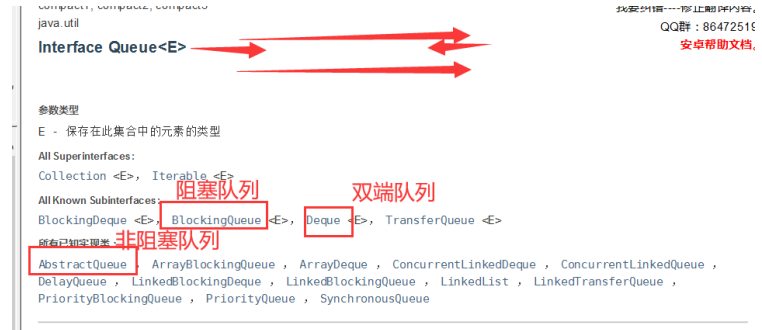
BlockingQueue BlockingQueue 不是新的东西 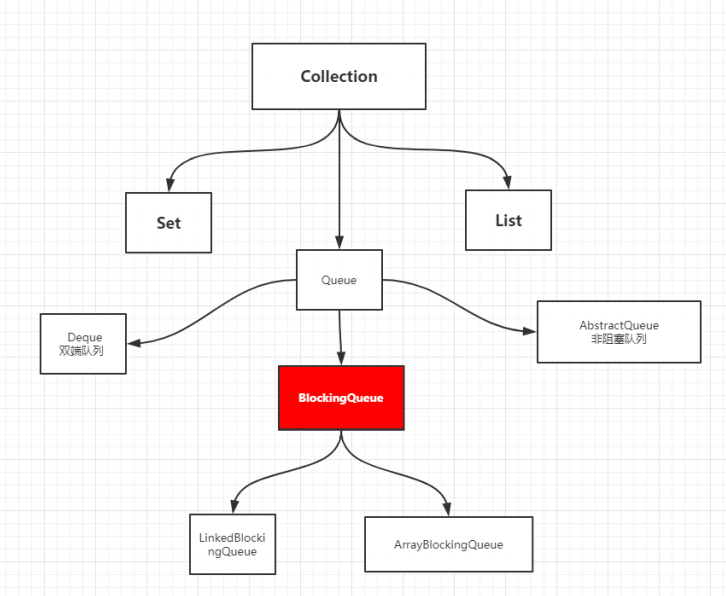
什么情况下我们会使用 阻塞队列:多线程并发处理,线程池!
学会使用队列
添加、移除
四组API 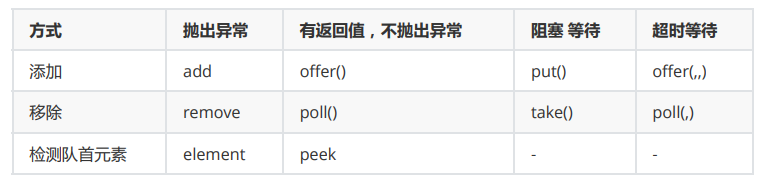
package cn.maidaotech.java07.syncaddlock.queue;import java.util.concurrent.ArrayBlockingQueue;/*** 抛出异常*/public class Test1 {public static void main(String[] args) {//队列的大小ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);//添加System.out.println(blockingQueue.add("a"));System.out.println(blockingQueue.add("b"));;System.out.println(blockingQueue.add("c"));;//Exception in thread "main" java.lang.IllegalStateException: Queue full//System.out.println(blockingQueue.add("d"));System.out.println("============");System.out.println(blockingQueue.remove());System.out.println(blockingQueue.remove());System.out.println(blockingQueue.remove());// java.util.NoSuchElementException 抛出异常!//blockingQueue.remove();}}
package cn.maidaotech.java07.syncaddlock.queue;import java.util.concurrent.ArrayBlockingQueue;/*** 有返回值,没有异常*/public class Tets2 {public static void main(String[] args) {//队列的大小ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);System.out.println(blockingQueue.offer("a"));System.out.println(blockingQueue.offer("b"));System.out.println(blockingQueue.offer("c"));// System.out.println(blockingQueue.offer("d")); // false 不抛出异常!System.out.println("================");System.out.println(blockingQueue.poll());System.out.println(blockingQueue.poll());System.out.println(blockingQueue.poll());System.out.println(blockingQueue.poll()); // null 不抛出异常!}}
package cn.maidaotech.java07.syncaddlock.queue;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.TimeUnit;/*** 等待,阻塞(一直阻塞)*/public class Test3 {public static void main(String[] args) throws InterruptedException {//队列大小ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);//一直阻塞blockingQueue.put("a");blockingQueue.put("b");blockingQueue.put("c");//blockingQueue.put("d"); // 队列没有位置了,一直阻塞System.out.println(blockingQueue.take());System.out.println(blockingQueue.take());System.out.println(blockingQueue.take());System.out.println(blockingQueue.take()); // 没有这个元素,一直阻塞}}
package cn.maidaotech.java07.syncaddlock.queue;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.TimeUnit;/*** 等待,阻塞,(等待超时)*/public class Test4 {public static void main(String[] args) throws InterruptedException {//队列的大小ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);blockingQueue.offer("a");blockingQueue.offer("b");blockingQueue.offer("c");blockingQueue.offer("d",2,TimeUnit.SECONDS); // 等待超过2秒就退出System.out.println("===========");System.out.println(blockingQueue.poll());System.out.println(blockingQueue.poll());System.out.println(blockingQueue.poll());blockingQueue.poll(2,TimeUnit.SECONDS); // 等待超过2秒就退出}}
SynchronousQueue 同步队列
package cn.maidaotech.java07.syncaddlock.queue;import java.util.concurrent.BlockingQueue;import java.util.concurrent.SynchronousQueue;import java.util.concurrent.TimeUnit;/*** 同步队列 和其他的BlockingQueue 不一样, SynchronousQueue 不存储元素* put了一个元素,必须从里面先take取出来,否则不能在put进去值! 没有容量, 进去一个元素,必须等待取出来之后,才能再往里面放一个元素!* put、take*/public class SynchronousQueueDemo {public static void main(String[] args) {BlockingQueue blockingQueue = new SynchronousQueue<>();// 同步队列new Thread(() -> {try {System.out.println(Thread.currentThread().getName() + "put 1");blockingQueue.put("1");System.out.println(Thread.currentThread().getName() + "put 2");blockingQueue.put("2");System.out.println(Thread.currentThread().getName() + "put 3");blockingQueue.put("3");} catch (InterruptedException e) {e.printStackTrace();}},"T1").start();new Thread(()->{try {TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());TimeUnit.SECONDS.sleep(3);System.out.println(Thread.currentThread().getName()+"=>"+blockingQueue.take());} catch (InterruptedException e) {e.printStackTrace();}},"T2").start();}}
OOM
为out of memory的简称,称之为内存溢出。
Java应用程序在启动时会指定所需要的内存大小,其主要被分割成两个不同的部分,分别为Head space(堆空间-Xmx指定)和Permegen(永久代-XX:MaxPermSize指定),
通常来说,造成如上图异常的基本上程序代码问题而造成的内存泄露。这种异常,通过dump+EMA可以轻松定位。(EMA虽功能强大,但对机器性能内存要求极高)
java.lang.OutOfMemeoryError:GC overhead limit exceeded(超出GC开销限制)
如上异常,即程序在垃圾回收上花费了98%的时间,却收集不回2%的空间,通常这样的异常伴随着CPU的冲高。定位方法同上
Java.lang.OutOfMemoryError: PermGen space(JAVA8引入了Metaspace区域) Metaspace(原空间)
永久代内存被耗尽,永久代的作用是存储每个类的信息,如类加载器引用、运行池常量池、字段数据、方法数据、方法代码、方法字节码等。基本可以推断PermGen占用大小取决于被加载的数量以及类的大小。定位方法同上。

产生这种异常的原因是由于系统在不停地创建大量的线程,且不进行释放。系统的内存是有限的,分配给JAVA应用的程序也是有限的,系统自身能允许创建的最大线程数计算规则:
(MaxProcessMemory-JVMMemory-ReservedOsMemory)/ThreadStackSize
其中
MaxProcessMemory:指的是一个进程的最大内存
JVMMemory :JVM内存
ReservedOsMemory:保留的操作系统内存
ThreadStackSize:线程栈的大小
从公式中可以得出结论,系统可创建线程数量与分配给JVM内存大小成反比。
总结:本人故障定位中查到的N多OOM问题,原因不外乎以下3类
1、线程池不管理式滥用
2、本地缓存滥用(如只需要使用Node的id,但将整个Node所有信息都缓存)
3、特殊场景考虑不足(如采用单线程处理复杂业务,环境震荡+多设备下积压任务暴增)
===利用gc.log进行OOM监控===
针对JVM的监听,JDK默认提供了如jconsole、jvisualVM工具都非常好用,本节介绍利用打开gc的日志功能,进行OOM的监控。
首先需要对JAVA程序添加执行参数:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
示例参数配置:
-xmx100M -XX:+PrintGCDetails -Xloggc:../logs/gc.log -XX:+PrintGCDetails -Xmx设置堆内存
输出日志的详细介绍:
总共分配了100M堆内存空间,老年代+年轻代=堆
就堆内存,此次GC共回收了79186-75828=3356=3.279M内存,能回收空间已经非常少了。
同时从PSYoungGen回收10612-7254=3558=3.474M内存
3558-3356=202K,说明有202K的空间在年轻代释放,却传入年老代继续占用
下一条日志输出:
2018-01-03T10:53:52.281+0800: 11.052: [Full GC (Allocation Failure) [PSYoungGen: 7254K->7254K(24064K)] [ParOldGen: 68574K->68486K(68608K)] 75828K->75740K(92672K), [Metaspace: 3357K->3357K(1056768K)], 0.6010057 secs] [Times: user=2.08 sys=0.00, real=0.60 secs]
68574-68486=88K
75828-75740=88K
此次FullGC 只能释放老年代的88K空间
ps.对于分析gc.log,提供一种图形化工具辅助分析
gcviewer-1.3.6
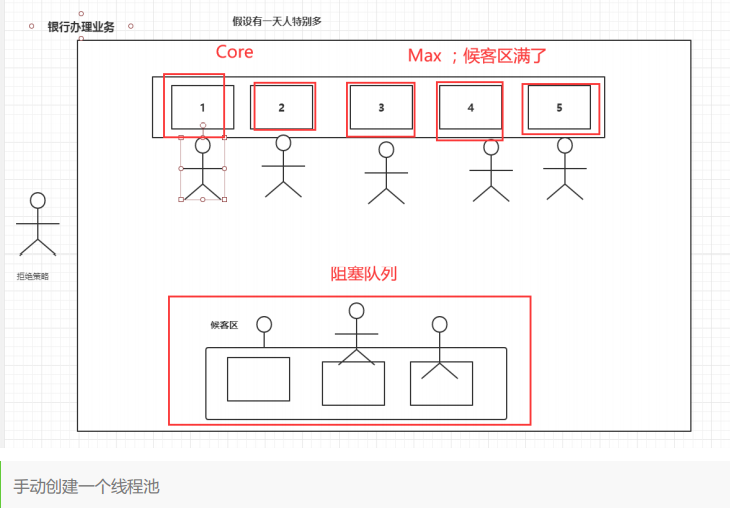
线程池:
三大方法
 [
[
](https://blog.csdn.net/sunquan291/article/details/79109197)
package cn.maidaotech.java07.syncaddlock.threadpool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.TimeUnit;// Executors 工具类、3大方法public class Demo01 {public static void main(String[] args) {ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程// ExecutorService threadPool = Executors.newFixedThreadPool(5); //创建一个固定的线程池的大小// ExecutorService threadPool = Executors.newCachedThreadPool(); // 可伸缩的,遇强则强,遇弱则弱try {for (int i = 0; i < 100; i++) {final int temp = i;// 使用了线程池之后,使用线程池创建线程threadPool.execute(()->{System.out.println(Thread.currentThread().getName()+"ok========>"+temp);});}} catch (Exception e) {e.printStackTrace();}finally{// 线程池用完,程序结束,关闭线程池threadPool.shutdown();}}}
7大参数
源码分析
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}// 本质ThreadPoolExecutor()public ThreadPoolExecutor(int corePoolSize, //核心线程池大小int maximumPoolSize, //最大核心线程池大小long keepAliveTime, //超时了没有人调用就会释放TimeUnit unit, //超时单位BlockingQueue<Runnable> workQueue, //阻塞队列ThreadFactory threadFactory,//线程工厂,创建线程的,一般不用动RejectedExecutionHandler handle // 拒绝策略)) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,threadFactory, defaultHandler);}
// 本质ThreadPoolExecutor()
public ThreadPoolExecutor(int corePoolSize, //核心线程池大小
int maximumPoolSize, //最大核心线程池大小
long keepAliveTime, //超时了没有人调用就会释放
TimeUnit unit, //超时单位
BlockingQueue
ThreadFactory threadFactory,//线程工厂,创建线程的,一般不用动
RejectedExecutionHandler handle // 拒绝策略)) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
package cn.maidaotech.java07.syncaddlock.threadpool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;// Executors 工具类、3大方法/*** new ThreadPoolExecutor.AbortPolicy() // 银行满了,还有人进来,不处理这个人的,抛出异常* new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里!* new ThreadPoolExecutor.DiscardPolicy() //队列满了,丢掉任务,不会抛出异常!* new ThreadPoolExecutor.DiscardOldestPolicy() //队列满了,尝试去和最早的竞争,也不会抛出异常!*/public class Demo2 {public static void main(String[] args) {/*** 拒绝策略* 1.new ThreadPoolExecutor.DiscardOldestPolicy() // 队列满了,尝试和最早的竞争,也不会抛出异常* 2.new ThreadPoolExecutor.AbortPlicy() // 银行满了,还有人进来,不处理这个人的,抛出异常* 会抛出异常 java.util.concurrent.RejectedExecutionException:* 3.new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里!* 4.new ThreadPoolExecutor.DiscardPolicy() //队列满了,丢掉任务,不会抛出异常!*/ExecutorService threadPool = new ThreadPoolExecutor(2,5,3,TimeUnit.SECONDS,new LinkedBlockingDeque<>(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardPolicy());try {// 最大承载:Deque + max// 超过 RejectedExecutionExceptionfor (int i = 1; i < 10; i++) {final int temp = i;// 使用了线程池之后,使用线程池来创建线程threadPool.execute(()->{System.out.println(Thread.currentThread().getName()+"ok====>"+temp);});}} catch (Exception e) {e.printStackTrace();}finally{// 线程池用完,程序结束,关闭线程池threadPool.shutdown();}}}
四种拒绝策略:
/*** new ThreadPoolExecutor.AbortPolicy() // 银行满了,还有人进来,不处理这个人的,抛出异常* new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里!* new ThreadPoolExecutor.DiscardPolicy() //队列满了,丢掉任务,不会抛出异常!* new ThreadPoolExecutor.DiscardOldestPolicy() //队列满了,尝试去和最早的竞争,也不会抛出异常!*/
池的最大的大小如何去设置!
了解:IO密集型,CPU密集型:(调优)
package cn.maidaotech.java07.syncaddlock.threadpool;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;/*** 池的最大的大小如何去设置!* 了解:IO密集型,CPU密集型:(调优)*/public class Demo3 {// 自定义线程池!工作 ThreadPoolExecutor// 最大线程到底该如何定义// 1、CPU 密集型,几核,就是几,可以保持CPu的效率最高!// 2、IO 密集型 > 判断你程序中十分耗IO的线程,// 程序 15个大型任务 io十分占用资源!// 获取CPU的核数public static void main(String[] args) {//创建线程池ExecutorService threadPool = new ThreadPoolExecutor(2,Runtime.getRuntime().availableProcessors(),3,TimeUnit.SECONDS,new LinkedBlockingDeque<>(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy());try {//用线程池创建线程for (int i = 1; i < 10; i++) {threadPool.execute(()->{System.out.println(Thread.currentThread().getName()+"ok");});}} catch (Exception e) {e.printStackTrace();}finally{// 线程池用完,程序结束,关闭线程池threadPool.shutdown();}}}
理解 HashMap 加载因子 loadFactor
一、何为加载因子?
加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
冲突的机会越大,则查找的成本越高.反之,查找的成本越小.因而,查找时间就越小.
因此,必须在 “冲突的机会”与”空间利用率”之间寻找一种平衡与折衷. 这种平衡与折衷本质上是数据结构中有名的”时-空”矛盾的平衡与折衷.
二、HashMap中的加载因子
HashMap默认的加载因子是0.75,最大容量是16,因此可以得出HashMap的默认容量是:0.75*16=12。
用户可以自定义最大容量和加载因子。
HashMap 包含如下几个构造器:
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。- HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
必须掌握的hashcode()方法
一、hashcode是什么?
想要知道这个hashcode,首先得知道hash,通过百度百科看一下:

hash是一个函数,该函数中的实现就是一种算法,就是通过一系列的算法来得到一个hash值。这个时候,我们就需要知道另一个东西,hash表,通过hash算法得到的hash值就在这张hash表中,也就是说,hash表就是所有的hash值组成的,有很多种hash函数,也就代表着有很多种算法得到hash值,如上面截图的三种,等会我们就拿第一种来说
2、hashcode
有了前面的基础,这里讲解就简单了,hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置。
每个对象都有hashcode,对象的hashcode怎么得来的呢?
首先一个对象肯定有物理地址,在别的博文中会hashcode说成是代表对象的地址,这里肯定会让读者形成误区,对象的物理地址跟这个hashcode地址不一样,hashcode代表对象的地址说的是对象在hash表中的位置,物理地址说的对象存放在内存中的地址,那么对象如何得到hashcode呢?
通过对象的内部地址(也就是物理地址)转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode。所以,hashcode是什么呢?就是在hash表中对应的位置。
这里如果还不是很清楚的话,举个例子,hash表中有 hashcode为1、hashcode为2、(…)3、4、5、6、7、8这样八个位置,有一个对象A,A的物理地址转换为一个整数17(这是假如),就通过直接取余算法,17%8=1,那么A的hashcode就为1,且A就在hash表中1的位置。
肯定会有其他疑问,接着看下面,这里只是举个例子来让你们知道什么是hashcode的意义。
二、hashcode有什么作用呢?
前面说了这么多关于hash函数,和hashcode是怎么得来的,还有hashcode对应的是hash表中的位置,可能大家就有疑问,为什么hashcode不直接写物理地址呢,还要另外用一张hash表来代表对象的地址?接下来就告诉你hashcode的作用,
1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的(后半句说的用hashcode来代表对象就是在hash表中的位置)
为什么hashcode就查找的更快,比如:我们有一个能存放1000个数这样大的内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间,用hashcode来记录对象的位置,来看一下。
hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果每一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
通过对原始方法和使用hashcode方法进行对比,我们就知道了hashcode的作用,并且为什么要使用hashcode了
三、equals方法和hashcode的关系?
通过前面这个例子,大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。
用个例子说明:上面说的hash表中的8个位置,就好比8个桶,每个桶里能装很多的对象,对象A通过hash函数算法得到将它放到1号桶中,当然肯定有别的对象也会放到1号桶中,如果对象B也通过算法分到了1号桶,那么它如何识别桶中其他对象是否和它一样呢,这时候就需要equals方法来进行筛选了。
1、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
2、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
这两条你们就能够理解了。
四、为什么equals方法重写的话,建议也一起重写hashcode方法?
如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
举个例子,其实就明白了这个道理,
比如:有个A类重写了equals方法,但是没有重写hashCode方法,看输出结果,对象a1和对象a2使用equals方法相等,按照上面的hashcode的用法,那么他们两个的hashcode肯定相等,但是这里由于没重写hashcode方法,他们两个hashcode并不一样,所以,我们在重写了equals方法后,尽量也重写了hashcode方法,通过一定的算法,使他们在equals相等时,也会有相同的hashcode值。
四大函数式接口(必需掌握)
新时代的程序员:lambda表达式、链式编程、函数式接口、Stream流式计算
函数式接口: 只有一个方法的接口
@FunctionalInterfacepublic interface Runnable {public abstract void run();}// 泛型、枚举、反射// lambda表达式、链式编程、函数式接口、Stream流式计算// 超级多FunctionalInterface// 简化编程模型,在新版本的框架底层大量应用!// foreach(消费者类的函数式接口)
Function函数式接口
package cn.maidaotech.java07.syncaddlock.forefunctioninterface;import java.util.function.Function;/*** Function 函数型接口, 有一个输入参数,有一个输出 只要是 函数型接口 可以 用 lambda表达式简化*/public class Demo01 {public static void main(String[] args) {// Function<String, String> function = new Function<String, String>() {// @Override// public String apply(String str) {// return str;// }// };//lamdar简写Function function = str->{return str;};System.out.println(function.apply("cccccc"));}}
Predicate 断定型接口:
有一个输入参数,返回值只能是 布尔值!
package cn.maidaotech.java07.syncaddlock.forefunctioninterface;import java.util.function.Predicate;/*** 断定型接口(Predicate):有一个输入参数,返回值只能是 布尔值!*/public class Demo02 {public static void main(String[] args) {//判断字符串是合法为空// Predicate<String> predicate = new Predicate<String>(){// @Override// public boolean test(String t) {// return t.isEmpty();// }// };Predicate<String> predicate = str->{return str.isEmpty();};System.out.println(predicate.test("as"));}}
Consumer 消费型接口
package cn.maidaotech.java07.syncaddlock.forefunctioninterface;import java.util.function.Consumer;/*** Consumer 消费型接口: 只有输入,没有返回值*/public class Demo03 {public static void main(String[] args) {// Consumer<String> consumer = new Consumer<String>(){// @Override// public void accept(String t) {// System.out.println(t);// }// };Consumer consumer = str->{System.out.println(str);};consumer.accept("asass");}}
Supplier 供给型接口
package cn.maidaotech.java07.syncaddlock.forefunctioninterface;import java.util.function.Supplier;/*** Supplier 供给型接口 没有参数,只有返回值*/public class Demo04 {public static void main(String[] args) {// Supplier<Integer> supplier = new Supplier<Integer>(){// @Override// public Integer get() {// System.out.println("get()");// return 1024;// }// };Supplier supplier = ()->{return 1024;};System.out.println(supplier.get());}}
springboot配置集成log4j
1.添加log4j依赖
<!-- pom.xml添加log4j依赖,最新版本可以去maven网站下载 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j</artifactId><version>1.3.8.RELEASE</version></dependency>
2. log4j配置
log4j日志的配置可以用log4j.xml,log4j.properties这2种形式配置。log4j的配置文件一般放在resources文件夹下。
//简单log4j.properties配置log4j.rootLogger=INFO,Console,Filelog4j.appender.Console=org.apache.log4j.ConsoleAppenderlog4j.appender.Console.Target=System.outlog4j.appender.Console.layout = org.apache.log4j.PatternLayoutlog4j.appender.Console.layout.ConversionPattern=[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c - %L]%m%nlog4j.appender.File = org.apache.log4j.RollingFileAppenderlog4j.appender.File.File = C:/Users/10301/Desktop/test/logs/info/info.loglog4j.appender.File.MaxFileSize = 10MBlog4j.appender.File.Threshold = ALLlog4j.appender.File.layout = org.apache.log4j.PatternLayoutlog4j.appender.File.layout.ConversionPattern =[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c - %L]%m%n
3. 配置完成,Controller中使用log4j
@RestController //声明Rest风格的控制器@RequestMapping("test")public class TestController {Logger logger=Logger.getLogger(TestController.class);@RequestMapping("logtest")@ResponseBodypublic String logtest(){logger.fatal("致命错误");logger.error("严重警告");logger.warn("警告");logger.info("普通信息");logger.debug("调试信息");return "";}}
java stream中Collectors的用法
https://www.cnblogs.com/flydean/p/java-stream-collection.html#collectorscounting
一、什么是泛型
“泛型” 意味着编写的代码可以被不同类型的对象所重用。泛型的提出是为了编写重用性更好的代码。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
https://www.cnblogs.com/whatlonelytear/p/11055126.html
可以看到,使用 Object 来实现通用、不同类型的处理,有这么两个缺点:
- 每次使用时都需要强制转换成想要的类型
- 在编译时编译器并不知道类型转换是否正常,运行时才知道,不安全
实际上引入泛型的主要目标有以下几点:
类型安全
- 泛型的主要目标是提高 Java 程序的类型安全
- 编译时期就可以检查出因 Java 类型不正确导致的 ClassCastException 异常
- 符合越早出错代价越小原则
消除强制类型转换
- 泛型的一个附带好处是,使用时直接得到目标类型,消除许多强制类型转换
- 所得即所需,这使得代码更加可读,并且减少了出错机会
潜在的性能收益
- 由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改
- 所有工作都在编译器中完成
- 编译器生成的代码跟不使用泛型(和强制类型转换)时所写的代码几乎一致,只是更能确保类型安全而已
当编译器对带有泛型的java代码进行编译时,它会去执行类型检查和类型推断,然后生成普通的不带泛型的字节码,这种普通的字节码可以被一般的 Java 虚拟机接收并执行,这在就叫做 类型擦除(type erasure)。
这证明了,static变量也不认识泛型,其实不仅仅是staic方法、static变量、static块,也不认识泛型,可以自己试一下。总结起来就是一句话:静态资源不认识泛型。

若有收获,就点个赞吧
0 人点赞
