忘记密码,修改mysql密码
https://blog.csdn.net/qq_40572277/article/details/89223005
Navicat连接mysql8.0.1版本出现1251—Client does not support authentication protocol requested by server的解决
https://blog.csdn.net/qq_42152399/article/details/80360817
ALTER 命令(掌握)
添加字段
MySQL 中使用 ADD 子句向数据表中添加列。语法结构为 :
alter table table_name add cloumn_name
例如向 student 表中增加 score 字段 :
alter table student add score int not null default 0 comment '分数'
添加字段时同时可以定义字段是否可以为空、默认值、备注等信息
删除字段
使用 ALTER 命令及 DROP 子句来删除已创建表中的某个字段。语法结构为:
alter table table_name drop column_name
例如,从 student 表中删除 score 字段 :
alter table student drop score;
修改字段
如果需要修改字段类型、名称等属性, 你可以在 ALTER 命令中使用 MODIFY 或 CHANGE 子句。其 语法结构为:
alter table table_name change column_name new_column_name date_type;//或者alter table table_name modify column_name date_type;
CHANGE 和 MODIFY 子句的却别在于,CHANGE 子句要求列出原列名和新列名,即使两者是一样的。 而 MODIFY 子句只需要指定字段名,但不能修改名称,只能修改其它属性。
例如,字段 score 修改为 math_score 只能实用 CHANGE 子句:
alter table student change score math_score int;
如果不需要修改字段名称,仅修改字段类型、是否可为空、默认值等属性建议使用 MODIFY 子句。
例如,修改字段类型
alter table student midify score varchar(10);
或者使用 CHANGE 子句 :
alter table student score score varchar(10);
若要修改其他属性,直接将新特性 MODIFY 或 CHANGE 子句中列出,注意字段数据类型不能省略,即使 与原类型相同
数据库三范式(了解)
结构化查询语言(Structured Query Language)简称 SQL,
是最重要的关系数据库操作语言,可以访问 和处理数据库
一些重要的 SQL 命令
SELECT - 从数据库中提取数据
UPDATE - 更新数据库中的数据
DELETE - 从数据库中删除数据
INSERT INTO - 向数据库中插入新数据
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库 CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
DISTINCT 关键字
在表中可能会有重复数据,或者一个字段包含多个重复值,有时希望仅仅列出不同的值。 DISTINCT 关键字用于返回唯一不同的结果。其语法 :
SELECT DISTINCT column_name,...,column_name
ORDER BY 关键字
用于对查询结果集按照一个列或者多个列进行排序。默认按照升序对记录进行 排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键
SELECT * FROM table_name ORDER BY column_name,column_name ASC|DESC;
例如:
select * from student where age>=20 order
这是按默认升序(ASC)排序的,如果想要按照降序(DESC)排序,则可以这样查询:
select * from student where age>=20 order by age desc
ORDER BY 子句支持对多个字段排序,先按照第一个排序字段进行排序,第一个排序字段值相同的 记录再按照第二个排序字段进行排序。同样的 ORDER BY 子句也支持三个及以上字段排序。例如:
select * from student order by sex asc,age desc
分页查询
如果一次 SELECT 查询语句返回结果比较多,可能会只返回符合要求的部分数据,实现分页查询。 不同数据库的实现方式各不相同,比如 MySQL、SQL Server 和 Oracle 的实现方式都不一样。 这里我们仅介绍 MySQL 的查询方式。其语法为 :
SELECT * FROM table_name LIMIT index,number;
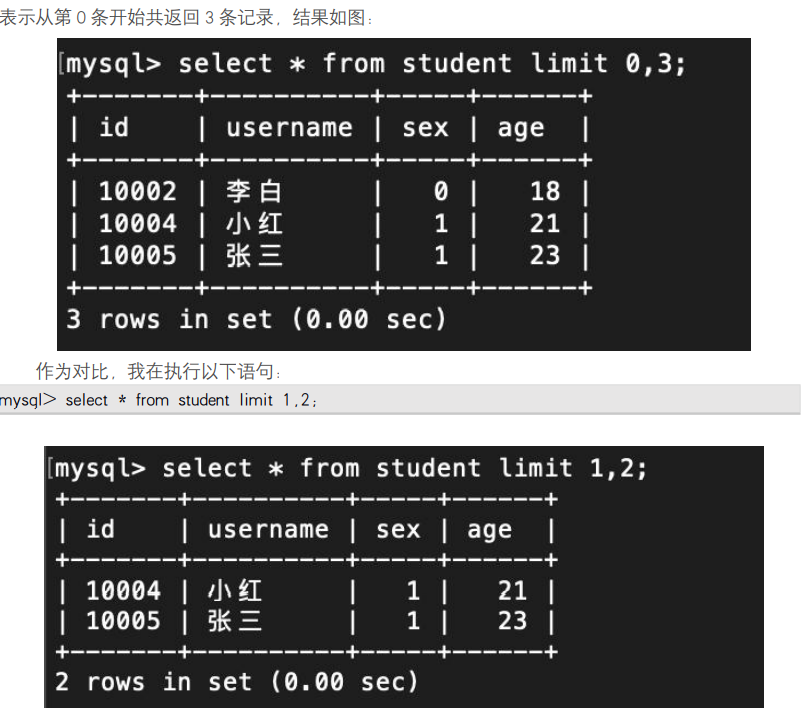
其中 index 为返回结果在符合查询条件的结果集中的序号(从 0 开始),number 是返回的记录数量。例 如 :
select * from student limit 0,3;
聚合函数
查询统计是指对符合条件的结果进行分析返回我们想要的结果。常用的统计查询有 :
COUNT()函数:统计符合条件的记录数
SELECT COUNT(column_name) FROM table_name//或者SELECT COUNT(*) FROM table_name//表明之后可以增加 WHERE 子句过滤数据,返回符合条件的记录数。
AVG()函数:返回数值列的平均值
SELECT AVG(column_name) FROM table_nam
SUM()函数:返回数值列的总数
SELECT SUM(column_name) FROM table_name//例如select sum(age) from student
MIN()函数:返回指定列的最小值
MAX()函数:返回指定列的最大值
SELECT MIN(column_name) FROM table_name;SELECT MAX(column_name) FROM table_name;//例如select min(age) from student;
GROUP BY
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。语法结构:
SELECT column_name1, function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_name1;
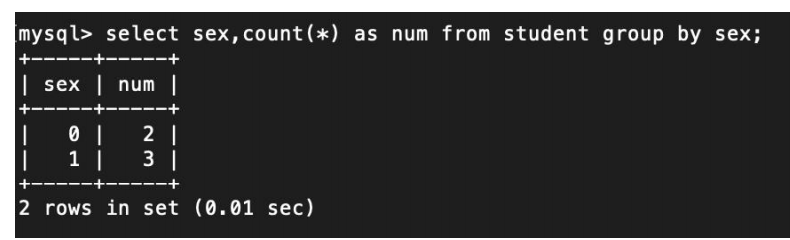
需要注意的是除了用于分组的字段可以直接返回,其他非分组字段需要结合统计函数来返回结果。 例如,分别统计不同性别的学生数量:
select sex,count(*) as num from student group by sex
HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。 HAVING 子句可以让我们筛选分组后的各组数据。语法结构:
SELECT column_name, aggregate_function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_nameHAVING aggregate_function(column_name) operator value;
例如,查询平均成绩大于 80 分的学生
select s.student_id,avg(s.score) avg_scorefrom score sgroup by s.student_idhaving avg(s.score)>80;
创建外键
//SQL语句创建数据表并设置外键关系-- 方式一:不指定外键名称,数据库自动生成foreign key (CharID) references ChineseCharInfo(ID)on delete cascade on update cascade-- 方式二:指定外键名称为(FK_Name)constraint FK_Name foreign key (CharID) references ChineseCharInfo(ID)on delete cascade on update cascade//当数据表已经存在时,就要使用下面的方法建立主外键关系-- 为表(demo.ChinesePinyinInfo)中字段(CharID)添加外键,并指定外键名为(FK_Name)alter table demo.ChinesePinyinInfo add constraint FK_Nameforeign key (CharID) references ChineseCharInfo(ID);-- 为表(demo.ChinesePinyinInfo)中字段(CharID)添加外键,不指定外键名,由数据库自动生成外键名alter table demo.ChinesePinyinInfo add foreign key (CharID)references ChineseCharInfo(ID);//删除主外键约束-- 通过修改列的属性来删除自增长,第一个(ID)为原列名,第二个(ID)为新列名alter table demo.ChinesePinyinInfo change ID ID int not null;-- 删除表(demo.ChinesePinyinInfo)中的主键约束,如果主键列为自增列,则需要先删除该列的自增长alter table demo.ChinesePinyinInfo drop primary key;-- 删除表(demo.ChinesePinyinInfo)中的名称为(FK_Name)的外键alter table demo.ChinesePinyinInfo drop foreign key FK_Name;
主外键关系的约束
如果子表试图创建一个在主表中不存在的外键值,数据库会拒绝任何insert或update操作。
如果主表试图update或者delete任何子表中存在或匹配的外键值,最终动作取决于外键约束定义中的on delete和on update选项。
on delete和on update都有下面四种动作。
cascade:主表删除或更新相应的数据行,则子表同时删除或更新与主表相匹配的行,即级联删除、更新。set null:主表删除或更新相应的数据和,则子表同时将与主表相匹配的行的外键列置为null。当外键列被设置为not null时无效。no action:数据库拒绝删除或更新主表。restrict:数据库拒绝删除或更新主表。如果未指定on delete或on update的动作,则on delete或on update的默认动作就为restrict。
唯一索引
UNIQUE KEY `uk_username` (`username`) ##唯一索引//如果是已经存在的表,设置表中某一个或几个列组合唯一,可以这样使用:ALTER TABLE student ADD UNIQUE KEY `uk_username` (`username`);

若有收获,就点个赞吧
0 人点赞
