1.SQL的分类
DDL:数据定义语言
这些语句定义了不同的数据段,数据库,表,列,索引等数据库对象。常用的语句关键字主要包括create,drop,alter等。
DML:数据操作语言
用于添加,删除,更新和查询数据库记录,并检查数据完整性。常用的语句关键字主要包括insert,delete,update,select等
DCL:数据操控语言
用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库,表,字段,用户的访问权限和安全级别。主要的语句关键字包括grant,revoke等。
2.基本的查询语句
1. SELECT
SELECT 9;SELECT 9/3; #没有任何子句
2. SELECT … FROM
SELECT * FROM `edu_subject`;
:代表查询所有
一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符‘’。使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率。通配符的优势是,当不知道所需要的列的名称时,可以通过它获取它们。
在生产环境下,不推荐你直接使用 SELECT * 进行查询。
SELECT id , title FROM `edu_subject`;
别名处理
SELECT id ,title ,parent_id AS pid FROM `edu_subject`;
紧跟列名,也可以在列名和别名之间加入关键字AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。AS可以省略
查询时的去重操作
SELECT DISTINCT parent_id FROM `edu_subject`;
在SELECT语句中使用关键字DISTINCT去除重复行,DISTINCT会对需要查询的结果整体做去重
空值参与运算
所有运算符或列值遇到null值,运算的结果都为null,可以使用 ifnull() 函数解决
显示表结构
DESCRIBE `edu_video`; #将表edu_video的表结构显示
可以简写为
DESC `edu_video`
3. SELECT … FROM …WHERE
使用 where 子句过滤数据
使用WHERE 子句,将不满足条件的行过滤掉
WHERE子句紧随 FROM子句
SELECT id ,title , parent_id AS pid FROM `edu_subject` WHERE parent_id = 0;
4. 运算符的使用
算术运算符
比较运算符

注:无论是判断还是运算,只要有null参与结果就为null;
安全等于可以将null进行判断,两边都是null返回1,一边是null返回0

is null 相当于是有null情况下的<=>
Like模糊查询
LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回0。如果给定的值或者匹配条件为NULL,则返回结果为NULL。
“%”:匹配0个或多个字符。
“_”:只能匹配一个字符。
SELECT name FROM `table` WHERE name Like "e%"
查询 name 以 e 开头的人
SELECT name FROM `table` WHERE name Like "%e%"
查询 name 中包含 e 的人
SELECT name FROM `table` WHERE name Like "_e%"
查询 name 中第二个字符是 e 的人
SELECT name FROM `table` WHERE name Like "__e%"
查询 name 中第三个字符是 e 的人
注:一个 匹配一个字符
如果先要查询 __ % 表示本身的含义 需要使用转移字符 \ _ \%
逻辑运算符
5. 排序与分页
使用 ORDER BY 子句排序
ASC(ascend): 升序
DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾。
SELECT * FROM `acl_permission` ORDER BY id DESC;
将查询出的数据使用 id 降序排序
SELECT * FROM `acl_permission` ORDER BY id ASC;
SELECT * FROM `acl_permission` WHERE `type` = 1 ORDER BY id ASC;
将查询出的数据使用 id 升序排序
OREDRV BY 默认使用升序排列
列的别名可以在ORDER BY子句中使用,不可以在WHERE子句中使用,因为SELECT 先执行然后是FROM子句和WHERE子句,后面是SELECT子句这时才有列的别名,最后才是ORDER BY子句
使用多个字段排序
SELECT * FROM `edu_subject` ORDER BY parent_id ASC,id DESC;
先根据 parent_id 升序,再根据 id 降序
分页查询
使用 LIMIT 实现分页
LIMIT [位置偏移量,] 行数
SELECT * FROM `edu_chapter` ORDER BY id ASC LIMIT 5,5
根据 id 升序排列,从第5个开始,向后查询5个
LIMIT (pageNo - 1)* pageSize , pageSize
3.多表查询
要查询某个人的工作部门和所在城市,需要涉及到三张表 employees,departments,locations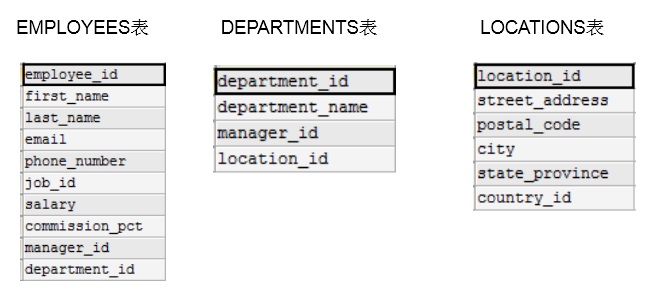
SELECT * FROM `employees` WHERE `first_name`='Diana' AND `last_name`='lorentz';
SELECT * FROM `departments` WHERE `department_id` = 80;
SELECT * FROM `locations` WHERE `location_id` =2500;
可以将三张表何在一起进行查询
SELECT
e.employee_id AS id,
e.first_name AS firstName ,
e.last_name AS lastName,
d.department_name AS department ,
l.city AS city
FROM
`employees` AS e,
`departments` AS d,
`locations` AS l
WHERE
e.first_name='Diana' AND e.last_name='lorentz' AND
e.department_id=d.department_id AND d.location_id=l.location_id;

自连接
SELECT e1.employee_id AS "manager",e1.last_name,e2.employee_id AS "employee",e2.last_name
FROM `employees` AS e1,`employees` AS e2
WHERE e1.employee_id = e2.manager_id AND e2.employee_id=108
查询员工id为108的员工,和他的上级,上级也是员工,所以要对同一张表使用自连接
不等值连接
SELECT e.salary,e.last_name,j.grade_level FROM `employees` AS e , `job_grades` AS j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal ORDER BY e.salary DESC;
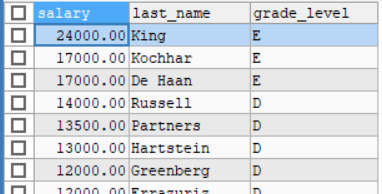
内连接和外连接

内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。如果是左外连接,则连接条件中左边的表也称为主表 ,右边的表称为从表 。如果是右外连接,则连接条件中右边的表也称为主表 ,左边的表称为 从表
左外连接
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e LEFT JOIN `departments` AS d
ON e.department_id=d.department_id
使用 A LEFT JOIN B ON 条件,会将A表的所有数据都显示出来
右外连接
使用 A RIGHT JOIN B ON 条件,会将B表的所有数据都显示出来
全连接(满外连接)
在sql的语法规则中满外连接是 FULL JOIN … ON 但是 MySQL不支持这种写法
使用 union 关键字(合并查询结果)实现满外连接
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e LEFT JOIN `departments` AS d
ON e.department_id=d.department_id
UNION
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e RIGHT JOIN `departments` AS d
ON d.department_id=d.department_id
左外连接 UNION 右外连接 将连个连接的结果何在一起并去重
左外连接(去中间)
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e LEFT JOIN `departments` AS d ON e.department_id=d.department_id
WHERE e.department_id IS NULL
右外连接(去中间)
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e RIGHT JOIN `departments` AS d ON e.department_id=d.department_id
WHERE e.department_id IS NULL
满外连接(去中间)
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e LEFT JOIN `departments` AS d ON e.department_id=d.department_id
WHERE d.department_id IS NULL
UNION
SELECT e.employee_id,e.last_name,d.department_id ,d.department_name
FROM `employees` AS e RIGHT JOIN `departments` AS d ON e.department_id=d.department_id
WHERE e.department_id IS NULL
4. 函数
函数在计算机语言的使用中贯穿始终,函数的作用是什么呢?它可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既 提高了代码效率 ,又 提高了可维护性 。在 SQL 中我们也可以使用函数对检索出来的数据进行函数操作。使用这些函数,可以极大地 提高用户对数据库的管理效率。
从函数定义的角度出发,我们可以将函数分成 内置函数 和 自定义函数 。在 SQL 语言中,同样也包括了内置函数和自定义函数。内置函数是系统内置的通用函数,而自定义函数是我们根据自己的需要编写的。
1. 单行函数
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以嵌套
- 参数可以是一列或一个值
数值函数
三角函数

指数和对数
进制间的转换
- 字符串函数


3.日期时间函数
获取日期时间
日期和时间戳的转换
日期和时间的格式化

4.数据加密
2. 流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数。
if
SELECT last_name , salary ,IF(salary>4000,'高薪','普通') FROM `employees`
case when … then … when … then … else … end
SELECT last_name , salary ,
CASE
WHEN salary>15000 THEN '高薪'
WHEN salary BETWEEN 7000 AND 15000 THEN '中薪'
ELSE '底薪' END AS 'details'
FROM `employees`
3. 聚合函数
常用的聚合函数
AVG():平均值
SUM():总和
MAX():最大值
MIN():最小值
COUNT():条数
SELECT
MAX(salary) 最大值 ,MIN(salary) 最小值, SUM(salary) 总和 ,COUNT(*) 总人数,AVG(salary) 平均工资
FROM `employees`
count():count(),count(1),count(具体字段)都能将所有的数据统计出来
在MYISAM中三种方式效率是相同的
在INNODB中count()=count(1)>count(具体字段)
GROUP BY
可以使用GROUP BY子句将表中的数据分成若干组
SELECT department_id, AVG(salary)
FROM employees WHERE department_id IS NOT NULL
GROUP BY department_id

注:SELECT中出现的非组函数的字段必须声明在GROUP BY子句当中
HAVING
HAVING一般用于分组后的条件过滤,可以解决where后面不能加聚合函数的问题
一般以GROUP BY … HAVING… 出现
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
HAVING 与 WHERE
SELECT *
FROM employees
GROUP BY department_id
HAVING MAX(salary)>5000 AND department_id IN (10,20,30)
SELECT *
FROM employees WHERE department_id IN (10,20,30)
GROUP BY department_id
HAVING MAX(salary)>5000
这两个SQL语句在查询的结果上是相同的,WHERE 和 HAVING都是起到过滤的作用,但是前一条的执行效率高于第二条,因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
SELECT 语句的执行顺序
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
5. 子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从 MySQL 4.1 开始引入,在 SELECT 子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。
单行子查询
查询工资大于149号员工工资的员工的信息
WHERE job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 141)
AND salary >
(SELECT salary
FROM employees
WHERE employee_id = 143);
在CASE表达式中使用单列子查询:
SELECT employee_id, last_name,
(CASE department_id
WHEN
(SELECT department_id FROM departments
WHERE location_id = 1800)
THEN 'Canada' ELSE 'USA' END) location
FROM employees;
多行子查询
查询每个部门薪资最低的人
SELECT employee_id,last_name
FROM employees
WHERE salary IN(
SELECT MIN(salary) FROM employees
GROUP BY department_id)
返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
SELECT employee_id,last_name ,salary
FROM employees
WHERE salary < ANY(
SELECT salary FROM employees
WHERE job_id='IT_PROG'
) AND job_id<>'IT_PROG'
返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、姓名、job_id 以及salary
SELECT employee_id,last_name ,salary
FROM employees
WHERE salary < ALL(
SELECT salary FROM employees
WHERE job_id='IT_PROG'
) AND job_id<>'IT_PROG'
相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
SELECT employee_id,salary ,department_id
FROM employees AS e1 WHERE salary >(
SELECT AVG(salary)
FROM employees WHERE department_id = e1.department_id
GROUP BY department_id
)
EXISTS 关键字
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
查询公司管理者的employee_id,last_name,job_id,department_id信息
SELECT employee_id,last_name,job_id,department_id
FROM employees AS e1
WHERE EXISTS (
SELECT * FROM employees AS e2
WHERE e1.employee_id = e2.manager_id
)

若有收获,就点个赞吧
0 人点赞
