简介
- 深度学习的步骤与前面的模型实际相同,分为以下三步
- 预设定相应的函数模型-Model
- 设定损失函数 -Loss function
- 求解最优的函数模型 -Find the best function
一、函数模型及误差函数的定义
1. 为什么可以使用神经网络作为函数模型
数学原理:任何连续多元函数都能被一组一元函数的有限次叠加(注意这里的叠加可以是非线性的)而成,其中每一个一元函数的自变量都是一组连续单变量函数的有限次加权叠加。而这内层的每一个单变量函数的自变量都是一个(即一维)变量。
例:
%2Blog(y%2B1)%7D-(x%2B0.5)-(y%2B0.5)#card=math&code=xy%20%3D%20e%5E%7Blog%28x%2B1%29%2Blog%28y%2B1%29%7D-%28x%2B0.5%29-%28y%2B0.5%29)
具体参考:https://en.wikipedia.org/wiki/Kolmogorov–Arnold_representation_theorem
- 一开始叠加定理只说明了存在性,但是并未告诉人们怎么构造
- 原理在神经网络上体现则为:固定一种统一的有限层计算网络结构,调整每个节点的参数和每层节点之间叠加计算的权重,来一致逼近任意一个多元函数。当然最好每个节点的一元函数都具有统一的形式
- 后来George Cybenko在Approximation by Superpositions of a Sigmoidal Function 证明(存在性)只要一个隐藏层并使用sigmoidal-type函数就能一致逼近任意一个多元连续函数(引出问题 why deep? )
- 之后Kurt Hornik在Approximation Capabilities of Multilayer Feedforward Networks 中指出,如果仅考虑一致逼近,关键不在于sigmoidal-type的激活函数函数,而是多层网络的前馈结构。除了sigmoidal-type,也可以选择其他激活函数,只要他们在连续函数空间上稠密//TODO(稠密性概念)
摘自知乎https://www.zhihu.com/question/24259872/answer/127219970(有所删改)
- 全连接网络图
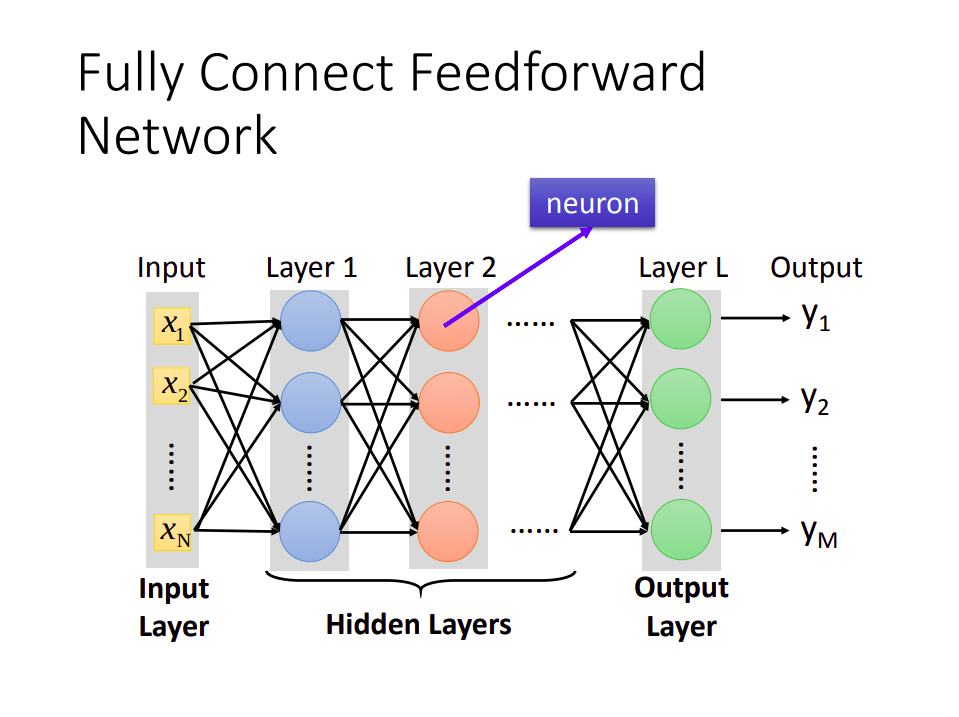
总: 上述材料说明了通过神经网络来设定函数模型的可行性,并且解释了激活函数的相关问题
2. 误差函数的定义
实际上根据不同的问题误差函数的定义也是不同的,但是其本质都时output层的输出与训练标签之间差异的衡量
- 以分类问题为例,误差函数为交叉熵

二、求解函数参数
通过前向传播和反向传播的叠加进行求导来进梯度下降
1. 前向传播
- 使用梯度下降法的关键就是求解误差函数的导数,即:
%7D%7D%7B%5Cpartial%7B%5Comega%7D%7D%3D%5Csum%7Bn%3D1%7D%5EN%7B%5Cfrac%7B%5Cpartial%7BC%5En(%5Ctheta)%7D%7D%7B%5Cpartial%7B%5Comega%7D%7D%7D%0A#card=math&code=%5Cfrac%7B%5Cpartial%7BL%28%5Ctheta%29%7D%7D%7B%5Cpartial%7B%5Comega%7D%7D%3D%5Csum%7Bn%3D1%7D%5EN%7B%5Cfrac%7B%5Cpartial%7BC%5En%28%5Ctheta%29%7D%7D%7B%5Cpartial%7B%5Comega%7D%7D%7D%0A)

- 截取上图中网络的一部分,通过链式法则将
拆成了如图所示的两项

- 其中
的结果可根据网络权重直接得出,而求解每个节点的
2. 反向传播
- 如通过前向传播求得
,再次拆分可得:
- 如下图,其中
为激活函数的导数,通过前向传播中求出的
值直接求得

- 剩余的
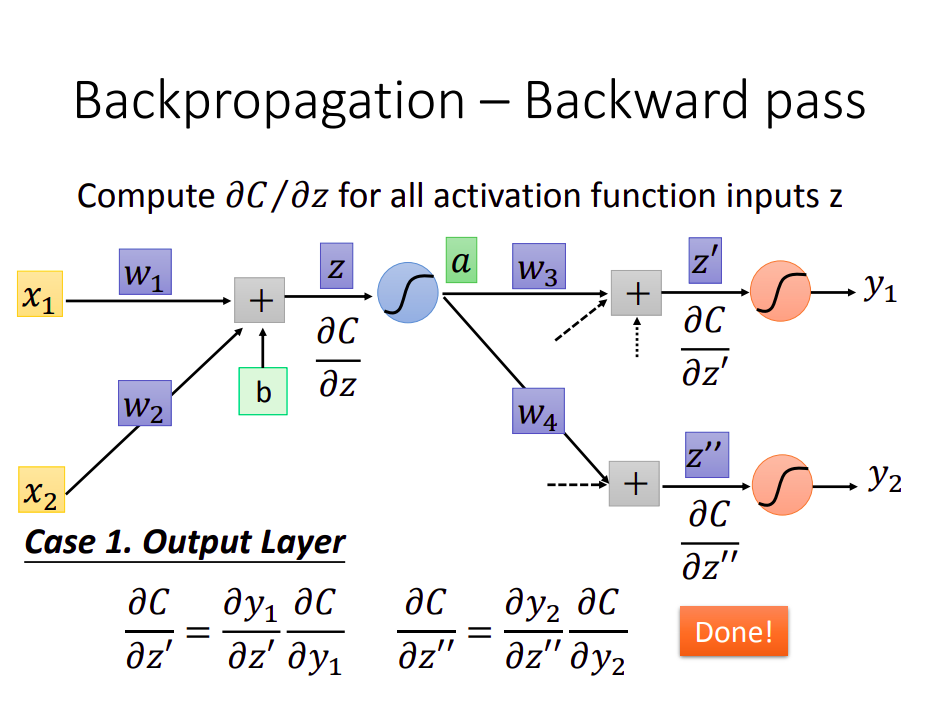

- 如图,要求当前结点的导数就是需要当前结点的前向传播结果和下级结点的反向传播结果,反向计算即可得到答案
总:通过前向传播和反向传播得到导数之后,正常按照梯度下降法求解即可
三、Tips
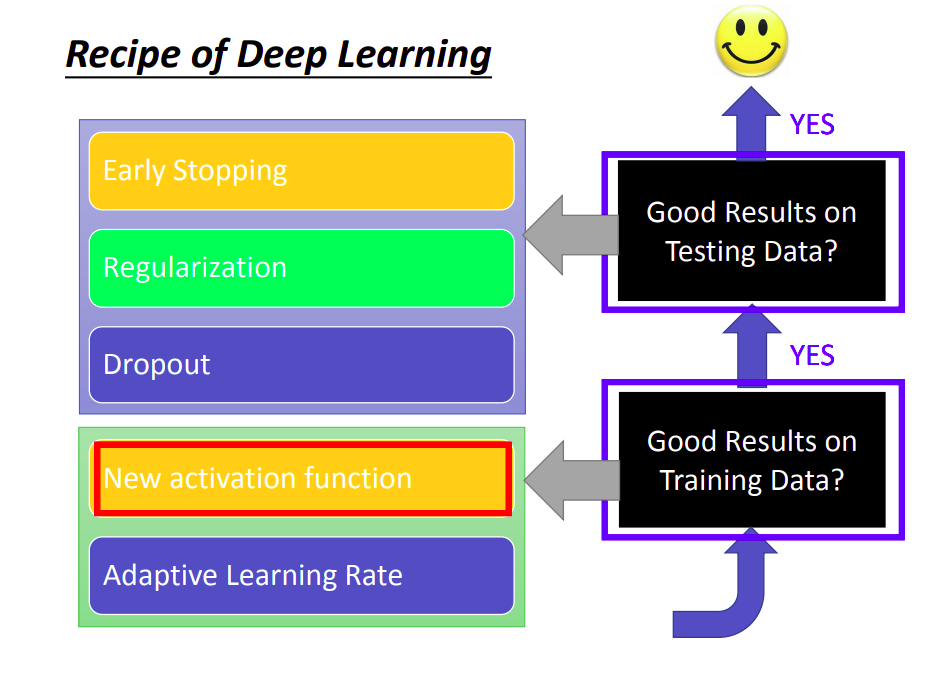
宏观上看看训练这件事
- 几种调节模型的方法,如下图
1. 新的激活函数(举例)
- 原因:因为一部分数据对于变化更加敏感,而另一部分权重对变化不敏感导致的梯度消失问题


- 解决方法:替换ReLU激活函数,来改变sigmoid函数性质上的缺陷

1.1 ReLU是MaxOut的特例
- MaxOut的激活函数实际上就是一个选择最大值输出的开关,其特殊指出在于,激活函数也是可以通过训练得到的

- 当MaxOut函数的输入值为线性函数时,可以转化为下图所示的样子,也就是ReLU函数

1.2 训练MaxOut的一些问题
- 实际上输入不同的时候,每一个MaxOut单元做出的输出也不同,也就是说随着训练的进行,连接MaxOut节点的每一条网络都可以被训练到,所以不会存在漏训练的问题

2. 通过对学习率的优化改善梯度下降法
2.1 Adagrad
原因:不同方向上的下降速度不同,需要不同的学习率
- 由于一般来说
会随着像最优点的靠近越来越小所以:
- 用对一次微分的二范数来代替难以计算的二次微分
%5E2%7D%7D%5Cnabla%7BL%7D%5Et%0A#card=math&code=%5Comega%5E%7Bt%2B1%7D%3D%5Comega%5Et-%5Cfrac%7B%5Ceta%7D%7B%5Csqrt%7B%5Csum_%7Bi%3D0%7D%5Et%28%5Cnabla%7BL%7D%5Ei%29%5E2%7D%7D%5Cnabla%7BL%7D%5Et%0A)
2.2 RMSProp
原因:同一方向上的下降速度也会不同,需要不同的学习率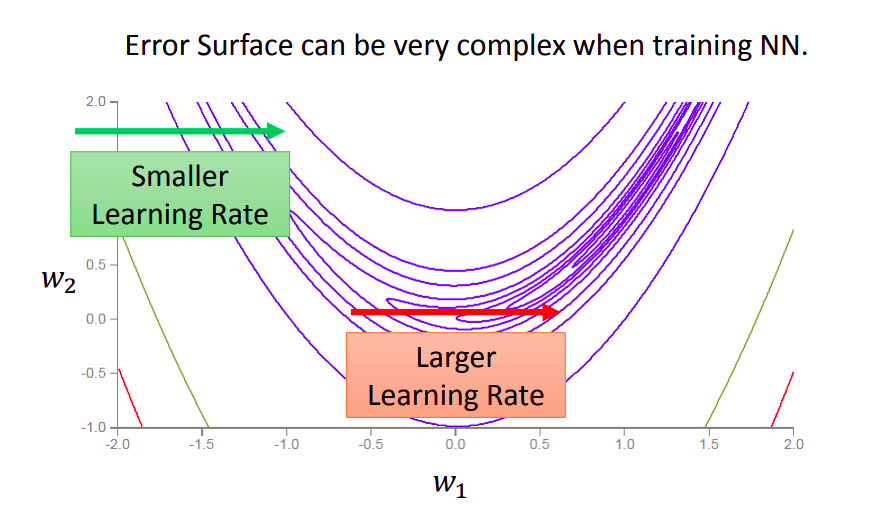

原因:一定程度上解决局部最优的问题,实际上可以看做引入了惯性的概念

2.4 Adam
原因:RMSProp与Momentum相结合
3. 训练到适当的时候停止
原因:抑制overfitting
通过有有标签的测试集实验选择更好的样本数
4. 正则化
原因:泛化特征,平滑曲线
- 趋近于0的是


5. Dropout
- 什么是Dropout
- 实际上就是每次训练时删除p%的单元,用minibatch进行训练,最后再将训练的模型的参数叠加
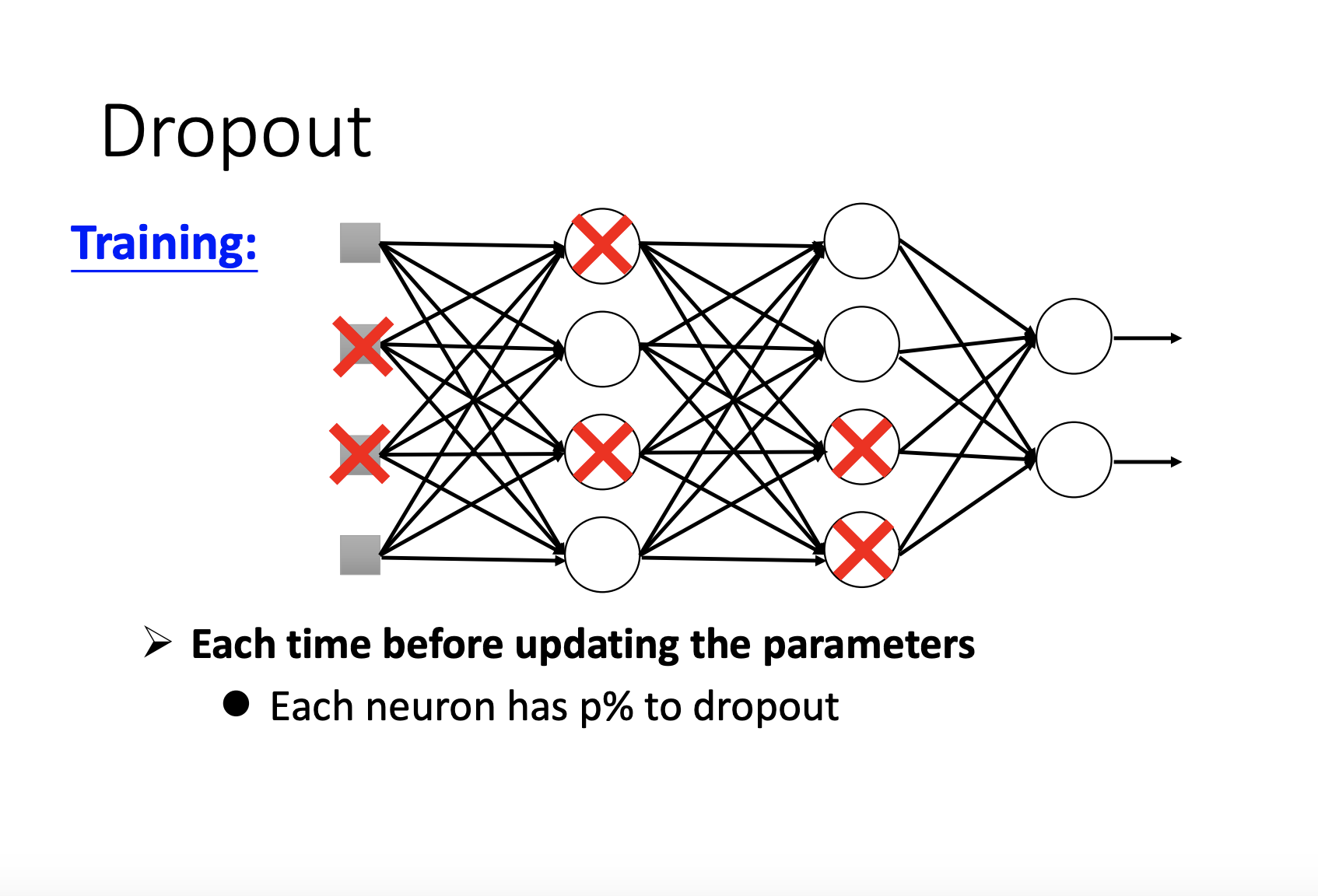


- 原理:实际通过一种全局的思想,每一个Dropout后的模型的variance小而Bias大,叠加之后就能获得variance和bias都较小的模型
- 由于激活函数为线性时可以严格证明Dropout的正确性,所以当激活函数越接近线性模型时,Dropout的效果最好;所以当激活函数为ReLU时,Dropout比较合适
四、Why deep
深度的实质可以看作在每个隐藏层作了模块化,对不同模块进行分类后,再将分类结果组合起来;所以深度学习可以用较少的数据达到更好的效果
一些思考:之前提到过神经网络的每一层可以看作对特征做了一些Transform来方便分类,实际上这些Transform的过程是不是可以看作将相同的模块进行了某种程度上的聚类,再多层分类后,对空间进行划分,分类

若有收获,就点个赞吧
0 人点赞
