第一章 Java基础
一、数据类型(8种)
1.基本数据类型
- byte/8
- short/16
- char/16
- int/32
- float/32
- long/64
- double/64
- boolean/~
boolean 只有两个值:true、false,理论上可以使用 1 bit 来存储,但是JAVA规范中没有定义boolean类型的大小。JVM 会在编译时期将boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。 boolean 数组是通过byte数组来实现的。
2.包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
//1.自动拆箱与自动装箱Integer x = 2; // 装箱int y = x; // 拆箱//2.两种创建包装类对象方式的不同Integer x = new Integer(123);Integer y = new Integer(123);System.out.println(x == y); // false 每次都会新建一个对象;Integer z = Integer.valueOf(123);Integer k = Integer.valueOf(123); //valueOf的实现方式是先在缓存池里面找有则返回缓存对象,没有则new一个System.out.println(z == k); // true 会使用缓存池中的对象,多次调用会取得同一个对象的引用//3.编译器在自动装箱的过程中会调用valueOf方法来创建对象Integer a = 123;Integer b = 123;System.out.println(a == b);//true,调用的是缓存池里面的对象所以相同
缓存池的大小
long //long类型大小范围 -128~127byte //byte类型所有数据,即-128~127short //short类型大小范围-128~127int //int类型大小范围 -128~127char //char类型所有数据,即所有字符//float double 和 boolean 类型的包装类没有缓冲池
- Integer 的缓冲池 上界是可调的,在启动 jvm 的时候,通过
-XX:AutoBoxCacheMax=<size>来指定这个缓冲池的大小. - 日常开发中,如果要比较包装类值的大小,必须使用equals方法,禁止使用==。
二 、String
(1)String
String对象是不可变的:不可变是指对象的内容不可变,而不是String的引用不可变。
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {/** The value is used for character storage. */private final char value[];}
在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用coder 来标识使用了哪种编码。
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {/** The value is used for character storage. */private final byte[] value;/** The identifier of the encoding used to encode the bytes in {@code value}. */private final byte coder;}
1.为什么String被设计为不可变?
- 高效:传参时不需要考虑谁会修改它,如果是可变类的话可能还需要进行深拷贝,有性能损失。
- 安全:String的不可变性保证了它作为参数传递时不会发生变化,不会因为参数发生变化而引起系统问题。
- 可以缓存hash 值:因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
- String Pool 的需要:如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用String Pool。
2.string如何实现不可变?
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value数组内容的方法,因此可以保证 String 不可变。
(2)字符串常量池
字符串常量池中存储的是所有字符串的字面量,这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串字面量添加到 String Pool 中。字符串常量池实现了字符串值的共享,避免了字符串字面量的重复,减少了内存不必要的占用。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
String str1 = "abc"; //str1存储的是常量池中的地址值String str2 = new String("abc"); //str2存储的是在堆中的对象的地址值,对象的value值地址与str1相同new String("abc")//使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
(3)StringBuffffer 和 StringBuilder
两者都是可变的字符串,继承自父类AbstractStringBuilder,父类中定义了value,和一些修改值的方法。默认情况下初始化一个大小为16的char[]存储值。
- StringBuffer 对⽅法加了同步锁或者对调⽤的⽅法加了同步锁,所以是线程安全的。
- StringBuilder 并没有对⽅法进⾏加同步锁,所以是⾮线程安全的。
三、Java的面向对象
-1. 封装
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
优点:
- 减少耦合:可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担:可以更容易被程序员理解,并且在调试的时候可以不影响其他模块
- 有效地调节性能:可以通过剖析来确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
权限修饰符
- public : 对所有类可见。 使用对象:类、成员。
- protected : 对同一包内的类和所有子类可见。 使用对象:成员。
- default: 在同一包内可见,不使用任何修饰符。 使用对象:类、成员。
- private : 在同一类内可见。 使用对象:成员。
2.继承
继承实现了 IS-A 关系,从而获得父类 非private 的属性和方法实现代码的复用,子类也可以对父类的方法进行重写。
3.多态
多态分为编译时多态和运行时多态:
- 编译时多态主要指方法的重载,具体使用哪个方法在编译时才确定
- 运行时多态指程序中定义的对象引用所指向的具体类型在运行期间才确定
重写与重载
重写的规则
- 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类。
- 访问权限不能比父类中被重写的方法的访问权限更低。
- 声明为 final 、 static 的方法,构造方法不能被重写。
- 只能抛出父类方法的字异常。
重载的规则
- 要求方法名相同,参数不完全相同;其他无要求
四、抽象类和接口
接口的设计目的,是对类的行为进行约束(更准确的说是一种“有”约束,因为接口不能规定类不可以有什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无,但不对如何实现行为进行限制。
而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己实现。 正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执行)。
总结:
抽象类是一个 “是不是”的关系,而接口实现则是 “有没有”的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如狗是否能钻火圈,能则可以实现这个接口,不能就不实现这个接口。
四、Object 类里面的方法
概览
public native int hashCode();public boolean equals(Object obj);protected native Object clone() throws CloneNotSupportedException;public String toString();public final native Class<?> getClass();protected void finalize() throws Throwable {};public final native void notify();public final native void notifyAll();public final native void wait(long timeout) throws InterruptedException;public final void wait(long timeout, int nanos) throws InterruptedException;public final void wait() throws InterruptedException
1.equals()
源码
public boolean equals(Object obj) {//object中的equals底层还是“==” 需要类自己重写return (this == obj);}
实现
- 检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型,如果不是,直接返回 false;
- 将 Object 对象进行转型;
- 判断每个关键域是否相等。
public class EqualExample {private int x;private int y;private int z;public EqualExample(int x, int y, int z) {this.x = x;this.y = y;this.z = z;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;EqualExample that = (EqualExample) o;if (x != that.x) return false;if (y != that.y) return false;return z == that.z;}}
2.hashCode()
源码
//默认的hashcode方法是根据对象地址生成哈希值public native int hashCode();
重写
在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。
//此例中实现了两个等价对象由于没有重写hascode方法,将他们添加到set中时会破坏set的不可重复性EqualExample e1 = new EqualExample(1, 1, 1);EqualExample e2 = new EqualExample(1, 1, 1);System.out.println(e1.equals(e2)); // trueHashSet<EqualExample> set = new HashSet<>();set.add(e1);set.add(e2);System.out.println(set.size()); // 2 正确的应该只有一个对象
理想的散列函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的散列值上。这就要求了散列函数要把所有域的值都考虑进来。可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位。**一个数与 31 相乘可以转换成移位和减法: 31x == (x<<5)-x ,编译器会自动进行这个优化。
@Overridepublic int hashCode() {int result = 17;result = 31 * result + x; //x是域的hash值result = 31 * result + y;result = 31 * result + z;return result;}
3.toString()
默认返回 ClassName@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
public String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());}
五、反射
反射就是在运行时才知道要操作的类是什么,并且可以在运行时获取类的完整构造,并调用对应的方法。
public class Apple {private int price;public int getPrice() {return price;}public void setPrice(int price) {this.price = price;}public static void main(String[] args) throws Exception{//正常的调用Apple apple = new Apple();apple.setPrice(5);System.out.println("Apple Price:" + apple.getPrice());//使用反射调用Class clz = Class.forName("com.chenshuyi.api.Apple");Method setPriceMethod = clz.getMethod("setPrice", int.class);Constructor appleConstructor = clz.getConstructor();Object appleObj = appleConstructor.newInstance();setPriceMethod.invoke(appleObj, 14);Method getPriceMethod = clz.getMethod("getPrice");System.out.println("Apple Price:" + getPriceMethod.invoke(appleObj));}}
一般情况下我们使用反射获取一个对象的步骤:
- 获取类的 Class 对象实例
Class clz = Class.forName("com.zhenai.api.Apple");
- 根据 Class 对象实例获取 Constructor 对象
Constructor appleConstructor = clz.getConstructor();
- 使用 Constructor 对象的 newInstance 方法获取反射类对象
Object appleObj = appleConstructor.newInstance();
而如果要调用某一个方法,则需要经过下面的步骤:
- 获取方法的 Method 对象
Method setPriceMethod = clz.getMethod("setPrice", int.class);
- 利用 invoke 方法调用方法
setPriceMethod.invoke(appleObj, 14);
六、异常
第二章、Java容器
一、概览
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射
表。
Collection
1.Set
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如
HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说
使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet:具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
2. List
ArrayList:基于动态数组实现,支持随机访问。
Vector:和 ArrayList 类似,但它是线程安全的。
LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此LinkedList
还可以用作栈、队列和双向队列。
3. Queue
LinkedList:可以用它来实现双向队列。
PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
MapT
- reeMap:基于红黑树实现。
- HashMap:基于哈希表实现-。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
二、容器中的设计模式
迭代器模式
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历Collection 中的元素。
适配器模式
java.util.Arrays 下的 asList() 方法可以把数组类型转换为 List 类型。
@SafeVarargs@SuppressWarnings("varargs")//asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。public static <T> List<T> asList(T... a) {return new ArrayList<>(a);}//使用方式Integer[] arr = {1, 2, 3};List list = Arrays.asList(arr);//也可以使用以下方式调用 asList()List list = Arrays.asList(1, 2, 3);
三、源码分析
如果没有特别说明,以下源码分析基于 JDK 1.8。
ArrayList
1. 概览
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;
2. 扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1) ,也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的。
4. Fail-Fast
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出
5. 序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
transient Object[] elementData; // non-private to simplify nested class access
ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
Vector
1. 同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}public synchronized E get(int index) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);return elementData(index);}
2. 与 ArrayList 的比较
Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
LinkedList
1. 概览
基于双向链表实现,使用 Node 存储链表节点信息。
private static class Node<E> {E item;Node<E> next;Node<E> prev;}
每个链表存储了 fifirst 和 last 指针:
transient Node<E> first;transient Node<E> last;
2. 与 ArrayList 的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现;
ArrayList 支持随机访问,LinkedList 不支持;
LinkedList 在任意位置添加删除元素更快。
HashMap
为了便于理解,以下源码分析以 JDK 1.7 为主。
1. 存储结构
内部包含了一个 Entry 类型的数组 table。
transient Entry[] table;
Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;}
2. 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();map.put("K1", "V1");map.put("K2", "V2");map.put("K3", "V3");
新建一个 HashMap,默认大小为 16;
插入
插入
插入
应该注意到链表的插入是以头插法方式进行的,例如上面的
部。查找需要分成两步进行:
计算键值对所在的桶;
在链表上顺序查找,时间复杂度显然和链表的长度成正比。
3. put 操作
public V put(K key, V value) {if (table == EMPTY_TABLE) {inflateTable(threshold);}// 键为 null 单独处理if (key == null)return putForNullKey(value);int hash = hash(key);// 确定桶下标int i = indexFor(hash, table.length);// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 valuefor (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;// 插入新键值对addEntry(hash, key, value, i);return null;}
第三章、Java IO
一、概览
Java 的 I/O 大概可以分成以下几类:
- 磁盘操作:File
- 字节操作:InputStream 和 OutputStream
- 字符操作:Reader 和 Writer
- 对象操作:Serializable
- 网络操作:Socket
- 新的输入/输出:NIO
二、磁盘操作
File 类可以用于表示文件和目录的信息,但是它不表示文件的内容。
递归地列出一个目录下所有文件:
public static void listAllFiles(File dir) {if (dir == null || !dir.exists()) {return;}if (dir.isFile()) {System.out.println(dir.getName());return;}for (File file : dir.listFiles()) {listAllFiles(file);}}
从 Java7 开始,可以使用 Paths 和 Files 代替 File。
三、字节操作
实现文件复制
public static void copyFile(String src, String dist) throws IOException {FileInputStream in = new FileInputStream(src);FileOutputStream out = new FileOutputStream(dist);byte[] buffer = new byte[20 * 1024];int cnt;// read() 最多读取 buffer.length 个字节// 返回的是实际读取的个数// 返回 -1 的时候表示读到 eof,即文件尾while ((cnt = in.read(buffer, 0, buffer.length)) != -1) {out.write(buffer, 0, cnt);}in.close();out.close();}
装饰者模式
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
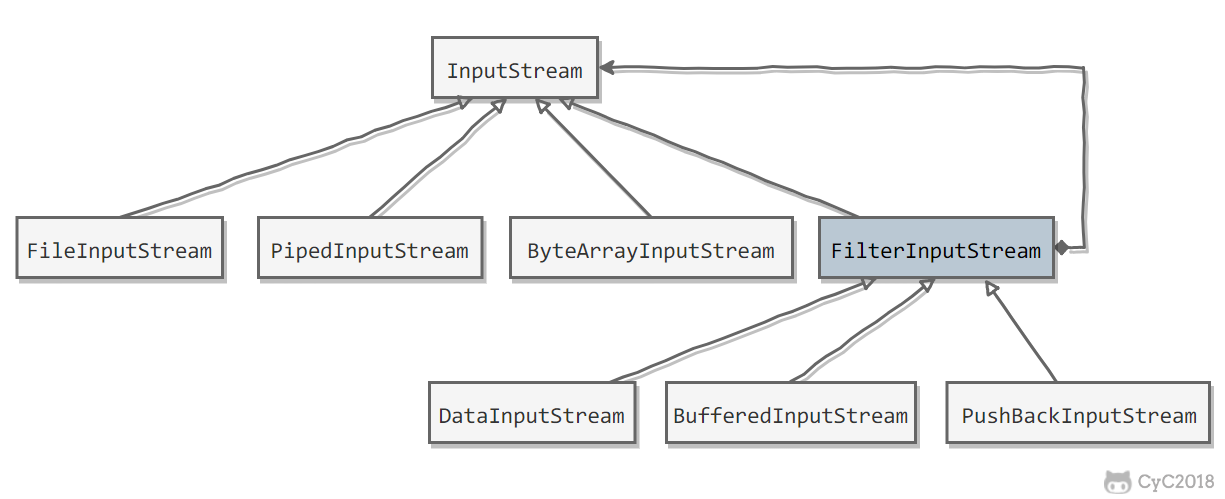
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
四、字符操作
编码与解码
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
String 的编码方式
String 可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为 String。
String str1 = "中文";byte[] bytes = str1.getBytes("UTF-8");String str2 = new String(bytes, "UTF-8");System.out.println(str2);
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
byte[] bytes = str1.getBytes();
Reader 与 Writer
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
- InputStreamReader 实现从字节流解码成字符流;
- OutputStreamWriter 实现字符流编码成为字节流。
实现逐行输出文本文件的内容
public static void readFileContent(String filePath) throws IOException {FileReader fileReader = new FileReader(filePath);BufferedReader bufferedReader = new BufferedReader(fileReader);String line;while ((line = bufferedReader.readLine()) != null) {System.out.println(line);}// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法// 因此只要一个 close() 调用即可bufferedReader.close();}
五、对象操作
序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:ObjectOutputStream.writeObject()
- 反序列化:ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {A a1 = new A(123, "abc");String objectFile = "file/a1";ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));objectOutputStream.writeObject(a1);objectOutputStream.close();ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));A a2 = (A) objectInputStream.readObject();objectInputStream.close();System.out.println(a2);}private static class A implements Serializable {private int x;private String y;A(int x, String y) {this.x = x;this.y = y;}@Overridepublic String toString() {return "x = " + x + " " + "y = " + y;}}
ransient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
六、网络操作
Java 中的网络支持:
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;
- Datagram:使用 UDP 协议实现网络通信。
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host);InetAddress.getByAddress(byte[] address);
URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {URL url = new URL("http://www.baidu.com");/* 字节流 */InputStream is = url.openStream();/* 字符流 */InputStreamReader isr = new InputStreamReader(is, "utf-8");/* 提供缓存功能 */BufferedReader br = new BufferedReader(isr);String line;while ((line = br.readLine()) != null) {System.out.println(line);}br.close();}
Sockets
- ServerSocket:服务器端类
- Socket:客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。

Datagram
- DatagramSocket:通信类
- DatagramPacket:数据包类
七、NIO
新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O。
流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io. 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io. 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
通道与缓冲区
1. 通道
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel:从文件中读写数据;
- DatagramChannel:通过 UDP 读写网络中数据;
- SocketChannel:通过 TCP 读写网络中数据;
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
2. 缓冲区
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量
- capacity:最大容量;
- position:当前已经读写的字节数;
- limit:还可以读写的字节数。
状态变量的改变过程举例:
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。

② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
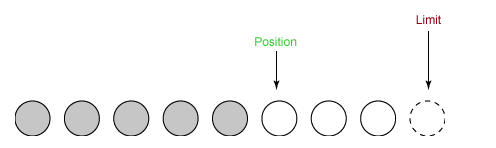
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。

④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。

⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。

文件 NIO 实例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {/* 获得源文件的输入字节流 */FileInputStream fin = new FileInputStream(src);/* 获取输入字节流的文件通道 */FileChannel fcin = fin.getChannel();/* 获取目标文件的输出字节流 */FileOutputStream fout = new FileOutputStream(dist);/* 获取输出字节流的文件通道 */FileChannel fcout = fout.getChannel();/* 为缓冲区分配 1024 个字节 */ByteBuffer buffer = ByteBuffer.allocateDirect(1024);while (true) {/* 从输入通道中读取数据到缓冲区中 */int r = fcin.read(buffer);/* read() 返回 -1 表示 EOF */if (r == -1) {break;}/* 切换读写 */buffer.flip();/* 把缓冲区的内容写入输出文件中 */fcout.write(buffer);/* 清空缓冲区 */buffer.clear();}}
选择器
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件,对于 IO 密集型的应用具有很好地性能。
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。

1. 创建选择器
Selector selector = Selector.open();
2. 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();ssChannel.configureBlocking(false);ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;public static final int OP_WRITE = 1 << 2;public static final int OP_CONNECT = 1 << 3;public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
3. 监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();Iterator<SelectionKey> keyIterator = keys.iterator();while (keyIterator.hasNext()) {SelectionKey key = keyIterator.next();if (key.isAcceptable()) {// ...} else if (key.isReadable()) {// ...}keyIterator.remove();}
5. 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}
套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
NIO 与普通 I/O 的区别主要有以下两点:
- NIO 是非阻塞的;
- NIO 面向块,I/O 面向流。
- ojava.blogspot.com/2012/12/socket-multicast.html)

若有收获,就点个赞吧
0 人点赞
