1. 锁的概述
1.1 锁的归类
自旋锁:线程反复检查锁变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显示释放自旋锁。自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的
OSSpinLock
互斥锁:是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区而达成
NSLockpthread_mutex@synchronizedos_unfair_lock
条件锁:就是条件变量,当进程的某些资源要求不满足时就进入休眠,也就是锁住了。当资源被分配到了,条件锁打开,进程继续运行
NSConditionNSConditionLock
递归锁:同一个线程可以加锁
N次而不会引发死锁NSRecursiveLockpthread_mutex(recursive)
信号量(
semaphore):一种更高级的同步机制,互斥锁可以说是semaphore在仅取值0/1时的特例。信号量可以有更多的取值空间,用来实现更加复杂的同步,而不单单是线程间互斥dispatch_semaphore
读写锁:一种特殊的自旋锁。它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作
相比自旋锁而言,能提高并发性。因为在多处理器系统中,它允许同时有多个读者来访问共享资源,最大可能的读者数为实际的逻辑
CPU数。但写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数先关),但不能同时既有读者又有写者。在读写锁保持期间也是抢占失效的如果读写锁当前没有读者,也没有写者,那么写者可以立刻获得读写锁,否则它必须自旋在那里,直到没有任何写者或读者
如果读写锁没有写者,那么读者可以立即获得该读写锁,否则读者必须自旋在那里,直到写者释放该读写锁
其实基本的锁就包括三类:⾃旋锁、互斥锁、读写锁,其他的⽐如条件锁、递归锁、信号量都是上层的封装和实现
互斥锁 = 互斥 + 同步,互斥保证线程安全,当一条线程执行时,其他线程休眠。同步保证执行顺序,多线程串行执行
NSLock、pthread_mutex、@synchronized、NSCondition、NSConditionLock、NSRecursiveLock、pthread_mutex(recursive)、os_unfair_lock
自旋锁 = 互斥 + 忙等,例如
do...while循环。它的优点在于不会引起调用者睡眠,所以不会进行线程调度,CPU时间片轮转等耗时操作。而缺点是当等待时会消耗大量CPU资源,所以自旋锁不适用较长时间的任务OSSpinLock
1.2 锁的性能
2021年iPhone 12真机测试,锁的性能对比图: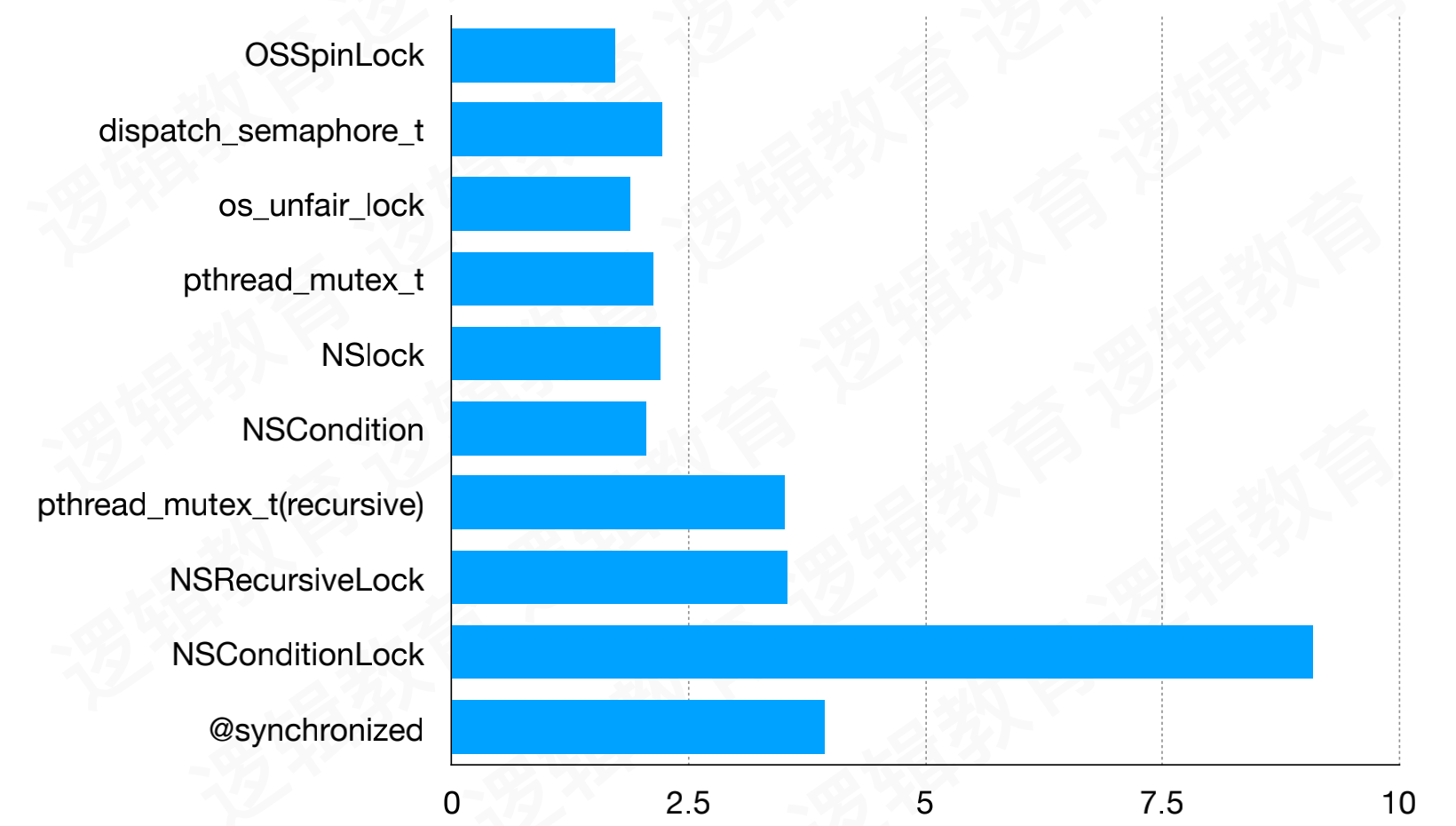
- 性能从高到低依次排列:
OSSpinLock(自旋锁)>os_unfair_lock(自旋锁)>NSCondition(条件锁)>pthread_mutex(互斥锁)>NSLock(互斥锁)>dispatch_semaphore(信号量)>pthread_mutex(recursive)(递归锁)>NSRecursiveLock(递归锁)>@synchronized(互斥锁)>NSConditionLock(条件锁)
1.3 测试方案
循环十万次,进行加锁和解锁操作。通过开始、结束时间,计算各自锁的耗时
int kc_runTimes = 100000;
OSSpinLock:
/** OSSpinLock 性能 */{OSSpinLock kc_spinlock = OS_SPINLOCK_INIT;double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {OSSpinLockLock(&kc_spinlock); //解锁OSSpinLockUnlock(&kc_spinlock);}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"OSSpinLock: %f ms",(kc_endTime - kc_beginTime)*1000);}
dispatch_semaphore_t:
/** dispatch_semaphore_t 性能 */{dispatch_semaphore_t kc_sem = dispatch_semaphore_create(1);double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {dispatch_semaphore_wait(kc_sem, DISPATCH_TIME_FOREVER);dispatch_semaphore_signal(kc_sem);}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"dispatch_semaphore_t: %f ms",(kc_endTime - kc_beginTime)*1000);}
os_unfair_lock_lock:
/** os_unfair_lock_lock 性能 */{os_unfair_lock kc_unfairlock = OS_UNFAIR_LOCK_INIT;double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {os_unfair_lock_lock(&kc_unfairlock);os_unfair_lock_unlock(&kc_unfairlock);}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"os_unfair_lock_lock: %f ms",(kc_endTime - kc_beginTime)*1000);}
pthread_mutex_t:
/** pthread_mutex_t 性能 */{pthread_mutex_t kc_metext = PTHREAD_MUTEX_INITIALIZER;double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {pthread_mutex_lock(&kc_metext);pthread_mutex_unlock(&kc_metext);}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"pthread_mutex_t: %f ms",(kc_endTime - kc_beginTime)*1000);}
NSLock:
/** NSLock 性能 */{NSLock *kc_lock = [NSLock new];double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {[kc_lock lock];[kc_lock unlock];}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"NSlock: %f ms",(kc_endTime - kc_beginTime)*1000);}
NSCondition:
/** NSCondition 性能 */{NSCondition *kc_condition = [NSCondition new];double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {[kc_condition lock];[kc_condition unlock];}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"NSCondition: %f ms",(kc_endTime - kc_beginTime)*1000);}
PTHREAD_MUTEX_RECURSIVE:
/** PTHREAD_MUTEX_RECURSIVE 性能 */{pthread_mutex_t kc_metext_recurive;pthread_mutexattr_t attr;pthread_mutexattr_init (&attr);pthread_mutexattr_settype (&attr, PTHREAD_MUTEX_RECURSIVE);pthread_mutex_init (&kc_metext_recurive, &attr);double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {pthread_mutex_lock(&kc_metext_recurive);pthread_mutex_unlock(&kc_metext_recurive);}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"PTHREAD_MUTEX_RECURSIVE: %f ms",(kc_endTime - kc_beginTime)*1000);}
NSRecursiveLock:
/** NSRecursiveLock 性能 */{NSRecursiveLock *kc_recursiveLock = [NSRecursiveLock new];double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {[kc_recursiveLock lock];[kc_recursiveLock unlock];}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"NSRecursiveLock: %f ms",(kc_endTime - kc_beginTime)*1000);}
NSConditionLock:
/** NSConditionLock 性能 */{NSConditionLock *kc_conditionLock = [NSConditionLock new];double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {[kc_conditionLock lock];[kc_conditionLock unlock];}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"NSConditionLock: %f ms",(kc_endTime - kc_beginTime)*1000);}
@synchronized:
/** @synchronized 性能 */{double_t kc_beginTime = CFAbsoluteTimeGetCurrent();for (int i=0 ; i < kc_runTimes; i++) {@synchronized(self) {}}double_t kc_endTime = CFAbsoluteTimeGetCurrent() ;KCLog(@"@synchronized: %f ms",(kc_endTime - kc_beginTime)*1000);}
其中@synchronized比之前在老版本中的测试结果快了很多,说明官方对其进行了优化
使用模拟器运行,运行结果和真机略有不同,因为系统底层在真机和模拟器上的处理有一些差异
2. @synchronized
2.1 底层实现
查看@synchronized的底层实现,可以使用clang或xcrun生成cpp文件,或者通过调试查看汇编代码
2.1.1 【方案一】查看cpp文件
在程序的main函数入口,增加@synchronized代码
int main(int argc, char * argv[]) {NSString * appDelegateClassName;@autoreleasepool {appDelegateClassName = NSStringFromClass([AppDelegate class]);@synchronized (appDelegateClassName) {}}return UIApplicationMain(argc, argv, nil, appDelegateClassName);}
使用xcrun生成cpp文件
xcrun -sdk iphoneos clang -arch arm64 -rewrite-objc main.m -o main.cpp
打开main.cpp文件,找到main函数的实现
调用
_sync_exit传入_sync_obj,相当于调用结构体的构造函数和析构函数。构造函数中没有代码,而析构函数中调用objc_sync_exit函数,传入的sync_exit等同于_sync_obj使用
objc_sync_enter(_sync_obj)函数,进行加锁使用
objc_sync_exit(_sync_obj)函数,进行解锁
使用
try...catch,说明锁的使用有可能出现异常
2.1.2 【方案二】查看汇编代码
在main函数设置断点,使用模拟器运行,查看汇编代码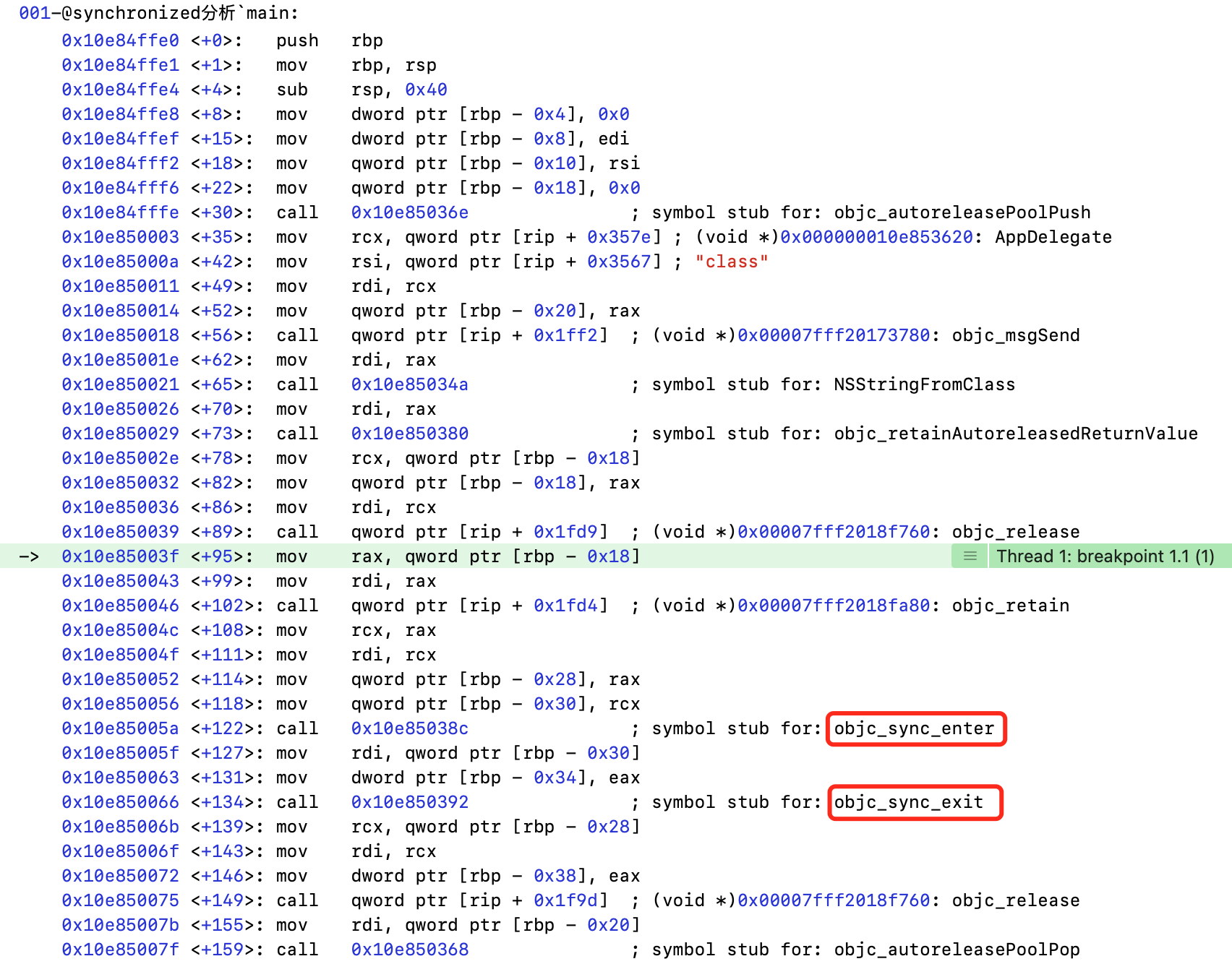
- 同样的效果,
objc_sync_enter和objc_sync_exit函数成对出现,分别进行加锁和解锁操作
对objc_sync_enter设置符号断点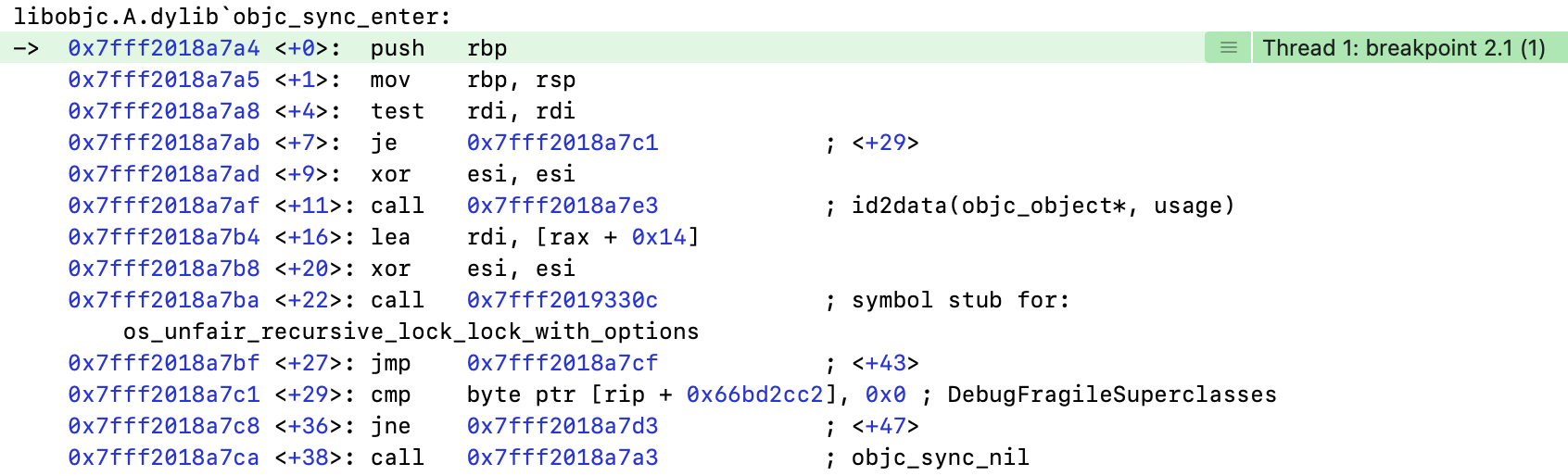
- 来自于
libobjc.A.dylib
2.2 源码分析
2.2.1 objc_sync_enter
打开objc4-818.2源码,进入objc_sync_enter函数
int objc_sync_enter(id obj){int result = OBJC_SYNC_SUCCESS;if (obj) {SyncData* data = id2data(obj, ACQUIRE);ASSERT(data);data->mutex.lock();} else {// @synchronized(nil) does nothingif (DebugNilSync) {_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");}objc_sync_nil();}return result;}
- 如果
obj存在,执行id2data函数 - 否则,执行
objc_sync_nil函数
进入objc_sync_nil函数
BREAKPOINT_FUNCTION(void objc_sync_nil(void));
找到BREAKPOINT_FUNCTION的宏定义
# define BREAKPOINT_FUNCTION(prototype) \OBJC_EXTERN __attribute__((noinline, used, visibility("hidden"))) \prototype { asm(""); }
实际上objc_sync_nil中的代码,相当于传入将void objc_sync_nil(void)传入宏,等同于以下代码:
void objc_sync_nil(void) { asm(""); }
- 相当于无效代码,不会进行加锁操作
查看objc_sync_nil的汇编代码
libobjc.A.dylib`objc_sync_nil:-> 0x7fff2018a7a3 <+0>: ret
- 什么都不处理,直接返回
所以,使用@synchronized时,传入nil,相当于无效代码,不会进行加锁操作
2.2.2 objc_sync_exit
进入objc_sync_exit函数
int objc_sync_exit(id obj){int result = OBJC_SYNC_SUCCESS;if (obj) {SyncData* data = id2data(obj, RELEASE);if (!data) {result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;} else {bool okay = data->mutex.tryUnlock();if (!okay) {result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;}}} else {// @synchronized(nil) does nothing}return result;}
- 如果
obj存在,调用id2data函数,和objc_sync_enter函数中的逻辑相似 - 否则,什么都不做
由此可见,objc_sync_enter和objc_sync_exit中的核心代码都是id2data函数,参数传入的ACQUIRE和RELEASE有所区别,但最终都获取到一个SyncData对象
在
objc_sync_enter中,对SyncData对象中的mutex,调用lock进行加锁在
objc_sync_exit中,对SyncData对象中的mutex,调用tryUnlock进行解锁
2.2.3 SyncData结构
找到SyncData的结构定义
typedef struct alignas(CacheLineSize) SyncData {struct SyncData* nextData;DisguisedPtr<objc_object> object;int32_t threadCount; // number of THREADS using this blockrecursive_mutex_t mutex;} SyncData;
SyncData结构,属于单向链表
nextData指向下一条数据DisguisedPtr<objc_object>用于封装类型threadCount记录多线程操作数recursive_mutex_t递归锁,可以递归使用,但不支持多线程递归
所以,通过SyncData的结构不难看出,@synchronized为递归互斥锁,支持多线程递归使用,比recursive_mutex_t更加强大
2.2.4 id2data
进入id2data函数
static SyncData* id2data(id object, enum usage why){//1、传入object,从哈希表中获取数据//传入object,从哈希表中获取lock,用于保证分配SyncData代码的线程安全spinlock_t *lockp = &LOCK_FOR_OBJ(object);//传入object,从哈希表中获取SyncData的地址,等同于SyncListSyncData **listp = &LIST_FOR_OBJ(object);SyncData* result = NULL;#if SUPPORT_DIRECT_THREAD_KEYSbool fastCacheOccupied = NO;//2、在当前线程的tls(线程局部存储)中寻找SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);if (data) {fastCacheOccupied = YES;//SyncData中的对象和传入的对象相同if (data->object == object) {//可以进入到这里,应该是同一线程中对同一对象,进行嵌套@synchronizeduintptr_t lockCount;result = data;lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);if (result->threadCount <= 0 || lockCount <= 0) {_objc_fatal("id2data fastcache is buggy");}switch(why) {case ACQUIRE: {//锁的次数+1lockCount++;//存储到tls中tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);break;}case RELEASE://锁的次数-1lockCount--;//存储到tls中tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);if (lockCount == 0) {// remove from fast cache//删除tls线程局部存储tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);//对SyncData对象的threadCount进行-1,因为当前线程中的对象已经解锁OSAtomicDecrement32Barrier(&result->threadCount);}break;case CHECK:// do nothingbreak;}return result;}}#endif//3、tls中未找到,在各自线程的缓存中查找SyncCache *cache = fetch_cache(NO);if (cache) {unsigned int i;//遍历缓存for (i = 0; i < cache->used; i++) {SyncCacheItem *item = &cache->list[i];//item中的对象和传入的对象不一致,跳过if (item->data->object != object) continue;result = item->data;if (result->threadCount <= 0 || item->lockCount <= 0) {_objc_fatal("id2data cache is buggy");}switch(why) {case ACQUIRE://锁的次数+1item->lockCount++;break;case RELEASE://锁的次数-1item->lockCount--;if (item->lockCount == 0) {// remove from per-thread cache//从缓存中删除cache->list[i] = cache->list[--cache->used];//对SyncData对象的threadCount进行-1,因为当前线程中的对象已经解锁OSAtomicDecrement32Barrier(&result->threadCount);}break;case CHECK:// do nothingbreak;}return result;}}//加锁,保证下面分配SyncData代码的线程安全lockp->lock();{SyncData* p;SyncData* firstUnused = NULL;//4、遍历SyncList,如果无法遍历,证明当前object第一次进入,需要分配新的SyncDatafor (p = *listp; p != NULL; p = p->nextData) {//遍历如果链表中存在SyncData的object和传入的object相等if ( p->object == object ) {//将p赋值给resultresult = p;//对threadCount进行+1OSAtomicIncrement32Barrier(&result->threadCount);//跳转至donegoto done;}//找到一个未使用的SyncDataif ( (firstUnused == NULL) && (p->threadCount == 0) )firstUnused = p;}//未找到与对象关联的SyncData,如果当前非ACQUIRE逻辑,直接进入doneif ( (why == RELEASE) || (why == CHECK) )goto done;//从SyncList中找到未使用的SyncData,进行覆盖if ( firstUnused != NULL ) {//赋值给resultresult = firstUnused;result->object = (objc_object *)object;result->threadCount = 1;//跳转至donegoto done;}}//5、分配一个新的SyncData并添加到SyncList中posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));result->object = (objc_object *)object;result->threadCount = 1;new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);//使用单链表头插法,新增节点总是插在头部result->nextData = *listp;*listp = result;done://解锁,保证上面分配SyncData代码的线程安全lockp->unlock();if (result) {//一些错误处理,应该只有ACQUIRE时,产生新SyncData时进入这里//所有的RELEASE和CHECK和递归ACQUIRE,都应该由上面的线程缓存处理if (why == RELEASE) {return nil;}if (why != ACQUIRE) _objc_fatal("id2data is buggy");if (result->object != object) _objc_fatal("id2data is buggy");//6、保存到tls线程或者缓存中#if SUPPORT_DIRECT_THREAD_KEYSif (!fastCacheOccupied) {//保存到当前线程的tls中tls_set_direct(SYNC_DATA_DIRECT_KEY, result);tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);} else#endif{//tls还在占用,保存到缓存if (!cache) cache = fetch_cache(YES);cache->list[cache->used].data = result;cache->list[cache->used].lockCount = 1;cache->used++;}}return result;}
【第一步】传入
object,从哈希表中获取数据传入
object,从哈希表中获取lock,用于保证分配SyncData代码的线程安全传入
object,从哈希表中获取SyncData的地址,等同于SyncList
【第二步】在当前线程的
tls(线程局部存储)中寻找从
tls中获取SyncData如果存在,对比
SyncData中的对象和传入的对象是否相同相同,根据传入的类型,对
lockCount进行++或--,更新tls。如果是RELEASE操作,对SyncData对象的threadCount进行-1,因为当前线程中的对象已经解锁。完成以上逻辑,直接返回result不同,进入【第三步】
不存在,进入【第三步】
【第三步】
tls中未找到,在各自线程的缓存中查找调用
fetch_cache函数,获取SyncCache如果存在,遍历缓存,对比
item中的对象和传入的对象是否相同相同,根据传入的类型,对
lockCount进行++或--,更新缓存。如果是RELEASE操作,对SyncData对象的threadCount进行-1,因为当前线程中的对象已经解锁。完成以上逻辑,直接返回result遍历结束,未找到相同对象,进入【第四步】
不存在缓存,进入【第四步】
【第四步】遍历
SyncList找到SyncData,相当于在所有线程中寻址对比
SyncData中的对象和传入的对象是否相同,同时在遍历过程中,找到未使用的SyncData相同,对对
threadCount进行+1,进入【第六步】遍历结束,未找到相同对象,查看未使用的
SyncData是否存在存在,将未使用的
SyncData中的object覆盖,threadCount重置为1,进入【第六步】不存在,需要分配新的
SyncData,进入【第五步】
如果无法遍历,证明当前
object第一次进入,需要分配新的SyncData,进入【第五步】
【第五步】分配一个新的
SyncData并添加到SyncList中对
object赋值,threadCount初始化为1使用单链表头插法,新增节点总是插在头部
进入【第七步】
【第六步】将
SyncData保存到tls线程或者缓存中判断
fastCacheOccupied,如果tls中存在SyncData,fastCacheOccupied为真如果为真,说明
tls还在占用,保存到缓存如果为假,保存到当前线程的
tls中
通过源码分析,同线程中的lockCount,表示@synchronized可递归使用。而SyncData中的threadCount,表示@synchronized可在多线程中使用
哈希表的结构
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock#define LIST_FOR_OBJ(obj) sDataLists[obj].datastatic StripedMap<SyncList> sDataLists;
lock和data都取自sDataLists,类型为StripedMap,使用static修饰,系统中只存在一份
来到StripedMap的定义
template<typename T>class StripedMap {#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATORenum { StripeCount = 8 };#elseenum { StripeCount = 64 };#endif...}
StripedMap是哈希表结构,真机预留8个空间,而模拟器上预留64个空间。所以之前测试锁的性能,使用真机和模拟器运行,结果略有不同
存储到链表的情况,当不同对象生成相同哈希,也就是出现哈希冲突的情况,会直接存储在链表中
另一种情况,以模拟器为例,当StripedMap中64个位置都插满后,并没有扩容操作。此时出现新对象,一定会出现哈希冲突,这时会将SyncData插入到链表中
从代码逻辑上看,会进入【第四步】遍历SyncList,但因为SyncData中的对象和传入的对象不同,会在链表中找未使用的SyncData覆盖。如果找不到未使用的SyncData,会分配一个新的SyncData并添加到SyncList中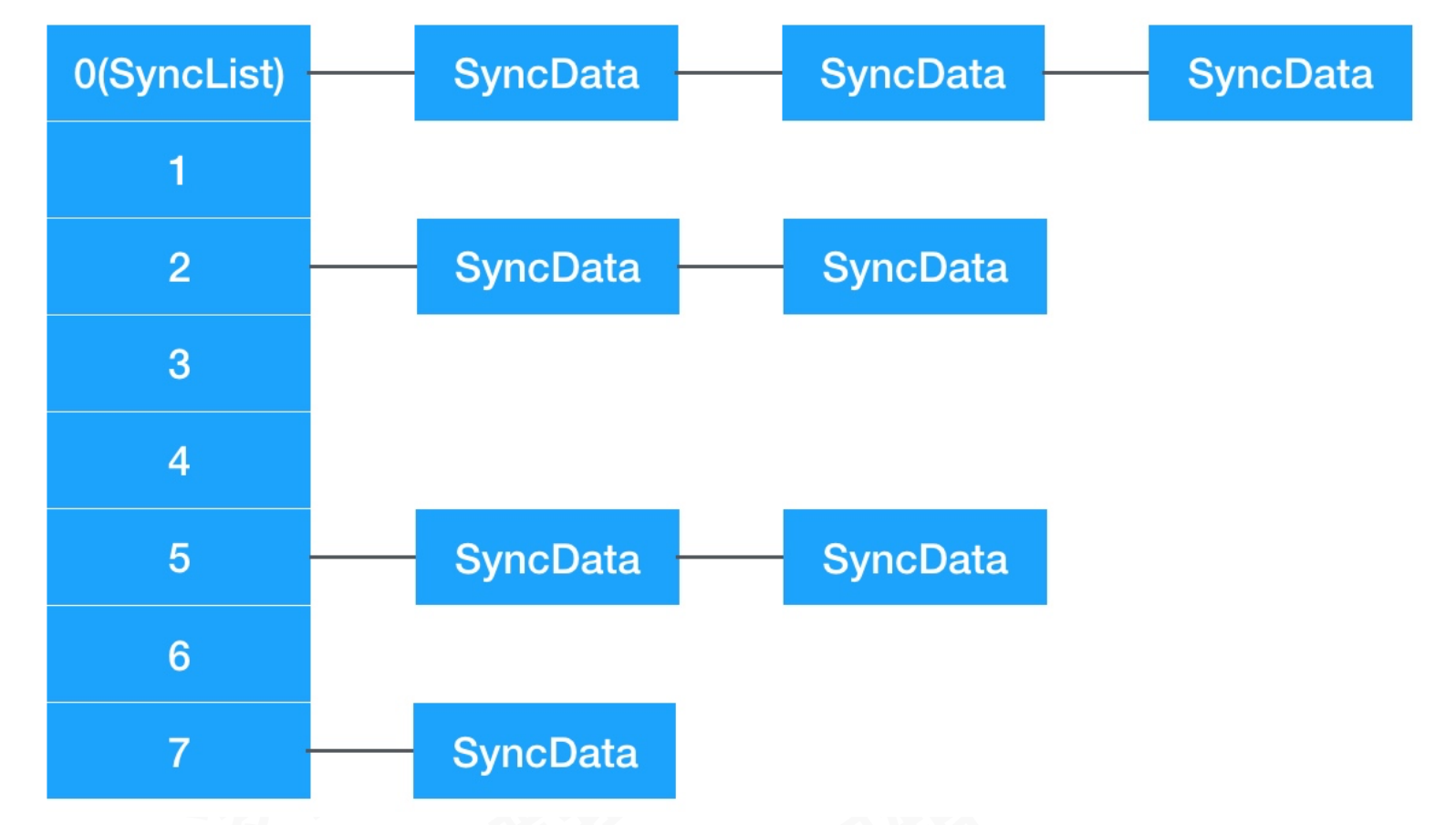
2.3 TLS线程相关解释
线程局部存储(Thread Local Storage,TLS):是操作系统为线程单独提供的私有空间,通常只有有限的容量
Linux系统下通过pthread库中的API使用:
pthread_key_create()pthread_getspecific()pthread_setspecific()pthread_key_delete()
2.4 注意事项
@synchronized为递归互斥锁,lockCount表示可递归使用,threadCount表示可在多线程中使用使用
@synchronized时,不能传入nil,使用nil锁的功能无法生效在日常开发中,经常会传入
self,它的好处可以保证生命周期同步,对象不会提前释放不能使用非
OC对象作为加锁对象,因为其object的参数为id类型底层的缓存和链表都使用循环遍历查找,所以性能偏低。但开发中使用方便简单,并且不用解锁,所以使用频率较高
3. pthread_mutex
在Posix Thread中定义有⼀套专⻔⽤于线程同步的mutex函数
mutex:⽤于保证在任何时刻,都只能有⼀个线程访问该对象。当获取锁操作失败时,线程会进⼊睡眠,等待锁释放时被唤醒
API:
//导入头文件#import <pthread/pthread.h>//锁的声明pthread_mutex_t _lock;//锁的初始化pthread_mutex_init(&_lock, NULL);//加锁pthread_mutex_lock(&_lock);//解锁pthread_mutex_unlock(&_lock);//锁的释放pthread_mutex_destroy(&_lock);
4. NSLock
NSLock的底层对pthread_mutex进行封装,同样是一把互斥锁。但它属于非递归互斥锁,所有不能进行递归使用
API:
//锁的初始化NSLock *lock = [[NSLock alloc] init];//加锁[lock lock];//解锁[lock unlock];
4.1 源码分析
NSLock的源码在Foundation框架中
由于OC的Foundation框架未能开源,我们通过Swift的Foundation源码代替
打开swift-corelibs-foundation-master项目,找到NSLock的实现
NSLock遵循NSLocking协议
public protocol NSLocking {func lock()func unlock()}
NSLock的初始化、销毁、加锁、解锁功能,都是对pthread_mutex进行二次封装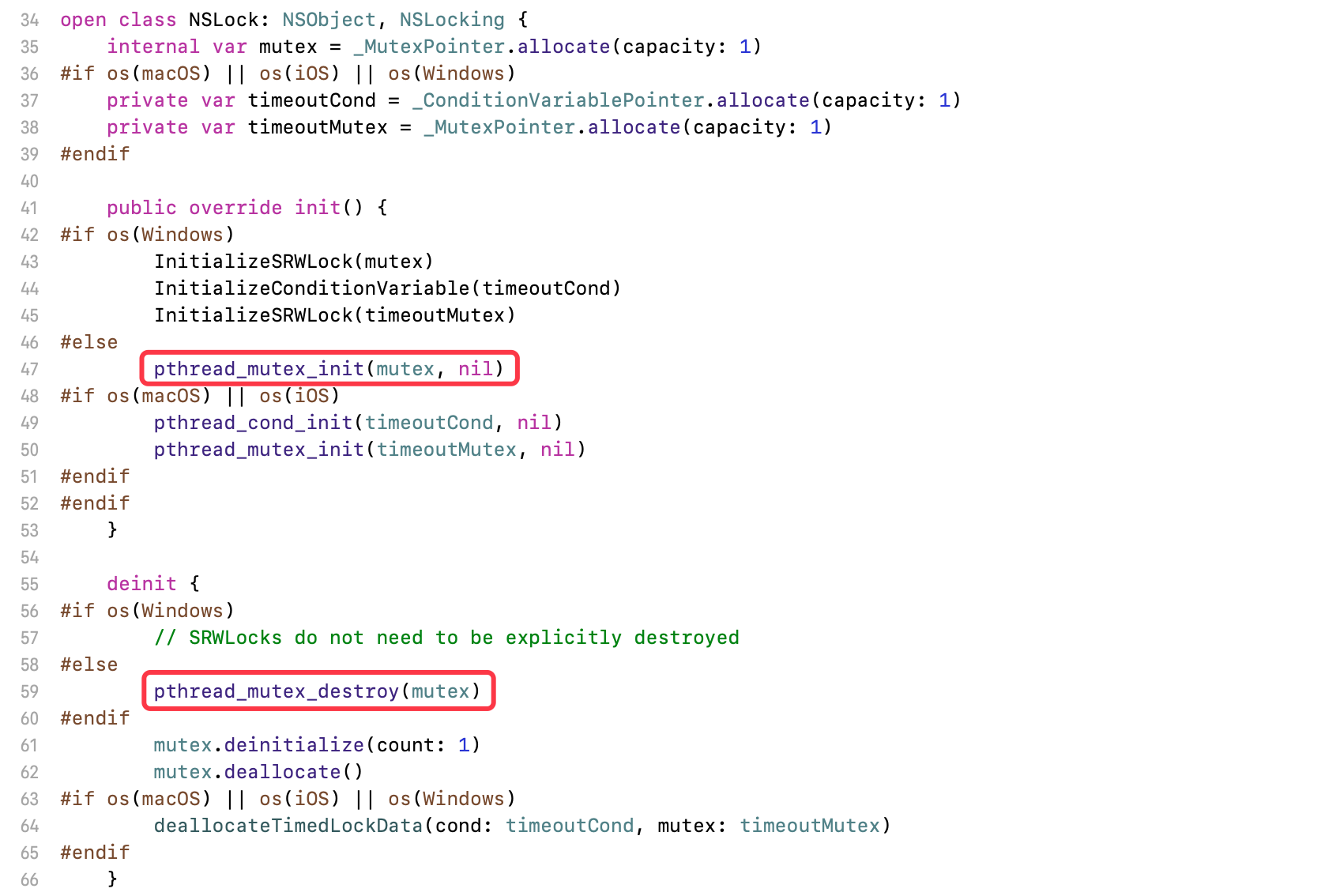
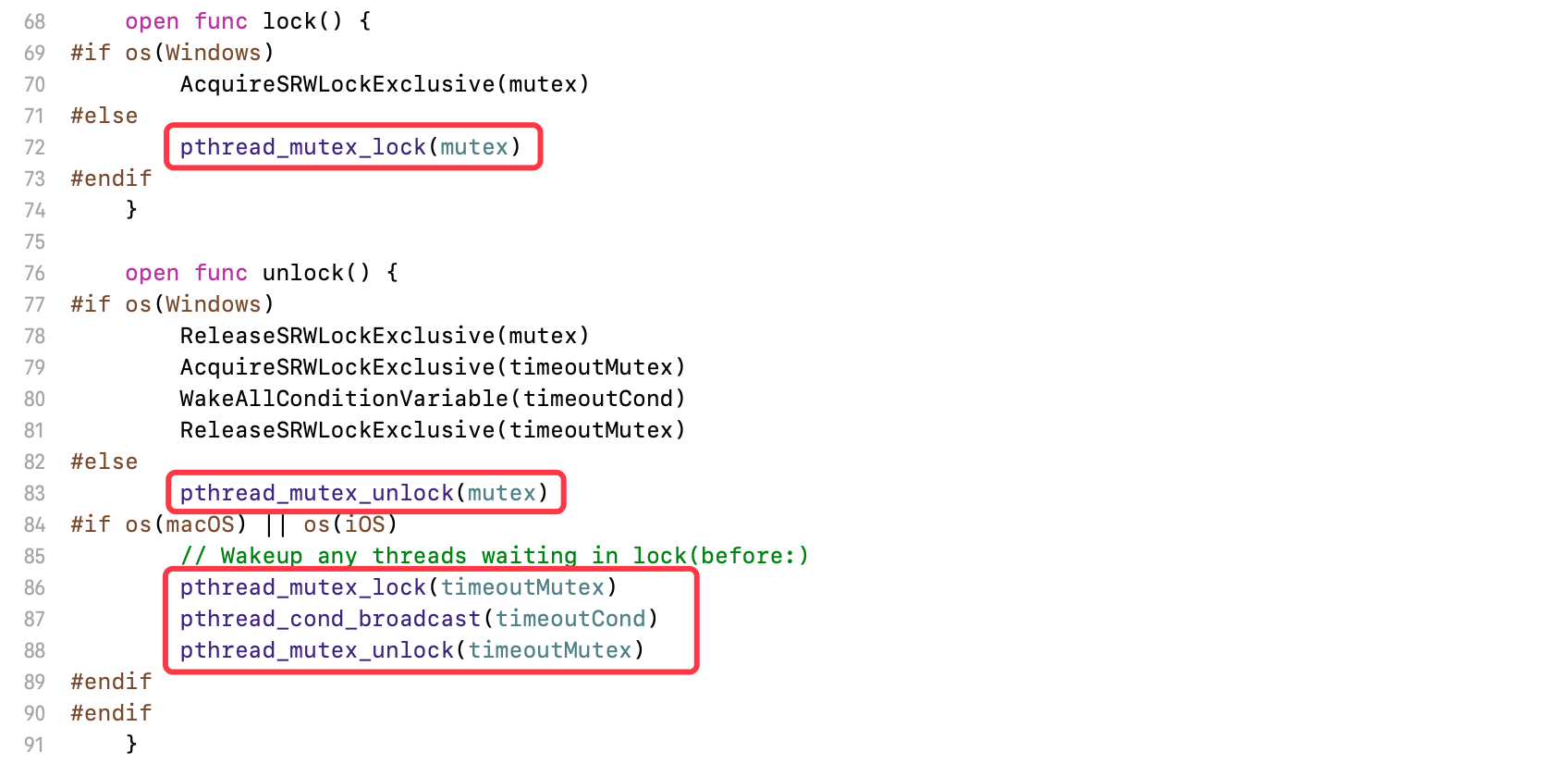
NSLock的初始化方法中,封装了pthread_mutex的初始化- 使用
NSLock必须调用它的init方法 - 通过
pthread_cond_broadcast广播,唤醒在锁中等待的所有线程
4.2 缺陷
NSLock属于非递归互斥锁,所有不能进行递归使用
案例:
- (void)lg_testRecursive{NSLock *lock = [[NSLock alloc] init];for (int i=0; i<10; i++) {dispatch_async(dispatch_get_global_queue(0, 0), ^{static void (^testMethod)(int);testMethod = ^(int value){if (value > 0) {NSLog(@"current value = %d",value);testMethod(value - 1);}};[lock lock];testMethod(10);[lock unlock];});}}
- 在异步函数的代码中,使用
NSLock进行加锁和解锁,可以保证线程安全,从10~1顺序输出,循环打印10遍
在block方法中进行加锁,同样可以保证线程安全。但NSLock属于非递归锁,遇到递归场景,在没有unlock的情况下,再次执行lock,造成死锁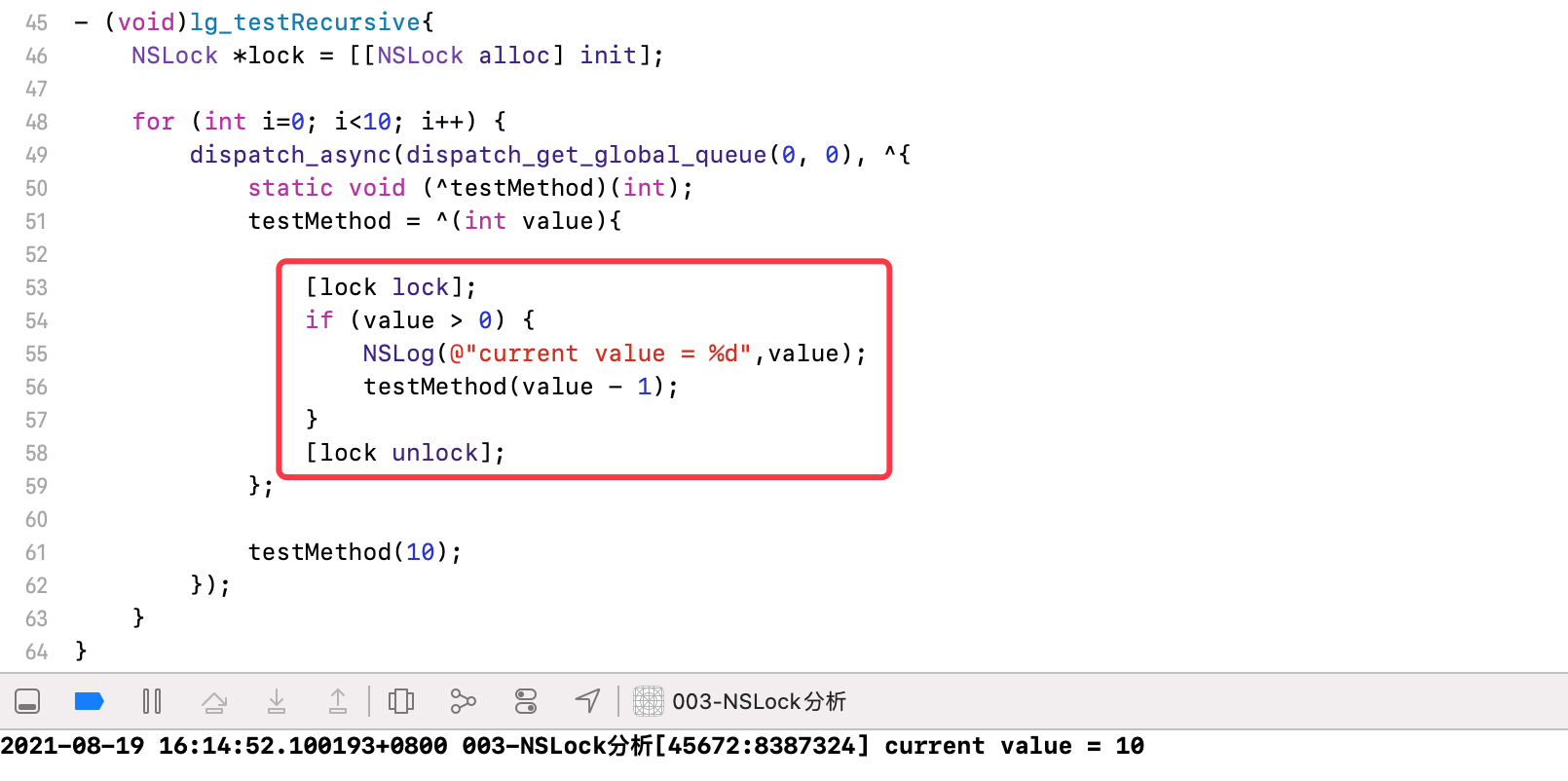
- 后面的结果无法继续打印
5. NSRecursiveLock
NSRecursiveLock也是对pthread_mutex进行封装,属于递归锁。它可以允许同一线程多次加锁,而不会造成死锁
- 与
NSLock相比,它可以在递归场景中使用 - 但它没有
@synchronized强大,因为它不支持在多线程中递归加锁
API:
//锁的初始化NSRecursiveLock *recursiveLock = [[NSRecursiveLock alloc] init];//加锁[recursiveLock lock];//解锁[recursiveLock unlock];
5.1 源码分析
找到NSRecursiveLock的实现,同样遵循了NSLocking协议。NSRecursiveLock的初始化、销毁、加锁、解锁功能,都是对pthread_mutex进行二次封装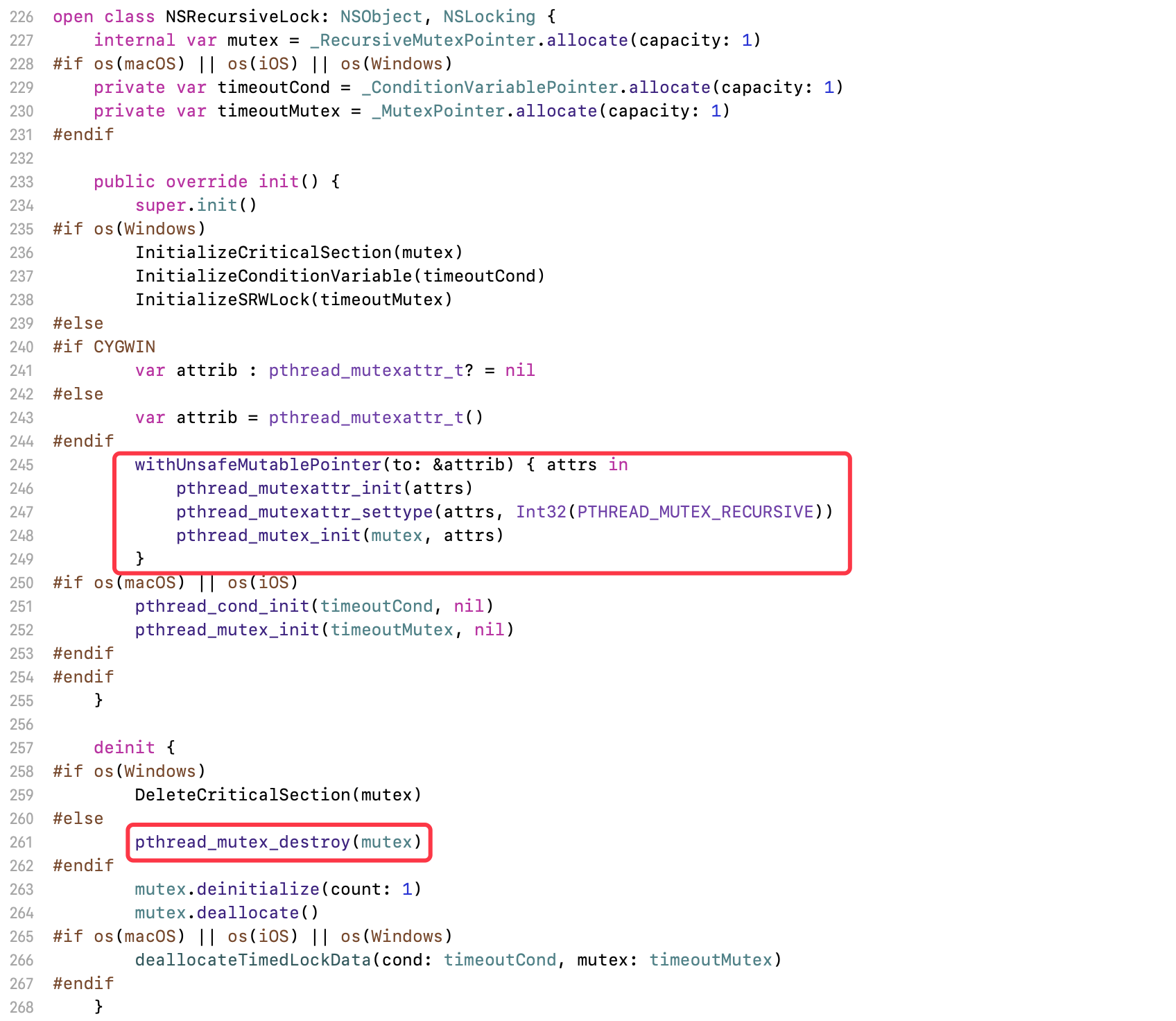
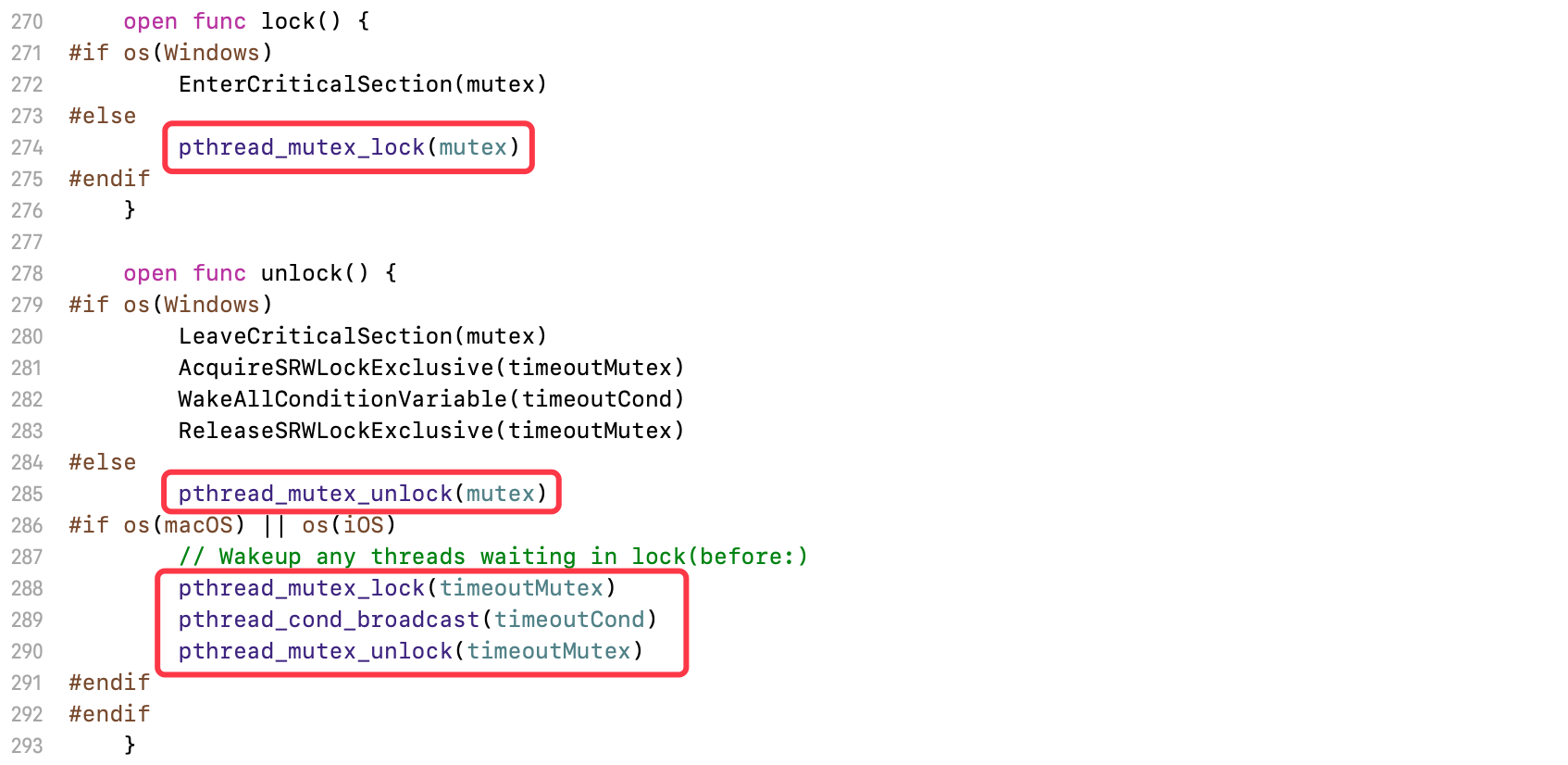
NSRecursiveLock的实现和NSLock非常相似,它们最大的区别在于初始化,NSRecursiveLock对pthread_mutex设置PTHREAD_MUTEX_RECURSIVE标示,故此NSRecursiveLock是一把递归互斥锁
pthread_mutexattr_settype(attrs, Int32(PTHREAD_MUTEX_RECURSIVE))
5.2 缺陷
NSRecursiveLock会跟踪它被lock的次数。每次成功的lock都必须平衡调用unlock操作。只有所有达到这种平衡,锁最后才能被释放,以供其它线程使用
案例:
- 在单一线程中正常打印出
10~1后,多线程递归执行报错
6. NSCondition
NSCondition属于条件锁,使用的方式和信号量相似。当线程满足需求后才会继续执行,否则会阻塞线程,使其进入休眠状态
NSCondition的对象实际上作为⼀个锁和⼀个线程检查器
- 锁主要为了当检测条件时保护数据源,执⾏条件引发的任务
- 线程检查器主要是根据条件决定是否继续运⾏线程,即线程是否被阻塞
API:
//⽤于多线程同时访问、修改同⼀个数据源//保证在同⼀时间内数据源只被访问、修改⼀次//其他线程的命令需要在lock外等待,直到unlock,才可访问[condition lock];//与lock同时使⽤[condition unlock];//使当前线程处于等待状态[condition wait];//CPU发信号告诉线程不⽤等待,可以继续执⾏[condition signal];
6.1 使用
生产消费者的模型案例:
#import "ViewController.h"@interface ViewController ()@property (nonatomic, assign) NSUInteger ticketCount;@property (nonatomic, strong) NSCondition *testCondition;@end@implementation ViewController- (void)viewDidLoad {[super viewDidLoad];[self lg_testConditon];}#pragma mark -- NSCondition- (void)lg_testConditon{_testCondition = [[NSCondition alloc] init];//创建生产-消费者for (int i = 0; i < 50; i++) {dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{[self lg_consumer];});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{[self lg_consumer];});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{[self lg_producer];});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{[self lg_producer];});}}- (void)lg_producer{//操作的多线程影响[_testCondition lock];self.ticketCount = self.ticketCount + 1;NSLog(@"生产一个 现有 count %zd",self.ticketCount);//信号[_testCondition signal];[_testCondition unlock];}- (void)lg_consumer{//操作的多线程影响[_testCondition lock];while (self.ticketCount == 0) {NSLog(@"等待 count %zd",self.ticketCount);[_testCondition wait];}//注意消费行为,要在等待条件判断之后self.ticketCount -= 1;NSLog(@"消费一个 还剩 count %zd",self.ticketCount);[_testCondition unlock];}@end
生产者和消费者都进行了加锁处理,保证线程安全
当消费者发现库存为0的时候,线程等待
当生产者增加库存后,发送信号。消费者收到信号,之前等待的线程继续执行
消费者判断库存为0,使用while循环,而不是if判断
使用
if判断,唤醒线程后会从wait之后的代码开始运行,但是不会重新判断if条件,直接继续运行if代码块之后的代码使用
while循环,也会从wait之后的代码运行,但是唤醒后会重新判断循环条件,如果不成立再执行while代码块之后的代码块,成立的话继续wait
6.2 源码分析
找到NSCondition的实现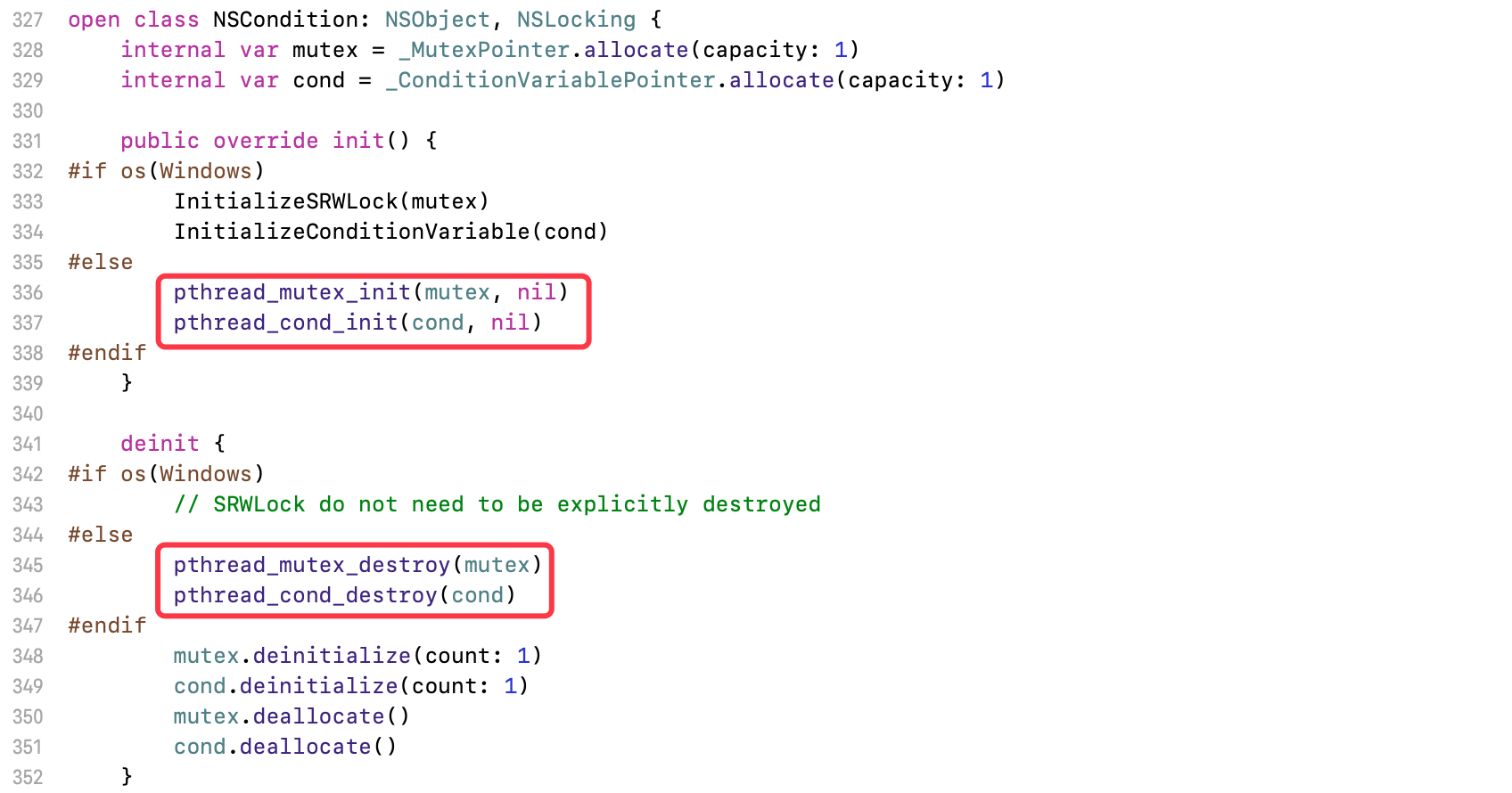

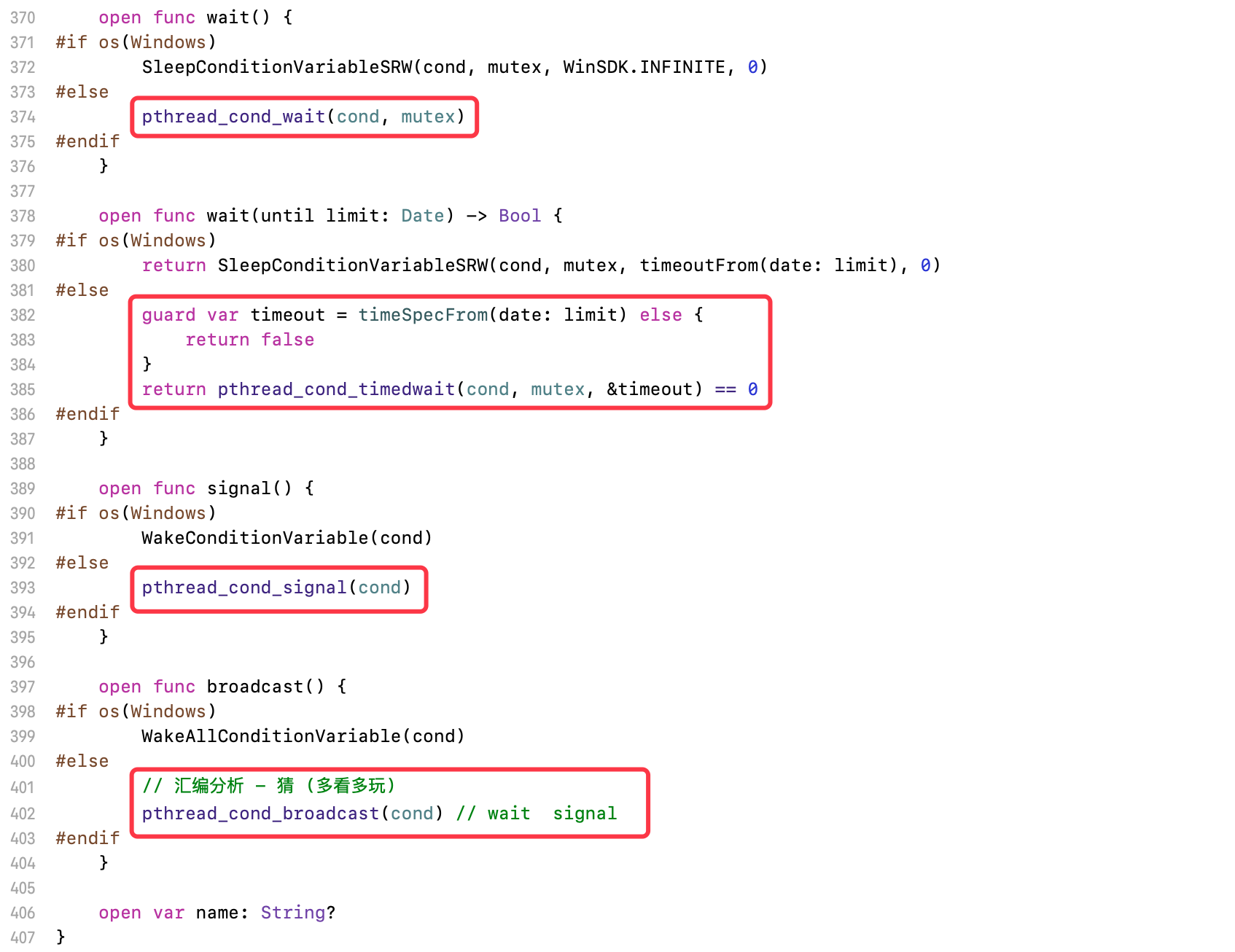
底层采用
pthread_mutex+pthread_cond实现pthread_mutex:对互斥锁进行封装pthread_cond:用来控制条件变量的执行情况
wait:操作会阻塞线程,使其进入休眠状态signal:操作唤醒一个正在休眠等待的线程,使其继续执行wait之后的代码块broadcast:唤醒在锁中等待的所有线程
7. NSConditionLock
NSConditionLock是一把条件锁,⼀个线程获得锁,其他线程⼀定等待。它的内部对NSCondition又做了一层封装,自带条件探测,能够更简单灵活的使用
与NSCondition相比:
相同点:
都是互斥锁
通过条件变量来控制加锁、释放锁,从而达到阻塞线程、唤醒线程的目的
不同点:
NSCondition是基于pthread_mutex的封装,而NSConditionLock是基于NSCondition又做了一层封装NSCondition需要手动让线程进入等待状态阻塞线程、释放信号唤醒线程,而NSConditionLock只需要外部传入一个值,就会依据这个值进行自动判断,决定阻塞线程还是唤醒线程
API:
⽆条件锁:
[conditionLock lock];[conditionLock unlock];
- 表示
condition期待获得锁,如果没有其他线程获得锁(不需要判断内部的condition) ,那它能执⾏此⾏以下代码 - 如果已经有其他线程获得锁(可能是条件锁,或者⽆条件锁),则等待,直⾄其他线程解锁
条件锁:
[conditionLock lockWhenCondition:A条件];
- 表示如果没有其他线程获得该锁,但是该锁内部的
condition不等于A条件,它依然不能获得锁,仍然等待 - 如果内部的
condition等于A条件,并且没有其他线程获得该锁,则进⼊代码区,同时设置它获得该锁,其他任何线程都将等待它代码的完成,直⾄它解锁 - 所谓的
A条件就是整数,内部通过整数⽐较条件
释放条件锁
[conditionLock unlockWithCondition:A条件];
- 表示释放锁,同时把内部的
condition设置为A条件
条件锁 + 超时时间:
return = [conditionLock lockWhenCondition:A条件 beforeDate:A时间];
- 表示如果被锁定(没获得锁),并超过该时间则不再阻塞线程。但是注意:返回的值是
NO,它没有改变锁的状态,这个函数的⽬的在于可以实现两种状态下的处理
7.1 使用
案例:
- (void)lg_testConditonLock{NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:2];dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{[conditionLock lockWhenCondition:1];NSLog(@"线程1");[conditionLock unlockWithCondition:0];});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{[conditionLock lockWhenCondition:2];NSLog(@"线程2");[conditionLock unlockWithCondition:1];});dispatch_async(dispatch_get_global_queue(0, 0), ^{[conditionLock lock];NSLog(@"线程3");[conditionLock unlock];});}
- 案例的执行结果,大概率为
线程3、线程2、线程1
NSConditionLock初始化,设置的条件为2。按照线程优先级顺序:
线程1优先级最高,但不符合条件,代码块无法执行,进入等待状态线程3默认优先级,同时属于无条件锁,可以执行代码块线程2优先级最低,但符合条件,也可以执行代码块
所以,大概率线程3会在线程2之前打印,而线程1必须等待线程2执行完,释放条件锁之后才能执行
7.2 源码分析
初始化: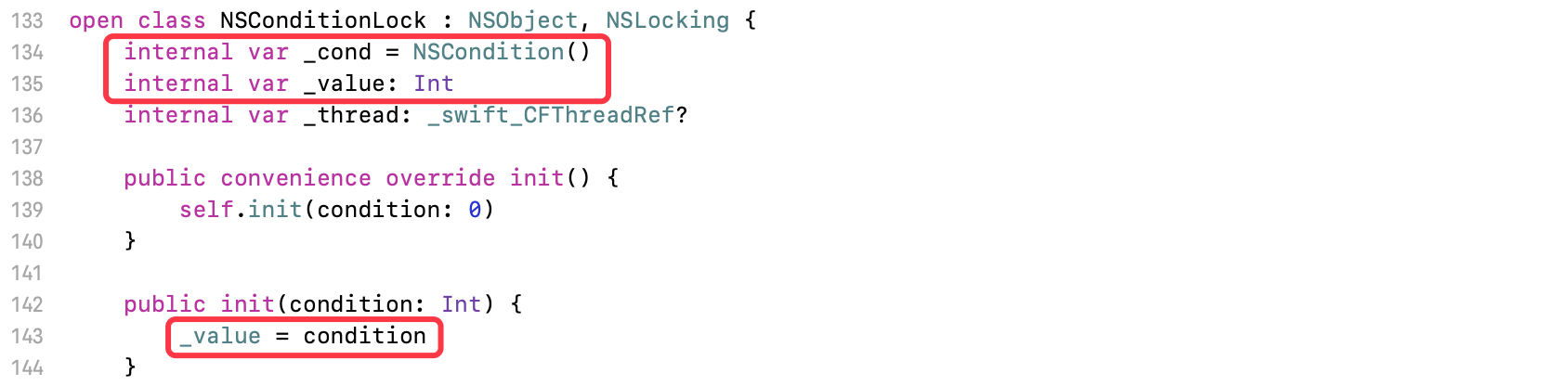
NSCondition和条件value,作为NSConditionLock的成员变量- 初始化时将条件赋值
value
无条件锁:
open func lock() {let _ = lock(before: Date.distantFuture)}open func lock(before limit: Date) -> Bool {_cond.lock()while _thread != nil {if !_cond.wait(until: limit) {_cond.unlock()return false}}#if os(Windows)_thread = GetCurrentThread()#else_thread = pthread_self()#endif_cond.unlock()return true}
- 调用
lock方法,底层调用的是lock(before limit: Date)方法,无条件判断,可直接执行
释放无条件锁:
open func unlock() {_cond.lock()#if os(Windows)_thread = INVALID_HANDLE_VALUE#else_thread = nil#endif_cond.broadcast()_cond.unlock()}
- 调用
unlock方法,实际上处理的是NSCondition
条件锁:
open func lock(whenCondition condition: Int) {let _ = lock(whenCondition: condition, before: Date.distantFuture)}open func lock(whenCondition condition: Int, before limit: Date) -> Bool {_cond.lock()while _thread != nil || _value != condition {if !_cond.wait(until: limit) {_cond.unlock()return false}}#if os(Windows)_thread = GetCurrentThread()#else_thread = pthread_self()#endif_cond.unlock()return true}
- 内部进行
lock和unlock处理,保证线程安全 - 如果条件不一致,调用
wait方法进入等待状态 - 否则,调用
pthread_self方法
释放条件锁:
open func unlock(withCondition condition: Int) {_cond.lock()#if os(Windows)_thread = INVALID_HANDLE_VALUE#else_thread = nil#endif_value = condition_cond.broadcast()_cond.unlock()}
- 内部进行
lock和unlock处理,保证线程安全 - 更新条件
value - 调用
broadcast方法,进行广播,唤醒在锁中等待的所有线程
7.3 汇编分析
7.3.1 initWithCondition:
设置-[NSConditionLock initWithCondition:]符号断点,真机运行项目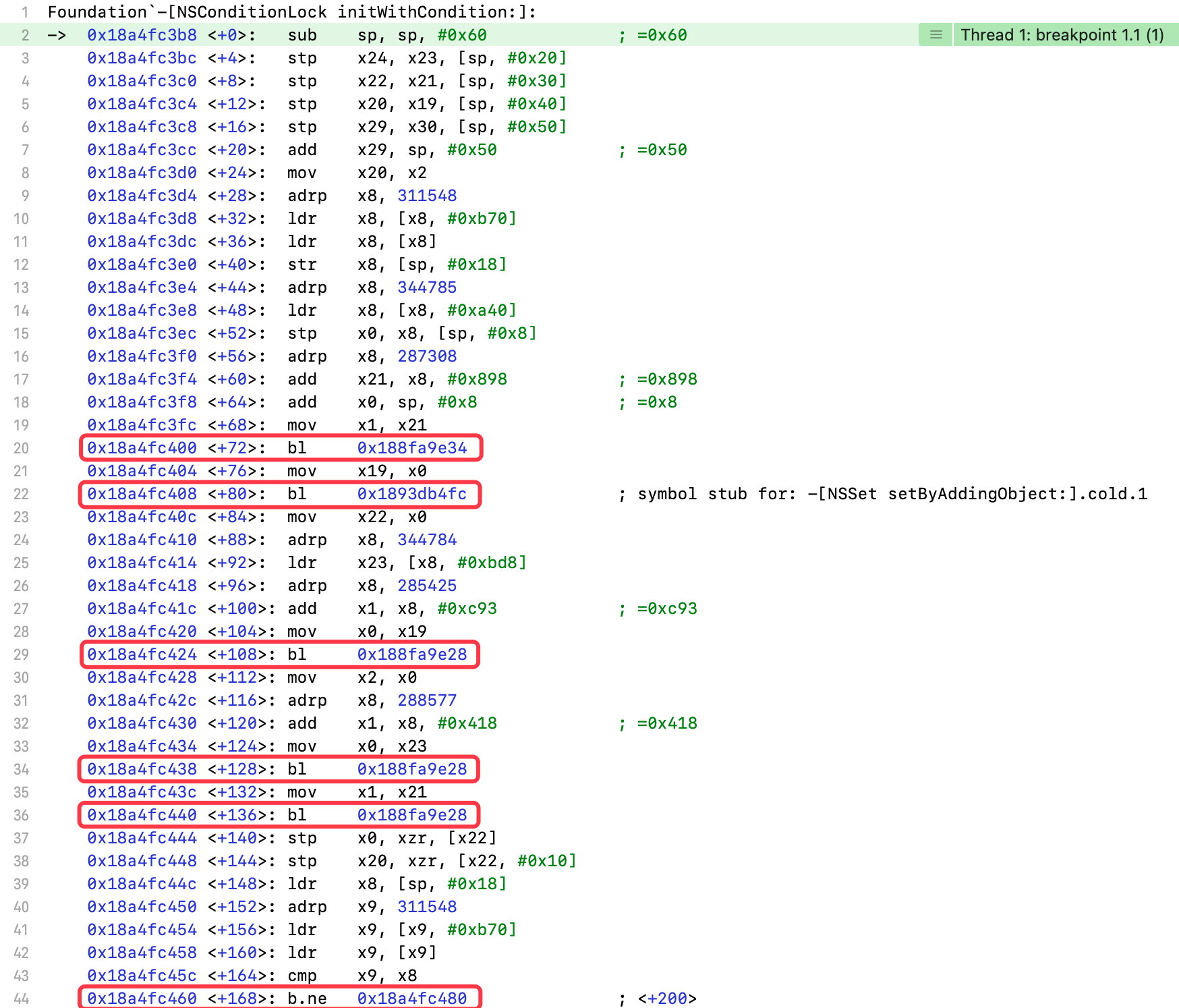
- 面对复杂的汇编代码,我们可以对所有的跳转代码设置断点,例如:
bl、b等指令,然后读取x0、x1寄存器查看消息接收者和方法编号,遇到ret指令,通过x0查看返回值
执行bl 0x188fa9e34指令
(lldb) register read x0x0 = 0x000000016f7b99c8(lldb) register read x1x1 = 0x00000001d0748898(lldb) po 0x000000016f7b99c86165338568(lldb) po (SEL)0x00000001d0748898"init"
- 调用一个未知对象的
init方法
执行bl 0x1893db4fc指令
(lldb) register read x0x0 = 0x0000000283e72670(lldb) register read x1x1 = 0x00000001d0748898(lldb) po 0x0000000283e72670<NSConditionLock: 0x283e72670>{condition = 0, name = nil}(lldb) po (SEL)0x00000001d0748898"init"
- 调用
NSConditionLock对象的init方法
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000283e72670(lldb) register read x1x1 = 0x00000001cffedc93(lldb) po 0x0000000283e72670<NSConditionLock: 0x283e72670>{condition = 0, name = nil}(lldb) po (SEL)0x00000001cffedc93"zone"
- 调用
NSConditionLock对象的zone方法,开辟内存空间
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x00000001de1d0e20 (void *)0x00000001de1d0e48: NSCondition(lldb) register read x1x1 = 0x00000001d0c3d418(lldb) po (SEL)0x00000001d0c3d418"allocWithZone:"(lldb) register read x2x2 = 0x00000001ded98000 libsystem_malloc.dylib`virtual_default_zone
- 调用
NSCondition类对象的allocWithZone:方法 - 传入参数:
virtual_default_zone
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000280220510(lldb) register read x1x1 = 0x00000001d0748898(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}(lldb) po (SEL)0x00000001d0748898"init"
- 调用
NSCondition对象的init方法
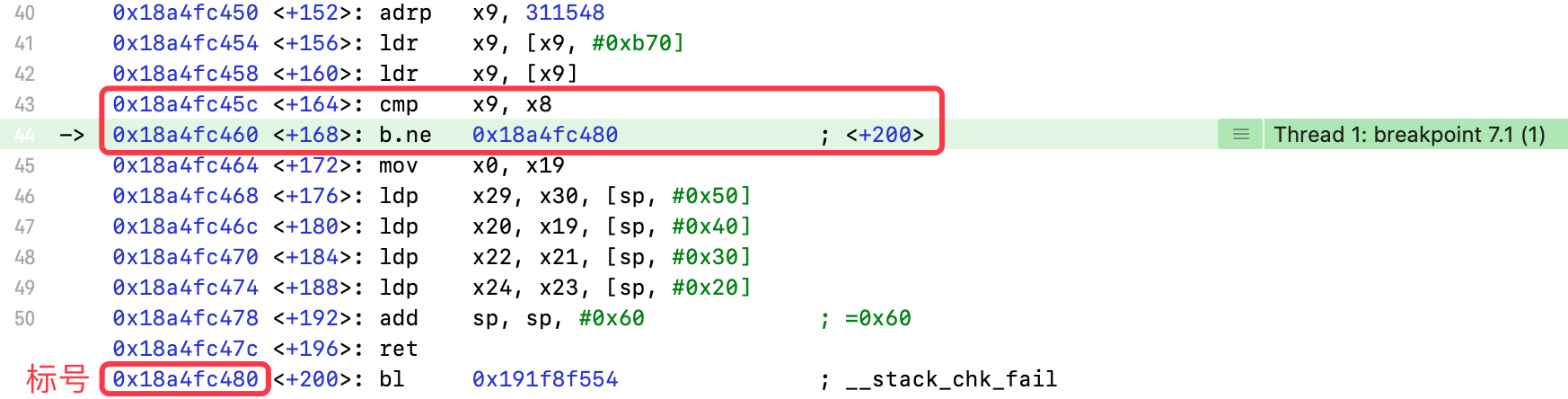
- 比较
x8、x9寄存器 b.ne:比较结果是不等于(not equal to),执行标号处指令,否则继续执行
输出x8、x9寄存器
(lldb) register read x9x9 = 0x933ba4ad46660065(lldb) register read x8x8 = 0x933ba4ad46660065
- 相等,继续执行
执行ret指令,输出x0寄存器,查看返回值
(lldb) register read x0x0 = 0x0000000283e72670(lldb) po 0x0000000283e72670<NSConditionLock: 0x283e72670>{condition = 2, name = nil}
- 返回
NSConditionLock实例对象
使用x/8g命令,查看实例对象的内存结构
(lldb) x/8g 0x283e726700x283e72670: 0x000021a1de1d0ec1 0x00000000000000000x283e72680: 0x0000000280220510 0x00000000000000000x283e72690: 0x0000000000000002 0x00000000000000000x283e726a0: 0x0000a817e1de26a0 0x00000000006000cc(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}
NSCondition和初始化设置的默认条件,都作为成员变量保存在NSConditionLock的实例对象中- 设置的默认条件:
0x0000000000000002,即:初始化时传入的2
7.3.2 lockWhenCondition:
设置-[NSConditionLock lockWhenCondition:]符号断点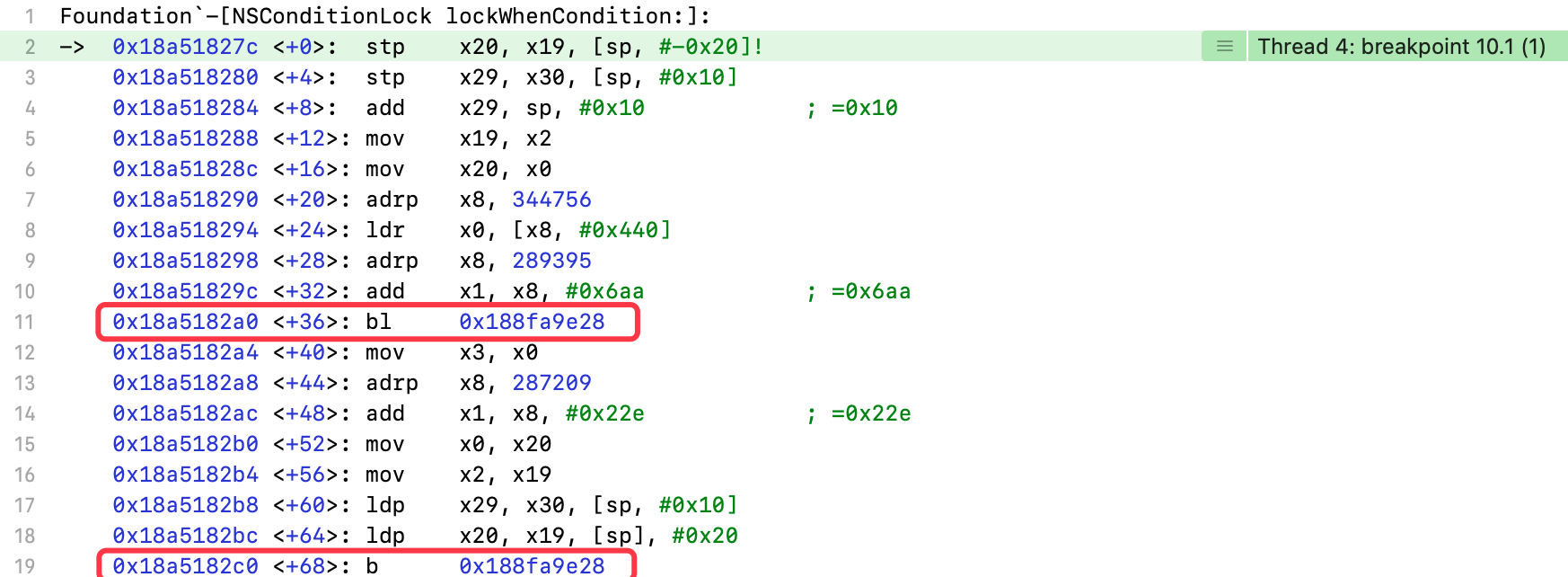
输出x0、x1、x2寄存器
(lldb) register read x0x0 = 0x0000000283fcbb40(lldb) register read x1x1 = 0x00000001d0543629(lldb) register read x2x2 = 0x0000000000000001(lldb) po 0x0000000283fcbb40<NSConditionLock: 0x283fcbb40>{condition = 2, name = nil}(lldb) po (SEL)0x00000001d0543629"lockWhenCondition:"
- 执行
线程1的代码 x2:传入的条件值为1
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x00000001de1c7030 (void *)0x00000001de1c7058: NSDate(lldb) register read x1x1 = 0x00000001d0f8b6aa(lldb) po (SEL)0x00000001d0f8b6aa"distantFuture"
- 调用
NSDate的distantFuture方法
执行b 0x188fa9e28指令
(lldb) register read x0x0 = 0x00000002813fc360(lldb) register read x1x1 = 0x00000001d070122e(lldb) po 0x00000002813fc360<NSConditionLock: 0x2813fc360>{condition = 2, name = nil}(lldb) po (SEL)0x00000001d070122e"lockWhenCondition:beforeDate:"(lldb) register read x2x2 = 0x0000000000000001(lldb) register read x3x3 = 0x00000001d64d7168 CoreFoundation`_NSConstantDateDistantFuture
- 调用
NSConditionLock对象的lockWhenCondition:beforeDate:方法 x2:传入的条件值1x3:上一个bl,调用distantFuture方法得到的返回值
7.3.3 lockWhenCondition:beforeDate:
设置-[NSConditionLock lockWhenCondition:beforeDate:]符号断点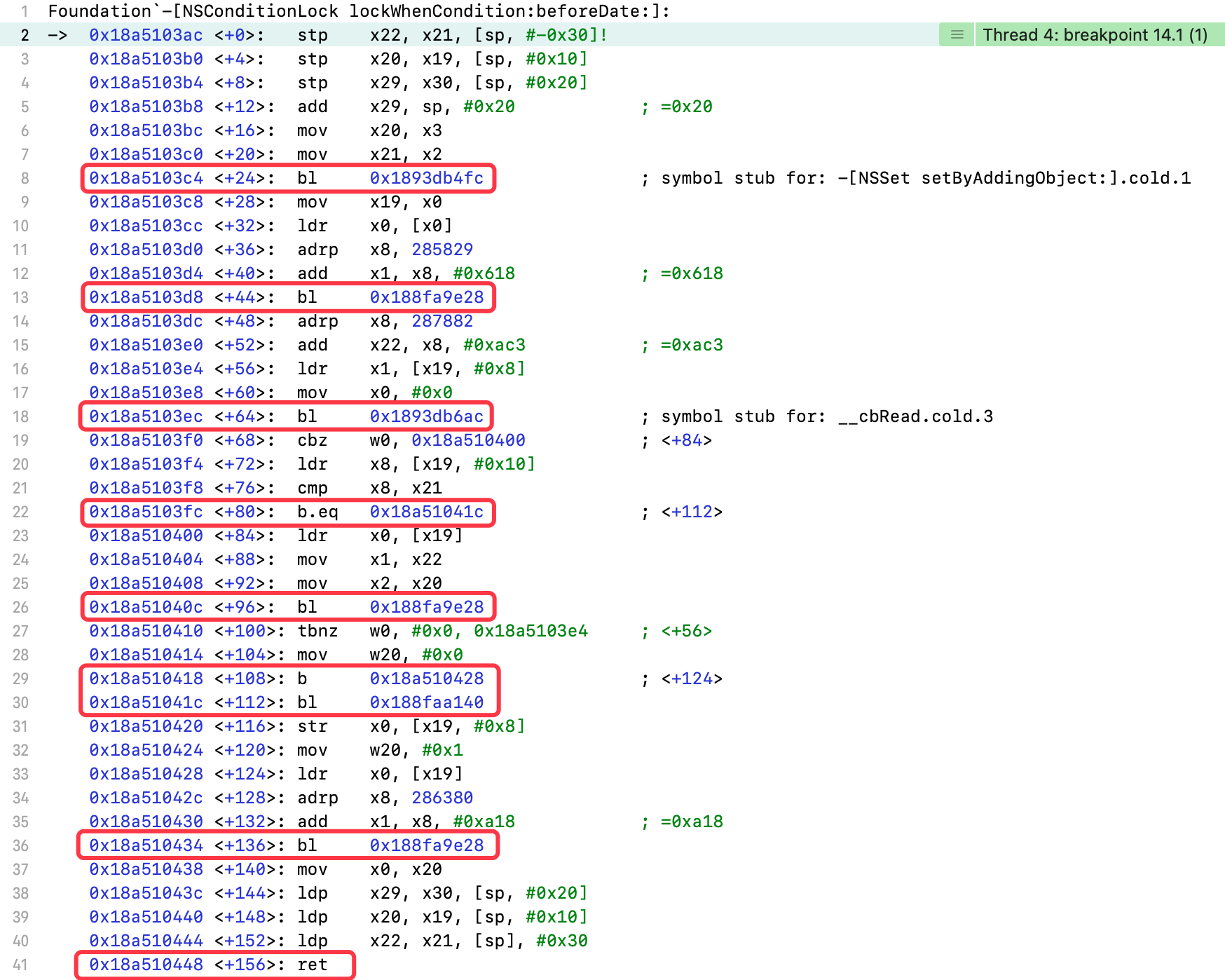
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000280220510(lldb) register read x1x1 = 0x00000001d0195618(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}(lldb) po (SEL)0x00000001d0195618"lock"
- 调用
NSCondition对象的lock方法
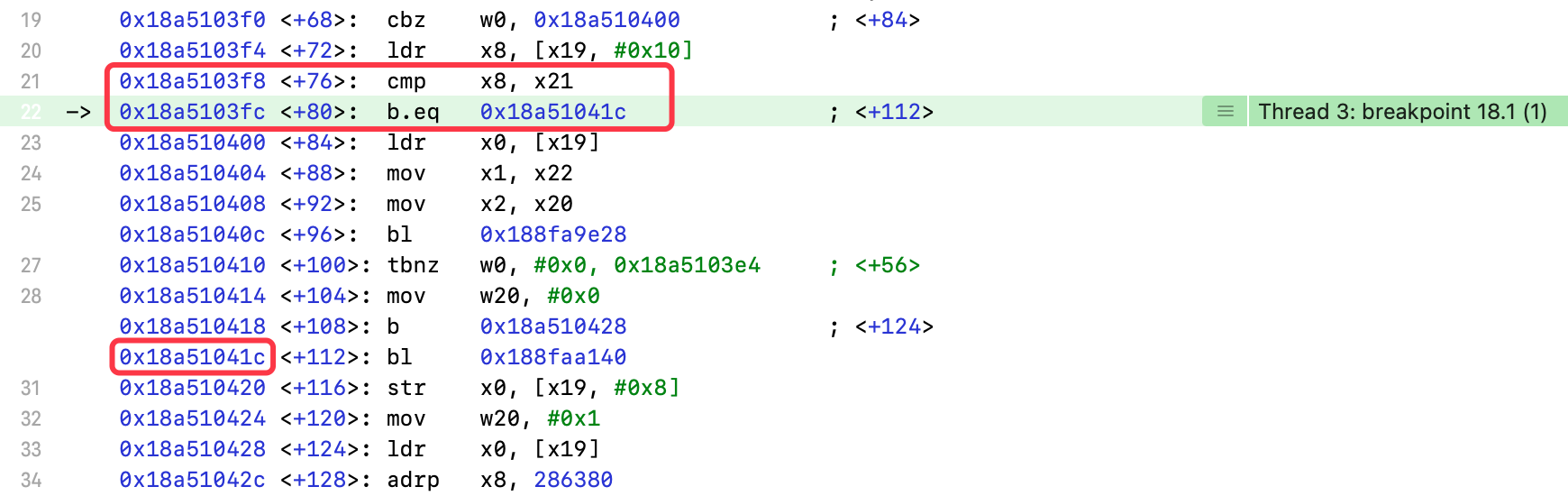
- 比较
x8、x21寄存器 b.eq:比较结果是等于(equal to),执行标号处指令,否则继续执行
输出x8、x21寄存器
(lldb) register read x8x8 = 0x0000000000000002(lldb) register read x21x21 = 0x0000000000000001
- 不相等,继续执行
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000281ad5050(lldb) register read x1x1 = 0x00000001d099aac3(lldb) po 0x0000000281ad5050<NSCondition: 0x281ad5050>{name = nil}(lldb) po (SEL)0x00000001d099aac3"waitUntilDate:"
- 调用
NSCondition对象的waitUntilDate:方法 - 线程进入等待状态
程序继续执行,此时会切换线程,跳转到线程2的lockWhenCondition:方法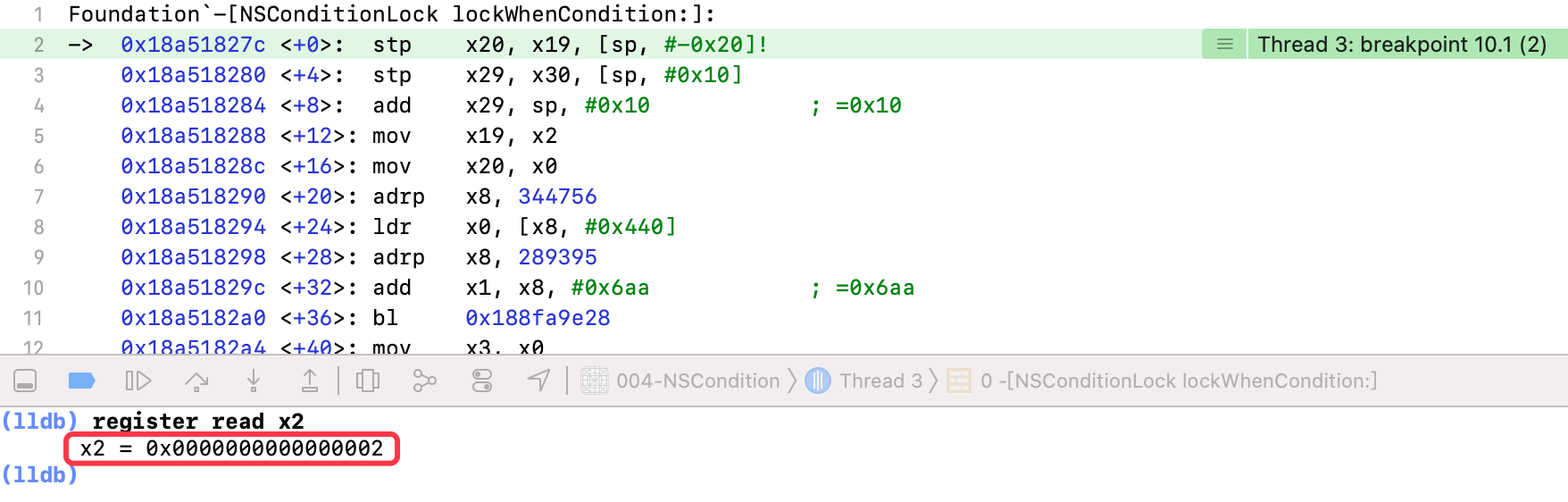
x2:传入的条件值为2
程序继续执行,进入线程2的lockWhenCondition:beforeDate:方法
(lldb) register read x0x0 = 0x0000000283e72670(lldb) register read x1x1 = 0x00000001d070122e(lldb) po 0x0000000283e72670<NSConditionLock: 0x283e72670>{condition = 2, name = nil}(lldb) po (SEL)0x00000001d070122e"lockWhenCondition:beforeDate:"(lldb) register read x2x2 = 0x0000000000000002(lldb) register read x3x3 = 0x00000001d64d7168 CoreFoundation`_NSConstantDateDistantFuture
- 和之前调用
线程1的区别,传入的条件值为2
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000280220510(lldb) register read x1x1 = 0x00000001d0195618(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}(lldb) po (SEL)0x00000001d0195618"lock"
- 调用
NSCondition对象的lock方法
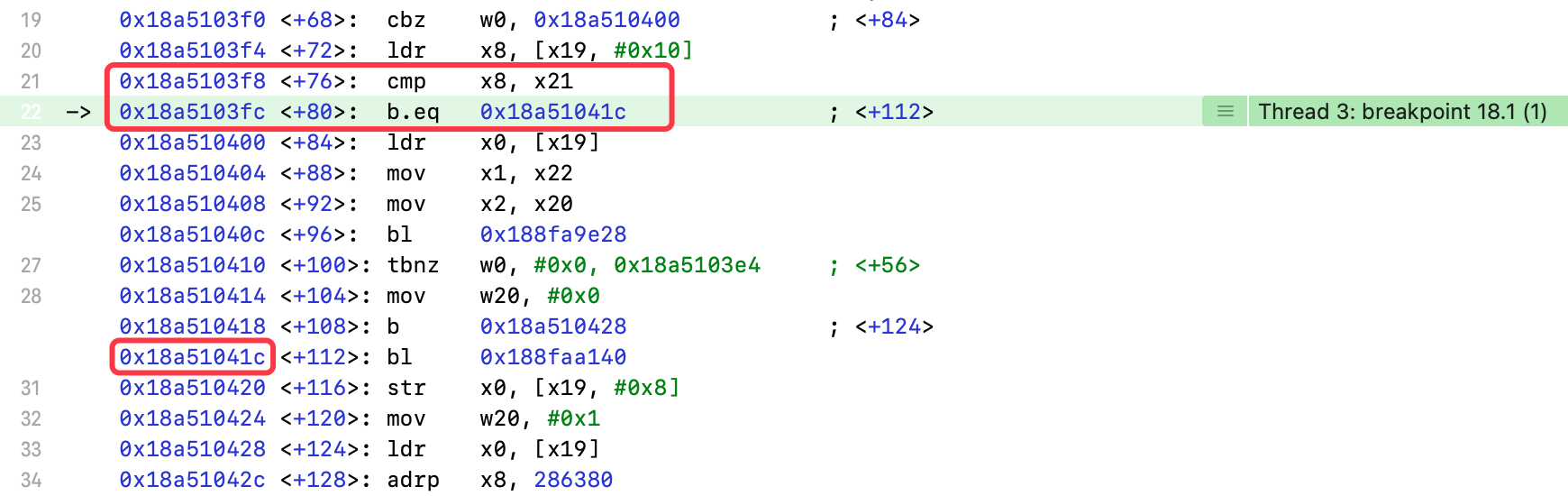
- 比较
x8、x21寄存器 b.eq:比较结果是等于(equal to),执行标号处指令,否则继续执行
输出x8、x21寄存器
(lldb) register read x8x8 = 0x0000000000000002(lldb) register read x21x21 = 0x0000000000000002
- 相等,执行标号处指令
执行bl 0x188faa140指令
(lldb) register read x0x1 = 0x0000000000000001
- 只能看出
x0寄存器的值为1,具体执行的代码未知
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000280220510(lldb) register read x1x1 = 0x00000001d03bca18(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}(lldb) po (SEL)0x00000001d03bca18"unlock"
- 调用
NSCondition对象的unlock方法
执行ret指令,输出x0寄存器,查看返回值
(lldb) register read x0x0 = 0x0000000000000001
- 返回值为
1,表示条件符合,代码块执行完成
如果条件不符合,线程进入等待状态,因为超时导致代码块未执行,会进行解锁,然后返回0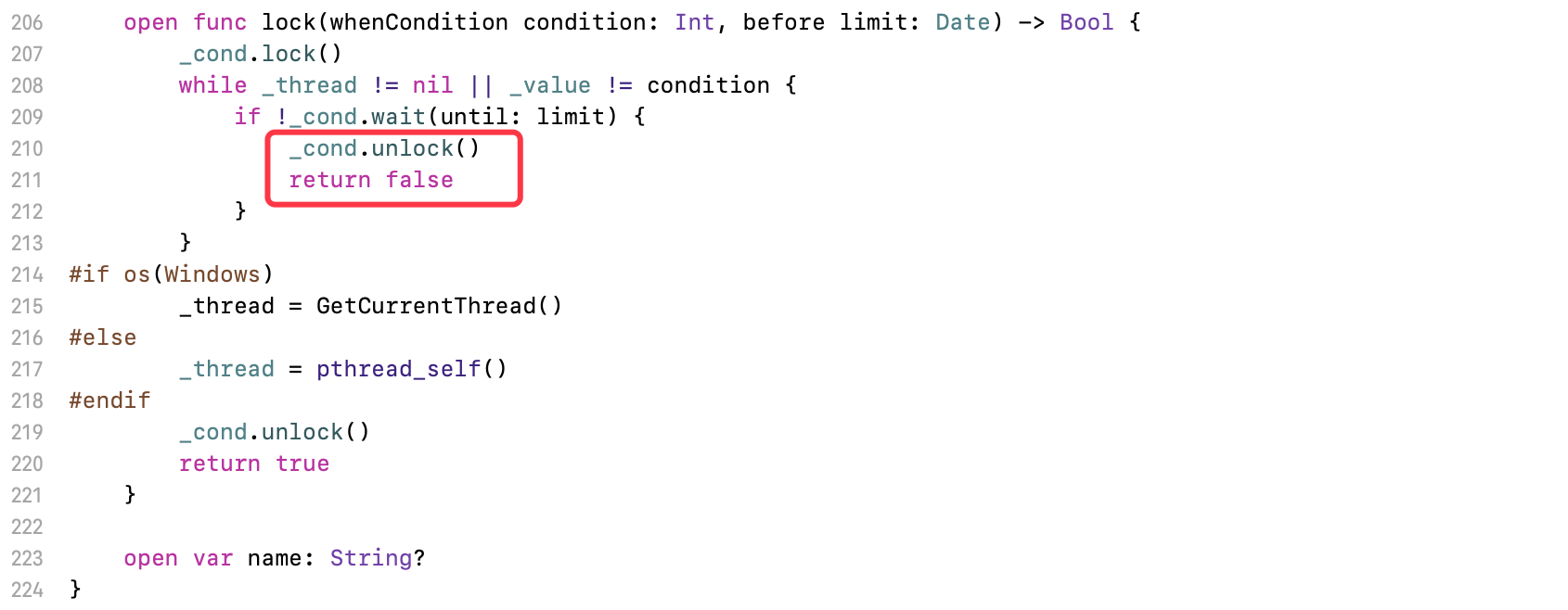
7.3.4 unlockWithCondition:
设置-[NSConditionLock unlockWithCondition:]符号断点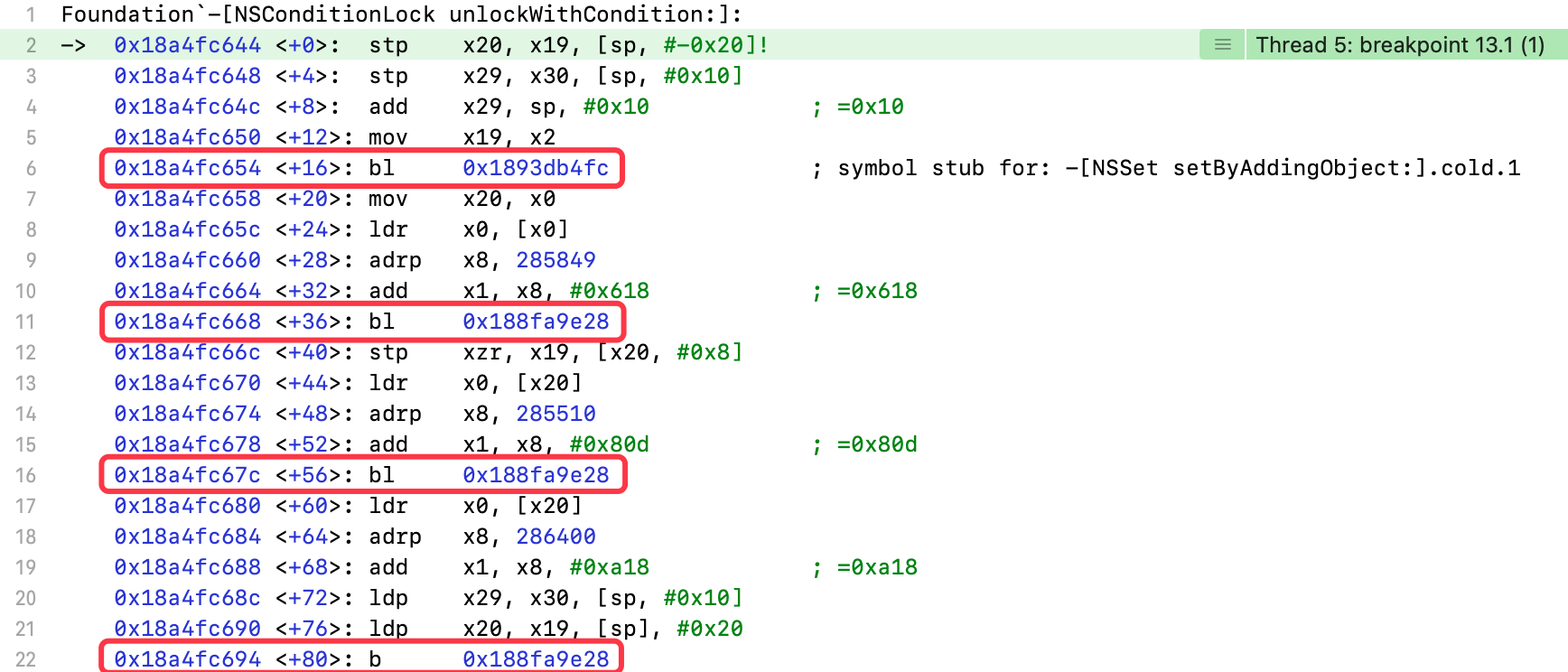
进入线程2的unlockWithCondition:方法
(lldb) register read x2x2 = 0x0000000000000001
- 传入的条件值为
1
执行bl 0x1893db4fc指令
(lldb) register read x0x0 = 0x0000000282688330(lldb) register read x1x1 = 0x00000001d025a602(lldb) po 0x0000000282688330<NSConditionLock: 0x282688330>{condition = 2, name = nil}(lldb) po (SEL)0x00000001d025a602"unlockWithCondition:"
- 调用
NSConditionLock对象的unlockWithCondition:方法
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000281ad5050(lldb) register read x1x1 = 0x00000001d0195618(lldb) po 0x0000000281ad5050<NSCondition: 0x281ad5050>{name = nil}(lldb) po (SEL)0x00000001d0195618"lock"
- 调用
NSCondition对象的lock方法
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000281ad5050(lldb) register read x1x1 = 0x00000001d004280d(lldb) po 0x0000000281ad5050<NSCondition: 0x281ad5050>{name = nil}(lldb) po (SEL)0x00000001d004280d"broadcast"
- 调用
NSCondition对象的broadcast方法,进行广播,唤醒在锁中等待的所有线程
执行b 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000281ad5050(lldb) register read x1x1 = 0x00000001d03bca18(lldb) po 0x0000000281ad5050<NSCondition: 0x281ad5050>{name = nil}(lldb) po (SEL)0x00000001d03bca18"unlock"
- 调用
NSCondition对象的unlock方法
使用b指令,表示义无反顾的跳转,不再返回。此方法执行完,线程2的代码执行结束
但是,在线程2中,调用NSCondition对象的broadcast方法,触发广播操作。此时,处于等待状态的线程1将被唤醒,继续线程1的代码执行
7.3.5 唤醒线程1
程序继续执行,此时会切换线程,跳转到线程1的lockWhenCondition:方法
此时线程1解除等待状态,继续执行代码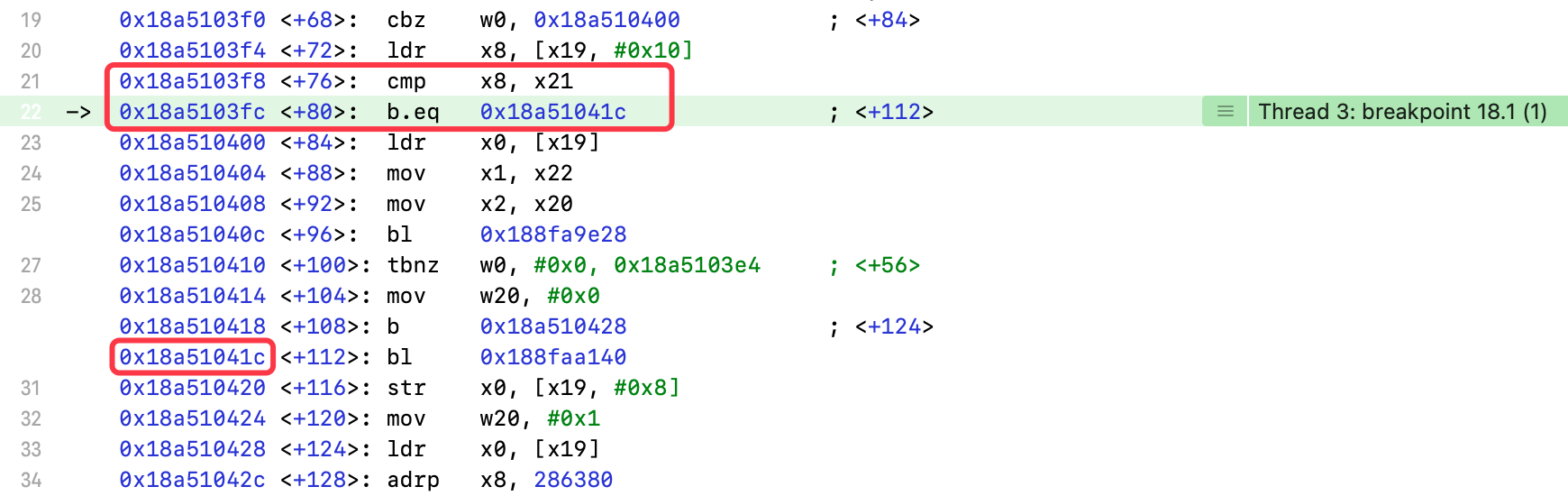
- 比较
x8、x21寄存器 b.eq:比较结果是等于(equal to),执行标号处指令,否则继续执行
输出x8、x21寄存器
(lldb) register read x8x8 = 0x0000000000000001(lldb) register read x21x21 = 0x0000000000000001
- 相等,执行标号处指令
执行bl 0x188faa140指令
(lldb) register read x0x1 = 0x0000000000000001
- 只能看出
x0寄存器的值为1,具体执行的代码未知
执行bl 0x188fa9e28指令
(lldb) register read x0x0 = 0x0000000280220510(lldb) register read x1x1 = 0x00000001d03bca18(lldb) po 0x0000000280220510<NSCondition: 0x280220510>{name = nil}(lldb) po (SEL)0x00000001d03bca18"unlock"
- 调用
NSCondition对象的unlock方法
执行ret指令,输出x0寄存器,查看返回值
(lldb) register read x0x0 = 0x0000000000000001
- 返回值为
1
之后会进入线程1的unlockWithCondition:方法,释放条件锁
8. 自旋锁
8.1 atomic
atomic是属性的修饰,不是锁
源码中针对atomic加锁的地方都定义为spinlock,也就是自旋锁。但是苹果在iOS10之后弃用OSSpinLock,内部使用os_unfair_lock实现,所以它在底层自带的是一把互斥锁
using spinlock_t = mutex_tt<LOCKDEBUG>;class mutex_tt : nocopy_t {os_unfair_lock mLock;...};
使用atomic修饰,只是能保证数据的完整性,单一线程安全,不能保证多线程安全。锁操作导致效率低,不推荐使用
案例:
- (void)lg_test_atomic2{//Thread Adispatch_async(dispatch_get_global_queue(0, 0), ^{for (int i = 0; i < 100000; i ++) {if (i % 2 == 0) {self.array = @[@"Hank", @"CC", @"Cooci"];}else {self.array = @[@"Kody"];}NSLog(@"Thread A: %@\n", self.array);}});//Thread Bdispatch_async(dispatch_get_global_queue(0, 0), ^{for (int i = 0; i < 100000; i ++) {if (self.array.count >= 2) {NSString* str = [self.array objectAtIndex:1];}NSLog(@"Thread B: %@\n",self.array);}});}
在线程A中,循环遍历的索引为偶数,数组中的元素一定存在三个
在线程B中,如果数组中的元素>= 2,获取第一个元素
如果这两个逻辑在同一线程中执行,一定不会报错。但由于多线程,atomic无法保证多线程安全,所以程序还是会崩溃
8.2 OSSpinLock
OSSpinLock是一把自旋锁,由于安全性问题,iOS10之后被os_unfair_lock(互斥锁)替代。使用OSSpinLock,会让线程处于忙等待状态。目前OSSpinLock还可以使用,但不推荐
案例:
#import "ViewController.h"#import <libkern/OSAtomic.h>#import <os/lock.h>@interface ViewController (){OSSpinLock _spinLock;}@implementation ViewController- (void)viewDidLoad {[super viewDidLoad];[self lg_testOSSPinLock];}#pragma mark -- OSSpinLock- (void)lg_testOSSPinLock{_spinLock = OS_SPINLOCK_INIT;// 线程1dispatch_async(dispatch_get_global_queue(0, 0), ^{NSLog(@"线程1 准备上锁,currentThread:%@",[NSThread currentThread]);OSSpinLockLock(&_spinLock);NSLog(@"线程1");sleep(3);OSSpinLockUnlock(&_spinLock);NSLog(@"线程1 解锁完成");});// 线程2dispatch_async(dispatch_get_global_queue(0, 0), ^{NSLog(@"线程2 准备上锁,currentThread:%@",[NSThread currentThread]);OSSpinLockLock(&_spinLock);NSLog(@"线程2");sleep(3);OSSpinLockUnlock(&_spinLock);NSLog(@"线程2 解锁完成");});}@end
9. os_unfair_lock
os_unfair_lock是一把互斥锁,使用os_unfair_lock,会让线程处于休眠状态
API:
//导入头文件#import <libkern/OSAtomic.h>#import <os/lock.h>//初始化os_unfair_lock _unfairLock = OS_UNFAIR_LOCK_INIT;//加锁os_unfair_lock_lock(&_unfairLock);//解锁os_unfair_lock_unlock(&_unfairLock);
10. 读写锁
通常,当读写锁处于读模式锁住状态时,如果有另外线程试图以写模式加锁,读写锁通常会阻塞随后的读模式锁请求。这样可以避免读模式锁⻓期占⽤,⽽等待的写模式锁请求⻓期阻塞
读写锁适合于对数据结构的读次数⽐写次数多得多的情况,因为读模式锁定时可以共享,以写模式锁住时意味着独占,所以读写锁⼜叫共享/独占锁
读写锁要实现以下几点:
多读单写
读和写互斥
写操作之间互斥
不能阻塞正常的任务执行
读写锁的两种实现方式:
使用
pthread实现使用
GCD实现
10.1 使用pthread实现
//导入头文件#include <pthread.h>//初始化int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr)//释放int pthread_rwlock_destroy(pthread_rwlock_t *rwlock)
- 成功返回
0, 出错返回错误编号 - 同互斥量以上,在释放读写锁占⽤的内存之前,需要先通过
pthread_rwlock_destroy对读写锁进⾏清理⼯作,释放由init分配的资源
//读锁int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);//写锁int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);//释放锁int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
- 成功返回
0, 出错返回错误编号 - 三个函数分别实现获取读锁,获取写锁和释放锁的操作.
- 获取锁的两个函数是阻塞操作
⾮阻塞的获取锁操作:
//读锁int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock)//写锁int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock)
- 成功返回
0, 出错返回错误编号
10.2 使用GCD实现
使用GCD创建自定义并发队列
通过同步函数实行读操作
通过异步栅栏函数实现写操作
将同步函数和异步栅栏函数加入同一队列,可以满足读写互斥,写操作之间的互斥。并且异步栅栏函数只会阻塞自身队列中的任务,不会影响其他任务的执行
声明:
#import "ViewController.h"@interface ViewController ()@property (nonatomic,strong) NSMutableDictionary *dic;@property (nonatomic,strong) dispatch_queue_t queue;@end
初始化:
- (void)viewDidLoad {[super viewDidLoad];_dic = [NSMutableDictionary dictionary];_queue = dispatch_queue_create("queue", DISPATCH_QUEUE_CONCURRENT);}
读操作:
- (NSString *)safrGetter:(NSString *)strKey{__block NSString* strValue;dispatch_sync(self.queue, ^{strValue = [self.dic objectForKey:strKey];NSLog(@"safrGetter:%@,%@,%@",strKey,strValue,[NSThread currentThread]);});return strValue;}
写操作:
- (void)safeSetter:(NSString *)strKey strValue:(NSString *)strValue{dispatch_barrier_async(self.queue, ^{[self.dic setObject:strValue forKey:strKey];NSLog(@"safeSetter:%@,%@,%@",strKey,strValue,[NSThread currentThread]);});}
测试代码:
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{[self test];}-(void)test{for (int intIndex=0; intIndex<50; intIndex++) {dispatch_async(dispatch_get_global_queue(0, 0), ^{[self safeSetter:[NSString stringWithFormat:@"key_%i",intIndex] strValue:[NSString stringWithFormat:@"value_%i",intIndex]];[self safrGetter:[NSString stringWithFormat:@"key_%i",intIndex]];});}}
总结
@synchronize:
采用
SyncData结构,包含nextData、threadCount和recursive_mutex_t递归锁@synchronized在底层维护一张哈希表,用来存储SyncData的单向链表。当遇到哈希冲突时,存储在链表中同一对象,单一线程多次加锁使用
lockCount记录,通过tls或缓存查找并记录同一对象,多线程加锁使用
threadCount记录,通过哈希表查找并记录所以
@synchronized更强大,可递归使用,可多线程使用
NSLock:
底层对
pthread_mutex进行封装线程安全,但不能递归使用
NSRecursiveLock:
底层对
pthread_mutex进行封装,通过PTHREAD_MUTEX_RECURSIVE标记为递归锁可递归使用,但不能多线程使用
NSCondition:
底层对
pthread_mutex进行封装条件锁,需要手动让线程进入等待状态阻塞线程、释放信号唤醒线程
NSConditionLock:
底层基于
NSCondition又做了一层封装条件锁,只需要外部传入一个值,就会依据这个值进行自动判断,决定阻塞线程还是唤醒线程
atomic:
atomic是属性的修饰,不是锁。它在底层自带一把互斥锁,只是能保证数据的完整性,单一线程安全,不能保证多线程安全。锁操作导致效率低,不推荐使用atomic:当属性在调用setter、getter方法时,会加上互斥锁os_unfair_lock,用于保证同一时刻只能有一个线程调用属性的读或写,避免了属性读写不同步的问题
nonatomic:
- 当属性在调用
setter、getter方法时,没有任何锁的操作,线程不安全。效率高,推荐使用
OSSpinLock:
自旋锁,由于安全性问题,
iOS10之后被os_unfair_lock替代目前
OSSpinLock还可以使用,但不推荐使用
OSSpinLock,会处于忙等待状态
os_unfair_lock:
互斥锁
使用
os_unfair_lock,会处于休眠状态
读写锁:
多读单写
读和写互斥
写操作之间互斥
不能阻塞正常的任务执行
两种实现方式:
使用
pthread实现使用
GCD实现

若有收获,就点个赞吧
0 人点赞
