🎈re模块
python中re模块是提供的一套关于处理正则表达式的模块
模块中提供了多个函数来匹配处理字符串
例如:compile、match 、search 、findall 、finditer 、split 、sub subn
| 函数 | 描述 |
|---|---|
| match (pattrtn,string,flags=0) |
根据pattern从string的头部开始匹配字符串 只返回1次匹配的对象 否则,返回None |
findall (pattern,string,flags=0) |
根据pattern在string中匹配字符串, 如果匹配成功,返回包含匹配的列表; 否则返回空列表。当pattern中有分组时, 返回包含多个元组的列表,每个元组对应1个分组。 flags表示规则选项,规则选项用于辅助匹配 |
sub (pattern,repl,string,count=0) |
根据指定的正则表达式,替换源字符串中的字串。 pattern是一个正则表达式, repl用于替换的字符串 string是源字符串。 如果count等于0,则返回string中匹配的所有结果; 若干count大于0,则返回count个匹配结果 |
| subn (pattern,repl,string,count=0) |
作用和sub()相同,返回一个二元的元组 第一个元素是替换结果 第二个是元素的替换次数 |
| search (pattern,string,flags=0) |
根据pattern在string中匹配字符串, 只返回1次匹配成功的对象 如果匹配失败,返回None |
| compile (pattern,flags=0) |
编译正则表达式pattern 返回1个pattern对象 |
| split (pattern,string,maxsplit=0) |
根据pattern分隔string,maxsplit表示最大分隔数 |
| escape (pattern) |
匹配字符串中的特殊字符,如*、+、?等 |
re 模块的一般使用步骤如下:
- import re导入re模块
- 使用 compile 函数将正则表达式的字符串形式编译为一个表达式对象
- 通过对表达式对象提供的一系列方法对文本进行匹配查找,获得匹配结果
- 最后使用 Match 对象提供的属性和方法获得信息
✨正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是事先定义好的一些特定字符、及这些特定字符的组合,组成“规则字符串”这个“规则字符串”用来表达对字符串的一种过滤逻辑;正则表达式是一种文本模式,模式描述在搜索文本时要匹配一个或多个字符串
作用:
- 给定的字符串是否符合正则表达式的过滤逻辑(称为“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
- 还可以对目标字符串进行替换操作
正则表达式的使用
re模块提供了一些根据正则表达式进行查找、替换、分隔字符串的函数。
match方法
match(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
#导入re模块import re#创建要匹配的对象str1="hello python"#定义要匹配的值pattern="hello"#调用match函数obj1=re.match(pattern,str1)print(obj1)#<re.Match object; span=(0, 5), match='hello'>print(type(obj1))#<class 're.Match'>
re.match尝试从字符的起始位置匹配:
匹配成功返回的是一个re.Match类型对象
匹配失败返回None
调用group可以返回匹配成功的字符串
修饰符(flag的参数)的介绍
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包括行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\w,\W,\b\B |
| re.X | 该标志通过给予你更灵活的格式以便你正则表达式写的更加理解 |
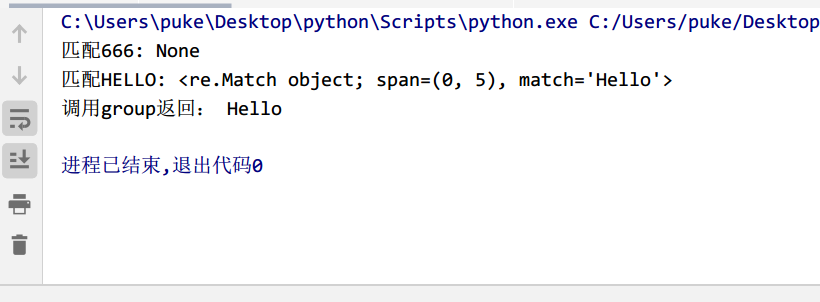
import restr2="Hello Python"pattern1="666"obj1=re.match(pattern1,str2)print('匹配666:',obj1)pattern2="HELLO"obj2=re.match(pattern2,str2,flags=re.I)#re.I忽略大小写print('匹配HELLO:',obj2)print('调用group返回:',obj2.group())
🧨常用匹配符
| ** | 描述 |
|---|---|
| . | 匹配任意一个字符(除了\n) |
| [] | 匹配列表中的字符 |
| \w | 匹配字母、数字、下划线,即a-z,A-Z,0-9 |
| \W | 匹配不是字母、数字、下划线 |
| \s | 匹配空白字符,即空格(\n,\t) |
| \S | 匹配不是空白的字符 |
| \d | 匹配数字,即0~9 |
| \D | 匹配非数字的字符 |
① . 的用法
匹配任意一个字符(除了\n)
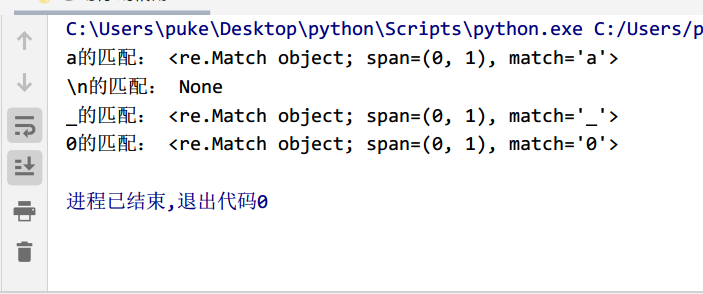
import re# 匹配任意一个字符(除了\n)str1='a'str2='\n'str3='_'str4='0'pattern='.'obj1=re.match(pattern,str1)obj2=re.match(pattern,str2)obj3=re.match(pattern,str3)obj4=re.match(pattern,str4)print('a的匹配:',obj1)print('\\n的匹配:',obj2)print('_的匹配:',obj3)print('0的匹配:',obj4)
②[]的用法
匹配列表中的字符
import restrs='h'pattern='[h]'objs=re.match(pattern,strs)print(objs)print(objs.group())

③\w和\W的用法
\w:匹配字母、数字、下划线,即a-z,A-Z,0-9
\W:与之相反
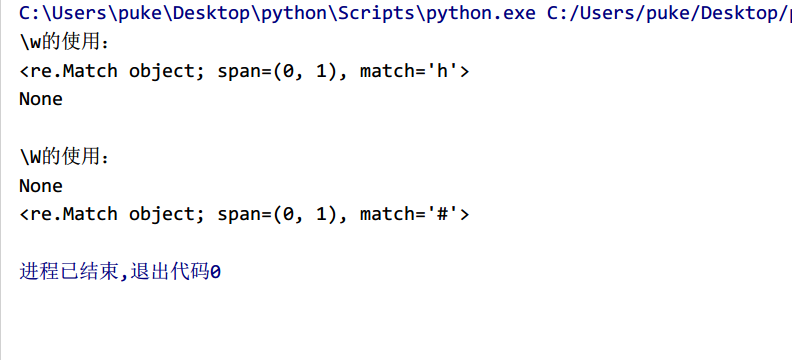
import restr1='h'str2='#'pattern1='\w'pattern2='\W'print('\w的使用:')obj1=re.match(pattern1,str1)obj2=re.match(pattern1,str2)print(obj1)print(obj2)print(' ')print('\W的使用:')obj3=re.match(pattern2,str1)obj4=re.match(pattern2,str2)print(obj3)print(obj4)
④\s和\S的使用
\s:匹配空白字符,即空格(\n,\t)
\S:与之相反
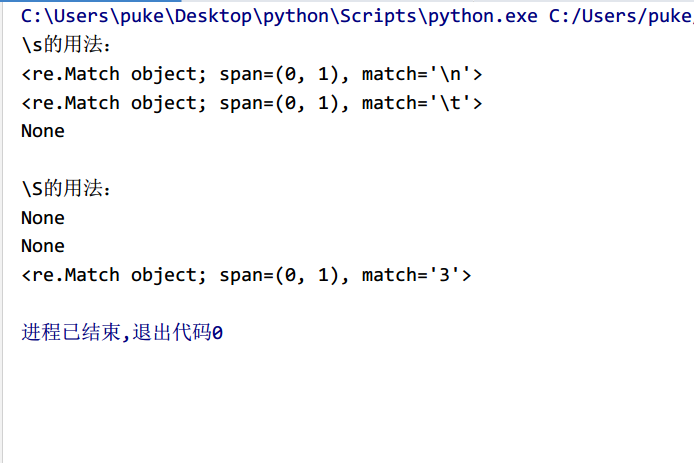
import restr1='\n'str2='\t'str3='3'pattern1='\s'pattern2='\S'obj1=re.match(pattern1,str1)obj2=re.match(pattern1,str2)obj3=re.match(pattern1,str3)print('\s的用法:')print(obj1)print(obj2)print(obj3)print(' ')obj4=re.match(pattern2,str1)obj5=re.match(pattern2,str2)obj6=re.match(pattern2,str3)print('\S的用法:')print(obj4)print(obj5)print(obj6)
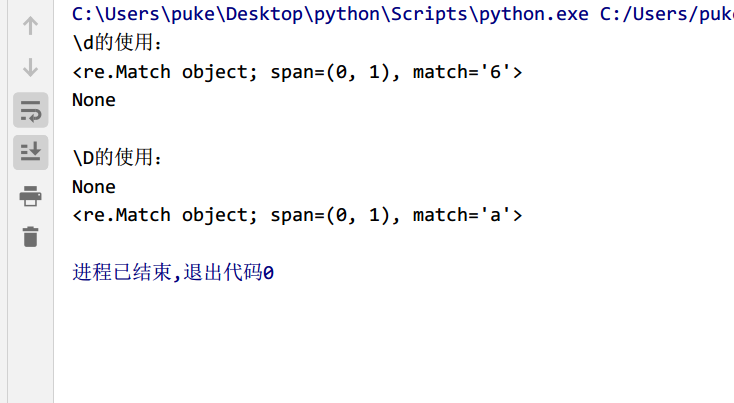
⑤\d和\D的使用
\d:匹配数字,即0~9
\D:与之相反
import re
str1='6'
str2='a'
pattern1='\d'
pattern2='\D'
obj1=re.match(pattern1,str1)
obj2=re.match(pattern1,str2)
print('\d的使用:')
print(obj1)
print(obj2)
print(' ')
obj3=re.match(pattern2,str1)
obj4=re.match(pattern2,str2)
print('\D的使用:')
print(obj3)
print(obj4)
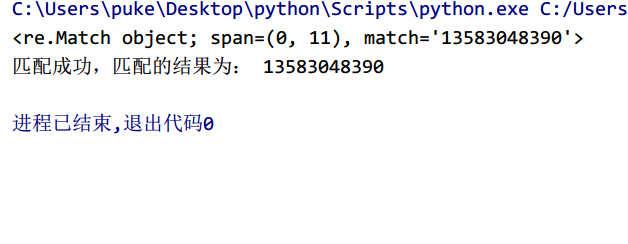
案例:
匹配一个电话号码:
import re
pattern='1[35789]\d\d\d\d\d\d\d\d\d'
p_num='13583048390'
objs=re.match(pattern,p_num)
print(objs)
print('匹配成功,匹配的结果为:',objs.group())
匹配多个字符
可以用限定符来匹配多个字符串
| 符号 | 描述 | 符号 | 描述 |
|---|---|---|---|
| * | 匹配0次或多次 | {m} | 重复m次 |
| + | 匹配1次或多次 | {m,n} | 重复m到n次,其中n可以省略,表示m到任意次 |
| ? | 匹配1次或0次 | {m,} | 至少m次 |
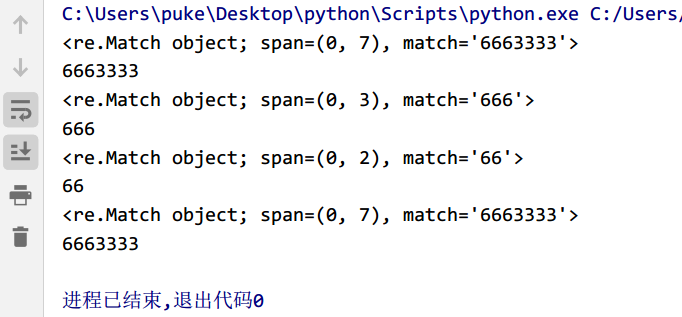
* 号的使用
匹配0次或多次,{}控制符号重复的次数
import re
strs='6663333啊'
pattern1='\d*'
pattern2='\d{3}'
pattern3='\d{1,2}'
pattern4='\d{7,}'
obj1=re.match(pattern1,strs)
obj2=re.match(pattern2,strs)
obj3=re.match(pattern3,strs)
obj4=re.match(pattern4,strs)
print(obj1)
print(obj1.group())
print(obj2)
print(obj2.group())
print(obj3)
print(obj3.group())
print(obj4)
print(obj4.group())
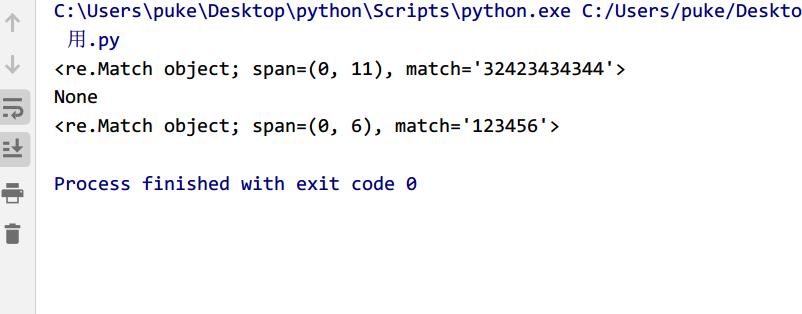
+ 号的使用
匹配1次或多次
import re
pattern="\d+"
s1="32423434344"
s2="q3242"
s3="123456"
obj1=re.match(pattern,s1)
obj2=re.match(pattern,s2)
obj3=re.match(pattern,s3)
print(obj1)
print(obj2)
print(obj3)
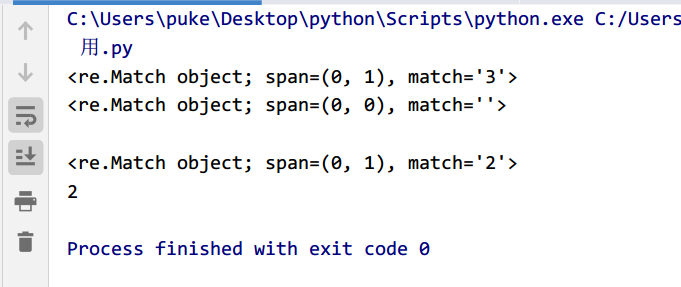
? 号的使用
匹配1次或0次
import re
pattern="\d?"
s1="32423434344"
s2="q3242"
s3="223456"
obj1=re.match(pattern,s1)
obj2=re.match(pattern,s2)
obj3=re.match(pattern,s3)
print(obj1)
print(obj2)
print(obj2.group())
print(obj3)
print(obj3.group())
import re
print("*号的使用")
pattern="\d*"
s="123sd"
o=re.match(pattern,s)
print(o)
print("------")
s="aadsd"
o=re.match(pattern,s)
print(o)
C:\User...
<re.Match object; span=(0, 3), match='123'>
------
<re.Match object; span=(0, 0), match=''>
进程已结束,退出代码0
import re
print("+号的使用")
pattern="\d+"
s="123sd"
o=re.match(pattern,s)
print(o)
print("------")
s="aadsd"
o=re.match(pattern,s)
print(o)
C:\User...
<re.Match object; span=(0, 3), match='123'>
------
None
进程已结束,退出代码0
import re
print("?号的使用")
pattern="\d?"
s="123sd"
o=re.match(pattern,s)
print(o)
print("------")
s="aadsd"
o=re.match(pattern,s)
print(o)
C:\User...
<re.Match object; span=(0, 1), match='1'>
------
<re.Match object; span=(0, 0), match=''>
进程已结束,退出代码0
🎆边界字符
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
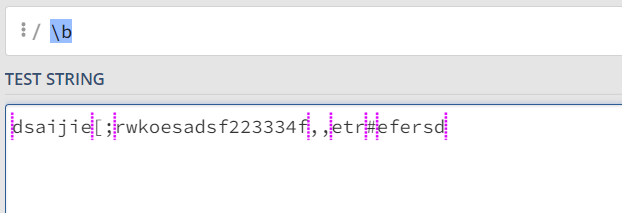
| \b | 匹配一个单词的边界 |
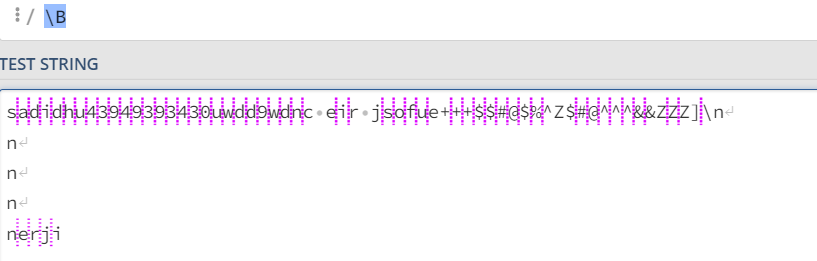
| \B | 匹配非单词的边界 |
import re
str1="2021145678@qq.com"
pattern="\d{5,11}@qq.com"
obj=re.match(pattern,str1)
print(obj)
search方法
与match类似
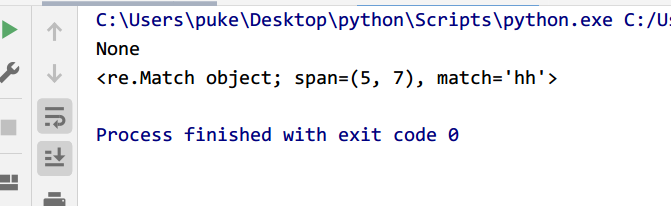
match与search的区别
re.match只匹配字符串的开始,不符合返回None;
re.search匹配整个字符串,一直找,找不到返回None
import re
str1="vvvtthh"
pattern="hh"
m = re.match(pattern,str1)
print(m)
s = re.search(pattern,str1)
print(s)
匹配多个字符串
search方法搜索一个字符串,想要搜索多个字符串,如搜索aa、bb和cc,最简单的方法是在文本模式字符串中使用择一匹配符号。择一匹配符号和逻辑符号类似,只要满足任何一个就算匹配成功
import re
pattern="aa|bb|cc"
s="aa"
o=re.match(pattern,s)
print(o)
s="bb"
o=re.search(pattern,s)
print(o)
s="my name is cc"
o=re.search(pattern,s)
# o=re.match(pattern,s)#返回None
print(o)
C:\Use...
<re.Match object; span=(0, 2), match='aa'>
<re.Match object; span=(0, 2), match='bb'>
<re.Match object; span=(11, 13), match='cc'>
进程已结束,退出代码0
pattern=r"[1-9]?\d$|100$"
s="100"
o=re.match(pattern,s)
print(o)
s="0"
o=re.match(pattern,s)
print(o)
s="43"
o=re.match(pattern,s)
print(o)
C:\Use...
<re.Match object; span=(0, 3), match='100'>
<re.Match object; span=(0, 1), match='0'>
<re.Match object; span=(0, 2), match='43'>
进程已结束,退出代码0
择一匹配符符合列表使用的差异
import re
pattern=r"[xyz]"
s="y"
o=re.match(pattern,s)
print("列表",o)
pattern=r"x|y|z"
s="y"
o=re.match(pattern,s)
print("择一匹配",o)
pattern=r"[ab][cd]"
s="ac"
o=re.match(pattern,s)
print(o)
pattern=r"ab[cd]"
s="abc"
o=re.match(pattern,s)
print(o)
pattern=r"ab|cd"
s="ab"
o=re.match(pattern,s)
print(o)
s="abc"
o=re.match(pattern,s)
print(o)
s="bc"
o=re.match(pattern,s)
print(o)
C:\Use...
列表 <re.Match object; span=(0, 1), match='y'>
择一匹配 <re.Match object; span=(0, 1), match='y'>
<re.Match object; span=(0, 2), match='ac'>
<re.Match object; span=(0, 3), match='abc'>
<re.Match object; span=(0, 2), match='ab'>
<re.Match object; span=(0, 2), match='ab'>
None
进程已结束,退出代码0
分组
如果一个模式字符串中有用一对圆括号括起来的部分,那么这部分就会作为一组,可以通过group方法的参数获取指定的组匹配的字符串。当然,如果模式字符串中没有任何用圆括号括起来的部分,那么就不会对待匹配的字符串进行分组
| 字符 | 功能 |
|---|---|
| (ab) | 将括号中的字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name) | 分别起组名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
import re
print("匹配座机号码")
pattern=r"(\d{3,4})-([1-9]\d{4,7})$"
s="011-753456"
o=re.match(pattern,s)
print(o)
print(o.group())
print(o.group(1))
print(o.group(2))
print(o.groups()[0])
print(o.groups()[1])
print(o.groups())
C:\Use...
匹配座机号码
<re.Match object; span=(0, 10), match='011-753456'>
011-753456
011
753456
011
753456
('011', '753456')
进程已结束,退出代码0
print("匹配出网页标签内数据")
import re
# pattern=r"<(.+)><(.+)>.+</\2+></\1+>"
pattern=r"<(.+)><(.+)>.+</\2+></\1+>"
s="<html><head>head部分</head></html>"
o=re.match(pattern,s)
print(o)
C:\Use...
匹配出网页标签内数据
<re.Match object; span=(0, 32), match='<html><head>head部分</head></html>'>
进程已结束,退出代码0
print("(?P<name>)分别取组名")
import re
pattern=r"<(?P<k_html>.+)><(?P<k_head>.+)>.+</(?P=k_head)+></(?P=k_html)+>"
s="<html><head>head部分</head></html>"
o=re.match(pattern,s)
print(o)
C:\Use...
(?P<name>)分别取组名
<re.Match object; span=(0, 32), match='<html><head>head部分</head></html>'>
进程已结束,退出代码0
re模块中其他常用的函数
sub和subn搜索与替换
sub函数和subn函数用于实现搜索和替换功能,这两个函数的功能几乎完全相同,都是某个字符串中所有匹配正则表达式的部分替换成其他字符串,sub函数返回替换后的结果,sub函数返回一个元组,元组的第一个元素是替换后的结果,第二个元素是替换的总数
re.sub(pattern,repl,string,count=0,flags=0)
| 参数 | 描述 |
|---|---|
| pattrtn | 匹配的正则表达式 |
| repl | 替换的字符串,也可做为一个函数 |
| string | 要被查找替换的原始字符串 |
| count | 模式匹配后替换的最大次数,默认0表示替换所有的匹配 |
import re
print("sub")
phone="2003-334-324 # 这是一个号码"
pattern=r"#.*$"
o=re.sub(pattern,"",phone)
print("sub",o)
pattern=r"#\D*"
o=re.sub(pattern,"",phone)
print("sub",o)
print("subn")
pattern=r"#.*$"
o=re.subn(pattern,"",phone)
print("subn",o)
print("subn",o[0])
print("subn",o[1])
C:\Use...
sub
sub 2003-334-324
sub 2003-334-324
subn
subn ('2003-334-324 ', 1)
subn 2003-334-324
subn 1
进程已结束,退出代码0
compile函数
compile函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match和search这两函数使用re.compile(pattern**, **flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 一个字符串形式的正则表达式 |
| flags | 可选,表示匹配模式,比如忽略大小写,多行模式等 |
print("compile")
import re
s="first123 line"
pattern=r"\w+"
regex=re.compile(pattern)
o=regex.match(s)
print(o)
C:\Use...
compile
<re.Match object; span=(0, 8), match='first123'>
进程已结束,退出代码0
findall函数与finditer函数
在字符串中找到正则表达式所有匹配的子串,并返回一个列表,如果没有找打匹配的,则返回空列表。findall(pattern**, **string**, **flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等 |
finditer和findall类似,但是返回的是一个迭代器
print("findall函数")
import re
s="first 1 second 2 third 3"
pattern="r\w+"
o=re.findall(pattern,s)
print(o)
print("finditer函数")
pattern="r\w+"
o=re.finditer(pattern,s)
print(o)
for i in o:
print(i.group(),end="")
C:\Use...
findall函数
['rst', 'rd']
finditer函数
<callable_iterator object at 0x000001C474244F10>
rstrd
进程已结束,退出代码0
split函数
split函数用于根据正则表达式分隔字符串,也就是,将字符串与模式匹配的子符串都作为分隔来分隔这个字符创。split函数返回一个列表形式的分隔结果,每一个列表元素都是分隔的子字符串。split(pattern**, **string**, **maxsplit=0**, **flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数maxsplit=1,分隔一次,默认为0,不限次数 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等 |
import re
print("split函数")
s="first 11 second 22 third 33"
pattern=r"\d+"
o=re.split(pattern,s)
print(o)
o=re.split(pattern,s,maxsplit=2)
print(o)
C:\Use...
split函数
['first ', ' second ', ' third ', '']
['first ', ' second ', ' third 33']
进程已结束,退出代码0
贪婪模式和非贪婪模式
贪婪模式是指在python中数量词是默认是贪婪的,总是尝试匹配尽可能多的字符,非贪婪则相反。
可以使用“*”,“?”,“+”,“{m,n}”后面加上?,使贪婪变成非贪婪
import re
import re
v=re.match(r"(.+)(\d+-\d+-\d+)","This is my tel:133-1234-1234")
print("贪婪模式")
print(v.group(1))
print(v.group(2))
print("非贪婪模式")
v=re.match(r"(.+?)(\d+-\d+-\d+)","This is my tel:133-1234-1234")
print(v.group(1))
print(v.group(2))
print("------------")
print("贪婪模式")
v=re.match(r"abc(\d+)","abc123")
print(v.group(1))
print("非贪婪模式")
v=re.match(r"abc(\d+?)","abc123")
print(v.group(1))
C:\Use...
贪婪模式
This is my tel:13
3-1234-1234
非贪婪模式
This is my tel:
133-1234-1234
------------
贪婪模式
123
非贪婪模式
1
进程已结束,退出代码0

若有收获,就点个赞吧
0 人点赞
