Ian J. Goodfellow ∗ , Jean Pouget-Abadie † , Mehdi Mirza, Bing Xu, David Warde-Farley,
Sherjil Ozair ‡ , Aaron Courville, Yoshua Bengio §
Département d’informatique et de recherche opérationnelle
Université de Montréal
Montréal, QC H3C 3J7
parper
https://arxiv.org/abs/1406.2661
code
https://github.com/wiseodd/generative-models/tree/master/GAN/vanilla_gan
http://www.github.com/goodfeli/adversarial
Abstract
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
我们提出了一个通过对抗过程来估计生成模型的新框架,在该框架中,我们同时训练了两个模型:一个生成模型G捕获数据分布,一个鉴别模型D估计样本来自训练数据而不是G的概率。G的训练程序是使D出错的概率最大化。 该框架对应于极小极大二人博弈。 在任意函数G和D的空间中,存在唯一的解决方案,其中G恢复训练数据分布,并且D各处都等于1/2。 在G和D由多层感知器定义的情况下,整个系统可以通过反向传播进行训练。 在训练或样本生成期间,不需要任何马尔可夫链或展开的近似推理网络。 实验通过对生成的样本进行定性和定量评估,证明了该框架的潜力。
1 Introduction
The promise of deep learning is to discover rich, hierarchical models [2] that represent probability distributions over the kinds of data encountered in artificial intelligence applications, such as natural images, audio waveforms containing speech, and symbols in natural language corpora. So far, the most striking successes in deep learning have involved discriminative models, usually those that map a high-dimensional, rich sensory input to a class label [14, 20]. These striking successes have primarily been based on the backpropagation and dropout algorithms, using piecewise linear units [17, 8, 9] which have a particularly well-behaved gradient .Deep generative models have had less of an impact, due to the difficulty of approximating many intractable probabilistic computations that arise in maximum likelihood estimation and related strategies, and due to difficulty of leveraging the benefits of piecewise linear units in the generative context. We propose a new generative model estimation procedure that sidesteps these difficulties.
深度学习的前景是发现丰富的层次模型[2],这些模型表示人工智能应用中遇到的各种数据的概率分布,例如自然图像、包含语音的音频波形和自然语言语料库中的符号。到目前为止,在深度学习中最引人注目的成功涉及到辨别模型,通常是那些将高维、丰富的感官输入映射到类别标签的模型[14,20]。这些惊人的成功主要是基于反向传播和退出算法,使用分段线性单元[17,8,9],具有特别好的梯度。深层生成模型的影响较小,由于在最大似然估计和相关策略中难以近似许多难以处理的概率计算,以及在生成环境中难以利用分段线性单元的优点。我们提出了一种新的生成模型估计方法来回避这些困难。
In the proposed adversarial nets framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution. The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency. Competition in this game drives both teams to improve their methods until the counterfeits are indistiguishable from the genuine articles.
在提出的对抗网络框架中,生成模型与竞争对手进行较量:这是一种判别模型,可以学习确定样本是来自模型分布还是数据分布。生成模型可以被认为类似于一组伪造者,试图制造假币并在不被发现的情况下使用它,而区别模型类似于警察,试图发现假币。在这个游戏中的竞争促使双方团队改进他们的方法,直到假冒的物品无法区分真品。
This framework can yield specific training algorithms for many kinds of model and optimization algorithm. In this article, we explore the special case when the generative model generates samples by passing random noise through a multilayer perceptron, and the discriminative model is also a multilayer perceptron. We refer to this special case as adversarial nets. In this case, we can train both models using only the highly successful backpropagation and dropout algorithms [16] and sample from the generative model using only forward propagation. No approximate inference or Markov chains are necessary.
该框架可以为多种模型和优化算法生成特定的训练算法。本文研究了产生式模型通过多层感知器传递随机噪声产生样本的特殊情况,判别式模型也是多层感知器。我们把这种特殊情况称为对抗网。在这种情况下,我们可以只使用非常成功的反向传播(back propagation )和dropout算法来训练这两个模型[16],并且只使用正向传播从生成模型中采样。不需要近似推理或马尔可夫链。
2 Related work
Until recently, most work on deep generative models focused on models that provided a parametric specification of a probability distribution function. The model can then be trained by maximizing the log likelihood. In this family of model, perhaps the most succesful is the deep Boltzmann machine [25]. Such models generally have intractable likelihood functions and therefore require numerous approximations to the likelihood gradient. These difficulties motivated the development of “generative machines”–models that do not explicitly represent the likelihood, yet are able to generate samples from the desired distribution. Generative stochastic networks [4] are an example of a generative machine that can be trained with exact backpropagation rather than the numerous approximations required for Boltzmann machines. This work extends the idea of a generative machine by eliminating the Markov chains used in generative stochastic networks.
直到最近,大多数关于深度生成模型的工作都集中在为概率分布函数提供参数说明的模型上。然后可以通过最大化对数似然来训练模型。在这个系列的模型中,也许最成功的是深玻尔兹曼机器(deep Boltzmann machine )[25]。这类模型通常具有难以处理的似然函数,因此需要对似然梯度进行无数次近似。这些困难促使了“生成机器”的发展——这种模型不能明确地代表可能性,但能够从期望的分布中生成样本。生成随机网络[4]是生成机器的一个例子,它可以用精确的反向传播训练,而不是玻尔兹曼机器所需的大量近似。他的工作通过消除生成随机网络中使用的马尔可夫链扩展了生成机器的思想。
Our work backpropagates derivatives through generative processes by using the observation that
我们的工作通过生成过程反向传播导数,通过使用观察
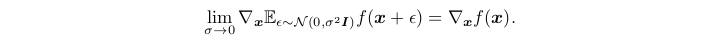
We were unaware at the time we developed this work that Kingma and Welling [18] and Rezende et al. [23] had developed more general stochastic backpropagation rules, allowing one to backpropagate through Gaussian distributions with finite variance, and to backpropagate to the covariance parameter as well as the mean. These backpropagation rules could allow one to learn the conditional variance of the generator, which we treated as a hyperparameter in this work. Kingma and Welling [18] and Rezende et al. [23] use stochastic backpropagation to train variational autoen-coders (VAEs). Like generative adversarial networks, variational autoencoders pair a differentiable generator network with a second neural network. Unlike generative adversarial networks, the second network in a VAE is a recognition model that performs approximate inference.GANs require differentiation through the visible units, and thus cannot model discrete data, while VAEs require differentiation through the hidden units, and thus cannot have discrete latent variables. Other VAE-like approaches exist [12, 22] but are less closely related to our method.<br />在我们开展这项工作时,我们还没有意识到Kingma和Welling [18]以及Rezende等人的工作。 [23]开发了更通用的随机反向传播规则,允许人们通过具有有限方差的高斯分布进行反向传播,并反向传播至协方差参数和均值。 这些反向传播规则可以使人们了解发生器的条件方差,在这项工作中我们将其视为超参数。 Kingma和Welling [18]和Rezende等。 [23]使用随机反向传播来训练变分自动编码器(VAE)。 像生成对抗网络一样,变分自编码器将可微分的生成器网络与第二个神经网络配对。 与生成对抗网络不同,VAE中的第二个网络是执行近似推理的识别模型.GAN需要通过可见单位进行区分,因此无法对离散数据进行建模,而VAE需要通过隐藏单位进行区分,因此不能具有离散潜在变量。 还存在其他类似VAE的方法[12,22],但与我们的方法关系不大。
Previous work has also taken the approach of using a discriminative criterion to train a generative model [29, 13]. These approaches use criteria that are intractable for deep generative models. These methods are difficult even to approximate for deep models because they involve ratios of probabili ties which cannot be approximated using variational approximations that lower bound the probability. Noise-contrastive estimation (NCE) [13] involves training a generative model by learning the weights that make the model useful for discriminating data from a fixed noise distribution. Using a previously trained model as the noise distribution allows training a sequence of models of increasing quality. This can be seen as an informal competition mechanism similar in spirit to the formal competition used in the adversarial networks game. The key limitation of NCE is that its “discriminator” is defined by the ratio of the probability densities of the noise distribution and the model distribution, and thus requires the ability to evaluate and backpropagate through both densities.
之前的研究也采用了使用判别准则训练生成模型的方法[29,13]。这些方法使用的标准对于深层生成模型来说是难以处理的。对于深度模型,这些方法甚至很难近似,因为它们涉及的概率比率无法用降低概率边界的变分近似来近似。噪声对比估计(NCE)[13]涉及到通过学习权值来训练生成模型,这些权值使模型有助于从固定的噪声分布中识别数据。使用先前训练过的模型作为噪声分布,可以训练一系列质量越来越高的模型。这可以看作是一种非正式的竞争机制,在精神上类似于对抗式网络游戏中使用的正式竞争。NCE的主要局限性是它的“鉴别器”是由噪声分布的概率密度与模型分布的概率密度之比来定义的,因此需要通过这两种密度来评估和反向传播的能力。
Some previous work has used the general concept of having two neural networks compete. The most
relevant work is predictability minimization [26]. In predictability minimization, each hidden unit in a neural network is trained to be different from the output of a second network, which predicts the value of that hidden unit given the value of all of the other hidden units. This work differs from predictability minimization in three important ways: 1) in this work, the competition between the networks is the sole training criterion, and is sufficient on its own to train the network. Predictability minimization is only a regularizer that encourages the hidden units of a neural network to be statistically independent while they accomplish some other task; it is not a primary training criterion.2) The nature of the competition is different. In predictability minimization, two networks’ outputs are compared, with one network trying to make the outputs similar and the other trying to make the outputs different. The output in question is a single scalar. In GANs, one network produces a rich,high dimensional vector that is used as the input to another network, and attempts to choose an input that the other network does not know how to process. 3) The specification of the learning process is different.
一些以前的工作使用了使两个神经网络竞争的一般概念。 最多相关工作是将可预测性最小化[26]。 在最小化可预测性方面,将神经网络中的每个隐藏单元训练为与第二个网络的输出不同,第二个网络的输出会在给定所有其他隐藏单元的值的情况下预测该隐藏单元的值。 这项工作在三个重要方面与可预测性最小化不同:1)在这项工作中,网络之间的竞争是唯一的训练标准,并且足以单独训练网络。 可预测性最小化只是一个正则化器,它鼓励神经网络的隐藏单元在完成其他任务时在统计上独立。 2)比赛的性质不同。 为了使可预测性最小化,比较了两个网络的输出,其中一个网络试图使输出相似,而另一个网络试图使输出不同。 有问题的输出是单个标量。 在GAN中,一个网络会生成一个丰富的高维向量,该向量将用作另一个网络的输入,并尝试选择另一个网络不知道如何处理的输入。 3)学习过程的规范不同。
Predictability minimization is described as an optimization problem with an objective function to be minimized, and learning approaches the minimum of the objective function. GANs are based on a minimax game rather than an optimization problem, and have a value function that one agent seeks to maximize and the other seeks to minimize. The game terminates at a saddle point that is a minimum with respect to one player’s strategy and a maximum with respect to the other player’s strategy.
可预测性最小化被描述为具有最小化目标函数的优化问题,学习接近目标函数的最小值。 GAN基于最小极大博弈而不是优化问题,并且具有一种价值函数,一个代理人试图最大化该价值,而另一个代理人试图最小化。 游戏终止于一个鞍点,该鞍点对于一个玩家的策略而言是最小值,而对于另一位玩家的策略而言则是最大值。
Generative adversarial networks has been sometimes confused with the related concept of “adversarial examples” [28]. Adversarial examples are examples found by using gradient-based optimization directly on the input to a classification network, in order to find examples that are similar to the data yet misclassified. This is different from the present work because adversarial examples are not a mechanism for training a generative model. Instead, adversarial examples are primarily an analysis tool for showing that neural networks behave in intriguing ways, often confidently classifying two images differently with high confidence even though the difference between them is imperceptible to a human observer. The existence of such adversarial examples does suggest that generative adversarial network training could be inefficient, because they show that it is possible to make modern discriminative networks confidently recognize a class without emulating any of the human-perceptible attributes of that class.
生成对抗网络有时与“对抗示例”的相关概念相混淆[28]。 对抗性示例是通过直接在分类网络的输入上使用基于梯度的优化找到的示例,以便查找与尚未分类的数据相似的示例。 这与当前的工作不同,因为对抗性示例不是训练生成模型的机制。 取而代之的是,对抗性示例主要是一种分析工具,用于显示神经网络以有趣的方式工作,通常以高置信度自信地对两个图像进行分类,即使人类观察者无法察觉它们之间的差异。 此类对抗性示例的存在确实表明,生成式对抗性网络训练可能是低效的,因为它们表明,有可能使现代的歧视性网络自信地识别某个类别,而无需模仿该类别的任何人类可感知的属性。
3 Adversarial nets
The adversarial modeling framework is most straightforward to apply when the models are both multilayer perceptrons. To learn the generator’s distribution p g over data x, we define a prior on input noise variables p z (z), then represent a mapping to data space as G(z; θ g ), where G is a differentiable function represented by a multilayer perceptron with parameters θ g . We also define a second multilayer perceptron D(x; θ d ) that outputs a single scalar. D(x) represents the probabilitythat x came from the data rather than p g . We train D to maximize the probability of assigning the correct label to both training examples and samples from G. We simultaneously train G to minimize log(1 − D(G(z))). In other words, D and G play the following two-player minimax game with value function V (G, D):
当模型都是多层感知器时,对抗性建模框架最容易应用。为了了解数据x上的生成器的分布p g,我们定义了输入噪声变量pz (z)的先验,然后表示到数据空间的映射为g (z;θ g),其中g是一个可微函数,由参数θ g的多层感知器表示。我们还定义了第二个多层感知器D(x;输出单个标量的θ d)。D(x)表示x来自数据而不是p g的概率。我们训练D以最大化分配正确标签给训练示例和G中的样本的概率。我们同时训练G以最小化log(1−D(G(z)))。也就是说,D和G进行如下值函数V (G, D)的二人极大极小博弈:
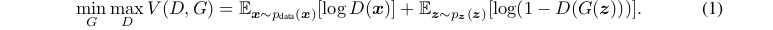
In the next section, we present a theoretical analysis of adversarial nets, essentially showing that the training criterion allows one to recover the data generating distribution as G and D are given enough capacity, i.e., in the non-parametric limit. See Figure 1 for a less formal, more pedagogical explanation of the approach. In practice, we must implement the game using an iterative, numerical approach. Optimizing D to completion in the inner loop of training is computationally prohibitive, and on finite datasets would result in overfitting. Instead, we alternate between k steps of optimizing D and one step of optimizing G. This results in D being maintained near its optimal solution, so long as G changes slowly enough. The procedure is formally presented in Algorithm 1.
在下一节中,我们将对对抗网进行理论分析,从本质上表明,当G和D被给予足够的容量时,即在非参数极限下,训练准则允许人们恢复数据生成分布。图1给出了一种不太正式、更具有教学意义的方法解释。在实践中,我们必须使用迭代的数值方法来执行游戏。在训练的内环中进行优化到完成在计算上是禁止的,并且在有限的数据集上会导致过拟合。。相反,我们在优化D的k步和优化G的一步之间交替进行。这样一来,只要G的变化足够缓慢,D就会保持在其最优解附近。该过程在算法1中正式给出。
In practice, equation 1 may not provide sufficient gradient for G to learn well. Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data. In this case, log(1 − D(G(z))) saturates. Rather than training G to minimize log(1 − D(G(z))) we can train G to maximize log D(G(z)). This objective function results in the same fixed point of the dynamics of G and D but provides much stronger gradients early in learning.
在实践中,方程1可能不能提供足够的梯度让G学习得很好。在学习的早期,当G较差时,D可以拒绝高置信度的样本,因为它们与训练数据明显不同。在这种情况下,log(1−D(G(z)))饱和。与其让G最小化log(1−D(G(z)),不如让G最大化log D(G(z))。这个目标函数的结果与G和D的动态不动点相同,但在学习早期提供了更强的梯度。
4 Theoretical Results
The generator G implicitly defines a probability distribution p g as the distribution of the samples G(z) obtained when z ∼ p z . Therefore, we would like Algorithm 1 to converge to a good estimator of p data , if given enough capacity and training time. The results of this section are done in a nonparametric setting, e.g. we represent a model with infinite capacity by studying convergence in the space of probability density functions. We will show in section 4.1 that this minimax game has a global optimum for p g = p data .
We will then show in section 4.2 that Algorithm 1 optimizes Eq 1, thus obtaining the desired result.
生成器G隐式地定义了概率分布p G作为样本G(z)的分布,当z∼pz时获得。因此,如果有足够的容量和训练时间,我们希望算法1收敛到p数据的一个好的估计量。本节的结果是在非参数设置下完成的,例如,我们通过研究概率密度函数空间的收敛性来表示一个具有无限容量的模型。我们将在4.1节中说明,对于p g = p data,这个极大极小对策具有全局最优。
我们将在4.2节中说明算法1优化了Eq 1,从而获得了想要的结果。

4.1 Global Optimality of p g = p data
We first consider the optimal discriminator D for any given generator G. Proposition 1. For G fixed, the optimal discriminator D i
4.2 Convergence of Algorithm 1

5 Experiments
We trained adversarial nets an a range of datasets including MNIST[21], the Toronto Face Database (TFD) [27], and CIFAR-10 [19]. The generator nets used a mixture of rectifier linear activations [17,8] and sigmoid activations, while the discriminator net used maxout [9] activations. Dropout [16] was applied in training the discriminator net. While our theoretical framework permits the use of dropout and other noise at intermediate layers of the generator, we used noise as the input to only the bottommost layer of the generator network.
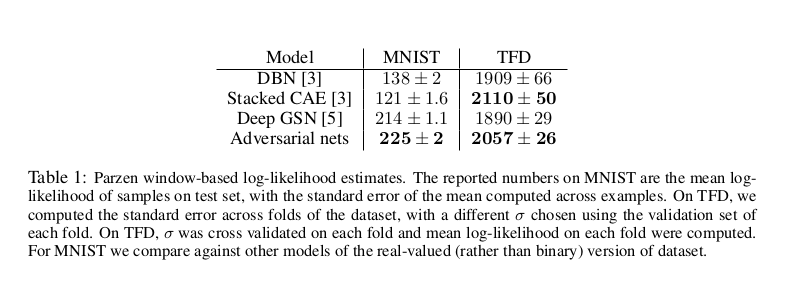
We estimate probability of the test set data under p g by fitting a Gaussian Parzen window to the samples generated with G and reporting the log-likelihood under this distribution. The σ parameter of the Gaussians was obtained by cross validation on the validation set. This procedure was introduced in Breuleux et al. [7] and used for various generative models for which the exact likelihood is not tractable [24, 3, 4]. Results are reported in Table 1. This method of estimating the likelihood has somewhat high variance and does not perform well in high dimensional spaces but it is the best method available to our knowledge. Advances in generative models that can sample but not estimate likelihood directly motivate further research into how to evaluate such models. In Figures 2 and 3 we show samples drawn from the generator net after training. While we make no claim that these samples are better than samples generated by existing methods, we believe that these samples are at least competitive with the better generative models in the literature and highlight the potential of the adversarial framework.
我们训练了一系列的数据集,包括MNIST[21]、Toronto Face Database (TFD)[27]和CIFAR-10[19]。发电机网使用整流线性激活[17,8]和sigmoid激活的混合,而鉴别器网使用maxout[9]激活。将Dropout[16]应用于判别器网络的训练。虽然我们的理论框架允许在发电机的中间层使用dropout和其他噪声,但我们只使用噪声作为发电机网络最底层的输入。
我们通过对由g生成的样本拟合一个高斯Parzen窗口来估计在p g下测试集数据的概率,并报告在该分布下的对数似然。高斯模型的σ参数是通过验证集上的交叉验证获得的。这个过程在Breuleux等人的[7]中被引入,用于各种精确似然难以处理的生成模型[24,3,4]。结果见表1。这种估计似然性的方法有较高的方差,在高维空间中表现不佳,但它是我们所知的最好的方法。生成模型可以抽样但不能估计可能性的发展直接激发了对如何评价这类模型的进一步研究。在图2和图3中,我们展示了训练后从生成器网络中抽取的样本。虽然我们不认为这些样本比现有方法生成的样本更好,但我们相信这些样本至少与文献中更好的生成模型竞争,并突出了对抗框架的潜力。
6 Advantages and disadvantages
This new framework comes with advantages and disadvantages relative to previous modeling frameworks. The disadvantages are primarily that there is no explicit representation of p g (x), and that D must be synchronized well with G during training (in particular, G must not be trained too much without updating D, in order to avoid “the Helvetica scenario” in which G collapses too many values of z to the same value of x to have enough diversity to model p data ), much as the negative chains of a Boltzmann machine must be kept up to date between learning steps. The advantages are that Markov chains are never needed, only backprop is used to obtain gradients, no inference is needed during learning, and a wide variety of functions can be incorporated into the model. Table 2 summarizes the comparison of generative adversarial nets with other generative modeling approaches.
与以前的建模框架相比,这个新框架既有优点也有缺点。缺点主要是没有明确表示g p (x)和D必须同步与g在训练(特别是g不能训练太多没有更新,为了避免“Helvetica场景”中g崩溃太多的z值相同的值(x)有足够的多样性模型数据页),负链的玻耳兹曼机之间必须保持最新的学习步骤。其优点是不需要马尔可夫链,只使用backprop来获得梯度,学习时不需要推理,模型中可以包含多种函数。表2总结了生成式对抗网与其他生成式建模方法的比较。
The aforementioned advantages are primarily computational. Adversarial models may also gain some statistical advantage from the generator network not being updated directly with data examples, but only with gradients flowing through the discriminator. This means that components of the input are not copied directly into the generator’s parameters. Another advantage of adversarial networks is that they can represent very sharp, even degenerate distributions, while methods based on Markov chains require that the distribution be somewhat blurry in order for the chains to be able to mix between modes.
上述优点主要是计算性的。对抗模型也可以获得一些统计上的优势,因为生成网络不直接用数据实例更新,而只通过通过鉴别器的梯度。这意味着输入的组件不会直接复制到生成器的参数中。对抗型网络的另一个优点是,它们可以代表非常尖锐,甚至是退化的分布,而基于马尔可夫链的方法要求分布有些模糊,以便链能够在模式之间混合。
7 Conclusions and future work
This framework admits many straightforward extensions:
- A conditional generative model p(x | c) can be obtained by adding c as input to both G and D.
2. Learned approximate inference can be performed by training an auxiliary network to predict z given x. This is similar to the inference net trained by the wake-sleep algorithm [15] but with the advantage that the inference net may be trained for a fixed generator net after the generator net has finished training.
3. One can approximately model all conditionals p(x S | x 6 S ) where S is a subset of the indices of x by training a family of conditional models that share parameters. Essentially, one can use adversarial nets to implement a stochastic extension of the deterministic MP-DBM [10].
4. Semi-supervised learning: features from the discriminator or inference net could improve performance of classifiers when limited labeled data is available.
5. Efficiency improvements: training could be accelerated greatly by devising better methods for coordinating G and D or determining better distributions to sample z from during training.
1.将c作为G和D的输入,可以得到条件生成模型p(x | c)。
2.学习近似推理可以由培训辅助网络预测z给x。这类似于和生物钟的推理网络训练算法[15]但推理网络的优势可能被训练为一个固定的发电机净后发电机完成培训。
3.通过训练一系列共享参数的条件模型,我们可以近似地为所有条件p(x S | x 6 S)建模,其中S是x指标的子集。本质上,我们可以使用对抗网来实现确定性MP-DBM[10]的随机扩展。
4.半监督学习:当有有限的标记数据可用时,来自识别器或推理网的特征可以提高分类器的性能。
5.效率提高:通过设计更好的方法来协调G和D,或者在训练过程中确定更好的分布来采样z,可以大大加快训练的速度。
This paper has demonstrated the viability of the adversarial modeling framework, suggesting that
these research directions could prove useful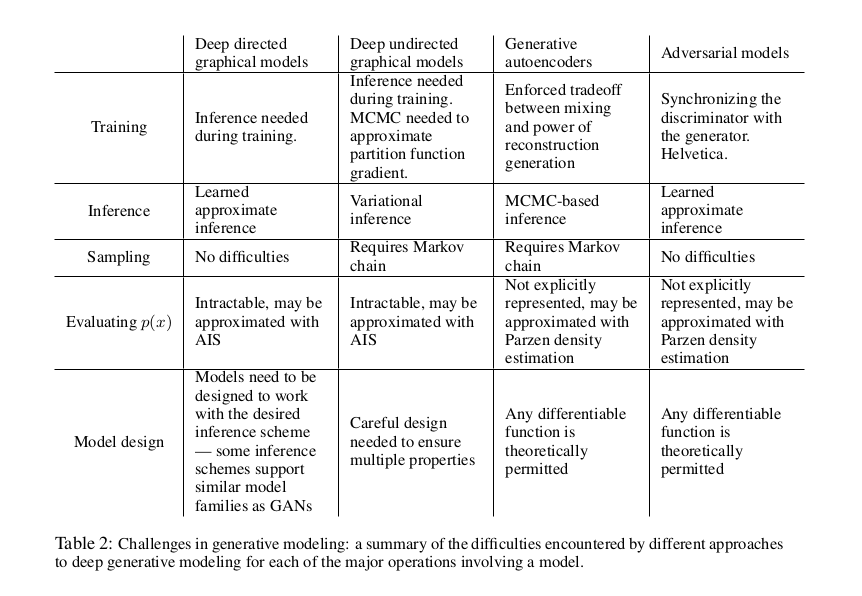
Acknowledgments
We would like to acknowledge Patrice Marcotte, Olivier Delalleau, Kyunghyun Cho, Guillaume Alain and Jason Yosinski for helpful discussions. Yann Dauphin shared his Parzen window evaluation code with us. We would like to thank the developers of Pylearn2 [11] and Theano [6, 1], particularly Frédéric Bastien who rushed a Theano feature specifically to benefit this project. Arnaud Bergeron provided much-needed support with L A TEX typesetting. We would also like to thank CIFAR, and Canada Research Chairs for funding, and Compute Canada, and Calcul Québec for providing computational resources. Ian Goodfellow is supported by the 2013 Google Fellowship in Deep Learning. Finally, we would like to thank Les Trois Brasseurs for stimulating our creativity.<br /><br />

若有收获,就点个赞吧
0 人点赞
