SQL慢的几个主要原因:
- 查询语句写的烂
- 索引失效
- 关联查询太多join(设计缺陷或不得已的需求)
- 服务器调优及各个参数设置(缓冲、线程数等)
SQL执行顺序:
-- inputselect distinct <cols>from table_mainleft join table_left on <join_condition>where <where_condition>group by <group_by_col>having <having_condition>order by <order_col>limit <x>-- 实际执行顺序1 连接表 from <table_left>2 连接条件 on <join_condition>3 join操作+主表 left join table_left4 where5 group by6 having7 select8 distinct <cols>9 order by <order_col>10 limit <x>
索引的概念
索引=排序+查找
MYSQL中索引发挥作用的方式(举例一种可能的方式):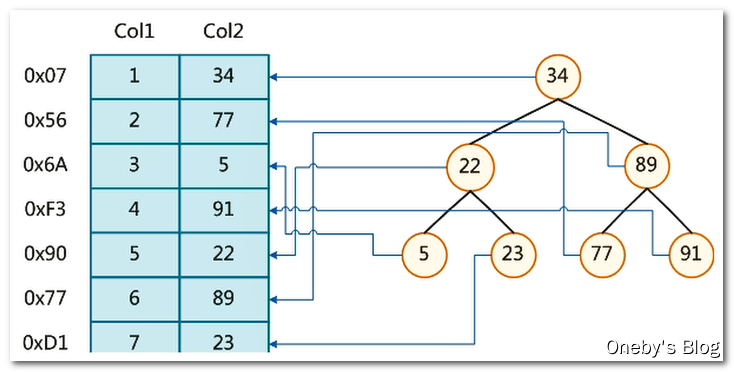
- 左边是数据表,一共有两列七条记录,最左边的十六进制数字是数据记录的物理地址
- 为了加快col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
索引结构
BTREE 索引
- 一颗 b 树, 浅蓝色的块我们称之为一个磁盘块, 可以看到每个磁盘块包含几个数据项(深蓝色所示) 和指针(黄色所示)
- 如磁盘块 1 包含数据项 17 和 35, 包含指针 P1、 P2、 P3
- P1 表示小于 17 的磁盘块, P2 表示在 17 和 35 之间的磁盘块, P3 表示大于 35 的磁盘块
- 真实的数据存在于叶子节点和非叶子节点中

- 如果要查找数据项 29, 那么首先会把磁盘块 1 由磁盘加载到内存, 此时发生一次 IO, 在内存中用二分查找确定 29在 17 和 35 之间, 锁定磁盘块 1 的 P2 指针, 内存时间因为非常短(相比磁盘的 IO) 可以忽略不计
- 通过磁盘块 1的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存, 发生第二次 IO, 29 在 26 和 30 之间, 锁定磁盘块 3 的 P2 指针
- 通过指针加载磁盘块 8 到内存, 发生第三次 IO, 同时内存中做二分查找找到 29, 结束查询, 总计三次 IO。
B+TREE 索引

【B+Tree 与 BTree 的区别】
- B-树的关键字(数据项)和记录是放在一起的;
- B+树的非叶子节点中只有关键字和指向下一个节点的索引, 记录只放在叶子节点中。
【B+Tree 与 BTree 的查找过程】
- 在 B 树中, 越靠近根节点的记录查找时间越快, 只要找到关键字即可确定记录的存在; 而 B+ 树中每个记录的查找时间基本是一样的, 都需要从根节点走到叶子节点, 而且在叶子节点中还要再比较关键字。
- 从这个角度看 B 树的性能好像要比 B+ 树好, 而在实际应用中却是 B+ 树的性能要好些。 因为 B+ 树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比 B 树多, 树高比 B 树小, 这样带来的好处是减少磁盘访问次数。
- 尽管 B+ 树找到一个记录所需的比较次数要比 B 树多, 但是一次磁盘访问的时间相当于成百上千次内存比较的时间, 因此实际中B+ 树的性能可能还会好些, 而且 B+树的叶子节点使用指针连接在一起, 方便顺序遍历(范围搜索), 这也是很多数据库和文件系统使用 B+树的缘故。
【性能提升】
- B+TREE只需要3层,即仅需3次IO
- 相比BTREE,B+数的IO代价更低
- B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点, 而只是叶子结点中关键字的索引。 所以任何关键字的查找必须走一条从根结点到叶子结点的路。 所有关键字查询的路径长度相同, 导致每一个数据的查询效率相当。
性能分析
Explain,详细可见:https://blog.csdn.net/oneby1314/article/details/107938325
索引失效情况
- 全值匹配我最爱
最佳左前缀法则:如果索引了多例,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
-- staffs 表中的复合索引:name、age、pos-- 在where的时候要顺序使用,不能跳过WHERE name = 'July'AND age = 23 AND pos = 'dev';-- 缺一不可!
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
-- 索引:nameWHERE LEFT(name,4) = 'July';
存储引擎不能使用索引中范围条件右边的列
SELECT * FROM staffs WHERE name = 'July'AND age > 23 AND pos = 'dev';-- pos失效
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
- 在使用 != ,<> 的时候,索引失效
- is null,is not null 也无法使用索引(早期版本不能走索引,后续版本应该优化过,可以走索引)
- like以通配符开头(eg: %abc…)mysql索引失效会变成全表扫描操作
字符串不加单引号索引失效
explain select * from staffs where name=2000;-- name为string,隐式的类型转换会使索引失效
少用or,用它连接时会索引失效


若有收获,就点个赞吧
0 人点赞
