Unable to load native-hadoop library for your platform解决方法
在执行hadoop命令的时候出现如下错误,不能加载Hadoop库
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
1
检查发现本地并没有库
[hadoop001@192 ~]$ hadoop checknative -a
18/12/30 03:46:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
snappy: false
lz4: false
bzip2: false
openssl: false
18/12/30 03:46:50 INFO util.ExitUtil: Exiting with status 1
进入Hadoop下的\lib\native发现是空文件夹
http://dl.bintray.com/sequenceiq/sequenceiq-bin/
下载对应版本的native库
解压至\lib\native下
重新启动dfs,解决了
问题二:运行start-dfs.sh时出现下面日志
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
在网上找到的全部文章中,都是说在hadoop-env.sh中增加下面两行配置:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS=”-Djava.library.path=${HADOOP_HOME}/lib/“
可是在測试过程中,增加以上配置还是会提示告警信息,说明本地库未载入成功。
开启debug:
export HADOOP_ROOT_LOGGER=DEBUG,console
运行start-dfs.sh,发现下面日志:
DEBUG util.NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
从日志中能够看出hadoop库不在java.library.path所配置的文件夹下,应该是java.library.path配置的路径有问题。在hadoop-env.sh中又一次配置:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS=”-Djava.library.path=${HADOOP_HOME}/lib/native/“
运行start-dfs.sh,告警信息不再显示。经測试。事实上仅仅需export HADOOP_OPTS就可以解决这个问题
Pyspark
1、Exception: Java gateway process exited before sending its port number
Java not found and JAVA_HOME environment variable is not set.
Install Java and set JAVA_HOME to point to the Java installation directory.
os.environ[‘JAVA_HOME’] = ‘C:\Program Files\Java\jre1.8.0_321’ # 这里的路径为java的bin目录所在路径
2、Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
下载hadoop-common-2.2.0-bin-master.zip
下载地址为:https://[github](https://so.csdn.net/so/search?q=github&spm=1001.2101.3001.7020).com/srccodes/hadoop-common-2.2.0-bin
也可以在国内进行下载
将下载里面的
将bin目录里面的hadoop.dll和winutils.ext这两个文件放到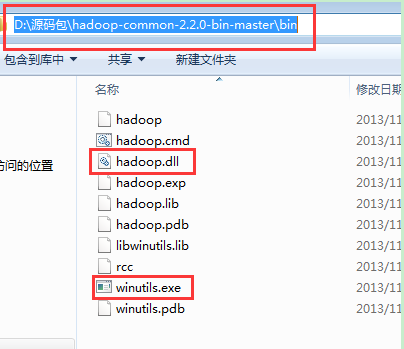

Hadoop的安装目录,也就是解压目录下面的bin里面。防止发生一些因为这2个文件没有而导致的错误。
修改主服务器上面的配置文件mapred-site.xml
添加上面那个是为了权限问题,不然会出现
(25 ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator)
hadoop eclipse插件不是必须的,其作用如下三点
对hadoop中的文件可视化。
创建MapReduce Project时帮你引入依赖的jar。
Configuration conf = new Configuration();时就已经包含了所有的配置信息。
虽然是搭建好了这个环境,但是只能在本地运行mapreduce,如果想要在集群运行的话,需要麻烦些,涉及重新编译hadoop以及修改配置文件。
在eclipse的hadoop2.2.0搭建的过程中
已经下载导入好了这个插件,hdfs上面的目录结构也显示了,但是运行mapreduce程序始终有个空指针异常
并且没有任何的提示,看到错误信息里面提到有个log4j的警告,需要导入log4j的配置文件
我win上面的hadoop2.2.0的目录,也就是hadoop2.2.0解压后的文件目录
将上面红框的文件,放到我自己创建的测试项目的bin目录下
这样就好分析错误的信息了,如果有时候发现没有信息输出,看看是不是没有把log4j的配置文件加载到目录当中
2:java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
说是 HADOOP_HOME的问题。如果HADOOP_HOME为空,必然fullExeName为null\bin\winutils.exe。解决方法比较简单,就是配置hadoop home的环境变量吧,不想重启电脑可以在MapReduce程序里加上 System.setProperty(“hadoop.home.dir”, “…”)
这里配置hadoop-home并重启电脑
(点击新建,输入hadoop的安装目录)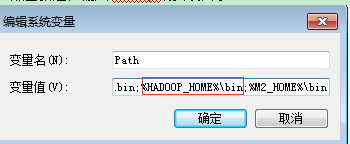
(并将hadoop安装目录下的bin目录添加到Path当中)
3:如果有Could not locate executable D:\Hadoop\tar\hadoop-2.2.0\hadoop-2.2.0\bin\winutils.exe in the Hadoop binaries.
这个是没有winutils.exe这个东西。去https://github.com/srccodes/hadoop-common-2.2.0-bin下载一个,放就去就可以了,
[

若有收获,就点个赞吧
0 人点赞
