k-nearest neighbor?
感性认知knn
 算法的思想是 “物以类聚,人以群分”
算法的思想是 “物以类聚,人以群分”
比如,观察下面这张图,试着判断一下外星人形状的东西属于哪一类?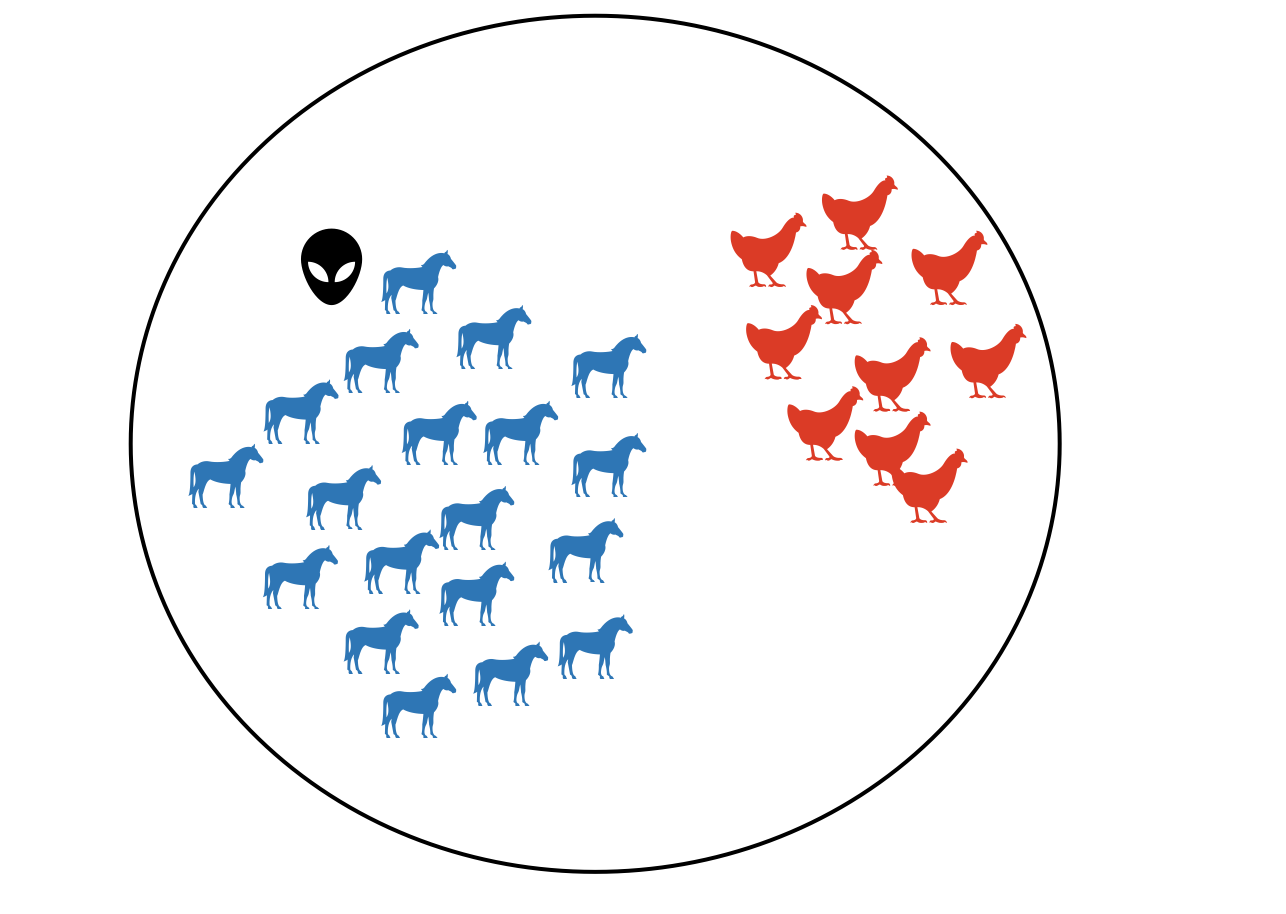
很显然,我们应该将它归于马一类
理性认知knn
k近邻模型
算法需要确定以下4个指标
- 训练集
- 距离度量
 的取值
的取值- 分类决策标准
训练集
距离度量
- 特征空间中两个实例点的距离是两个点相似程度的反映
定义
 距离,
距离,
若
值较小,可以理解为用较小的一片区域的训练实例来进行预测,但这样会导致预测结果对近邻的实例点非常敏感,如若邻近的点恰好是噪声,预测就会出错- 优点:“学习”的近似误差会减小
- 缺点:“学习”的估计误差会增大,容易过拟合
- 若 值较大,可以理解为用较大的一片区域的训练实例来进行预测,这就意味值与输入实例较远的训练实例也会对预测起作用,从而使得预测出错
- 优点:“学习”的估计误差会减小
- 缺点:“学习”的近似误差会增大
 称作曼哈顿距离
称作曼哈顿距离  ,
, 
 称作欧氏距离
称作欧氏距离  ,
, 
 代表了各个坐标的最大值
代表了各个坐标的最大值 
用下面这幅图来说明 值的重要性,图中的灰色点到底是属于红色还是绿色?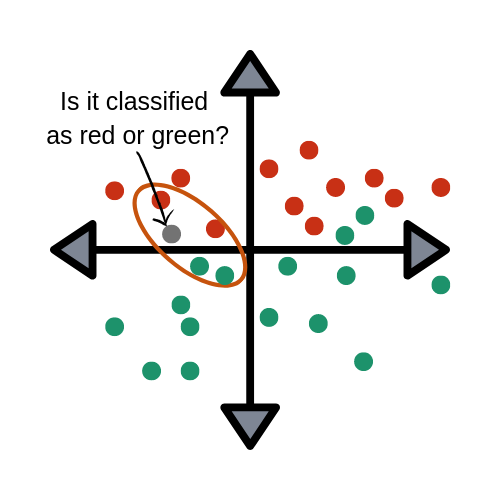
要想知道灰色点属于哪一类,这取决于 的取值
值一般取一个比较小的数值,例如采用交叉验证法来选择最优的  值
值
分类决策标准
- 在
 中的分类决策规则往往都是多数表决,即由输入实例的个邻近的训练实例中多数类决定输入实例的类
中的分类决策规则往往都是多数表决,即由输入实例的个邻近的训练实例中多数类决定输入实例的类
比如,当 值确定后,就可以通过距离度量来计算灰色点归属于哪一类
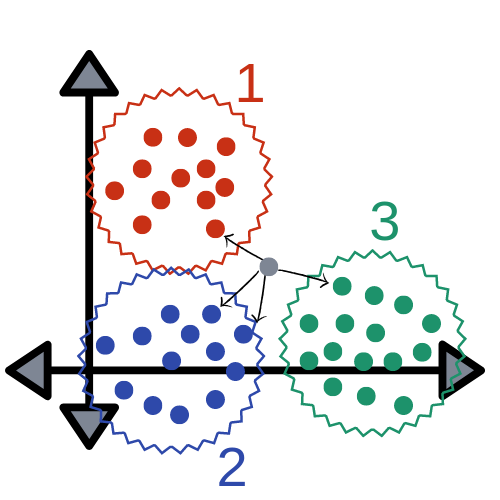
k近邻法学习算法工作流程
输入:训练数据集  其中
其中  ,
,  ,
,  代表类别
代表类别
输出:实例  所属的类别
所属的类别 
- 根据给定的距离度量,在训练集
 中找出与 最邻近的 个点,涵盖这 个点的领域称作
中找出与 最邻近的 个点,涵盖这 个点的领域称作 
- 在 中根据分类决策标准 (比如多数表决) 决定 的类别
近邻法的特殊情况为  的情形,称作最近邻算法;对于输入的实例点 ,最近邻法将训练数据中与 最领近的点的类作为 的类
的情形,称作最近邻算法;对于输入的实例点 ,最近邻法将训练数据中与 最领近的点的类作为 的类
参考

若有收获,就点个赞吧
0 人点赞
