在之前文章中我们主要了解了 CRDB 事务处理的相关内容和更新语句的处理流程,而在 CRDB 中个人觉得除了事务处理外另一个个人比较有兴趣的地方是对于读语句 select 的处理,首先在 Planner 上也有其他知乎大佬解析过的 Cascade Planner(后续也会看源码),而本文将更多关注 Planner 之后的执行阶段,一直听说 CRDB 很有特点,实现了将 sub-plan 分发到合适节点执行的机制,通过本文我们就来看看。
基本流程
通过前面的 range meta 闲逛和文档阅读我们知道 CRDB 已经在 KV 维度上对上层逻辑提供一个分布式的 monolithic sorted 流程 map 抽象,但相比直接使用 KV 接口进行网络交互处理,将计算逻辑放到更靠近数据所在的地方执行会更高效(多节点并行处理+网络传输减少),另外对于一些复杂计算的算子通过一定的节点间数据交换可以在无法完全 Local 处理时多节点并行处理充分利用机器资源,而 DistSQL 在 CRDB 中会负责将 Plan 切分并在多个节点上执行并将最终执行结果通过首次接收 SQL 节点响应返回给客户端。
下面我们先快速简单看下一个可以被 DistSQL 方式执行的 SQL 如何被 CRDB 处理:(这里只是为了有个总体的概念,细节后面会细说~)
- CRDB 首先会先执行和数据分布无关的“逻辑优化”获取考虑代价的单机执行最优 PlanNode 树(解决选择什么索引?选择什么 JOIN, SORT, AGG 策略?…等只需要结合算子类型,统计信息和代价模型就能作出决策的本地优化)
- 在此基础上生成 PhysicalPlan, 生成过程会自底向上将算子根据 range meta 和节点特性切分为多个可在 Node 上运行且使用 stream 连接的多个 Processor 分组(i.e. 根据 range 划分 table reader 为多个 processor, 并在每个 tablereader processor 之上累加能继续在 table reader 节点执行的 filter projection 等其他算子 processor),每个 Processor 会定义执行算子的 Spec(e.g. TableReaderSpec),后置处理(PostProcessorSpec),输出同步(InputSyncSpec),输出路由(OutputRouterSpec)等信息
- 对 PhysicalPlan 根据 Node 节点维度生 FlowSpec(i.e. 可在一个节点上执行多个 Processor 比如同节点的几个 range 的处理会合并成一个 FlowSpec),同一个 SQL 的所有 FlowSpec 都会有相同的 FlowID(后续 setup 过程会依赖 FlowID 来识别并关联)
- 之后对非本地 Node 的 FlowSpec 构建 SetupFlowRequest 并发送到远端节点触发在对应节点进行 Flow Setup,在远程 Node 的 Flow Setup 完成后,再进行本地 Local Flow 的 SetupLocalSyncFlow
- 在完成远端和本地的 Flow 的 Setup 后,本地 Flow 会直接进行 Run(即最后一个 Processor 会当前 goroutine 运行,其他 Processor 会分别用 goroutine 执行); 远端的 Flow 则通过 Node 维度的 FlowScheduler 调度执行 Start(每个 Processor 一个ie goroutine 异步运行,需要的话可以用 Wait 来完成等待)
其中因为在不同节点上运行的不同 Processor, 需要特别关注相互之间的关联建立问题,这里先稍微仔细看下上面第 4 步 Setup 过程中和 Processor 之间连接关系建立的相关工作:
- 对当前的 Processor 的所有 InputSyncSpec 进行 Setup, 根据是否需要保证结果顺序选择: 能在多个 RowChannel 保序获取的 orderedSynchronizer(多个输入各自有序,只需要顺序读取多个输入就能保证合并后有序)或直接使用一个 RowChannel 无序处理(可以同时接收多个输入但就不能保证次序);
- 对 Processor 的 InputSyncSpec 中的多个 Stream 进行 setupInboundStream, 主要是: 对 Remote 的 stream 注册好 InboundStreamHandler 等后续远端连上来后开始运行时处理 Processor 远端输入(注意只是注册不会实际让 goroutine 运行); 对 Local 的 stream 注册好本地 localStreams(streamId -> rowReciever) 方便其他本地 Processor 找到该 Processor 的输入口
- 根据 OutputRouterSpec 类型是否是 PASS_THOUGH 选择:输出直接是一个 output RowReceiver 还是通过 Router 分发的多个 output(i.e. 一个 Processor 可以选择将结果按照 Range 或 Hash 分发或对多个节点进行 Mirror 复制分发);
- 对于每个 output Stream 同样会进行 Setup: 对于 Remote 的 stream 会注册 Outbox 等待 Processor 运行时实际运行处理输出发送远端逻辑; 对 Local 的 stream 会检查有对应注册 inbound stream; 对于 Router 这一步只是注册 Startable 等实际执行才会启动 goroutine
- 根据 Spec 生产具体的 Processor,根据 Spec 生产具体可执行的执行器,并是使用第4步产生的 output RowReciever 作为当前执行器的输入供给下一步的 Processor 作为输入
在完成 Setup, Processor 已经知道“要从谁收输入”和“要将输入如何发给其他人”,但并没有实际去启动 goroutine 和建立连接,只是注册了大量的 Startable 到 Flow 中,而等待实际 Flow 被运行(本地的 Run 或远端 Scheduler 调起的 Start)的首次运行过程中会调用 startInternal 在这个方法中会完成实际拓扑的延迟建立:
- 首先将自己的所有需要从 remote 获取的 inboundStream 进行 RegisterFlow, 这个能保证 remote 节点向自己建立关联时能找到对应 inboundStream,并且如果 remote 早于当前节点被调度运行会等待当前节点的调度(生产者等消费者工作才能工作)
- 之后会对注册的各种 Startable 进行启动, 比如 Outbox 会启动 goroutine,并建立 GRPC 连接调用 FlowStream 获取后续通讯使用 GRPC Stream, 之后则负责将 Procesor 产生的输出发送的 Stream 上
- 对端节点在收到 FlowStream 在返回 Stream 的同时会运行 flowStreamInt 在当前节点找到当前节点中被 RegisterFlow 的 stream(入过当前节点的 Processor 还没被 Schedule 则会等待并通过 ConsumerSignal 反馈发送方), 并触发 InboundStreamHandler 新建 goroutine 来读取 stream 传入的输入并通过 rowRecevier 发给当前节点的 Processor 作为输入数据处理
这之后我们的 SQL 就能在多个节点上运行并相互通信交数据了,最后集中由开始接收 SQL 的节点返回回客户端。 接下来我们再看具体每个步骤的处理过程。
能否 Dist 执行
如上面整体流程中看到的,我们在拿到一个经过结合统计信息在单机器优的 SQL 后(其实为什么不在 volcano 中考虑而是要单独拉出来考虑呢?Calcite 中如何处理类似情况?—-等后面回去看看), CRDB 会通过 shouldDistributePlan 方法先通过遍历检查 PlanNode 树来给出 distRecommendation:
- cannotDistribute 不能 dist 执行
- shouldNotDistribute 可以 dist 但可能需要 suffer
- canDistribute 可能 dist 没效果但可能不需要 suffer(但可组合其他 dist node)
- shouldDistribute 使用 dist 执行很可能有效果
实现过程也是对树进遍历,对节点以及节点的表达式(主要是 Func 的 DistsqlBlacklist 属性)判断,并类似三值逻辑进行 compose 组合 distRecommendation 结果给出最终整颗树的 recommandation, 并根据当前 session 的 DistSQLExecMode 来决定用不用 Dist 执行,默认的 DistSQLAuto 模式下 shouldDistribute才可 Dist 执行,对于具体节点类型和判断逻辑可以参考代码 shouldDistributePlan 代码这里不在罗列。
如果可以 dist 执行则会生成可以 dist 执行能访问 range meta 的 PlanningCtx, 并开始 DistPlanner.PlanAndRun(这里先不考虑子查询)。
生成物理计划
进入到 DistPlanner.PlanAndRun 这个方法会 createPlanForNode 根据 PlanNode(逻辑 Plan 节点)类型对 PlanNode 树进行递归的处理生成 PhysicalPlan, 生成的物理计划逻辑上是由一下信息组成:
- 多个 Processor 的数组,定义每个 Node 需要执行的 ProcessorSpec 即 SubPlan 的具体执行逻辑 Core ProcessorCoreUnion Input/Ouput Spec 以及 inline 的后置处理 PostProcessSpec, 通过 spec 定义后续能在对应节点上 setup 准备出可执行的设施,具体这些 spec 中:
- Core ProcessorCoreUnion 类似 C 中的 Union 可以是 TableReaderSpec 或 JoinReaderSpec 等一个具体执行器的 Spec
- InputSyncSpec 会定义多个 inputStream(type, streamID, targetNodeID), 需保证排序的列定义,和是否需要对多个 stream 保证排序
- OutputRouterSpec 定义了多个 outputStream, 输出路由方式(pass, hash, range, mirror),是否不想要输出 buffer (有些情况会导致 deadlock)
- 多个 LocalProcessor 的数组,对于不支持 dist 执行的 PlanNode 会被 wrap 成 planNodeToRowSource 形式的的 LocalProcessor 添加到此,同时会以为 LocalPlanNodeSpec 的形式放到前面的 Processor 数组中并维护指向 LocalProcessor 数组的 Index
- 多个 Stream 的数组,在构建过程中维护所有 stream 主要标识 source 和 dest processor 的在当前 PhysicalPlan 中的 index, 在 Plan 的最后阶段会通过 PopulateEndpoints 方法中转换为具体 Processor 中的 input 或 output StreamSpec
- 叫 ResultRouter 的 index 数组,用于标识 PhysicalPlan 当前阶段作为“输出 Processor” 的 Index,后续扩展将会在这些 Processor 上继续(例如,最开始的 N 个 TableReader 的 index 在这维护,后一步加 Filter 会对每个 TableReader 都加)
- ResultTypes 的类型数组,用于标识当前阶段的 Plan 的输出列类型信息,同样也会随着 Plan 的构建而不停更新,Plan 构建完成后形成最终的输出结果类型信息
回到 createPlanForNode 会按照类型递归处理 PlanNode 自底向上进行构建上面描述结构的 PhysicalPlan:
scanNode:
一般来叶子节点都是 scanNode 代表对 table 或 index 的访问,在拿到 scanNode 后 createTableReaders 将:
- 准备好 scanNode 所需要列到实际表中列的 索引映射 scanNodeToTableOrdinalMap
- 根据 scanNode 初始化对应的 tableReaderSpec 模板
- 准备在指定 node 需处理多少 span 的 SpanPartition 信息数组, 主要分三种情况,如果但却 PlanCtx 是不可 dist 则让 gateway node 负责所有 span; 如果可 dist 但有 hard/soft limit 会先让地一个 span leader 所在节点负责所有 span 来避处理超过 limit 的数据; 最后如果没有 limit 则会对每个 span 定位 leader replica node,相关的 node 会负责其上的相关 span,在处理过程中会考虑节点版本的细节(比如部分节点还在升级过程中不支持这个 plan) 和同节点相邻 span 合并逻辑, 代码可以看下 PartitionSpans 方法
- 之后对每个 SpanPartition 拷贝 tableReaderSpec 模板分别初始各自的 spans,生成对应 node 包装了 tableReader 的 Processor 添加到 physicalPlan 中, 如果第三步中设生成的是多个 node 的 PartitionSpan 到这里 Physical 中将对每个 node 有一个自己的 Table Processor 来处理当前 node 的 span 读取, 并且会用 ResultRouters 来标识“这几个 Processor 是当前 Plan 构建的 top 后续请在这几个之上叠加”
- 如果有多个 table reader 被分到多个节点执行且语句有要求排序的话,需要维护 PhysicalPlan 的 MergeOrder,这里没需要注意还是 scanNode 和 表 列 idx 值的转换
- 之后会对每个 node 的 tableReader Processor 来设置 PostProcessor(通过 ResultRouter 来找到这些 Processor), 这一步主要设置 inline 的 filter 到 PostProcessor - SetLastStagePost
- 最后会根据 table reader 的输出列结果继续 AddProjection 这个方法中继续对 PostProcessor 进行更新,根据已有 renderExp 或 project 的情况调整输出列,并根据新的列次序更新 MergeOrder
- 最后会维护当前 scanNode 的列到 output 列的 index 映射供后面接收其他节点发来数据时隐式 Project 处理用.
总结下就是通过对于 tableReader 可能会按照 span 所在节点分为多个 TableReader Processor 在多个节点执行,并且 tableReader 会分别 inline 一些 filter 和 projection 逻辑, 添加多个 tableReader 后 phyiscal plan 自身也会保证 mergeOrder 信息的正确维护。
indexJoinNode:
indexJoinNode 是较常见的 planNode,完成大家常说的回表操作,即通过索引结果读取表结果,表现形式类似 join, 他的 input 通常是对 index 读取的 tableReader(当这个 tableReader 之上可以有 filter/project..), 而 table 属性是一个 scanNode 即”要回的 table”。
变成执行器会是 indexJoiner 很有特点,始终会对 input 的每行去查 table,在多节点下执行获取可以选择以下三种方式之一:
- 在 gateway 执行 + 远程读 input 远程回表, gateway 等从 input 到数据再根据 pk 找对应 node 发请求获取表数据(通常这里会 batch),后续算子逻辑会在 gateway 继续执行
- 分散到各个节点执行 + 本地读 input 远程回表,在 input 的 node(比如:索引数据所在 range 的 leader node)各自附加 joinReader, 执行 node 会根据 pk 直接向其他节点请求获取表数据(通常这里会 batch),后续逻辑会在当前 node 继续执行
- 分散到各个节点执行 + 本地读 input, 根据 pk 将结果传输到 pk 所属节点,后续逻辑会在传输目标节点继续执行
CRDB 目前使用的看上去是第二种方法(虽然第三种看上去好像更好且 CRDB 对 ouptputSpec 是可以支持这么做的)
所以在完成叶子节点 scanNode 处理 index 读取的 tableReader 后,通常会来到 createPlanForIndexJoin 方法,进行 indexJoinNode 到物理计划的处理:
- 首先处理 input 子节点(通常是前面提到的 scanNode)
- 通过 AddProject 方法将 input 收入列裁剪排序为符合要回查表的 primary 列定义的样子
- 生成 JoinReaderSpec 通过仔细看代码可以发现这 spec 后面通过判断是否有 LookupColumns 最终生成, 通过 index 查 table 的 indexerJoiner 或通过 table 查 index 的 JoinReader, 对于这里会生成不带 LookupColumns 的 spec
- 使用目标 table 准备输出列类型信息以及需要应用在回表结果上的的内联 filter
- 根据当前已有下层 Physical Plan 的情况,如果下层已经有多个输出 stream(((ResultRouters) > 1)和是否使用 Dist Join(默认 true), 选择将 JoinReaderSpec 的新 Processor 分别叠加并在 input 节点 dist 执行(AddNoGroupingStage) ,还是在一个节点集中执行(AddSingleGroupStage)
- AddNoGroupingStage: 可以理解会在当前 PhysicalPlan 的多个结果输出 Processor 后分别添加 Processor, 会前置 Processor 在同一个 node 上执行, 从整体看是 Dist 并行计算
- AddSingleGroupStage: 相反则在一个节点上等待所有前置 Processor 都处理完成才会开始执行
lookupJoinNode:
趁热打铁,看完了通过 index 找 table 的 indexJoinNode,这里顺带看下通过 table 查 index 的 lookupJoinNode,使用场景通常是 2 个表 join, 但代价计算使用 a 表结果去分别去 b 表中用某个 index 看是否有匹配行。
通过 createPlanForLookupJoin 方法可以看到也是生成 JoinReaderSpec 但会制定 IndexIdx 和 LookupColumns 等来让最终生成的是 joinReader 算子,另外相比 indexReader 无脑回表,这里也需要考虑 join 类型对输出结果列信息的影响。
对于 lookupJoinNode 的 JoinReaderSpec 都会按照 AddNoGroupingStage 分别累加到已有输入后。
joinNode:
前面看了两个比较“简单的 join”, 而对于正常 join 的 joinNode 操作, joinNode 只描述了左右儿子,join 条件和 join 类型等, 这个节点之后会被实现为 HashJoin 或 MergeJoin。
便于理解代码先简单描述下如何用多个节点做 Distributed Join,主要思想是通过 Hash 将要比较的行分发到到同一个 Node,即理论上我们可以在集群中选择任意 N 个节点(可以和 input 放一起也可以不放一起并且 N 可多可少),并在上面各自放一个 Join Processor,然后让 Join 的输入算子在 output 时按照对比较行 Hash 路由分发数据到这 N 个中即可,可以发现这里有个限制是 Join Predict 中需要有等值比较(=)。
进入 createPlanForJoin 方法, 这里我们先不考虑 interleave table 特性的处理, 看下具体处理过程:
- 首先还是先完成对左右孩子的递归转换物理计划
- 然后使用 MergePlans 方法将左右子树的 PhyicalPlan 进行 merge, 大体处理过程是将各自的 Processor 合并在一起,并修正 Stream 的 Dest 和 Source Index 和 ResultRouter 等 ProcessorIdx(right 都加 len(left))
- 之后看 Join 条件如果没有等值条件(e.g. t1.c > t2.c), 则不能 dist 执行会选择 right 或 left input 所在 node 进行单节点处理
- 如果有等值条件, 则可以 dist 处理 join, 会通过 findJoinProcessorNodes 获取用于处理 Join 的 Node, 目前实现比较粗糙会直接用所有 input 的 node(作者有 TODO 说后续改进)
- 对于等值条件,还会进一步检查是否所有比较列都有序,是的话会使用 MergeJoinerSpec, 否则都用 HashJoinerSpec(这部分后续文章需要结合前面 planner 看下,另外注释中也说这里可以通过进入 hybrid hash/merge processor 来 relax 需完匹配的约束)
- 到这里可以为所有处理 Join 的 Node 生成 Processor(Merge/Hash Join), 并对左右当前 Result Processor 的 output spec 设置为按照等值比较列做 OutputRouterSpec_BY_HASH 路由, 并用 MergeResultStreams 将左右 router 和当前的 N 个 Join Processor 准备 synchronizer(排序 or 不排序收) 和关联 stream, 并维护加入 join 后当前 plan 的 ResultRouters。
- 最后就是根据 join 的类型,维护作为 join 输出结果信息的 PlanToStreamColMap, ResultTypes 和 MergeJoinOrder
总的来说就是对于等值 join 可以通过在多个节点上准备 JoinProcessor 并让上游 Processor router 根据比较列做 Hash 分发到到对应 JoinProcessor 即可实现用多个节点执行 Join。(类似下图)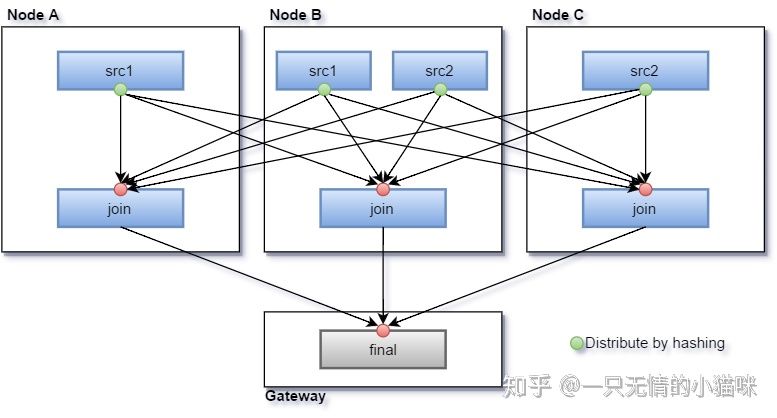
可能看文档还有一种 mirror 的方式(类似中间件里大家说的“小表广播”),router 基础设施是支持的, 但实际代码除了测试外没有实际用到(另外一种 router by range 也是没用到),应该是这两者选择需呀更好的代价模型来决定看上去 CRDB 还在继续改进这块。
groupNode:
看完 join 正好看下代表聚合的 groupNode
同样简单描述下 Distributed aggregation 的基本处理过程, 根据聚合函数的不同 Agg 通常可以抽象为 2 个 stage: 分布在每个 input 所在节点的 local stage 和产生最终结果的 final stage,然后 final stage 根据 group by 情况可以做类似上面 join 类似 hash 分发支持多个节点执行 final stage(其实如果单机处理可以可以做类似 2 stages 来用多个线程做并行 agg,这里将线程变为机器节点).
转换代码位于 addAggregators 方法:
- 在完成对儿子节点的递归处理后,首先会将 groupNode 中的每个聚合函数(n.funcs)预先处理从 Str 转换为对应的函数 enum, 并预准备是否是 distinct,filter, render column 索引和常量参数等
- 接下来对会先检查所有上游 Processor 是否都在一个 Node(输入都在一个节点没必要 dist 执行)
- 之后通过查看 DistAggregationTable来确定聚合函数是否支持分 local/final 多阶段(已经具体函数应该怎么分,推荐看下 AggregatorSpec_AVG), 如果不支持多阶段则直接将所有 func 放到 finalAggsSpec 执行
- 并且会做一个优化逻辑,如果函数都是 distinct,虽然 distinct 不能被 local/final 但如果都是 disinct 可以也先 local distinct 下来减少传输数据量
- 如果聚合函数支持多阶段,则对每个函数根据 DistAggregationTable的定义生成对应的 local 和 final spec, 这里有点细节是关于输出输入列 index 处理和如果有重复 spec 通过输入输出 index 复用已有 spec 不用重复计算
- 对 local stage 的spec 做一些修正(主要是如果是 SELECT min(v) FROM kv GROUP BY k 这种没 group column 的 sql 需要在 local stage 输出中补 k 的 AggregatorSpec_ANY_NOT_NULL 来让 final 能知道 k, 另外 local 输出的 order column 的列 column idx 需要修正)后就可以将 local stage 就可用 AddNoGroupingStage 附加到所有节点做 Processor 了。
- 对于 final stage 如果是没有 group columns(没有 group by)或 input 只有 1 个的情况会选择 input 节点 AddSingleGroupStage 做一个单点的聚合处理
- 有 group columns 且有多个 input 则类似 Join 会在每个 input 所在节点配置 final stage 的 Processor(和 Join 一样这里比较粗糙有 TODO),并对上游 Processor 的 output spec 对 group column 使用 OutputRouterSpec_BY_HASH 分发并 stream 互联,维护输出结果信息的 PlanToStreamColMap, ResultTypes 和 MergeJoinOrder
总结下 agg 会根据函数定义,分 local 和 final, local 可以分发到各个 input 节点, final 则根据 group column 类似 join 做 hash 分发聚合。
sortNode:
在 CRDB 中的 sortNode 节点只负责将当前 input 分别排序不会管收紧到一个节点的全局 order(那些可以通过添加其他算子或 orderedSynchronizer), 所以实现就是用 AddNoGroupingStage 将 sort 累加到当前所有输出节点上。
更多其他节点{PlaceHolder}
另外还有其他一些节点(render, limit, filter….)这里出于时间关系这里就不一一看了,或者后么看了我会在这继续补充
添加结果节点并暴露 Endpoint
在 createPlanForNode 方法之后,已经有基于逻辑计划节点生产的多个 Processor,但还需在 gateway 节点用 FinalizePlan 方法进行 2 个工作
首先, 看当前节点的 ResultRouters 是否有为 1, 不是则 AddSingleGroup 在当前 Node 添加一个 NoopCoreSpec 的不做任何事情只转发 Processor(因为 CRDB 是每个节点都可接收客户端请求,就可能出现 A, B, C 三个节点请求的请求到达 A 节点但实际数据在 C,最后作出的 Plan 将是 C 上 tableReader 输出给 A 上的 noop, A 返回给客户端)
此外, 使用 PopulateEndpoints 将前面构建过程中“临时”放置在 plan.Streams 中的关联信息整理并放到各自 Processor 的 input(Input[s.DestInput].Streams) 和 output(router.Streams) spec 中, 并且在整理过程看如果 dest 和 src 不是同节点标记 StreamEndpointSpec_REMOTE 类型,来帮助后续执行确认自己是否需要和其他节点远程交互。
得到的物理计划之后
到这里我们已经从逻辑计划得到了,能明确知道算子应该在哪个节点执行,算子间如何关联分发的物理计划(类似这样文档中的这个图),之后就是运行,对于运行过程本文最开始基本流程部分有一些总体描述,本篇有些长打算下一篇再来仔细看下 Setup/Schedule 和执行的实现细节~ 最后付个官网的复杂图: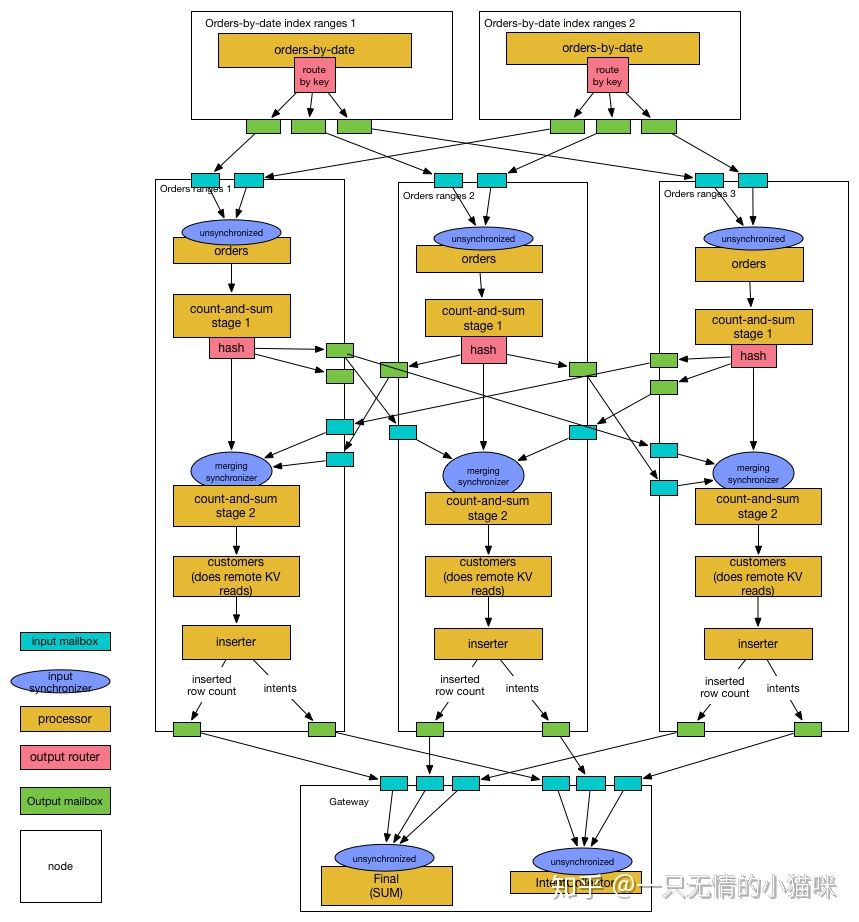
小结
在本文中我们看了下 CRDB 中 DistSQL 的宏观处理流程,并集中看下如何将逻辑计划转换为可以被 Dist 执行的物理计划,特别是其中 Join/AGG 等算子的处理,下一篇我们将继续看下 PhyiscalPlan 在多个节点的 Setup 和执行。
对于 CRDB 的逻辑转物理看上去是没有太多考虑分布代价,更多是基于规则的直接转换,另外对于一次 Invoke 哪些节点看去也比较粗糙(但有可能是想先随意 Plan 然后到 schedule 的时候再做资源控制?),但感觉已经有了一些不错基础设施基础设计,看也有很多 TODO 等待后续改进相信为来也许会更好 - -,而对我之前没看过类似多节点运行 Plan 的东西感觉还是有些帮助,希望本文对大家也有帮助(我的风格比较乱, 更可怕的是这次用 vscode 插件写专栏,代码样式丢了…)~

若有收获,就点个赞吧
0 人点赞
