在之前的两篇文章中,我们看了一下 CRDB 基本事务处理处理和最近的一些有意思的流程优化,本文中我们将来看下事务中的时间戳处理细节(主要整体看下各个时间戳的处理)。
事务的核心模型是 roachpb.Transaction 结构体,这里精简并看下和时间戳和重试相关字段:
type Transaction struct {// 内嵌的 `enginepb.TxnMeta` 结构体// 即事务的元数据这部分信息会作为 Transaction 的一部分持久化为 Transaction RecordTxnMeta struct {// 事务的唯一 ID 标识ID UUID// Transaction Record 所在的 author keyKey []byte// 初始为 0 每次重试 +1 来 invalidate 所有之前的写入Epoch int32// 事务的“提议时间戳”,初始为 wall-time, 当通过 `tscache` 得知已有其他更晚的事务已发生时// 会将这个“提议时间戳”向后 forward 到已发生的事务之后, 事务中的 DML 始终改字段的当前值// 作为写入 key 中的时间戳,所以可能会出现一个事务有不同的时间戳 key 不过这不是问题,在最// 后将 intent resolve 为 commit 数据时会将最后的“提议时间”作为提交数据 key 的时间戳。// 需要注意的是对于读还是会以 OrigTimestamp 来进行,只有写才会被不断 forward// - 使用 forward 后时的间戳写入可以避免 time-bound iterator 漏读 intent// - 使用 forward 后的时间戳写入可以减少读 forward 时间戳之前数据操作的无效 PushRequest// - 使用 forward 后的时间戳写入可以减少在 resolve intent 时重写 mvcc key 的数量Timestamp hlc.Timestamp// 事务开始时间戳(epoch=0 时)是当前事务中可能写 intent 的最早时间戳,会被用于:// - 对于 transaction record author key 和 tscache write 水位对比识别能否 synthesize txn record// - 同时会用于 resolve intent 时扫描 range 的 ts 下界MinTimestamp hlc.Timestamp// 事务的优先级, TODOPriority TxnPriority// 事务中请求的编号,对于写入或 EndTxn 会 +1,读不会// 在事务内读取时只能读到小于等于当前请求中 seq 的数据Sequence TxnSeq}// 事务状态(pending, stage, committed, aborted)Status TransactionStatus// 代表客户端事务的最后活跃时间,如果最近活跃则避免 abort 事务LastHeartbeat hlc.Timestamp// 事务中*所有*读操作使用的时间戳和 meta.Timestamp 时间戳会被不同 forward 不同// 读时间戳不会被 forward 且在提交时会检查如果 meta.Timestamp <> OrigTimestamp// 需要进行 refreshTimestamp 来尝试 forward OrigTimestamp 如果 refresh 失败则需重试// 并且这个 forward 过程会通过设置下面的 RefreshedTimestamp 来完成OrigTimestamp hlc.Timestamp// 事务中有使用 NOW() 函数等暴露 OrigTimestamp 到应用层的标记(PG 中 `now()` 是事务开始时间和 mysql 不一样)// 之后即使能 refresh 也不会尝试 forward OrigTimestamp 而是报错触发重试OrigTimestampWasObserved bool// 如前面 OrigTimestamp 所述用户 refresh 后不修改 orign 但在后续版本中可以直接修改这个字段会被移除RefreshedTimestamp hlc.Timestamp// 等于开始的 meta.Timestamp + clock skew, 由于 HLC 如果在读操作遇到在 timestamp 和 maxTimestamp 之间的数据// 并且读取节点不在 observed_timestamps 中则返回 `UncertaintyIntervalError` 触发重试MaxTimestamp hlc.Timestamp// nodeid + 时间戳对保存用于一定程度减少 UncertaintyIntervalErrorObservedTimestamps []ObservedTimestamp// 标记事务之后需要重试,但会继续完写 intent,来减少重试时的操作WriteTooOld bool// 记录 resolve intent 时需要扫描的 span 信息,前面一篇文章有介绍~IntentSpans []Span// Parallel commit 中介绍过的 inflight 的 write,前面一篇文章有介绍~InFlightWrites []SequencedWrite}
在 CRDB 中如何将这些字段用起来呢?这里使用一张巨大的图片来说明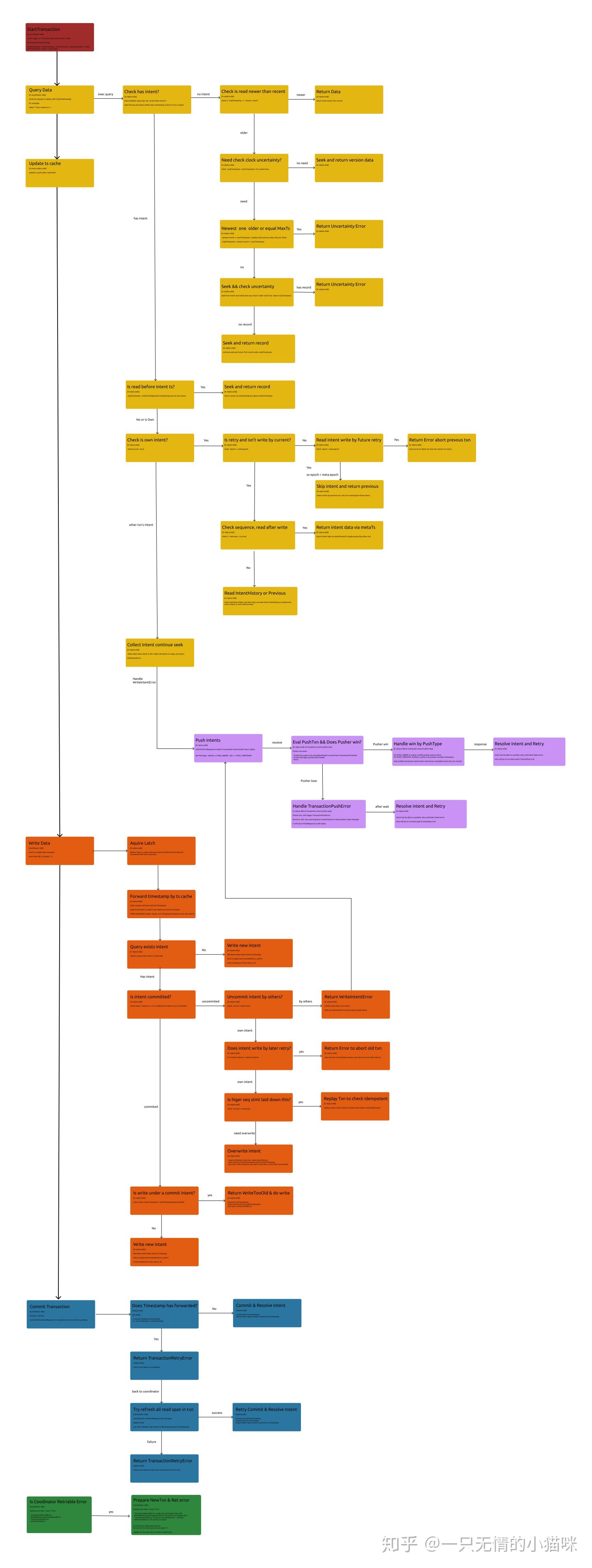
(点击可以放大~ )
通过上面的图片虽然没有对应到代码但也有大量的细节, 多数内容在之前文章中也有一些涉及,这里只是了下视角只集中看时间戳使用和处理就不再重复描述了~可能我有看错欢迎讨论~
总体感觉 CRDB 的事务模型实际去使用应该和 mysql 还是有一些不同,虽然有 txnwait.Queue 来通过等待减少重试,但 txnwait.Queue 并不是锁
- 虽然是 serializable 对于读被写阻塞的前提的是能以 OrigTimestamp 看到 intent 为前提,如果读的事务的 begin 发生在写 intent 的事务 begin 之后,虽然先写 intent,先 begin 的事务是不会被等锁的,但如果这个读事务后面有写入会在提交时 refresh 失败需要客户端重试(并不是说这个不好,其实都是 trade-off 这样的好处是只读事务虽然 serializable 也不会被其他事务阻塞,不过代价就是如果后面有写最后提交还是需客户端重试)
- 写遇到 uncommit 的 intent 就会等待(不管时间戳),但等待的其实是对方的 abort 如果对方提交成功自己需要重试,其实也没啥问题不等的话重试也成功不了
- 整个事务中的读都是 begin 开始时的 origTimestamp 快照读,不像 mysql 通过加锁能读当前值返回(crdb 如果读遇到 uncommit 的 intent 等待之后能读到刚 commit 的 intent 的值,但这个仅仅因为这些 intent 的能被 origTimestamp 看到而已 intent’s timestamp <= origTimestamp)
总之,对于使用 CRDB 冲突重试还是还是不可避免的,不过 CRDB 在 serializeable 级别下减少重试已经做了很多,另外也有一些自动重拾和帮助客户端重试的机制,本文本来打算介绍不过时间都花去画图了(有朋友建议我多画图- -),另外重拾会涉及到 client.Txn 等前面没啥介绍的内容(这个写了一部分等后面发)等后面我们再单独来看~

若有收获,就点个赞吧
0 人点赞
