Kubernetes中为了实现服务实例间的负载均衡和不同服务间的服务发现,创造了Service对象,同时又为从集群外部访问集群创建了Ingress对象。
3.7.1 Service
对于Kubernetes集群中的应用,Kubernetes提供了简单的Endpoints API,只要service中的一组Pod发生变更,应用程序就会被更新。
对于非Kubernetes集群中的应用,Kubernetes提供了基于VIP的网桥的方式访问Service,再由Service重定向到backend Pod。
VIP和Service代理
在Kubernetes集群中,每个Node运行一个kube-proxy进程。
kube-proxy负责为Service实现一种VIP的形式,而不是ExternalName的形式。
在Kubernetes v1.0版本,代理完全在userspace,Service是4层概念。
在Kubernetes v1.1版本,新增了Iptables代理,但并不是默认的运行模式。新增了Ingress API,用来表示7层服务。
从Kubernetes v1.2起,默认是iptables代理。
在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。
userspace代理模式
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。
任何连接到“代理端口”的请求,都会被代理到 Service 的backend Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个 backend Pod,是基于 Service 的 SessionAffinity 来确定的。
最后,它安装 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP)和 Port 的请求,并重定向到代理端口,代理端口再代理请求到 backend Pod。
网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。
默认的策略是,通过 round-robin 算法来选择 backend Pod。 实现基于客户端 IP 的会话亲和性,可以通过设置 service.spec.sessionAffinity 的值为 "ClientIP" (默认值为 "None")。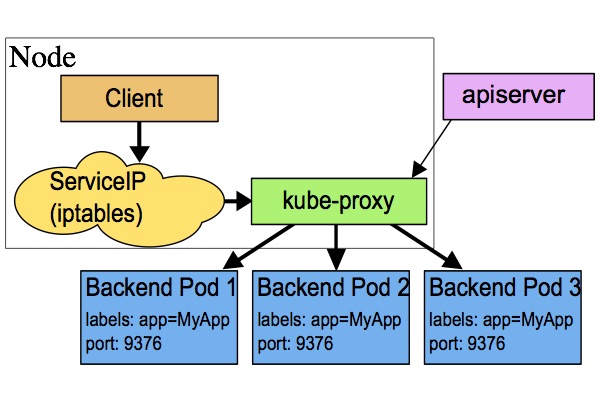
iptables代理模式
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某个上面。对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend Pod。
默认的策略是,随机选择一个 backend。实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
和 userspace 代理类似,网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。
这应该比 userspace 代理更快、更可靠。然而,不像 userspace 代理,如果初始选择的 Pod 没有响应,iptables 代理不能自动地重试另一个 Pod,所以它需要依赖 readiness probes。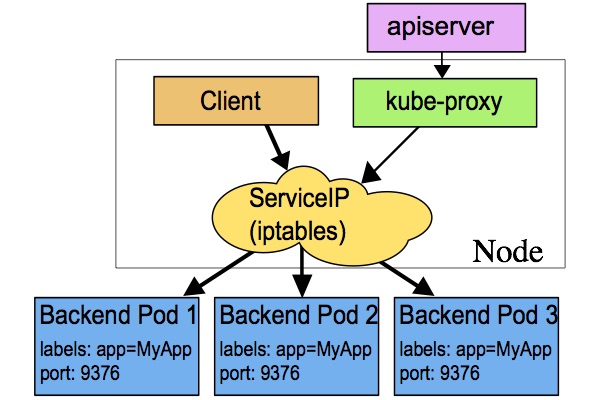
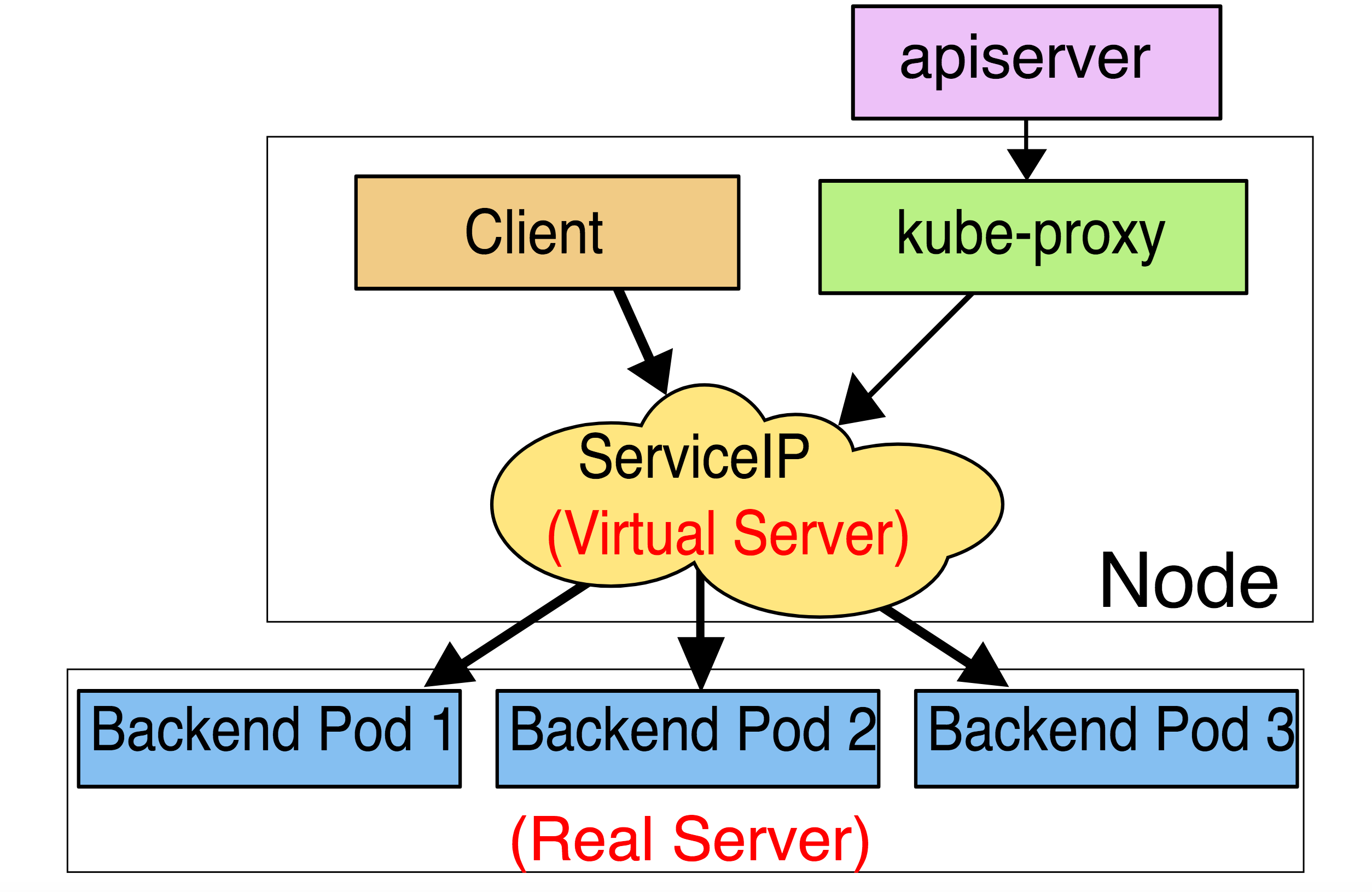
ipvs代理模式
这种模式,kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度lc:最小连接数dh:目标哈希sh:源哈希sed:最短期望延迟nq: 不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
多端口Service
Kubernetes 支持在 Service 对象中定义多个端口。 当使用多个端口时,必须给出所有的端口的名称,这样 Endpoint 就不会产生歧义,例如:
kind: ServiceapiVersion: v1metadata:name: my-servicespec:selector:app: MyAppports:- name: httpprotocol: TCPport: 80targetPort: 9376- name: httpsprotocol: TCPport: 443targetPort: 9377
选择自己的IP地址
在Service创建的请求中,可以通过设置spec.clusterIP字段来指定自己的集群IP地址。
IP地址需要在service-cluster-ip-range CIDR范围内。
服务发现
Kubernetes支持2种基本的服务发现模式:环境变量和DNS。
环境变量
当Pod运行在Node上,kubelet会为每个活跃的service添加一组环境变量。它同时支持Docker links兼容变量、简单的{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT变量,这里的Service名称需要大写,横线被转换成下划线。
Pod想要访问的任何Service必须在Pod之前被创建,否则这些环境变量就不会被赋值。
DNS没有这个限制。
DNS
DNS服务器监视着创建新Service的Kubernetes API,从而为每一个Service创建一组DNS记录。
如果整个集群的DNS一直被启用,那么所有的Pod应该能够自动对Service进行名称解析。
Kubernetes也支持对端口名称的DNS SRV(Service)记录。
Kubernetes DNS 服务器是唯一的一种能够访问ExternalName类型的Service的方式。
Headless Service
有时不需要或者不想要负载均衡,以及单独的Service IP。
可以通过指定Cluster IP的值为None来创建Headless Service。
对这类Service并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。
DNS如何实现自动配置,依赖于Service是否定义了selector。
配置Selector
对定义了selector的Headless Service,EndPoint控制器在API中创建了Endpoints记录,并且修改DNS配置返回A记录(地址),通过这个地址直达Service的后端Pod上。
不配置Selector**
对没有定义selector的Headless Service,Endpoint控制器不会创建Endpoints记录。然而DNS系统会查找和配置,无论是:
ExternalName类型Service的CNAME记录
记录:与Service共享一个名称的任何Endpoints,以及所有其他类型
发布服务-服务类型
有些应用,可能希望通过外部(Kubernetes集群外部)IP地址暴露Service。
Kubernetes ServiceTypes允许指定一个需要的类型的Service,默认是ClusterIP类型。
Type的取值及行为如下:
ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort服务会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求<NodeIP>:<NodePort>,可以从集群的外部访问一个NodePort服务。LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。ExternalName:通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。 没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的kube-dns才支持。
NodePort 类型
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定。
外部IP
如果外部的 IP 路由到集群中一个或多个 Node 上,Kubernetes Service 会被暴露给这些 externalIPs。通过外部 IP(作为目的 IP 地址)进入到集群,打到 Service 的端口上的流量,将会被路由到 Service 的 Endpoint 上。externalIPs 不会被 Kubernetes 管理,它属于集群管理员的职责范畴。
根据 Service 的规定,externalIPs 可以同任意的 ServiceType 来一起指定。在下面的例子中,my-service 可以在 80.11.12.10:80(外部 IP:端口)上被客户端访问。
kind: ServiceapiVersion: v1metadata:name: my-servicespec:selector:app: MyAppports:- name: httpprotocol: TCPport: 80targetPort: 9376externalIP:- 80.11.12.10
3.7.2 Ingress
Ingress解析
Ingress是从Kubernetes集群外部访问集群内部服务的入口。
什么是Ingress?
通常情况下,service和pod仅可在集群内部网络中通过IP地址访问。所有到达边界路由器的流量或被丢弃或被转发到其他地方。
internet|------------[ Services ]
Ingress是授权入站连接到达集群服务的规则集合。
internet|[ Ingress ]--|-----|--[ Services ]
可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等。
用户通过POST Ingress资源到API Server的方式来请求Ingress。
Ingress Controller负责实现Ingress,通常使用负载均衡器,它还可以配置边界路由和其他前端。
Ingress Resource
最简化的Ingress配置:
apiVersion: apps/v1kind: Ingressmetadata:name: test-ingressspec:rules:- http:paths:- path: /testpathbackend:serviceName: testservicePort: 80
Ingress Controllers
为了使Ingress正常工作,集群中必须运行Ingress controller。
- Kubernetes当前支持并维护GCE和nginx两种Controller。
- F5(公司)支持并维护F5 BIG-IP Controller for Kubernetes。
- Kong同时支持并维护社区版和企业版的Kong Ingress Controller for Kubernetes。
- Traefik是功能齐全的ingress controller。
- Istio使用CRD Gateway来控制Ingress流量。
Ingress类型
单Service Ingress
创建一个没有rule的默认backend的方式:
apiVersion: apps/v1kind: Ingressmetadata:name: test-ingressspec:backend:serviceName: testsvcservicePort: 80
假如想创建这样一个设置:
foo.bar.com -> 178.91.123.132 -> / foo s1:80/ bar s2:80
则需要这个一个Ingress:
apiVersion: apps/v1kind: Ingressmetadata:name: testspec:rules:- host: foo.bar.comhttp:paths:- path: /foobackend:serviceName: s1servicePort: 80- path: /barbackend:serviceName: s2servicePort: 80
只要服务(s1,s2)存在,Ingress Controller就会将提供一个满足该Ingress的特定loadbalancer实现。
这一步完成后,您将在Ingress的最后一列看到loadbalancer的地址。
基于名称的虚拟主机
Name-Based的虚拟主机在同一个IP地址下拥有多个主机名。
foo.bar.com --| |-> foo.bar.com s1:80| 178.91.123.132 |bar.foo.com --| |-> bar.foo.com s2:80
如下这个Ingress说明基于Host header的后端loadbalancer的路由请求:
apiVersion: apps/v1kind: Ingressmetadata:name: testspec:rules:- host: foo.bar.comhttp:paths:- backend:serviceName: s1servicePort: 80- host: bar.foo.comhttp:paths:- backend:serviceName: s2servicePort: 80
一个没有rule的Ingress,所有流量都将发送到一个默认的backend。
TLS
可以通过指定包含TLS私钥和证书的secret来加密Ingress。
目前Ingress仅支持单个TLS端口443,并假定TLS termination。
如果Ingress中的TLS配置部分指定了不同的主机,则它们将根据通过SNI TLS扩展指定为tls.crt和tls.key的密钥。
apiVersion: apps/v1data:tls.crt: base64 encoded certtls.key: base64 encoded keykind: Secretmetadata:name: testsecretnamespace: defaulttype: Opaque
在Ingress中引用这个secret将通知Ingress Controller使用TLS加密从将客户端到loadbalancer的channel:
apiVersion: apps/v1
kind: Ingress
metadata:
name: no-rules-map
spec:
tls:
- secretName: testsecret
backend:
serviceName: s1
servicePort: 80
更新Ingress
kubectl edit ing test

若有收获,就点个赞吧
0 人点赞
