3.6.1 Deployment
Deployment为Pod和ReplicaSet提供了一个声明式定义方法,用来替代以前的ReplicationController来方便的管理应用。典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
一个简单的Nginx可以定义为:
apiVersion: extension/v1beta1kind: deploymentmetadata:name: nginx-deploymentspec:replicas: 3template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80
扩容:
kubectl scale deployment nginx-deployment --replicas 10
如果集群支持horizontal pod autoscaling的话,还可以为Deployment设置自动扩展:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
更新镜像:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
回滚:
kubectl rollout undo deloyment/nginx-deployment
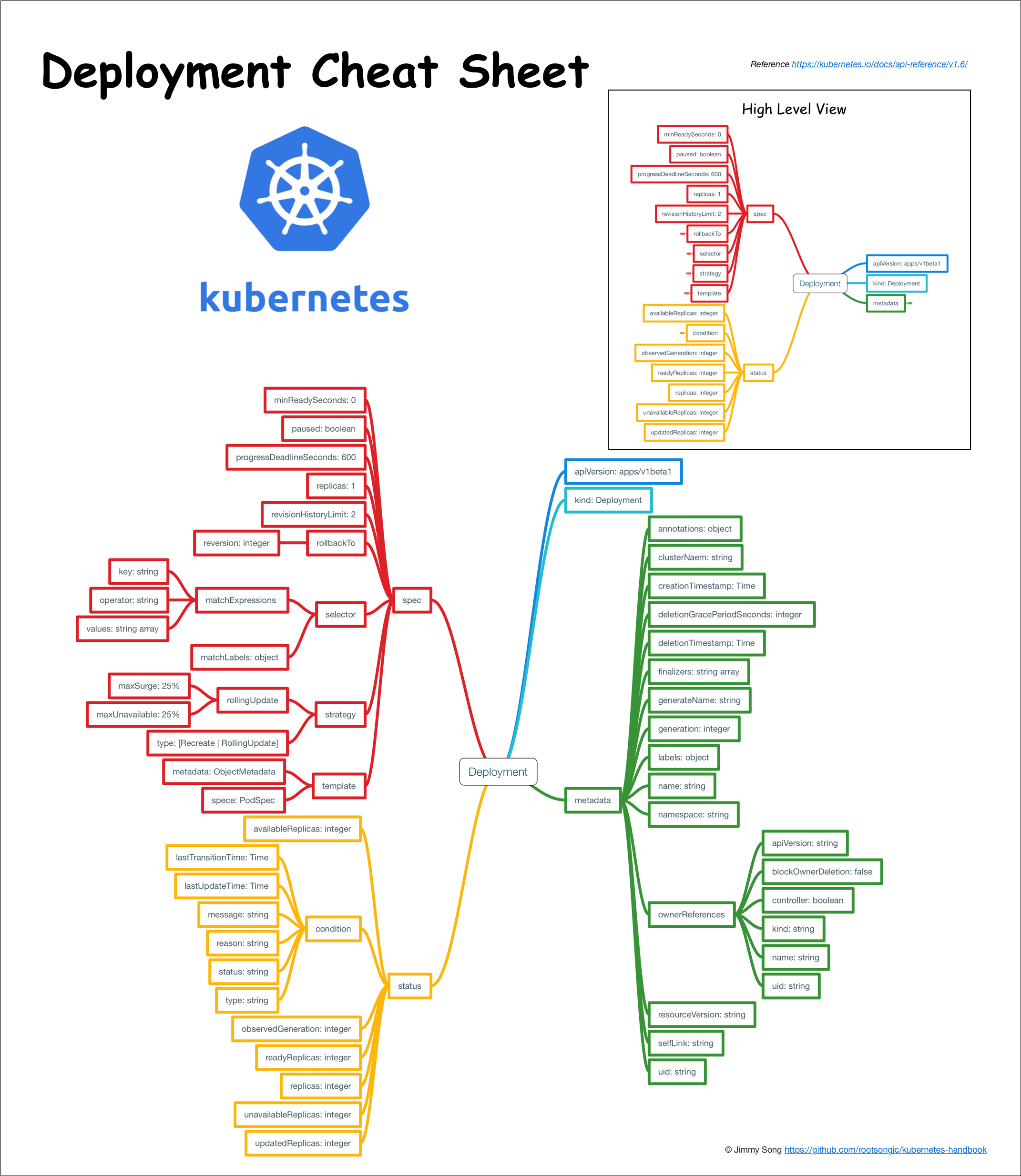
检查Deployment升级的历史记录
检查Deployment的revision:
kubectl rollout history deployment/nginx-deployment
因为我们创建Deployment时使用了—record参数可以记录命令,可以方便查看每次revision的变化。
查看单个revision的信息:
kubectl rollout history deployment/nginx-deployment --revision=2
回退到历史版本
回退到当前的rollout之前的版本:
kubectl rollout undo deployment/nginx-deployment
也可以使用—revision参数指定某个历史版本:
kubectl rollout undo deployment/nginx-deployment --to-revison=2
Deployment扩容
扩容Deployment:
kubectl scale deployment nginx-deployment --replicas 10
启用Horizontal pod autoscaling:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
删除autoscale
kubectl get hpa
kubectl delete hpa ${name of hpa}
暂停和恢复Deployment
暂停Deployment:
kubectl rollout pause deployment/nginx-deployment
恢复Deployment:
kubectl rollout resume deploy nginx
3.6.2 StatefulSet
StatefulSet作为Controller为Pod提供唯一的标识。它可以保证部署和scale的顺序。
StatefulSet是为了解决有状态服务的问题,应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展时要依据定义的顺序依次进行,基于init Container来实现
- 有序收缩,有序删除
StatefulSet由以下几个部分组成:
- 用于定义网络标志(DNS Domain)的Headless Service
- 用于创建PersistentVolumes的volumeClaimTemplates
- 定义具体应用的StatefulSet
StatefulSet中每个Pod的DNS格式为statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.local,其中:
- serviceName为Headless Service的名字
- 0..N-1为Pod所在的序号,从0开始到N-1
- statefulSetName为StatefulSet的名字
- namespace为服务所在的namespace,Headless Service和StatefulSet必须在相同的namespace
- .cluster.local为Cluster Domain
其他操作:
#扩容
kubectl scale statefulset web --replicas=5
#缩容
kubectl patch statefulset web -p '{"spec":{"replicas":3}}'
#删除statefulset和Headless Service
kubectl delete statefulset web
kubectl delete service nginx
#StatefulSet删除后PVC还会保留,数据不再时也需要删除
kubectl delete pvc www-web-0 www-web-1
集群外部访问StatefulSet的Pod
方法是为Pod设置Label,然后用kubectl expose 将其以NodePort方式暴露到集群外部。
以下使用命令方式来暴露其中的两个zookeeper节点:
kubectl label pod zk-0 zkInst=0
kubectl label pod zk-1 zkInst=1
kubectl expose po zk-0 --port=2181 --target-port=2181 --name=zk-0 --selector=zkInst=0 --type=NodePort
kubectl expoer po zk-1 --port=2181 --target-port=2181 --name=zk-1 --selector=zkInst=1 --type=NodePort
这样在Kubernetes集群外部就可以根据Pod所在主机所映射的端口来访问了。
3.6.3 DaemonSet
什么是DaemonSet?
DaemonSet确保全部(或者一些)Node上运行一个Pod的副本。
当有Node加入到集群时,也会为他们新增一个Pod。
当有Node从集群移除时,这些Pod也会被回收。
删除DaemonSet将会删除它创建的所有Pod。
使用DaemonSet的一些典型用法:
- 运行集群存储daemon,例如在每个Node上运行glusterd、ceph。
- 在每个Node上运行日志收集daemon,例如fluentd、logstash。
- 在每个Node上运行监控daemon,例如Prometheus Node Exporter、collectd、Datalog代理、New Relic代理,或者Ganglia gmond。
3.6.4 ReplicaitonController和ReplicationSet
3.6.5 Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Job Spec格式
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
一个例子:
more job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl","-Mbignum=bpi","-wle","print bpi(2000)"]
restartPolicy: Never
3.6.6 CronJob
CronJob管理基于时间的Job,即:
- 在给定时间点只运行一次
- 周期性的在给定时间点运行
一个示例:
more cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date;echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
3.6.7 Horizontal Pod Autoscaling
HPA解析
HPA仅适用于Deployment和ReplicaSet。
HPA由API Server和controller共同实现。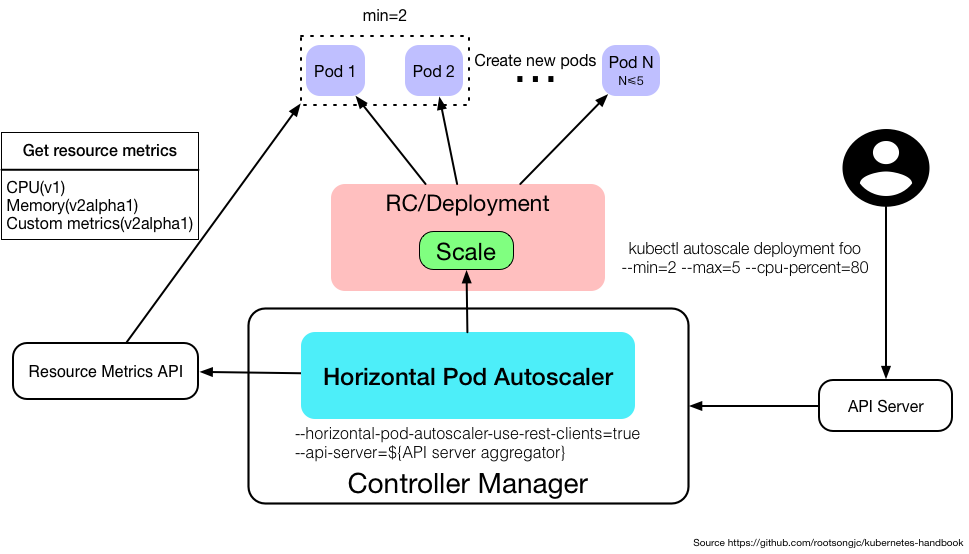
Metrics支持
在不同的API版本中,HPA autoscale时可以根据以下指标来判断:
autoscaling/v1
•CPU
autoscaling/v1alpha1
•内存
•自定义metrics
•多种metrics组合
HPA会根据每个metric的值计算出scale的值,并将最大的那个值作为扩容的最终结果。
使用kubectl管理
kubectl create hpa
kubectl get hpa
kubectl describe hpa
kubectl delete hpa
举个栗子🌰:
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
Horizontal Pod AutoScaler如何工作?
HPA由一个控制循环实现,循环周期由Controller manager中的—horizontal-pod-autoscaler-sync-period标志指定(默认为30秒)。
在每个周期内,Controller manager会查询HPA中定义的metric的资源利用率。
Controller manager从resource metric API或者自定义metric API中获取metric。
HPA控制器可以以两种不同的方式获取metric:直接的Heapster访问和REST客户端访问。
当使用直接的Heapster访问时,HPA直接通过API服务器的代理子资源查询Heapster。
需要在集群中部署Heapster并在kube-system namespace中运行。
AutoScaler访问相应的Replication Controller、Deployment、ReplicaSet来缩放子资源。
Scale是一个允许您动态设置副本数并检查其当前状态的接口。
API Object
HPA是kubernetes的autoscaling API组中的API资源。
3.6.8 准入控制器(Admission Controller)
准入控制器位于API Server中,在对象被持久化之前,准入控制器拦截对API Server的请求,一般用来做身份验证和授权。
其中包含两个特殊的控制器:MutaingAdmissionWebhook和ValidatingAdmissionWebhook。分别作为配置的变更和验证准入控制的webhook。
变更准入控制:修改请求的对象
验证准入控制:验证请求的对象
当请求到达API Server时首先执行变更准入控制,然后再执行验证准入控制。
可以默认开启如下准入控制器:
--admission-control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota,MutaingAdmissionWebhook,ValidatingAdmissionWebhook
准入控制器列表
Kubernetes 目前支持的准入控制器有:
- AlwaysPullImages:此准入控制器修改每个 Pod 的时候都强制重新拉取镜像。
- DefaultStorageClass:此准入控制器观察创建
PersistentVolumeClaim时不请求任何特定存储类的对象,并自动向其添加默认存储类。这样,用户就不需要关注特殊存储类而获得默认存储类。 - DefaultTolerationSeconds:此准入控制器将Pod的容忍时间
notready:NoExecute和unreachable:NoExecute默认设置为5分钟。 - DenyEscalatingExec:此准入控制器将拒绝
exec和附加命令到以允许访问宿主机的升级了权限运行的pod。 - EventRateLimit (alpha):此准入控制器缓解了 API Server 被事件请求淹没的问题,限制时间速率。
- ExtendedResourceToleration:此插件有助于创建具有扩展资源的专用节点。
- ImagePolicyWebhook:此准入控制器允许后端判断镜像拉取策略,例如配置镜像仓库的密钥。
- Initializers (alpha):Pod初始化的准入控制器,详情请参考动态准入控制。
- LimitPodHardAntiAffinityTopology:此准入控制器拒绝任何在
requiredDuringSchedulingRequiredDuringExecution的AntiAffinity字段中定义除了kubernetes.io/hostname之外的拓扑关键字的 pod 。 - LimitRanger:此准入控制器将确保所有资源请求不会超过 namespace 的
LimitRange。 - MutatingAdmissionWebhook (1.9版本中为beta):该准入控制器调用与请求匹配的任何变更 webhook。匹配的 webhook是串行调用的;如果需要,每个人都可以修改对象。
- NamespaceAutoProvision:此准入控制器检查命名空间资源上的所有传入请求,并检查引用的命名空间是否存在。如果不存在就创建一个命名空间。
- NamespaceExists:此许可控制器检查除
Namespace其自身之外的命名空间资源上的所有请求。如果请求引用的命名空间不存在,则拒绝该请求。 - NamespaceLifecycle:此准入控制器强制执行正在终止的命令空间中不能创建新对象,并确保
Namespace拒绝不存在的请求。此准入控制器还防止缺失三个系统保留的命名空间default、kube-system、kube-public。 - NodeRestriction:该准入控制器限制了 kubelet 可以修改的
Node和Pod对象。 - OwnerReferencesPermissionEnforcement:此准入控制器保护对
metadata.ownerReferences对象的访问,以便只有对该对象具有“删除”权限的用户才能对其进行更改。 - PodNodeSelector:此准入控制器通过读取命名空间注释和全局配置来限制可在命名空间内使用的节点选择器。
- PodPreset:此准入控制器注入一个pod,其中包含匹配的PodPreset中指定的字段,详细信息见Pod Preset。
- PodSecurityPolicy:此准入控制器用于创建和修改pod,并根据请求的安全上下文和可用的Pod安全策略确定是否应该允许它。
- PodTolerationRestriction:此准入控制器首先验证容器的容忍度与其命名空间的容忍度之间是否存在冲突,并在存在冲突时拒绝该容器请求。
- Priority:此控制器使用
priorityClassName字段并填充优先级的整数值。如果未找到优先级,则拒绝Pod。 - ResourceQuota:此准入控制器将观察传入请求并确保它不违反命名空间的
ResourceQuota对象中列举的任何约束。 - SecurityContextDeny:此准入控制器将拒绝任何试图设置某些升级的SecurityContext字段的pod 。
- ServiceAccount:此准入控制器实现serviceAccounts的自动化。
- 用中的存储对象保护:该
StorageObjectInUseProtection插件将kubernetes.io/pvc-protection或kubernetes.io/pv-protection终结器添加到新创建的持久卷声明(PVC)或持久卷(PV)。在用户删除PVC或PV的情况下,PVC或PV不会被移除,直到PVC或PV保护控制器从PVC或PV中移除终结器。有关更多详细信息,请参阅使用中的存储对象保护。 - ValidatingAdmissionWebhook(1.8版本中为alpha;1.9版本中为beta):该准入控制器调用与请求匹配的任何验证webhook。匹配的webhooks是并行调用的;如果其中任何一个拒绝请求,则请求失败。
推荐配置
Kubernetes 1.10+
对于Kubernetes 1.10及更高版本,我们建议使用--enable-admission-plugins标志运行以下一组准入控制器(顺序无关紧要)。
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota

若有收获,就点个赞吧
0 人点赞
