回顾
上文我们介绍了 VSCode 进行代码重构的大体逻辑,
内置的 TypeScript 插件(typescript-language-features)响应快捷键后,发消息给 tsserver,
tsserver 计算重构后的结果并返回,最后展示在编辑器中。
颇费篇幅的是 vscode 和 typescript 的调试配置。
包括如何调试 VSCode 内置插件,如何 attach 到 tsserver 进程,
如何让 VSCode 调用指定版本的 TypeScript 源码(需要 source map)。
代码调通后,剩下的工作就会变得简单许多了。
本文重点研究 tsserver 的重构过程,看看它是怎样计算得到重构结果的。
1. 找到相关的 refactor
接上一篇文章,我们打开了两个 VSCode 实例,
一个用于启动 TypeScript 插件(typescript-language-features),
另一个用于 attach 到 tsserver。
启动 TypeScript 插件(typescript-language-features)后,
VSCode 会弹出一个新的名为 [Extension Development Host] 的窗口,
在这个窗口中,打开一个 .ts 文件,对它执行重构。
选中 x, y,按 ⌘ + .,选择 Extract to function in global scope。
const f = x => {x, y};
重构结果为,
const f = x => {newFunction(x);};function newFunction(x: any) {x, y;}
下图为 tsserver 执行重构前的断点位置,
位于 getEditsForRefactor src/services/refactorProvider.ts#L35 函数中,
export function getEditsForRefactor(context: RefactorContext, refactorName: string, actionName: string): RefactorEditInfo | undefined {const refactor = refactors.get(refactorName);return refactor && refactor.getEditsForAction(context, actionName);}
它首先根据 refactorName 拿到了相关的 refactor,
然后再调用这个 refactor 的 getEditsForAction 方法,得到重构结果。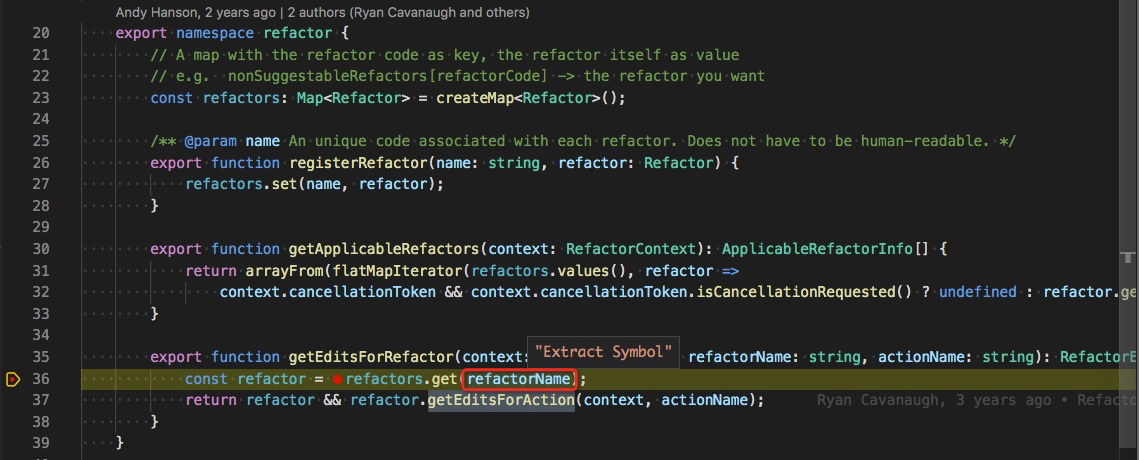
我们选择的是 Extract to function in global scope 重构方式,对应的 refactorName 为 Extract Symbol。
单步调试,进入到 refactor.getEditsForAction 函数中,位于 src/services/refactors/extractSymbol.ts#L89。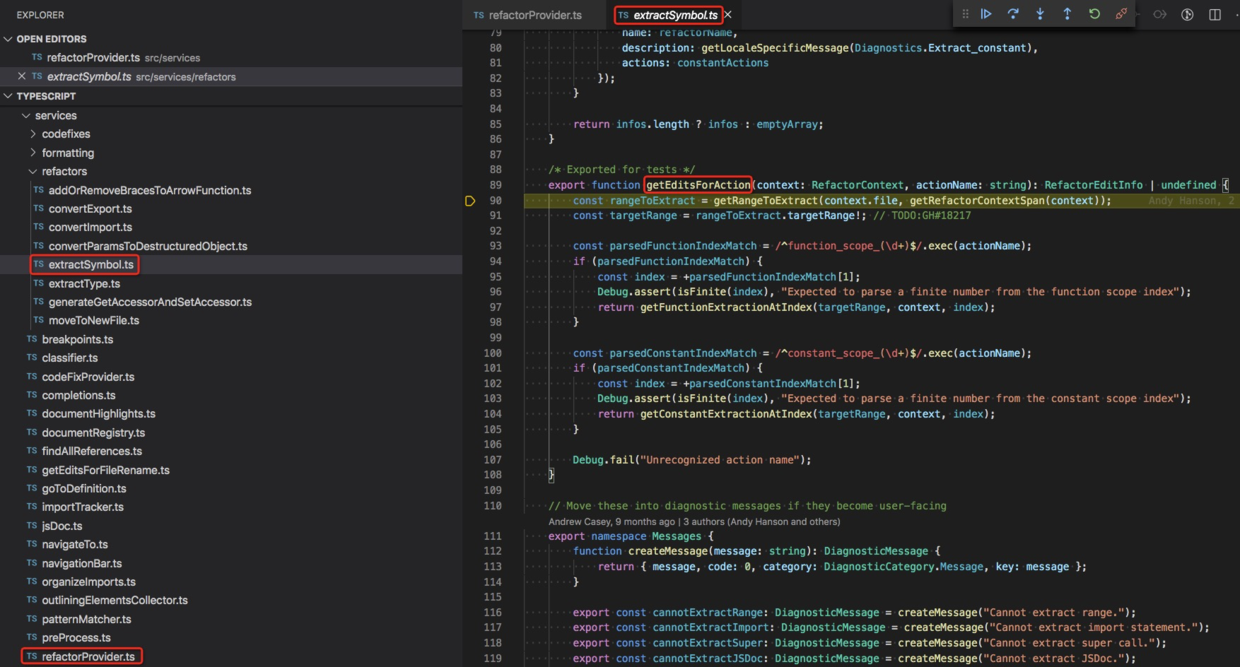
这就进到了 extractSymbol 这个 refactor 中,
仔细观察一下,src/services/refactors/ 这个文件夹包含了 8 个 refactor。
每个 refactor 的代码结构都是类似的,
/* @internal */namespace ts.refactor.xxx {const refactorName = "xxx";registerRefactor(refactorName, { getAvailableActions, getEditsForAction });function getAvailableActions(context: RefactorContext): readonly ApplicableRefactorInfo[] { }function getEditsForAction(context: RefactorContext, actionName: string): RefactorEditInfo | undefined { }}
都是调用了 ts.refactor namespace 中的 registerRefactor 进行注册。
传入了 getAvailableActions(有哪些重构方式) 和 getEditsForAction(计算特定的重构结果) 两个方法。
其中,registerRefactor,位于 src/services/refactorProvider.ts#L26,
namespace ts {...export namespace refactor {...export function registerRefactor(name: string, refactor: Refactor) {refactors.set(name, refactor);}...}...}
2. extractSymbol refactor 全流程
知道了 refactor 的代码结构之后,我们言归正传,来看当前用到的 extractSymbol 这个 refactor。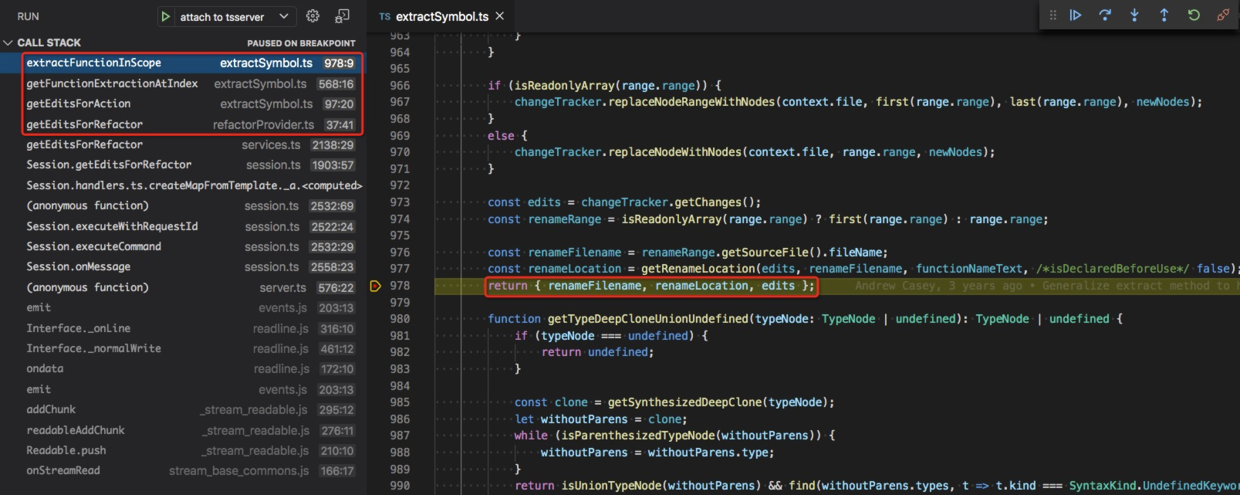
仔细阅读代码之后,我直接将断点停在了重构结果返回的位置,
位于 extractFunctionInScope 函数中 src/services/refactors/extractSymbol.ts#L978,有 282 行。
过程中重点调用的函数总结如下,
refactor.getEditsForActiongetFunctionExtractionAtIndex# 分析上下文信息getPossibleExtractionsWorker# 计算作用域信息collectEnclosingScopes# 计算 usage 信息,以确定参数列表collectReadsAndWrites# 提取函数extractFunctionInScope# 在全局作用域创建一个函数声明createIdentifiercreateParametertransformFunctionBodycreateFunctionDeclarationchangeTracker.insertNodeAtEndOfScope# 在原位置创建一个函数调用createCallcreateStatementchangeTracker.replaceNodeRangeWithNodes# 获取所有的修改changeTracker.getChanges
我们发现这个流程还是挺复杂的,并且没有采用拼字符串的方式生成代码,
而是使用了创建 ast 节点的工厂方法(createXXX),
这些工厂方法都集中放在了 src/compiler/factory.ts 文件中,有 5547 行。
值得一提的是,changeTracker.getChanges 的返回值 edits 有一个坑。
从 VSCode 的表现来看,Extract to function in global scope 会产生两个 changes,
一个是在全局作用域创建函数声明,另一个是在原位置创建一个函数调用。
它们都应该反映在 changeTracker.getChanges 的返回值 edits 中。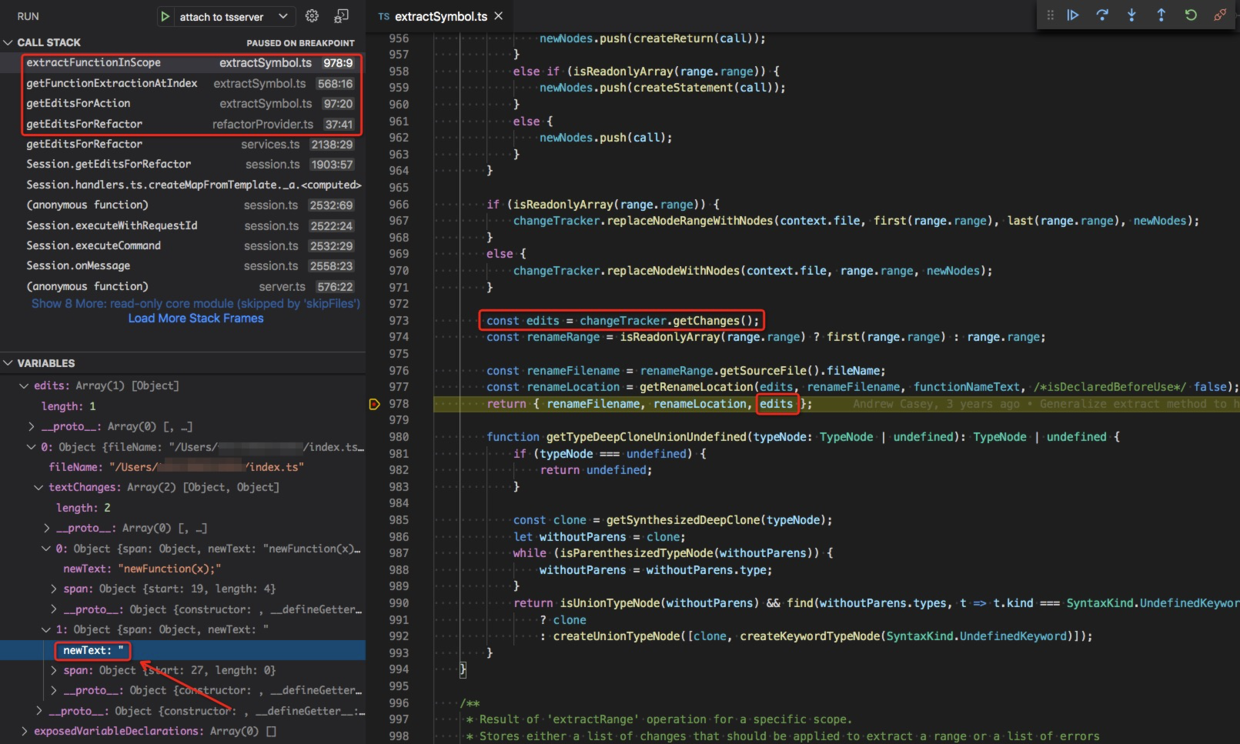
edits[0].textChanges[1].newText 其实是多行文本,
但由于 VSCode 调试面板只能展示第一行,就看起来这个 newText 只是一个空字符串了。
我们在 DEBUG CONSOLE 中展示一下 edits 的内容,就看到换行符了。
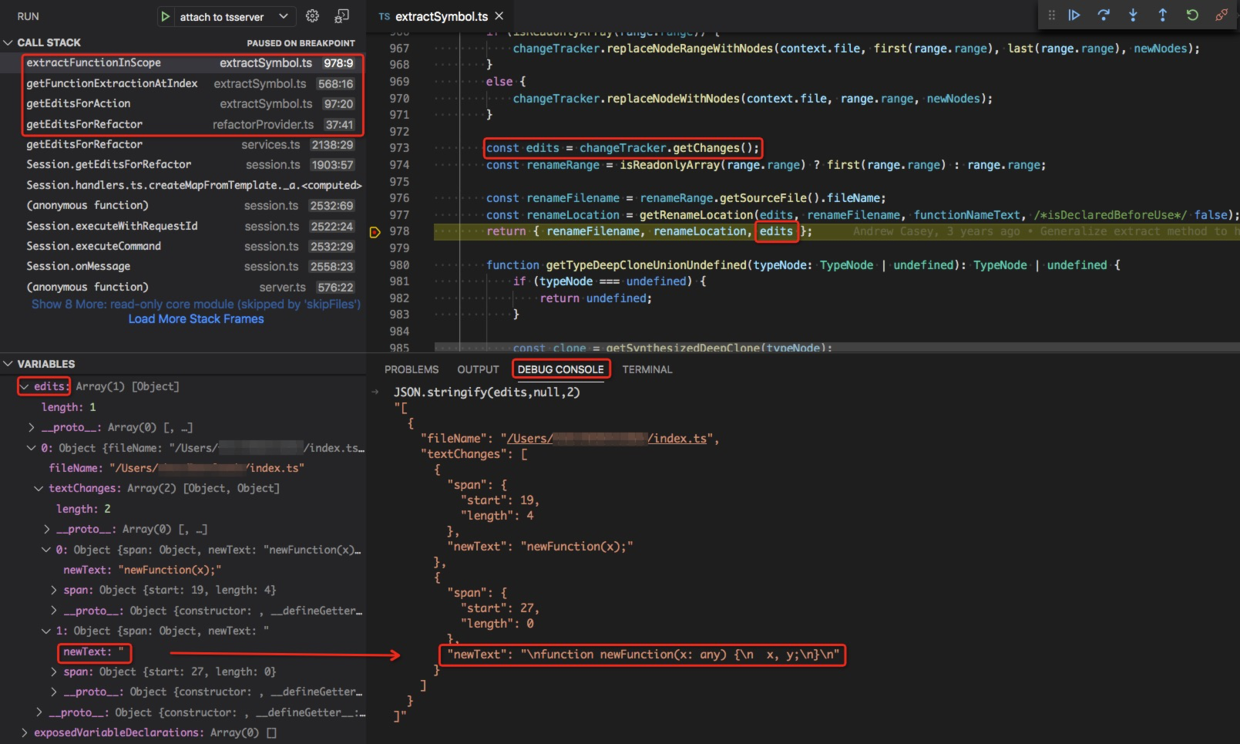
[{"fileName": "/Users/.../index.ts","textChanges": [{"span": {"start": 19,"length": 4},"newText": "newFunction(x);"},{"span": {"start": 27,"length": 0},"newText": "\nfunction newFunction(x: any) {\n x, y;\n}\n"}]}]
最后,回顾整个重构过程,getPossibleExtractionsWorker 对上下文进行分析,
得到了作用域信息,usage 信息,我觉得反而是最值得研究的环节,
只有拿到了这些信息,提取函数才有据可依。
3. 详解:上下文分析
getPossibleExtractionsWorker 位于 src/services/refactors/extractSymbol.ts#L644,
function getPossibleExtractionsWorker(...): ... {...const scopes = collectEnclosingScopes(targetRange);...const readsAndWrites = collectReadsAndWrites(...);return { scopes, readsAndWrites };}
它返回了两个变量 scopes 和 readsAndWrites。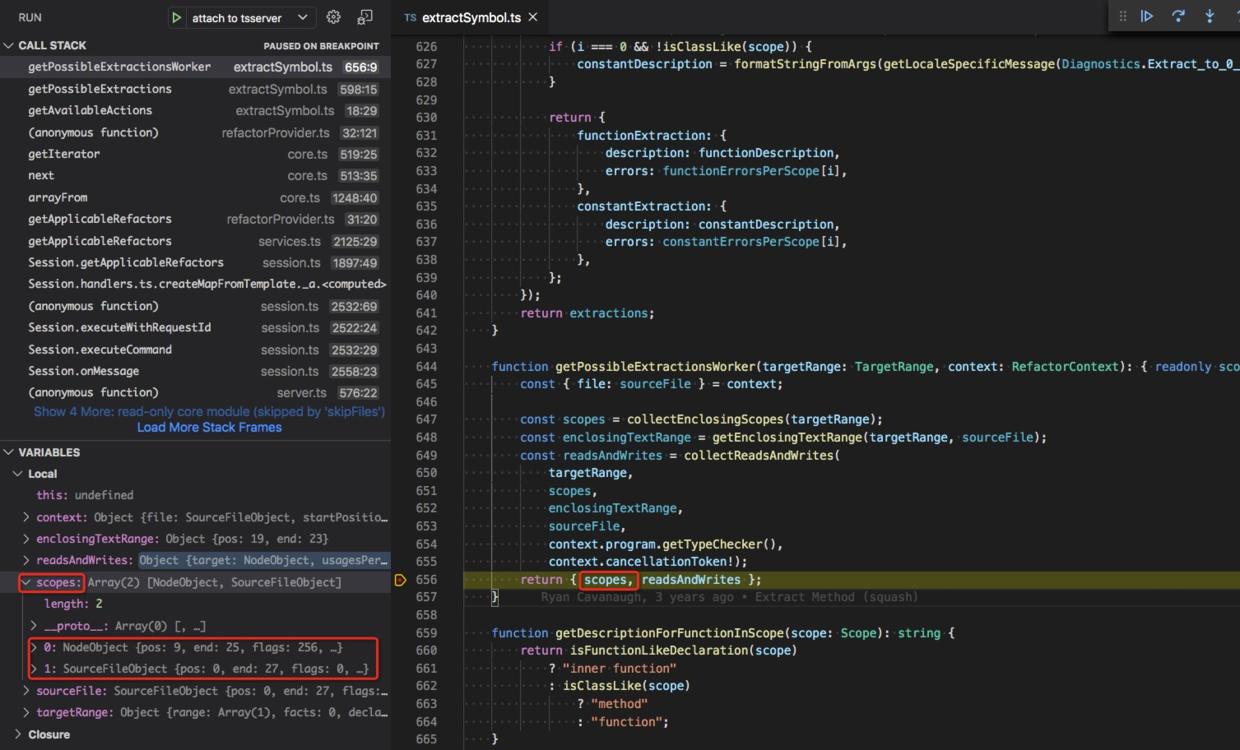
3.1 collectEnclosingScopes
我们对着代码来说,
const f = x => {x, y};
scopes 是一个数组,包含了两个节点,
第一个元素是函数 f 的定义,第二个元素是 sourceFile。
也就是从选中的待提取为函数的代码 x, y 来看,它包含在这样两个作用域(ast 节点)中。
它是怎么知道是这两个节点呢?
这还要看 collectEnclosingScopes 的代码 src/services/refactors/extractSymbol.ts#L528,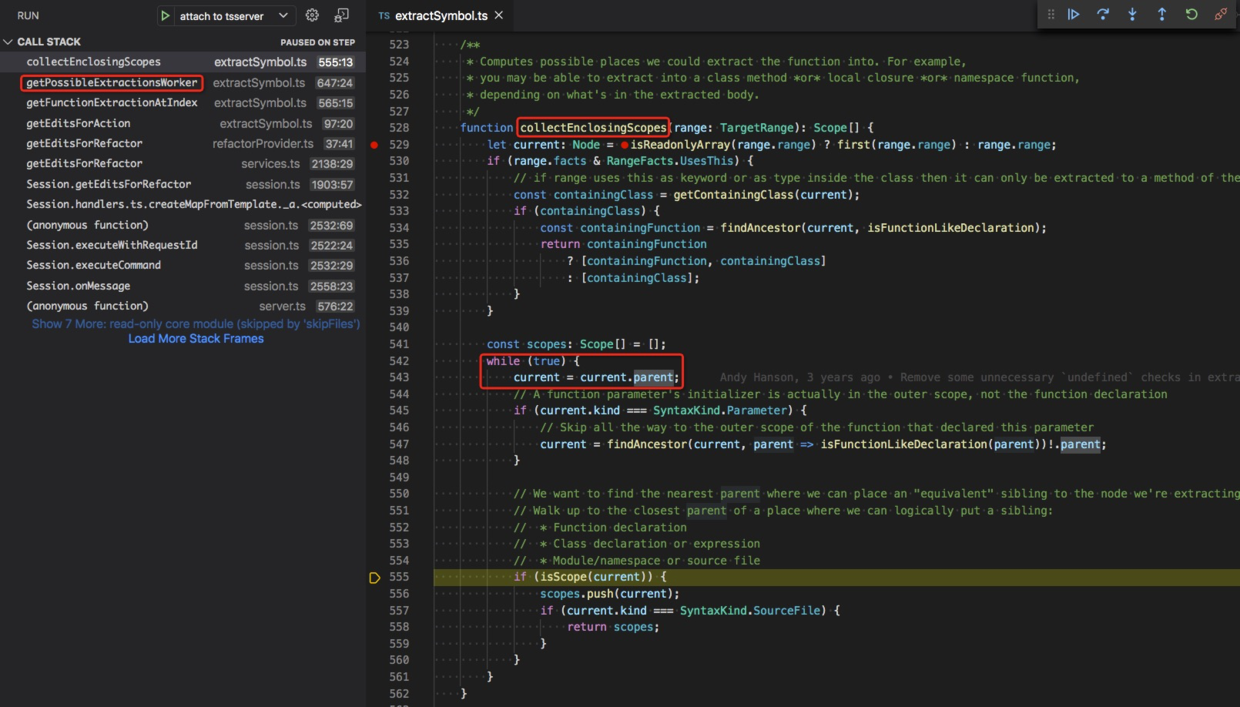
function collectEnclosingScopes(range: TargetRange): Scope[] {...const scopes: Scope[] = [];while (true) {current = current.parent;...if (isScope(current)) {scopes.push(current);if (current.kind === SyntaxKind.SourceFile) {return scopes;}}}}
它会从当前节点位置,循环往上查找父节点 current.parent,识别每个是作用域边界(isScope )的节点,
isScope,src/services/refactors/extractSymbol.ts#L519,
function isScope(node: Node): node is Scope {return isFunctionLikeDeclaration(node) || isSourceFile(node) || isModuleBlock(node) || isClassLike(node);}
3.2 collectReadsAndWrites
usage 信息就略微复杂一些了,collectReadsAndWrites 位于 src/services/refactors/extractSymbol.ts#L1451,有 367 行。
它不止返回了 usage 信息,从返回类型上,我们看到还包含这些信息,ReadsAndWrites,src/services/refactors/extractSymbol.ts#L1444
interface ReadsAndWrites {readonly target: Expression | Block;readonly usagesPerScope: readonly ScopeUsages[];readonly functionErrorsPerScope: readonly (readonly Diagnostic[])[];readonly constantErrorsPerScope: readonly (readonly Diagnostic[])[];readonly exposedVariableDeclarations: readonly VariableDeclaration[];}
我们只看 usagesPerScope。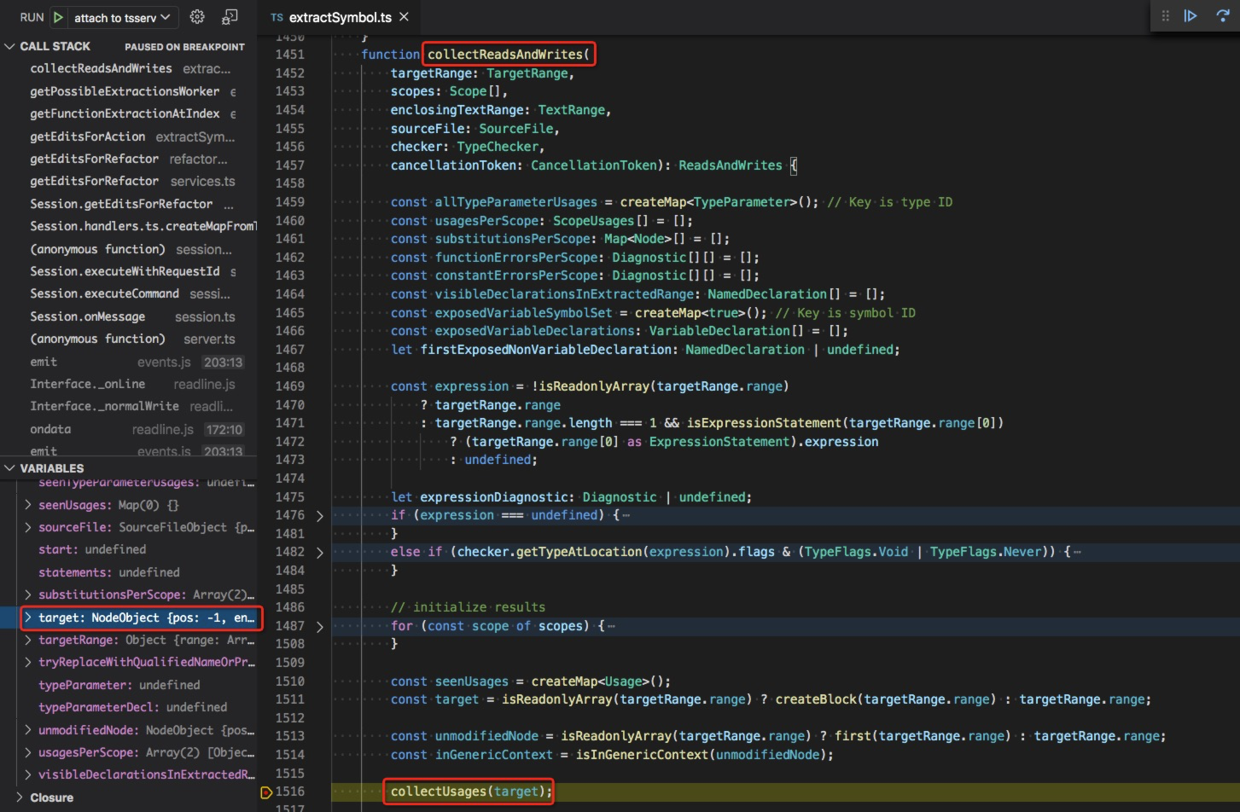
collectReadsAndWrites 创建了一个临时节点 target,然后调用 collectUsages 来分析 usage 情况。
我们看到 target.statements[0].expression.left 和 target.statements[0].expression.right,
刚好是我们选中的代码 x, y(逗号表达式)的逗号分隔的两个部分 x,y。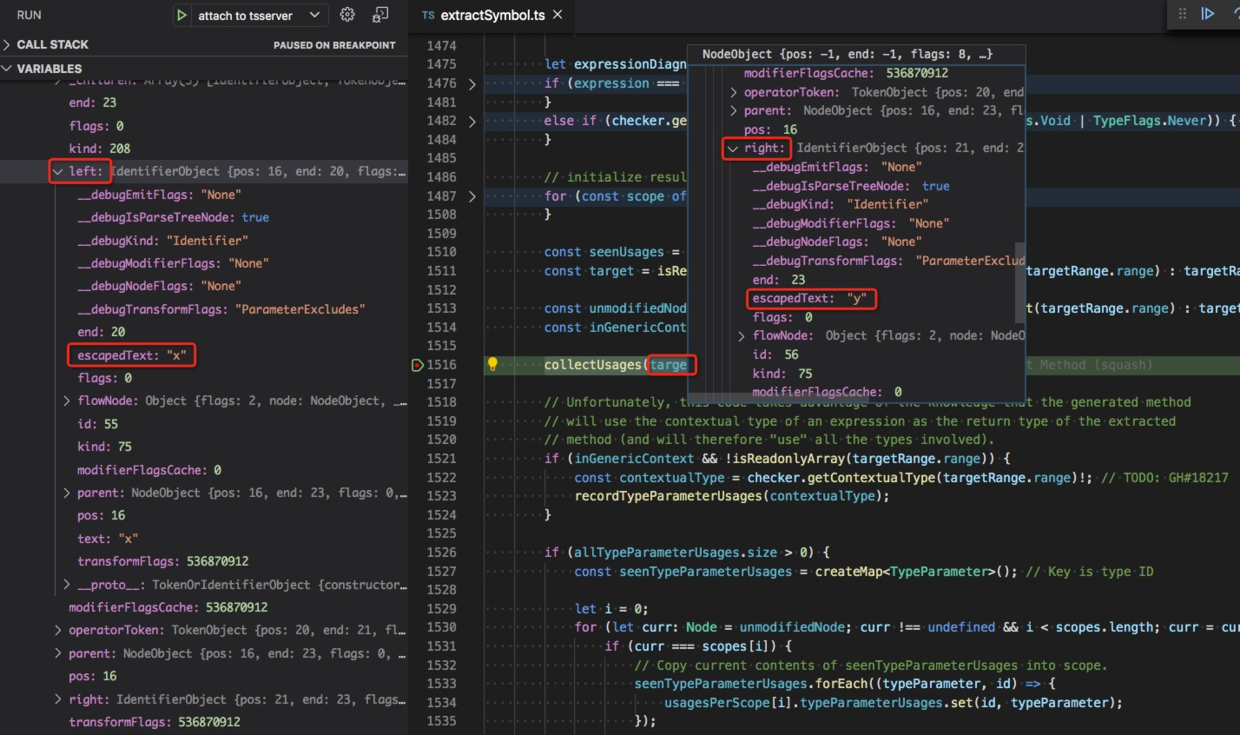
接着我们来看 collectUsages 函数,src/services/refactors/extractSymbol.ts#L1629
它会遍历临时创建的那个节点 target,然后计算 recordUsage 每个标识符的 usage 信息。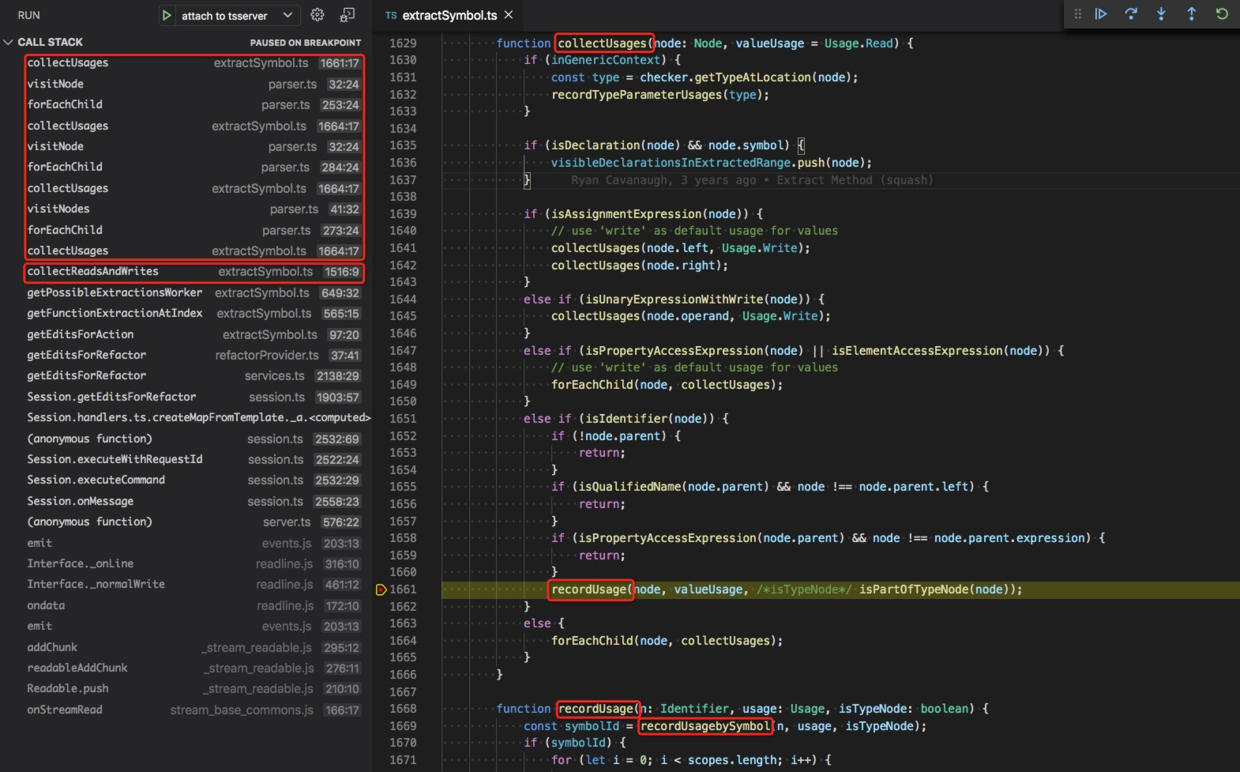
recordUsage 位于 src/services/refactors/extractSymbol.ts#L1668
function recordUsage(n: Identifier, usage: Usage, isTypeNode: boolean) {const symbolId = recordUsagebySymbol(n, usage, isTypeNode);...}
正是第一行的 recordUsagebySymbol 函数 src/services/refactors/extractSymbol.ts#L1681 计算了 usage 信息。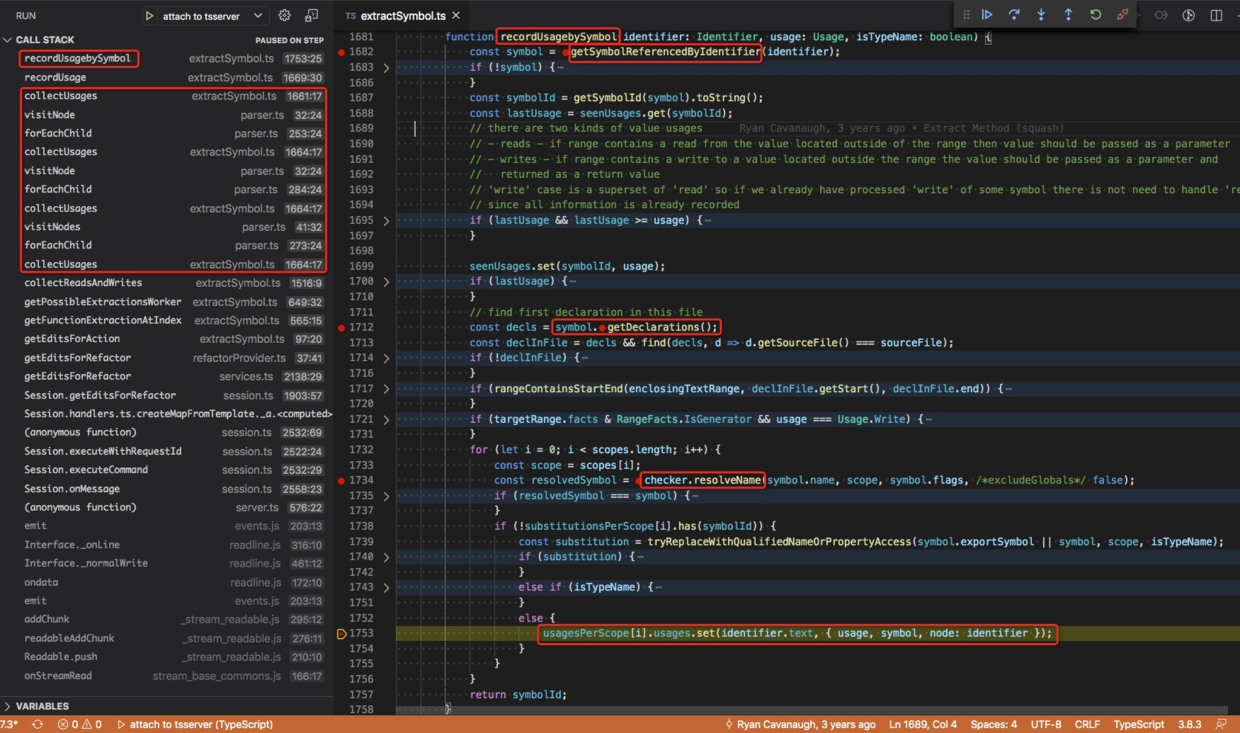
结合重构前的代码来看,
const f = x => {x, y};
recordUsagebySymbol 函数中,有几个地方值得注意,
getSymbolReferencedByIdentifier:获取与标识符(ast 节点)对应的 symbol 对象。symbol.getDeclarations:获取 symbol 的定义节点,例如x这个符号是函数的形参,所以定义位置就是形参节点(ast 节点)。checker.resolveName:在函数f作用域下,找一下变量名x,能找到就会返回 symbol。
对于 y 来说,getSymbolReferencedByIdentifier 直接返回 undefined,
自然就不会加入 usage 了。
最终得到的 ussage 信息如下,x 是有 usage 的,它引用了函数 f 形参定义的符号,
而 y 则没有 usage 信息。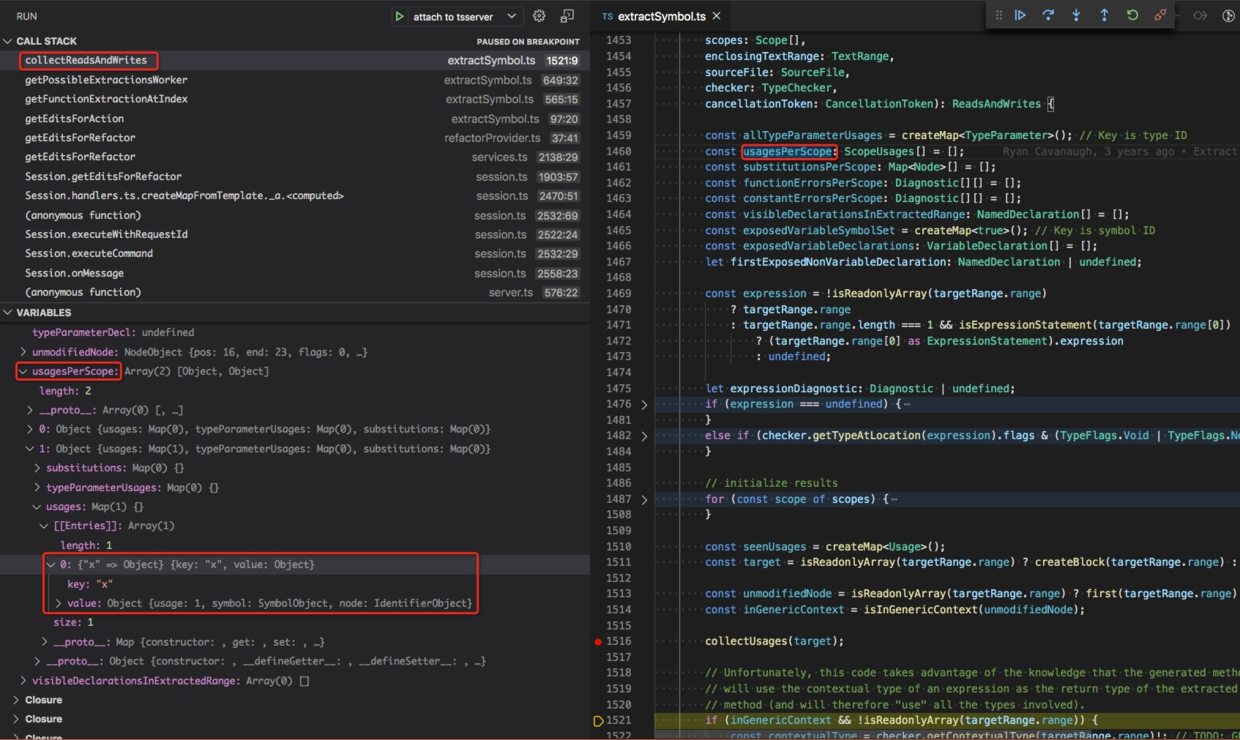
4. 总结
本文分析了 tsserver 计算重构结果的过程,主要包含两个步骤,
getPossibleExtractionsWorker:分析上下文信息(获得 scope 和 usage 信息)extractFunctionInScope:提取函数(利用工厂函数创造 ast 节点)
其中,第一步需要对 ast 进行语义分析,第二步需要对工厂函数较为熟悉才可以。
因此 tsserver 重构完全是基于 ast 和语义的,能更好的理解上下文。
代码重构这些内容,值得投入些时间来学习。
参考

若有收获,就点个赞吧
0 人点赞
