前言
随着互联网技术的高速发展,信息的高效传播,业务需求的变化越来越快,这对软件开发的交付速度要求是越来越高的,甚至要达到持续交付的程度。在这种敏捷开发模式在整个开发团队里面运用得越来越多,运维们也开始高举DevOps、AIOps的大旗,作为软件开发环节中保证软件交付质量最重要的一环的测试,也不能再安逸于用例设计和简单的手工测试了,必须加快测试的速度,提高自己的交付能力了。而要提高测试速度,甚至做到持续测试,自动化就是其中最关键的一步了。<br /> 现在要谈起web UI自动化,就不可能不提到近几年一直占据自动化测试工具排行榜首位的Selenium了。本书将使用目前最新版本的Selenium 3进行介绍(据官方介绍Selenium 4将在今年-2019年圣诞节发布,敬请期待),从最基本的Selenium3的介绍、基本原理、元素定位、元素操作开始介绍,从零基础开始带大家深入了解Selenium 3,了解WebDriver。<br /> 这个版本是基于使用频率最高,大家可能也听得最多的语言Java来介绍的,Python版也会做同步更新。<br /> Python版访问地址:[https://www.yuque.com/testops/afopxn/xptgoz](https://www.yuque.com/testops/afopxn/xptgoz)
补充说明
本文是以前百度阅读的2017年左右的原文,所有部分内容会比较老,这里会根据情况对当前主流变化做一些同步更新。
https://yuedu.baidu.com/book/new?book_id=0f80a8bd67ec102de3bd8960
Selenium 3介绍
一晃从selenium1到selenium3已经10个多年头过去了,2016年10月selenium3.0正式发布,最新版本为3.0.1,主要的变化在:
1. JDK1.8的支持
2. RC模块的删除
3. 对Firefox浏览器使用第三方扩展,支持FireFoxgeckodriver
4. 最低支持IE9
从2017年开始,云层基于米阳和张飞老师的Webdriver体系编写基于JAVA基本文档。
环境安装可以参考
https://ke.qq.com/course/236848
如果需要课程视频可以参考
https://www.bilibili.com/video/av92553814
环境部署
本书将主要使用JAVA语言来作为脚本开发语言,所以JAVA环境安装如下。
http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
在Oracle官方下载对应的JDK,推荐大家使用64位操作系统,本书以Win7 64位操作系统为基础。
注:从JDK1.8开始无需配置环境变量。
Intellij IDEA
本次书将使用Intellij IDEA来做为开发工具,相对Eclipse在很多地方会有较好的优化。
http://www.jetbrains.com/idea/
浏览器驱动
从Selenium3.0开始,其自身已经不带浏览器驱动了,不能使用默认的Firefox直接启动浏览器了,所有的浏览器都需要安装驱动。
去Selenium官方网站可以下载得到所需要驱动的各种浏览器扩展,将这些驱动保存在环境路径中就可以在代码中正常驱动浏览器启动。
Chrome驱动
https://sites.google.com/a/chromium.org/chromedriver/downloads
国内镜像可以查询
http://npm.taobao.org/mirrors/chromedriver/
下载对应的版本后可以保存chromedirver.exe到system32目录下或者path路径下,方便自动寻找驱动。
截止到本文更新的最后时间2019-10-8,最新的版本为78.0.3904.11
新建Selenium3.0项目
启动IDEA,选择新建一个maven项目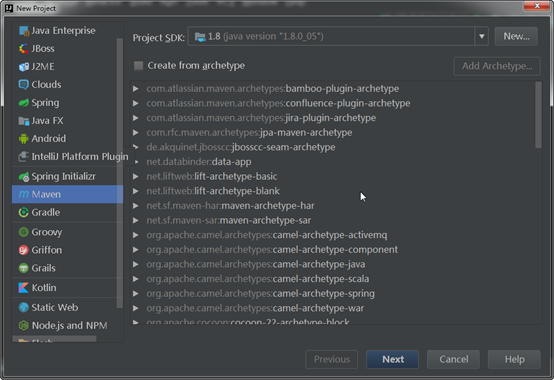
Next,然后配置项目信息
GroupID就和Package的作用相同,ArtifactId是用来做项目名称的,Next下一步。
这里确定项目信息,完成项目新建。
Maven
Maven的基础是POM.xml,新建Maven项目后需要选择 EnableAuto-Import,允许启动导入。
接着找到Maven的公开仓库http://mvnrepository.com,并且获得Selenium3.0的更新信息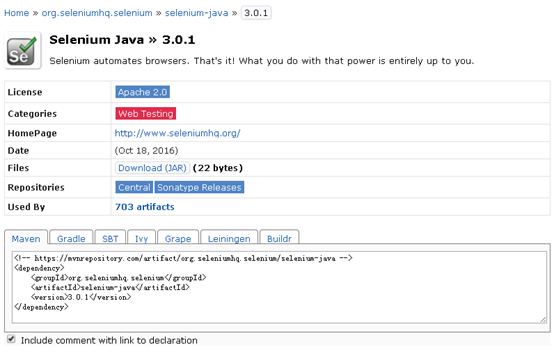
在这里把Maven的信息复制下来,回到Pom.xml文件中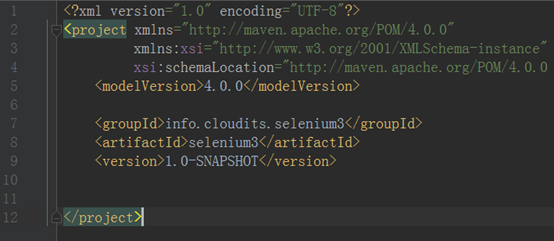
在project标签中添加
由于前面启动了自动更新,所以Maven会自动去远程下载Selenium3.0.1的Jar包来支撑该Jave项目。
在右侧的Maven Project中,当更新完成,Dependencies下就会出现对应的依赖库
启动Chrome浏览器
在项目的java目录下选择右键新建一个Java Class
接着在新建的Borwse类中新建一个主方法,代码如下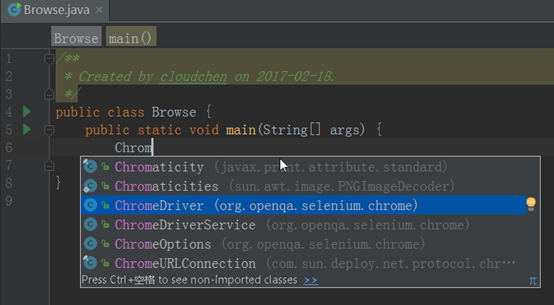
输入Chrom可以看到对应的驱动,我们这里需要新建ChromeDriver驱动。
使用navigate().to()方法来启动浏览器。
右键运行,即可看到Chrome浏览器被启动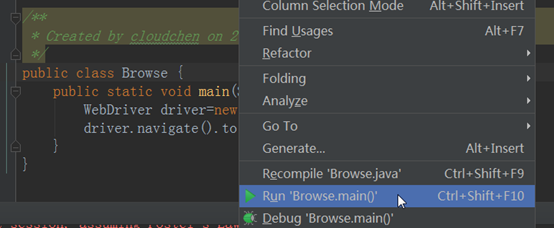
可以参考的入门视频
https://v.qq.com/x/page/v0544e7xubo.html
源代码Github地址
Selenium3.0的源代码均会在Github上提供,访问地址
https://github.com/cloudits/selenium3.0
基本对象识别和对象操作
Xpath定位
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 |
bookstore
子元素的第一个
book
元素。 |
| /bookstore/book[last()] | 选取属于
bookstore
子元素的最后一个
book
元素。 |
| /bookstore/book[last()-1] | 选取属于
bookstore
子元素的倒数第二个
book
元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于
bookstore
元素的子元素的
book
元素。 |
| //title[@lang] | 选取所有拥有名为
lang
的属性的
title
元素。 |
| //title[@lang='eng'] | 选取所有
title
元素,且这些元素拥有值为
eng
的
lang
属性。 |
| /bookstore/book[price>35.00] | 选取
bookstore
元素的所有
book
元素,且其中的
price
元素的值须大于
35.00。 |
| /bookstore/book[price>35.00]/title | 选取
bookstore
元素中的
book
元素的所有
title
元素,且其中的
price
元素的值须大于
35.00。 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| fn:contains(string1,string2) | 如果 string1
包含 string2,则返回
true,否则返回 false。
例子:contains(‘XML’,’XM’)
结果:true |
| fn:starts-with(string1,string2) | 如果 string1
以 string2 开始,则返回
true,否则返回 false。
例子:starts-with(‘XML’,’X’)
结果:true |
| fn:ends-with(string1,string2) | 如果 string1
以 string2 结尾,则返回
true,否则返回 false。
例子:ends-with(‘XML’,’X’)
结果:false |
| fn:matches(string,pattern) | 如果 string
参数匹配指定的模式,则返回
true,否则返回 false。
例子:matches(“Merano”,
“ran”)
结果:true |
CSS定位

对象操作
driver.findElement(By.xpath(“.//[@id=’kw’]”)).sendkey();
driver.findElement(By.xpath(“.//[@id=’kw’]”)).click();
TestNG框架
在前面有了基本的访问及操作后,先暂停一下对特殊对象的访问及处理机制,接着先来解决一下测试框架的问题。
何为测试框架,简单说就是将测试脚本合理的管理并方便的组织,这样在执行测试的时候可以独立、高效、方便的运行。
载入TestNG
由于使用maven,所以加载TestNG只需要在pom.xml中添加对应的依赖说明即可。
新建TestNG用例1
使用TestNG的主要目的就是将测试代码与被测代码隔离,并且提供独立的运行及断言、报告体系。
在test目录下的java目录中新建一个类testSelenium
@Test用例注解
TestNG的测试类和普通类的主要区别在于注解,这里我们先新建一个标准的注解用例,关键字@Test
import org.testng.annotations.Test;
/
Created by cloudchen on 2017-06-30.
/
public class testSelenium {
@Test
public void mycase1()
{
}
}
在TestNG的测试方法中必须使用@Test开头,并且是一个void的无返回方法。接着在这个方法中编写需要访问的代码。
这里我直接将实战百度搜索的代码完整的粘贴进来。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.annotations.Test;
/
Created by cloudchen on 2017-06-30.
/
public class testSelenium {
static WebDriver driver;
@Test
public void mycase1()
{
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.get(“http://www.baidu.com“);
WebElement element_searchtext;
element_searchtext=driver.findElement(By.xpath(“.//[@id=’kw’]”));//百度搜索框
element_searchtext.sendKeys(“云层”);
WebElement element_searchbutton;
element_searchbutton=driver.findElement(By.xpath(“.//[@id=’su’]”));//百度搜索按钮
element_searchbutton.click();
try {
Thread.sleep(3000);//线程等待3秒,不推荐用,暂时这里为了效果
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement element_searchresult;//由于搜索有时候要一些时间,为了避免出现由于没有刷新导致的对象访问不到,所以这里加入了线程等待
element_searchresult=driver.findElement(By.xpath(“.//[@id=’container’]/div[2]/div/div[2]”));//搜索结果匹配记录的区域定位
System.out.println(element_searchresult.getText());//输出搜索结果
}
}
看起来似乎和以前的写法没有什么区别,右键菜单,试着点击Run mycase1()运行一下,会发现这个时候的运行已经不是走Java的基本主方法运行了,而是走TestNG的运行体系了。
在运行完成后会出现TestNG的执行结果说明,并且提供了导出报告的功能。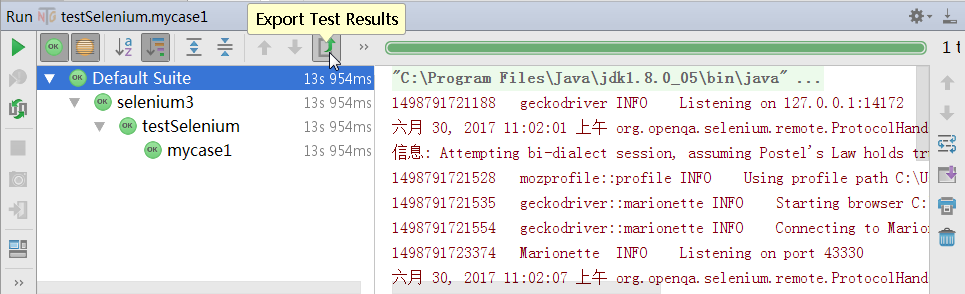
如果我们需要执行多个用例,只需要继续添加基于@Test注解的void方法即可,TestNG会自动运行所有的用例方法。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.annotations.Test;
/**
Created by cloudchen on 2017-06-30.
/
public class testSelenium {
static WebDriver driver;
@Test
public void mycase1()
{
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.get(“http://www.baidu.com“);
WebElement element_searchtext;
element_searchtext=driver.findElement(By.xpath(“.//[@id=’kw’]”));//百度搜索框
element_searchtext.sendKeys(“云层”);
WebElement element_searchbutton;
element_searchbutton=driver.findElement(By.xpath(“.//[@id=’su’]”));//百度搜索按钮
element_searchbutton.click();
try {
Thread.sleep(3000);//线程等待3秒,不推荐用,暂时这里为了效果
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement element_searchresult;//由于搜索有时候要一些时间,为了避免出现由于没有刷新导致的对象访问不到,所以这里加入了线程等待
element_searchresult=driver.findElement(By.xpath(“.//[@id=’container’]/div[2]/div/div[2]”));//搜索结果匹配记录的区域定位
System.out.println(element_searchresult.getText());//输出搜索结果
}
@Test
public void mycase2()
{
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.get(“http://www.baidu.com“);
WebElement element_searchtext;
element_searchtext=driver.findElement(By.xpath(“.//[@id=’kw’]”));//百度搜索框
element_searchtext.sendKeys(“陈霁”);
WebElement element_searchbutton;
element_searchbutton=driver.findElement(By.xpath(“.//[@id=’su’]”));//百度搜索按钮
element_searchbutton.click();
try {
Thread.sleep(3000);//线程等待3秒,不推荐用,暂时这里为了效果
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement element_searchresult;//由于搜索有时候要一些时间,为了避免出现由于没有刷新导致的对象访问不到,所以这里加入了线程等待
element_searchresult=driver.findElement(By.xpath(“.//*[@id=’container’]/div[2]/div/div[2]”));//搜索结果匹配记录的区域定位
System.out.println(element_searchresult.getText());//输出搜索结果
}
}
这样通过方法名的区别,就可以完成对所有用例的管理。(这里的用例之间有很多冗余,后期可以合并优化)
断言
使用TestNG框架或者类似的Xunit框架最大的另外一个好处就是提供了断言机制,所谓的断言可以简单理解成判断分支。
作为自动化测试来说,最重要的两个点就是:
- 代替人完成对业务的操作
- 代替人完成对业务操作后结果的检查,并给出测试用例是否通过,如果不通过的原因及现象表现
前面的对象定位和操作解决了第一个点,那么第二个点就依赖于断言了,现在看一下如果没有TestNG框架是怎么写断言的。
/*
Created by cloudchen on 2017-07-01.
*/
public class assertBasic {
public static void main(String[] args) {
String result;
result=”执行成功”;
if(result==”执行成功”)
System.out.println(“PASS”);
else
System.out.println(“FAIL”);
}
}
当有了一个result的字符串的时候,一般都是通过if语句来完成判断的过程,给出测试结果PASS或者FAIL的信息。
在TestNG中,其提供了断言的封装,大大简化了断言的过程。
@Test
public void testcase1()
{
String result;
result=”执行成功”;
Assert.assertEquals(result,”执行成功”,”断言返回字符串是否为执行成功”);
}
同样的代码在TestNG中使用断言就简单了很多,在Assert类下有很多断言方法,提供了对于不同数据类型,不同情况的断言,例如相等、不等、为真、为假、为空等情况。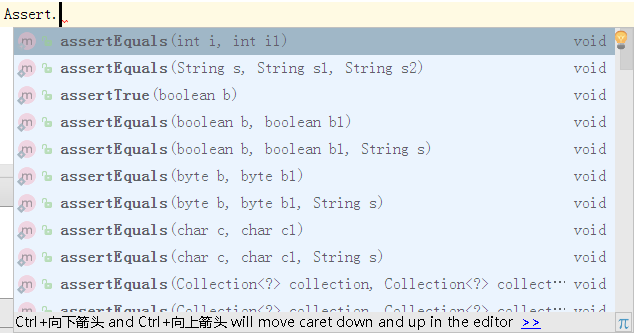
如果断言失败,TestNG还会给出具体的错误信息,expected期望结果和actual实际结果不同,所以断言失败。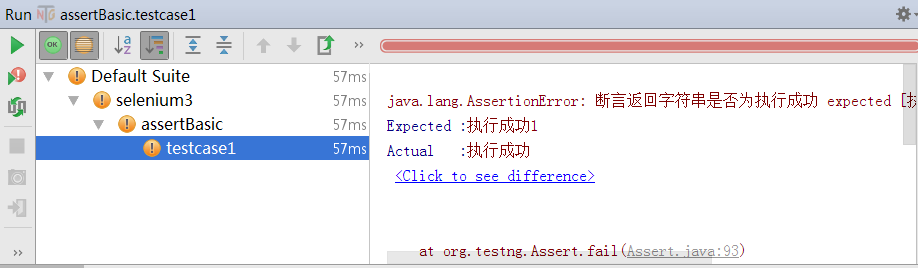
现在使用TestNG的体系来运行就会觉得比Java的主方法运行来的方便和清晰的多了。
@BeforeMethod
@BeforeMethod提供了构造函数的类似作用,在每一个@Test被运行前都会先运行一次该注解的方法。
import org.testng.Assert;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
/*
Created by cloudchen on 2017-07-01.
/
public class assertBasic {
/
public static void main(String[] args) {
String result;
result=”执行成功”;
if(result==”执行成功”)
System.out.println(“PASS”);
else
System.out.println(“FAIL”);
}
*/
@Test
public void testcase1()
{
String result;
result=”执行成功”;
Assert.assertEquals(result,”执行成功1”,”断言返回字符串是否为执行成功”);
}
@Test
public void testcase2()
{
String result;
result=”执行成功”;
Assert.assertEquals(result,”执行成功”,”断言返回字符串是否为执行成功”);
}
@BeforeMethod
public void setUp() throws Exception {
System.out.println(“@BeforeMethod”);
}
}
这里注释了主方法,并且添加了一个测试用例testcase2,在@BeforeMethod中添加了一个输出语句,当运行整个assertBasic测试用例的时候,会看到每个@Test用例之前都会先运行一次setUp()方法。
有了这个@beforeMethod方法后,就可以对前面的用例做抽象整合了。
实战百度搜索TestNG优化
新建一个testSelenium1的类,并且把testSelenium中的代码复制过来,接着在Idea代码框中右键选择Generate…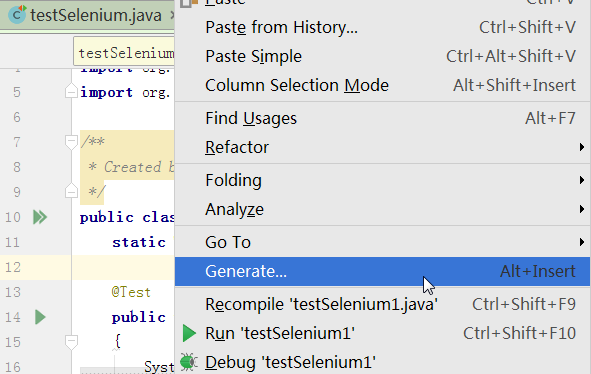
接着就会出现关于TestNG注解的语法生成提示,选择生成SetUP Method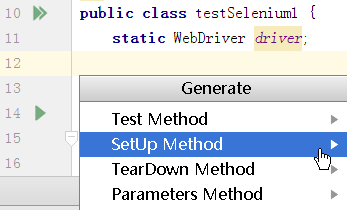
接着就会自动生成@BeforeMethod方法了
@BeforeMethod
public void setUp() throws Exception {
}
在以前每一个用例都需要设置浏览器初始化启动访问百度的操作,现在可以统一放在setUp方法中。
@BeforeMethod
public void setUp() throws Exception {
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.get(“http://www.baidu.com“);
}
接着由于有了断言,就可以把以前的简单输出变成一个具体的断言操作。
Assert.assertNotNull(element_searchtext,”不存在搜索结果”);
使用非空断言来判断搜索后返回的文本是否存在(这个断言不够明确,暂时先使用,准确的断言应该是一个非常具体的确定的内容较好)。
最终代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.Assert;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
/*
Created by cloudchen on 2017-07-01.
/
public class testSelenium1 {
static WebDriver driver;
@BeforeMethod
public void setUp() throws Exception {
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.get(“http://www.baidu.com“);
}
@Test
public void mycase1()
{
WebElement element_searchtext;
element_searchtext=driver.findElement(By.xpath(“.//[@id=’kw’]”));//百度搜索框
element_searchtext.sendKeys(“云层”);
WebElement element_searchbutton;
element_searchbutton=driver.findElement(By.xpath(“.//[@id=’su’]”));//百度搜索按钮
element_searchbutton.click();
try {
Thread.sleep(3000);//线程等待3秒,不推荐用,暂时这里为了效果
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement element_searchresult;//由于搜索有时候要一些时间,为了避免出现由于没有刷新导致的对象访问不到,所以这里加入了线程等待
element_searchresult=driver.findElement(By.xpath(“.//[@id=’container’]/div[2]/div/div[2]”));//搜索结果匹配记录的区域定位
System.out.println(element_searchresult.getText());//输出搜索结果
Assert.assertNotNull(element_searchtext,”不存在搜索结果”);
}
@Test
public void mycase2()
{
WebElement element_searchtext;
element_searchtext=driver.findElement(By.xpath(“.//[@id=’kw’]”));//百度搜索框
element_searchtext.sendKeys(“陈霁”);
WebElement element_searchbutton;
element_searchbutton=driver.findElement(By.xpath(“.//[@id=’su’]”));//百度搜索按钮
element_searchbutton.click();
try {
Thread.sleep(3000);//线程等待3秒,不推荐用,暂时这里为了效果
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement element_searchresult;//由于搜索有时候要一些时间,为了避免出现由于没有刷新导致的对象访问不到,所以这里加入了线程等待
element_searchresult=driver.findElement(By.xpath(“.//*[@id=’container’]/div[2]/div/div[2]”));//搜索结果匹配记录的区域定位
System.out.println(element_searchresult.getText());//输出搜索结果
Assert.assertNotNull(element_searchtext,”不存在搜索结果”);
}
}
新建TestNG用例2
@AfterMethod
有BeforeMethod就有AfterMethod,简单来说就是当用例执行完了接着做什么?当然是要考虑关闭浏览器咯,否则每运行一个用例就启动一次浏览器太麻烦了。
添加代码
@AfterMethod
public void tearDown() throws Exception {
driver.quit();
}
这样每次执行完用例Firefox浏览器就自动关闭了。
@BeforeClass/@AfterClass
@BeforeClass与@AfterClass,这两个注解的方法,也就是在每个类运行之前与之后会自动的被调用
在自动化脚本运行时,一个类里面的所有测试方法设计的是在同一个浏览器里面运行,那么就是说在这个类对象产生之前,就要把浏览器给启动起来,这时候@BeforeClass可以启动浏览器,@AfterClass就可以关闭浏览器了。
@BeforeSuite/@AfterSuite /@BeforeTest/@AfterTest
这四个注解是分别用在Suite与Test上的,Suite与Test是定义在XML中的,后面介绍TestNG的XML运行化的时候再做介绍。
数据驱动
数据驱动是自动化测试中非常常见的一种模式,所谓数据驱动就是通过一个数据源的变化在不影响测试脚本本身来完成多组不同输入。
@DataProvider
@DataProvider提供了对于数据驱动源的声明部分,常见代码如下
@DataProvider(name = “myData”)
public Object[][] Userinfo() {
return new Object[][]{{“1”},{“2”}};
}
其中name中的myData是用来说明数据源名称的,如果不写该名称,则直接使用方法名。DataPorivder返回Object对象的二维数组,在方法中可以自己扩展数据来源的方式,例如Excel或者数据库均可。
对于数据源调用的代码为
@Test(dataProvider=”myData”)
public void mycase1(String x)
{
System.out.println(x);
}
通过在@Test注解中添加数据源名称说明来导入数据,通过String x来作为形参接收数据。
代码运行后可以发现,TestNG自动会将@Test用例执行两次,每次传递一个数据。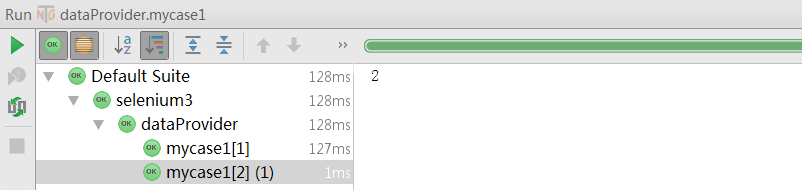
完整代码
import org.testng.annotations.DataProvider;
import org.testng.annotations.Test;
/*
Created by cloudchen on 2017-07-05.
*/
public class dataProvider {
@DataProvider(name = “myData”)
public Object[][] Userinfo() {
return new Object[][]{{“1”},{“2”}};
}
@Test(dataProvider=”myData”)
public void mycase1(String x)
{
System.out.println(x);
}
}
扩展@DataProvider文件源
使用代码管理数据源总是个麻烦的事情,接着扩展引入外部文件源。
在项目目录下新建文件TXTData.txt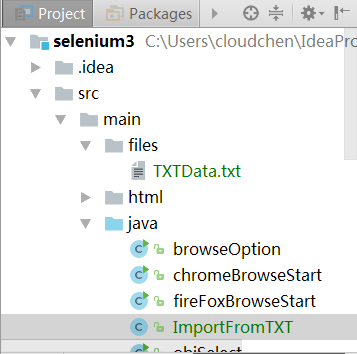
内容为
Test,Tes,测试Test,sss,PeformanceTest,InterfaceTest,AutomationTest
接着编写读取文件用的基础类ImportFromTXT
import java.io.;
/**
Created by cloudchen on 2017-07-10.
*/
public class ImportFromTXT {
public static String[] ImportTXT(String Dir) throws IOException {
//String encoding=”GBK”;
String encoding=”UTF-8”;
File FileDir=new File(Dir);
BufferedReader BufferReader = new BufferedReader( //以缓冲方式读取文本,方便使用readLine读取分行文本
new InputStreamReader( //将字节转换为字符并指定编码方式
new FileInputStream(FileDir),encoding)); //以字节流方式从目录路径读取文件
String word;
StringBuffer words = new StringBuffer();
//分行读取缓冲区中文本,以字符串格式读取至字符序列
while ((word = BufferReader.readLine()) != null) {
words.append(word);
}
String wordss = words.substring(0); //从序列中从第一个开始读取字符串,0表示开始的第一个字符
String w[] = wordss.split(“,”); //按英文逗号分割,并将数据取出存放至一维数组中
return w;
}
}
该类中的ImportTXT方法完成了对指定文件使用逗号分隔符转化为数组返回。
接着在@DataProvider中编写载入文件
@DataProvider
public Object[][] TXTData() throws IOException
{
//设置需要导入的txt文件路径,并调用txt转化为以为数组功能
File directory = new File(“”);//设定为当前文件夹
String basedir=directory.getCanonicalPath();//获取标准的路径C:\Users\cloudchen\IdeaProjects\selenium3
String Dir = basedir+”\src\main\files\TXTData.txt”;
ImportFromTXT txt = new ImportFromTXT();
String[] arr=txt.ImportTXT(Dir);
Object[][] data=new Object[arr.length][];//Object第一个下标标记测试方法要调用的次数,所以数据为arr数组的长度
for(int i=0;i
}
return data;
}
最后编写使用这个数据源的测试用例
@Test(dataProvider = “TXTData”)//由于数据源没有说明名称,所以这里使用方法名
public void TXTTest(String data) throws IOException {
System.out.println(“Data is:”+data);
//Assert.assertTrue(data.contains(“Test”));
}
运行结果可以看到,将文本文件中的每一项单独取出完成(通过修改分隔符可以完成使用回车区分,做到每一行单独,类CSV格式)。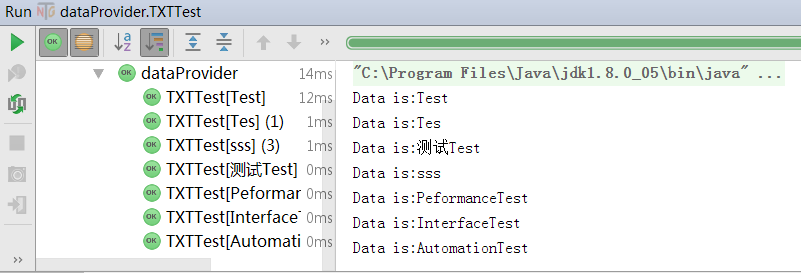
扩展@DataProivder使用Excel源
文本毕竟还是麻烦,怎么使用Excel源呢?这里引用了POI框架
在Maven的Pom中添加依赖
首先新建一个接口
ublic interface ExcelReader {
public String[][] readExcel(String url);
}
接着编写代码ExcelReaderImpl实现了接口ExcelReader并复写了ExcelReader方法。
import java.io.File;
import java.io.FileInputStream;
import java.text.SimpleDateFormat;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
/*
Created by liurui on 2017-07-20.
*/
public class ExcelReaderImpl implements ExcelReader {
@Override
public String[][] readExcel(String url) {
Workbook workbook = getExcelInputStream(url);
if (workbook == null || workbook.getNumberOfSheets() < 1) {
System.out.println(“读取excel错误或sheet为空”);
return null;
}
if (workbook.getNumberOfSheets() < 1) {
System.out.println(“sheet为空”);
return null;
}
return readToArray(workbook);
}
private String[][] readToArray(Workbook workbook) {
Sheet sheet = workbook.getSheetAt(0); //读取第一个Sheet
int rowCount = sheet.getPhysicalNumberOfRows(); //获取总行数
if (rowCount < 1) {
System.out.println(“行数为空”);
return null;
}
//创建最外层数组
String[][] rowArray = new String[rowCount][];
//遍历每一行
for (int r = 0; r < rowCount; r++) {
Row row = sheet.getRow(r);
int cellCount = row.getPhysicalNumberOfCells(); //获取总列数
if (cellCount < 1) {
continue;
}
//创建每一行存储数组
String[] cellArray = new String[cellCount];
//遍历每一列
for (int c = 0; c < cellCount; c++) {
Cell cell = row.getCell(c);
cellArray[c] = getCellStringValue(cell);
}
rowArray[r] = cellArray;
}
return rowArray;
}
private static final SimpleDateFormat fmt = new SimpleDateFormat(“yyyy-MM-dd”);
private String getCellStringValue(Cell cell) {
String cellValue = null;
int cellType = cell.getCellType();
switch (cellType) {
case Cell.CELL_TYPE_STRING: //文本
cellValue = cell.getStringCellValue();
break;
case Cell.CELL_TYPE_NUMERIC: //数字、日期
if (DateUtil.isCellDateFormatted(cell)) {
cellValue = fmt.format(cell.getDateCellValue()); //日期型
} else {
cellValue = String.valueOf(cell.getNumericCellValue()); //数字
}
break;
case Cell.CELL_TYPE_BOOLEAN: //布尔型
cellValue = String.valueOf(cell.getBooleanCellValue());
break;
case Cell.CELL_TYPE_BLANK: //空白
cellValue = cell.getStringCellValue();
break;
case Cell.CELL_TYPE_ERROR: //错误
cellValue = “错误”;
break;
case Cell.CELL_TYPE_FORMULA: //公式
cellValue = “暂不支持公式”;
break;
default:
cellValue = “读取错误”;
}
return cellValue;
}
private Workbook getExcelInputStream(String url) {
File excelFile = new File(url); //创建文件对象
FileInputStream is;
Workbook workbook = null;
try {
is = new FileInputStream(excelFile);
workbook = WorkbookFactory.create(is); //支持 Excel 2003/2007/2010
} catch (Exception e) {
System.out.println(“读取excel错误”+e);
}
return workbook;
}
}
在TestNG中使用
@DataProvider
public Object[][] ExcelData()
{
ExcelReader excelReader = new ExcelReaderImpl();
String excelUrl = “D:/ExcelReadTest.xlsx”;
String[][] excelArray = excelReader.readExcel(excelUrl);
return excelArray;
}
@Test(dataProvider = “ExcelData”)
//有几列写几个形参即可
public void mycase2(String x,String y,String z)
{
System.out.println(x+y+z);
}
运行后可以看到结果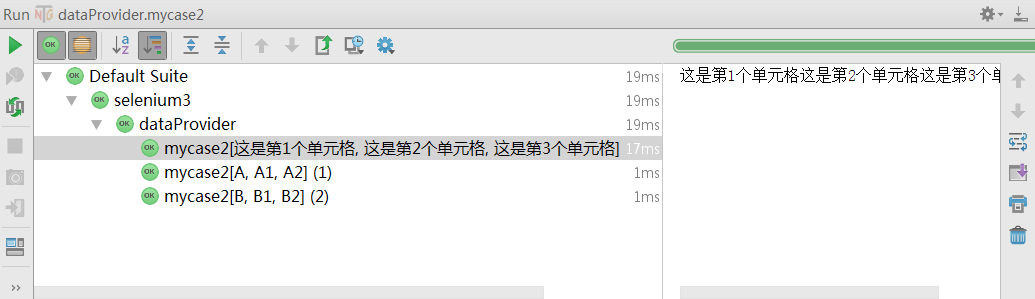
对应的Excel文件格式为
实战百度搜索数据驱动
有了前面的数据驱动模式,现在就可以把原本需要编写代码的测试过程变成测试用例与测试实现分离的效果了。从而让执行自动化测试的与设计自动化测试脚本的团队完全分离。
Jenkins持续集成与发布
如果每次都自己在Idea中运行代码是很麻烦的事情的,那么要跑起来还有啥办法呢?Maven的作用来了,不光是加载库文件,还负责了代码的执行。
Maven
在Idea中可以看到Maven的管理菜单,点击Maven test就可以执行TestNG的所有用例。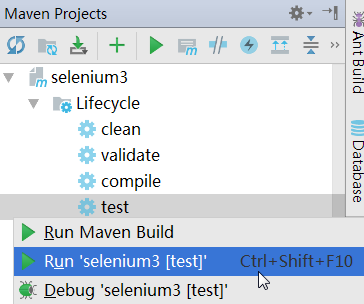
默认包含的测试类:
/*Test.java
/Test.java
**/TestCase.java
默认排除的测试类:
/Abstract*Test.java
/AbstractTestCase.java
这里编写一个专用测试类
import org.testng.Reporter;
import org.testng.annotations.Test;
/**
Created by cloudchen on 2017-09-14.
*/
public class Testmaven {
@Test
public void test1()
{
System.out.println(“test”);
Reporter.log(“TestOps”);
}
}
通过Reporter对象完成对TestNG的报告内容添加,接着运行Maven test,就会自动执行这个类中的测试方法,并且生成报告
[INFO] —- maven-surefire-plugin:2.12.4:test (default-test) @ selenium3 —-
[INFO] Surefire report directory: C:\Users\cloudchen\IdeaProjects\selenium3\target\surefire-reports
打开该目录可以看到TestNG的报告存放在其中。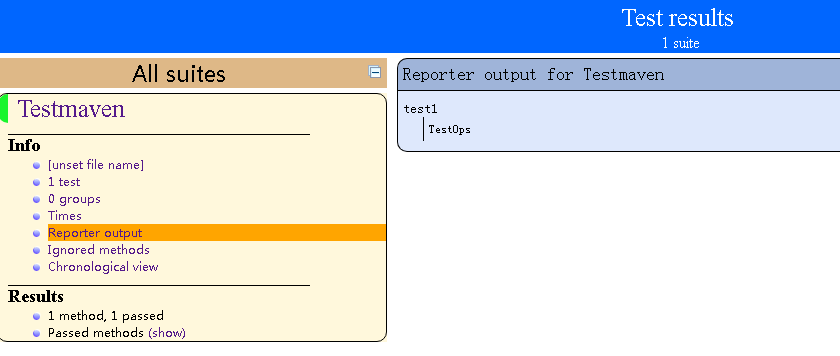
在Report output中存放了通过Reporter对象输出的内容。
如果需要使用TestNG的配置文件,可以这样在POM文件里面写。
如果需要调整默认类和排除类,可以在POM文件里面写。
org.apache.maven.plugins maven-surefire-plugin 2.5 */Tests.java -
*/ServiceTest.java **/TempDaoTest.java -
-
-
Tomcat安装
官方下载http://tomcat.apache.org/
这里由于是Windows环境,所以选择32/64-bit windows zip
下载后直接解压在目录中的bin子目录中,找到startup.bat,双击启动
打开浏览器,在地址栏中输入127.0.0.1:8080就可以看到下面的页面。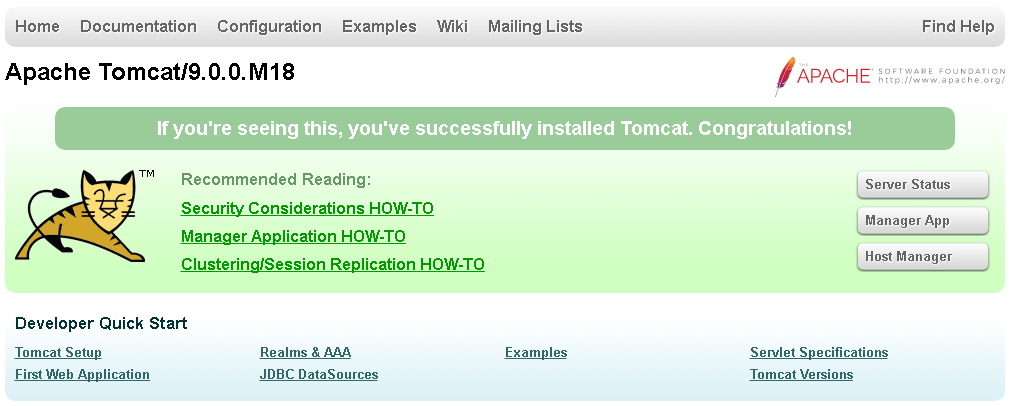
说明Tomcat安装完成。Jenkins部署
官方网站https://jenkins.io/在其下载页面中,选择下载War包。
接着将该下载的jenkins.war文件存放于Tomcat的webapps目录下即可。
打开浏览器访问127.0.0.1:8080/jenkins就可以看到jenkins首页,首次使用会出现插件更新界面。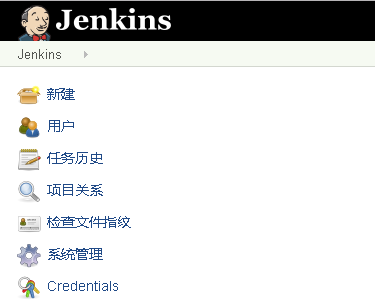
可参考视频
https://v.qq.com/x/page/t0390iakl8u.html使用Jenkins运行Maven项目
首先打开Jenkins首页找到系统管理下的插件管理,过滤中填写Maven,并且选择安装Maen Intergration plugin。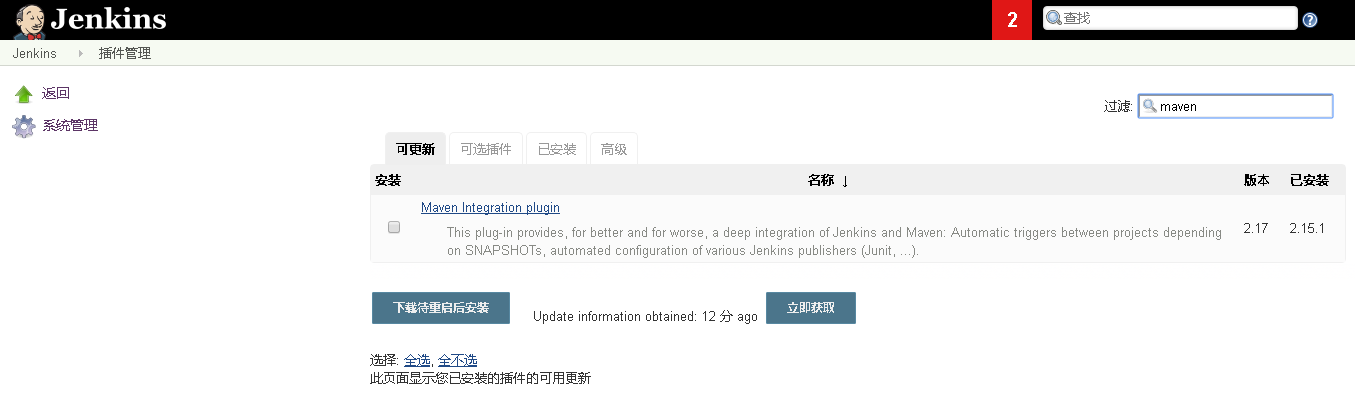
等待更新完成,回到首页,新建一个任务,类型为创建一个Maven项目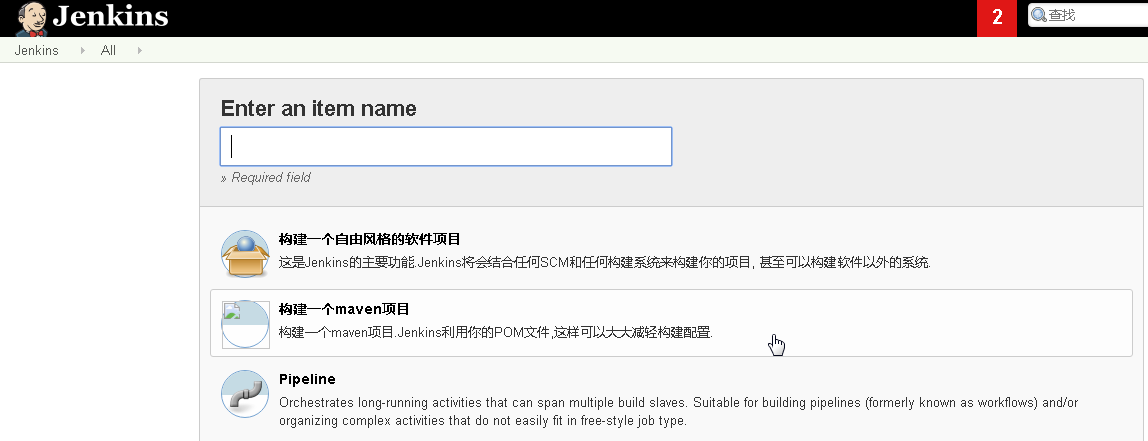
填写项目名称为TestOps,选择OK进入具体项目说明界面。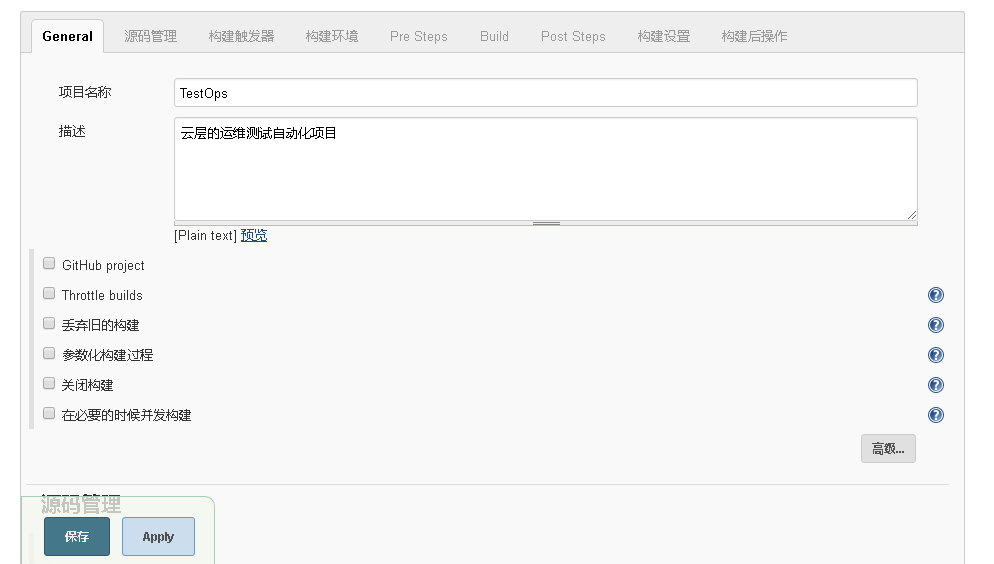
往下拖动,找到Build项目,在这里选择具体要执行的pom.xml文件,并且在Goals and options中添加test参数,从而实现maven -test测试执行效果。
在Idea中找到Pom.xml文件,右键选择Show in Explorer
将目录复制粘贴到Root POM地址中即可。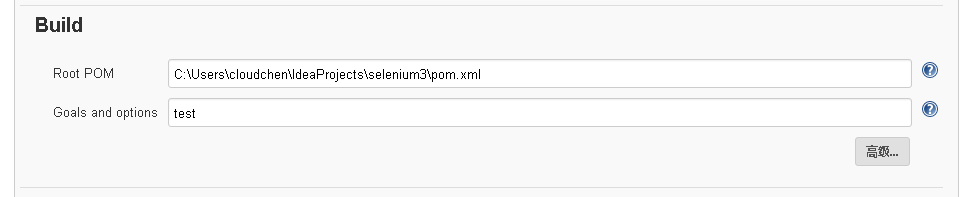
基本使用可以不用配置别的内容,直接保存整个Jenkins任务。
最后只需要点击立即构建即可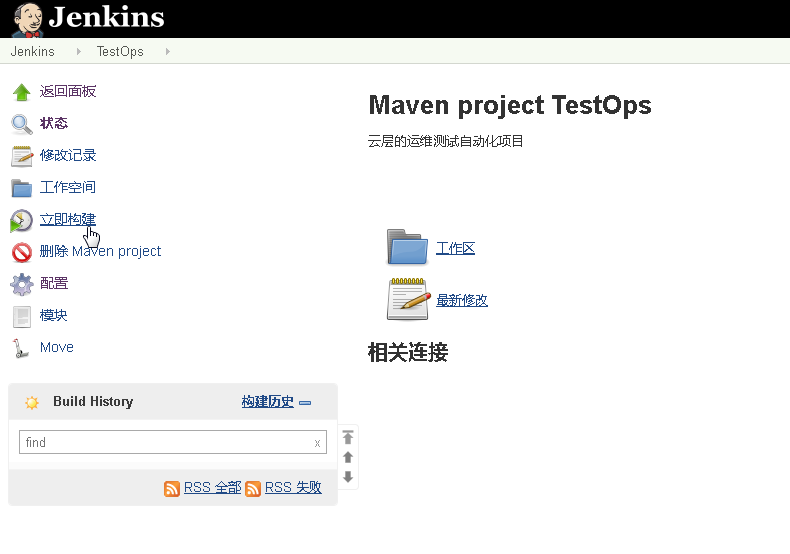
等待片刻完成构建执行即可查看构建结果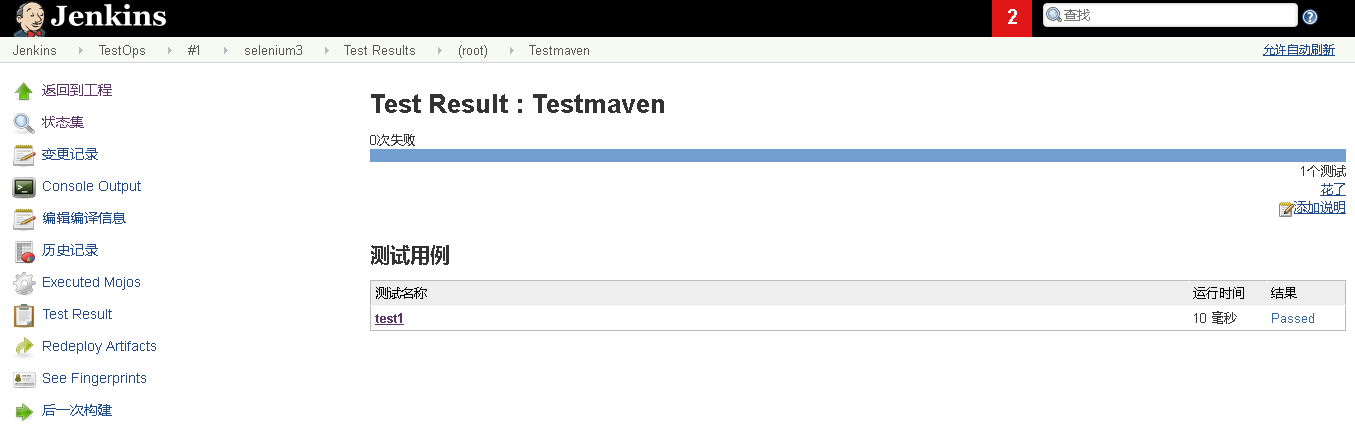
Jenkins定时任务
在很多自动化场合中都需要利用系统空余时间来进行测试,例如利用深夜的时候进行无人值守的自动化回归,这个时候就需要使用Jenkins的定时任务来完成了。
在Jenkins任务中选择构建触发器,里面有个日程表。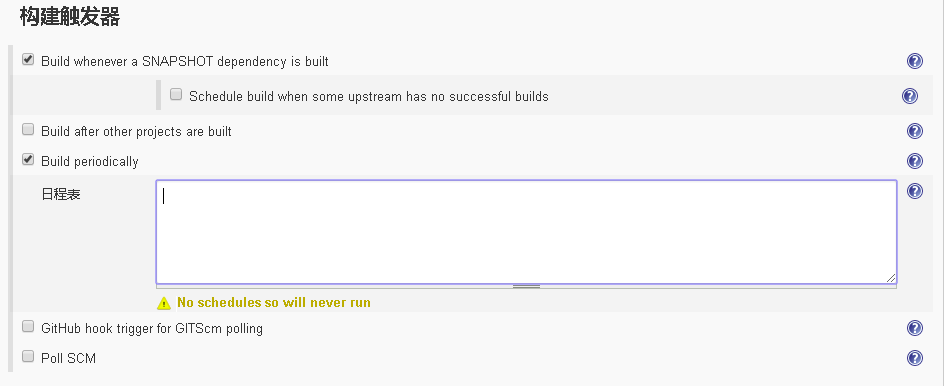
这里的日程表和Linux下的Crontab格式相同,使用”分 时 天 月 周”的方式展示,一般可以写成
第一个是代表分钟 H 表示随机
第二个是代表小时 9-15/4 9点到下午三点期间的每隔4个小时
_第三个是代表天 任意一天
第四个是代表月份 1-12 表示1到12月份
第五个是代表星期 1-5 表示工作日
没有用到 H 随机的话,不要加括号
_H(9-18) 9点到18点 中随机的一个点
例如:
表示任何一个时间段,同一个时间都可能会触发执行。不建议使用
H/30 表示每天每隔 30分钟构建一次
H 4-19/3 表示,一天的凌晨点到下午7点,每隔3个小时构建一次
3-5 表示,每个月的3号,4号,5号 都会被构建,具体时间未知
1-5 表示,工作日时会构建,具体时间未知
H/30 8-19/3 1-28 1-11 1-5 表示 在1月到11月中的1号-28号,每个工作日,早晨的8点到下午7点每隔3.5个小时会触发构建。
这里我们可以配置一个每天晚上2点开始执行的自动构建任务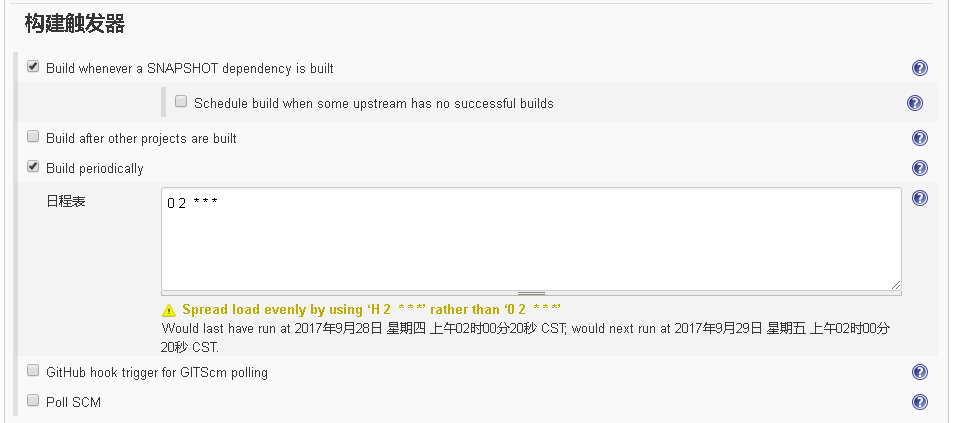
保存后就可以等待其到点自动运行了。
扩展元素识别管理
其实有了前面的内容已经可以入门完成自动化测试了,接着要说的就是一些对象的细节处理。
Alert处理
Alert是JS的弹出框,编写测试案例代码alerthtml.html
<!DOCTYPE html>
当点击按钮click it后会弹出JS的Alert提示框,WebDriver提供了对弹出框的处理方式。
Alert alert=driver.switchTo().alert();//切换到弹出alert框上
alert.accept();//确认
//alert.dismiss();//取消
最终代码
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
/*
Created by cloudchen on 2017-10-07.
*/
public class ExtendObj {
public static WebDriver driver;
public static void main(String[] args) {
System.setProperty(“webdriver.gecko.driver”, “C:\Windows\System32\geckodriver.exe”);
System.setProperty(“webdriver.firefox.bin”,”C:\Program Files (x86)\Mozilla Firefox51\firefox.exe”);
driver=new FirefoxDriver();
driver.navigate().to(“http://127.0.0.1/selenium3/alerthtml.html“);
alertopt();
}
public static void alertopt()
{
driver.findElement(By.xpath(“//button”)).click();
Alert alert=driver.switchTo().alert();//切换到弹出alert框上
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
alert.accept();//确认
//alert.dismiss();//拒绝
}
}
Confirm处理
Confirm和Alert很类似,区别只是在于提供了取消按钮。
function myconfirm()
{
window.confirm(“this is alert”);
}
对于Confirm处理和Alert基本一致,只是点击取消按钮使用
//alert.dismiss();//取消
即可
Prompt处理
Prompt是提供输入框的弹出窗口,在访问时补充一个填充文本框操作即可。
function myprompt()
{
var myprompt=prompt(“title”,”message”);
}
访问代码
public static void promptopt()
{
driver.findElement(By.xpath(“//button[3]”)).click();
Alert alert=driver.switchTo().alert();//切换到弹出alert框上
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
alert.sendKeys(“TestOps.cn”);
alert.accept();//确认
}
Iframe处理
Iframe提供了多页面框架结构,由于每个框架内都是一个独立的HTML,所以在访问的时候需要先切换到对应Iframe上,再使用定位方法来完成对象访问。
参考HTML基础中关于Iframe的页面
切换到frame上的方法有下面几个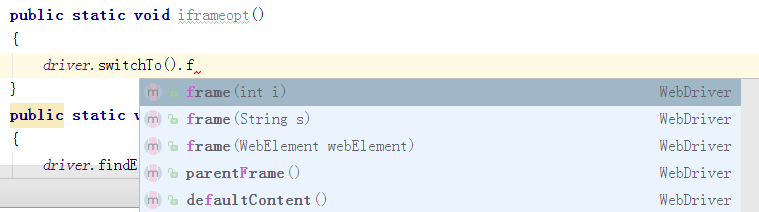
可以通过数字,名称和定位来获取具体的frame,也可以访问父frame和默认顶层frame。
访问代码如下
public static void iframeopt()
{
driver.navigate().to(“http://127.0.0.1/selenium3/iframe.html“);
driver.switchTo().frame(“sidebar”);
System.out.println(driver.findElement(By.xpath(“html/body”)).getText());
driver.switchTo().parentFrame();
driver.switchTo().frame(1);
System.out.println(driver.findElement(By.xpath(“html/body”)).getText());
driver.switchTo().defaultContent();
}
新窗体
在超链接中如果用target=”_blank”这样的属性就会弹出新的窗口例如:
测试一下
这时由于webdriver没有切到新的窗体上,会导致定位失败,所以需要捕获窗体句柄。
public static void newwindow()
{
driver.navigate().to(“http://localhost/selenium3/alerthtml.html“);
driver.findElement(By.xpath(“//a”)).click();
String handle=driver.getWindowHandle();//获取当前句柄
Set
handles.remove(handle);
driver.switchTo().window(handles.iterator().next());//切换到新窗体
System.out.println(driver.findElement(By.xpath(“html/body/table/tbody/tr[2]/td”)).getText());
}
也可以这样写
public static void newwindow1()
{
driver.navigate().to(“http://localhost/selenium3/alerthtml.html“);
driver.findElement(By.xpath(“//a”)).click();
String handle=driver.getWindowHandle();//获取当前句柄
for(String handles:driver.getWindowHandles())//循环获取
{
if(handles.equals(handle))
continue;
else
driver.switchTo().window(handles);
}
System.out.println(driver.findElement(By.xpath(“html/body/table/tbody/tr[2]/td”)).getText());
}
鼠标事件
当需要访问双击、右键、鼠标移动的时候需要使用Action类。
Actions MyA=new Actions(driver);
在MyA对象中提供了双击、鼠标拖拽以及鼠标移动的方法。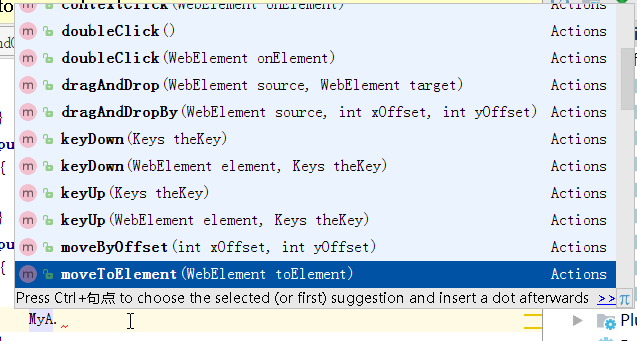
鼠标访问对象在HTML中可以这样写
对应的访问代码为
public static void mouseover()
{
driver.navigate().to(“http://localhost/selenium3/alerthtml.html“);
Actions MyA=new Actions(driver); MyA.moveToElement(driver.findElement(By.xpath(“//button[4]”))).perform();
}
下拉菜单
下拉菜单一般在HTML中都是使用Select来实现的。
对于这样的下拉菜单使用Select类来处理
public static void selectobj()
{
driver.navigate().to(“http://127.0.0.1/selenium3/htmlbasic.html“);
WebElement element=driver.findElement(By.xpath(“html/body/form/select”));
Select select=new Select(element);
select.selectByIndex(2);
}
扩展功能
从本章开始以WebDriver3.7.0版本为基础了,为了避免PhantomJS的不兼容错误
截图
很多时候在系统出错了都希望有截图辅助,在Selenium3中截图是这样实现的
public static void scrshot()
{
driver.navigate().to(“http://localhost/selenium3/alerthtml.html“);
File screenShotFile=((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
try {
FileUtils.copyFile(screenShotFile,new File(“D:/test.png”));
} catch (IOException e) {
e.printStackTrace();
}
}
这里使用了Apache库中的FileUtils,所以需要在Pom.xml文件中添加引用
PhantomJs虚拟浏览器
由于PhantomJs长期不更新已经不是Selenium官方推荐模块,所以建议大家改用HTMLUnit模块来代替PhantomJS,或者用Chrome浏览器的无头模式来实现。
使用浏览器运行包含界面总是很慢的,其实还有一种后台的虚拟浏览器例如PhantomJs,其可以通过内存完成页面操作处理。
添加Maven引用
在代码中编写
public class PhantomJSD {
public static void phantomjs()
{
System.setProperty(“phantomjs.binary.path”, “phantomjs.exe”);
WebDriver pdriver = new PhantomJSDriver();
pdriver.get(“http://www.baidu.com“);
System.out.println(pdriver.getTitle());
}
public static void main(String[] args) {
phantomjs();
}
}
需要去官网下载phantomjs.exe存放在脚本目录下,官网地址http://phantomjs.org/
运行后即可看到效果。
对象等待体系
在自动化测试中,由于业务处理或者网络问题,都会导致所需要访问的对象不会立即出现,而WebDriver对象查找是立即执行的,如果对象没出现就会出现对象无法访问的情况。
强制等待
所谓强制等待,就是通过直接强制等待时间的方式来解决对象不出现的问题。
Thread.sleep(1000);//单位毫秒
该语句需要配合异常处理,或者直接在方法上控制
try {
Thread.sleep(3000);//线程等待3秒
} catch (InterruptedException e) {
e.printStackTrace();
}
这种等待的最大缺点是就算是对象出现了也会等待到线程时间,所以缺乏可控性并且浪费时间。
全局等待
WebDriver提供了对于全局等待的设置
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
在设置了后,每一句对象访问如果查询不到对象,都会等待10秒中,这种全局设置比较轻松;而如果对象出现了就直接进行,不会产生不必要的等待。
显式等待
显式等待使用ExpectedConditions类中自带方法, 可以进行显试等待的判断。针对访问对象独立设置等待的时间,例如:
e=new WebDriverWait(driver,10).until(ExpectedConditions.presenceOfElementLocated(By.id(“id”)));
显式等待可以自定义等待的条件,用于更加复杂的页面等待条件
(1)页面元素是否在页面上可用和可被单击:elementToBeClickable(By locator)
(2)页面元素处于被选中状态:elementToBeSelected(WebElement element)
(3)页面元素在页面中存在:presenceOfElementLocated(By locator)
(4)在页面元素中是否包含特定的文本:textToBePresentInElement(By locator)
(5)页面元素值:textToBePresentInElementValue(By locator, java.lang.String text)
(6)标题 (title):titleContains(java.lang.String title)
Log4J2日志体系
添加Log4j2框架
在src目录下配置log4j2.xml,由于Log4j的2版本修改,所以配置文件的配置位置也变了
<?xml version=”1.0” encoding=”UTF-8”?>
接着将log4j2.xml存放在src目录下的resources目录
接着编写代码通过Log4j来记录日志
public class chromeBrowseStart {
private static final Logger logger = LogManager.getLogger(ResolverUtil.Test.class.getName());
public static void main(String[] args) {
WebDriver driver=new ChromeDriver();
driver.navigate().to(“http://www.baidu.com“);
logger.info(“info message”);
logger.trace(“trace message”);
logger.error(“error message”);
logger.debug(“debug message”);
}
}
执行后可以看到在d盘目录下的log目录下会出现对应的日志记录。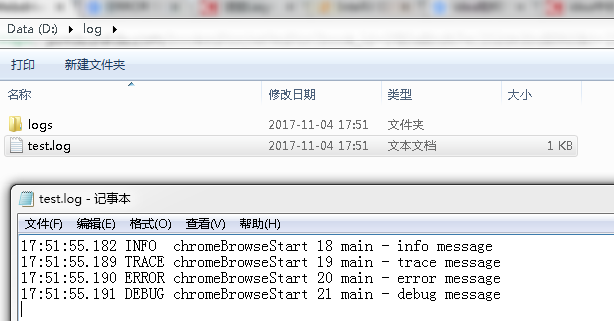
PageObject框架
到现在为止我们对测试的脚本管理还是比较混乱的,当测试的内容越来越多的时候,会发现有很多重复的过程,这个时候就需要重构来简化整个项目。
PageObject体系就是这样的一个便于我们管理测试对象和测试流程的框架。
基本概念
PageObject体系简单来说就是类对象库、方法体系,也就是一个类一个页面、页面内的对象和方法都有该类管理。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
/
Created by cloudchen on 2017-11-27.
/
public class PoBasic {
public static By baidusearchtext=By.id(“kw”);
public static By baidusearchbutton=By.id(“su”);
public WebDriver wd;
public PoBasic(WebDriver driver)
{
this.wd=driver;
}
public void search(String searchstring)
{
wd.findElement(baidusearchtext).sendKeys(searchstring);
wd.findElement(baidusearchbutton).click();
}
}
在这个代码中通过属性完成了对页面对象的管理,而通过方法完成了对页面业务操作的封装,而构造函数解决了浏览器统一的问题。
而如果要调用这个代码,就可以这样写。
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.annotations.Test;
/
Created by cloudchen on 2017-11-27.
/
public class PoTest {
@Test
public void potest1()
{
WebDriver driver=new ChromeDriver();
driver.get(“http://www.baidu.com“);
PoBasic pb=new PoBasic(driver);
pb.search(“TestOps”);
}
}
优化1-初始化页面地址
在上面框架中我们新建一个这个页面的时候没有自动打开页面,那么补充一个就行了。
添加属性url以及构造函数中添加地址刷新。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
/*
Created by cloudchen on 2017-11-27.
*/
public class PoBasic {
public static By baidusearchtext=By.id(“kw”);
public static By baidusearchbutton=By.id(“su”);
public static String url=”http://www.baidu.com“;
public WebDriver wd;
public PoBasic(WebDriver driver)
{
this.wd=driver;
wd.get(url);
}
public void search(String searchstring)
{
wd.findElement(baidusearchtext).sendKeys(searchstring);
wd.findElement(baidusearchbutton).click();
}
}
优化2-对象自动等待
在默认情况下如果访问的对象不在或者由于某些原因没有刷新出现,就会出现对象访问失败的情况,那么把等待体系封装在PO框架中就很合适了。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
/
Created by cloudchen on 2017-11-27.
/
public class PoBase {
public static String url;
public WebDriver wd;
public static int timeout=10;
public PoBase(WebDriver driver)
{
this.wd=driver;
}
public WebElement findelement(By by,int timeout)
{
WebElement element=null;
try {
element = new WebDriverWait(wd, timeout).until(ExpectedConditions.presenceOfElementLocated(by));
}
catch(Exception e)
{
System.out.println(“ | “+by.toString()+” | 对象访问失败”);
}
finally {
return(element);
}
}
public WebElement findelement(By by)
{
WebElement element=null;
try {
element = new WebDriverWait(wd, 10).until(ExpectedConditions.presenceOfElementLocated(by));
}
catch(Exception e)
{
System.out.println(“ | “+by.toString()+” | 对象访问失败”);
}
finally {
return(element);
}
}
}
在这个代码中通过对象等待实现了PoBase类下的findelement方法,其中包含可自定义的等待时间方法findelement(By by,int timeout)和一个使用默认等待时间方法 public WebElement findelement(By by),后续页面需要继承于该类。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
/
Created by cloudchen on 2017-11-27.
/
public class BaiduPo extends PoBase {
public static By baidusearchtext=By.id(“kw”);
public static By baidusearchbutton=By.id(“su”);
public static String url=”http://www.baidu.com“;
public BaiduPo(WebDriver wd)
{
super(wd);
wd.get(this.url);
}
public BaiduPo(WebDriver wd,String url)
{
super(wd);
wd.get(url);
}
public void search(String searchstring)
{
this.findelement(baidusearchtext).sendKeys(searchstring);
this.findelement(baidusearchbutton,5).click();
}
}
这个时候来看BaiduPo页面,只需要继承与PoBase,这里使用了super来调用父类的构造函数,而在使用的时候和以前区别不大。
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
/*
Created by cloudchen on 2017-11-27.
*/
public class PoTest {
WebDriver driver;
@BeforeMethod
public void setup()
{
driver=new ChromeDriver();
}
@Test
public void potest1()
{
driver.get(“http://www.baidu.com“);
PoBasic pb=new PoBasic(driver);
pb.search(“TestOps”);
}
@Test
public void potest2()
{
BaiduPo bp=new BaiduPo(driver);
bp.search(“TestOps”);
BaiduPo bp1=new BaiduPo(driver,”http://testops.ke.qq.com“);
bp1.search(“testops”);
}
}
这里为了看到对象访问失败,所以故意使用带url地址的构造函数跳转了页面,这样bp1.search一定会出现对象不存在的错误。
优化3-错误截图
在基类中提供了对于错误记录的功能,但是错误并没有截图功能,所以将截图补充进来。
import org.apache.commons.io.FileUtils;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
/
Created by cloudchen on 2017-11-27.
/
public class common {
public static String gettime()
{
Date now = new Date();
SimpleDateFormat dateFormat = new SimpleDateFormat(“yyyyMMddHHmmss”);
System.out.println(dateFormat.format(now));
return (dateFormat.format(now));
}
public static void scrshot(WebDriver driver)
{
File screenShotFile=((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
try {
FileUtils.copyFile(screenShotFile,new File(“D:/“+gettime()+”.png”));
} catch (IOException e) {
e.printStackTrace();
}
}
}
这里的common类中完成了获取当前时间格式以及截图的方法,截图可以通过gettime()方法来获得对应的文件名。
而在PoBase中只需要调用一下这个方法即可。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
/
Created by cloudchen on 2017-11-27.
/
public class PoBase {
public static String url;
public WebDriver wd;
public static int timeout=10;
public PoBase(WebDriver driver)
{
this.wd=driver;
}
public WebElement findelement(By by,int timeout)
{
WebElement element=null;
try {
element = new WebDriverWait(wd, timeout).until(ExpectedConditions.presenceOfElementLocated(by));
}
catch(Exception e)
{
System.out.println(“ | “+by.toString()+” | 对象访问失败”);
common.scrshot(wd);
}
finally {
return(element);
}
}
public WebElement findelement(By by)
{
WebElement element=null;
try {
element = new WebDriverWait(wd, 10).until(ExpectedConditions.presenceOfElementLocated(by));
}
catch(Exception e)
{
System.out.println(“ | “+by.toString()+” | 对象访问失败”);
common.scrshot(wd);
}
finally {
return(element);
}
}
}
性能监控
在自动化中也会涉及到性能指标监控,UI的执行效率是最直观的响应时间体现,当响应时间超长时怎么知道问题到底在哪里呢?
Har自动生成
通过BrowserMob可以帮助我们基于代理模式来生成对应的har文件(以前云层是通过firebug插件实现的)。
添加引用,编写代码
import com.sun.java.browser.net.ProxyService;
import net.lightbody.bmp.BrowserMobProxy;
import net.lightbody.bmp.BrowserMobProxyServer;
import net.lightbody.bmp.client.ClientUtil;
import net.lightbody.bmp.core.har.Har;
import org.openqa.selenium.Proxy;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxProfile;
import org.openqa.selenium.remote.CapabilityType;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.io.File;
import java.io.IOException;
/*
Created by cloudchen on 2017-11-29.
*/
public class chromegethar {
public static void main(String[] args) {
BrowserMobProxy proxy = new BrowserMobProxyServer();
proxy.start();
Proxy seleniumProxy = ClientUtil.createSeleniumProxy(proxy);
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability(CapabilityType.PROXY, seleniumProxy);
// WebDriver driver = new FirefoxDriver(capabilities);
WebDriver driver=new ChromeDriver(capabilities);
proxy.newHar(“http://testops.ke.qq.com“);
driver.get(“http://testops.ke.qq.com“);
Har har = proxy.getHar();
try {
har.writeTo(new File(“testops.ke.qq.com.har”));
} catch (IOException e) {
e.printStackTrace();
}
driver.close();
}
}
通过设置浏览器代理为BrowserMob,再通过BrowserMob的har功能生成har。代码运行后会在目录下生成har文件,通过harviewer即可查看
http://www.softwareishard.com/har/viewer/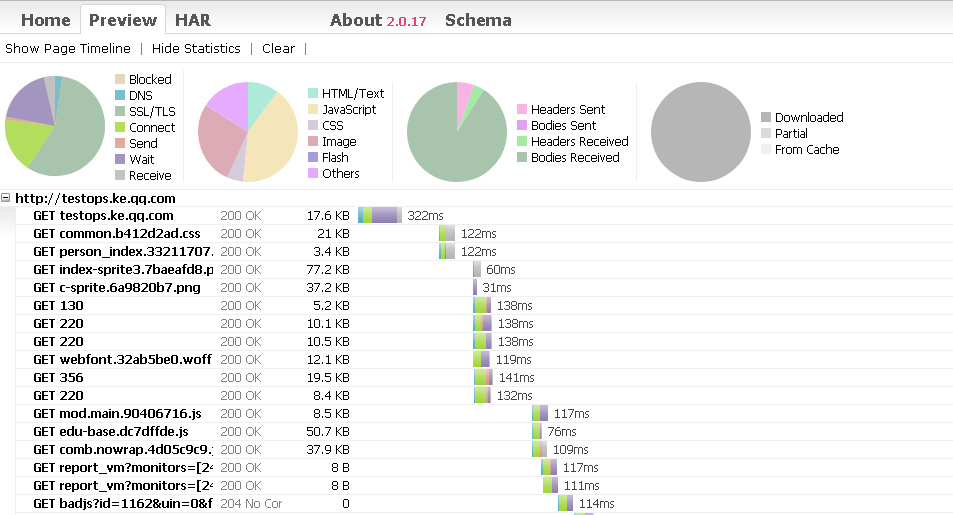

若有收获,就点个赞吧
0 人点赞
