TensorFlow 调试器
tfdbg 是 TensorFlow 的专用调试器。由于 TensorFlow 的计算 — 图形使用常规调试器难以调试,例如 Python 的 pdb,因此它允许你在训练和推断的 i 过程中查看运行 TensorFlow 图的内部结构和状态。
本指南重点关注 tfdbg 的命令行接口(CLI)。关于如何使用 tfdbg 的图形化用户界面(GUI),TensorBoard 调试插件,请查询它的 README。
注意:TensorFlow 调试器使用 curses) —— 基于文本用户界面。在 Mac OS X 上, ncurses 库是必需的,可以用 brew install ncurses 进行安装。Windows 对 curses 支持性并不好,因此可以使用基于接口的 readline,用 pip 安装 pyreadline 来使用 tfdbg。如果你使用 Anaconda3,你可以使用 "C:\Program Files\Anaconda3\Scripts\pip.exe" install pyreadline 这样的命令来安装它。非官方的 Windwos curses 包可以在这里下载,然后用 pip install <your_version>.whl 安装。但是 curses 在 Windows 上可能无法像它在 Linux 和 Mac 上一样可靠地运行。
本教程演示了如何使用 tfdbg 命令行界面(CLI)来调试 nans 和 infs 错误,这是 TensorFlow 模型开发中经常遇到的错误类型。以下示例适用于使用 TensorFlow 的底层 Session API 的用户。本文档的后续部分描述了如何在更高层的 API 中使用 tfdbg,包括 tf.estimator、tf.keras / keras 和 tf.contrib.slim。
要观察这个问题,请运行以下命令而不使用调试器(源代码可以在这里找到)。
python -m tensorflow.python.debug.examples.debug_mnist
该代码训练一个简单的神经网络用于 MNIST 数字图像识别。请注意,在第二次迭代训练后(step 1)训练之后,准确度就虽然还略有提高,但都是在 0.098 附近徘徊,变化已经不大了。
Accuracy at step 0: 0.1113Accuracy at step 1: 0.3183Accuracy at step 2: 0.098Accuracy at step 3: 0.098Accuracy at step 4: 0.098
想知道可能出了什么问题,你怀疑计算图在训练时中的某些节点产生了不良的数值,例如 infs 和 nans,因为这是训练失败的一个常见原因。让我们用 tfdbg 来调试这个问题,并确定第一次出现这种数值问题的图结点的确切位置。
使用 tfdbg 包装 TensorFlow 会话(Sessions)
要在我们的示例中添加对 tfdbg 的支持,所需要的是添加以下代码行,并使用调试器包装器包装 Session 对象。此代码已添加到 debug_mnist.py 中,因此你可以在命令行中使用 --debug 标志来激活 tfdbg 命令行界面(下文都将简称为 tfdbg CLI)。
# 编译TensorFlow时,让你的构建(BUILD)目标依赖于 "//tensorflow/python/debug:debug_py"# (只要你是使用 pip install 来安装开源 TensorFlow 的,就不需要担心构建时的依赖问题)from tensorflow.python import debug as tf_debugsess = tf_debug.LocalCLIDebugWrapperSession(sess)sess.add_tensor_filter("has_inf_or_nan", tf_debug.has_inf_or_nan)
该包装器具有与 Session 相同的接口,因此启动调试不需要对代码进行任何修改。包装器提供了额外的特性,包括:
- 在
Session.run()之前和之后显示一个命令行界面,让你控制执行,并检查图的内部状态。 - 允许你为张量值注册特殊的过滤器,以便于诊断问题。
在这个例子中,我们已经注册了一个称为 tfdbg.has_inf_or_nan 的张量过滤器,它简单地确定中间张量是否有包含 nan 或 inf 值的中间张量(从输入到输出的路径中的张量,而不是 Session.run() 时的输入和输出张量)。该过滤器用于 nans,infs 是一个常见的使用情况,我们使用 debug_data 模块来发送它。
注意:你也可以编写自定义的过滤器。到 tfdbg.DebugDumpDir.find 中查看其他相关信息。
使用 tfdbg 调试模型训练
让我们再次训练模型,但这次带上了 --debug 标志:
python -m tensorflow.python.debug.examples.debug_mnist --debug
调试包装器会话将在你要调用第一个 Session.run() 时提示你,并在屏幕上显示一些值,其中包含有关获取的张量(Fetches)的信息,以及供给数据所对应的字典参数(Feeds)。
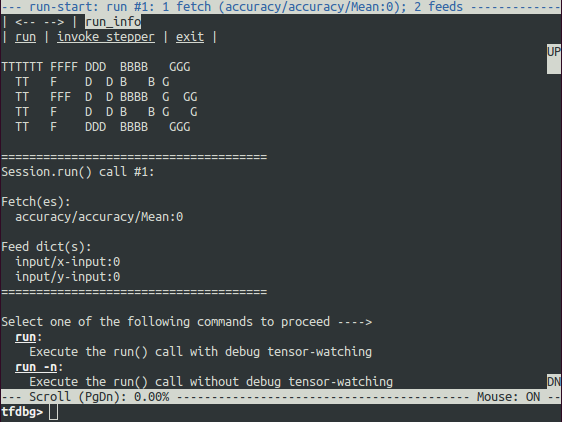
这就是我们所说的 run-start CLI。在执行任何操作之前,它会将 Session.run 调用所需要输入的 Fetch 和 Feed 张量列出来。
如果屏幕尺寸太小,无法完整显示消息的内容,你可以调整其大小。
使用 PageUp/PageDown/Home/End 键来导航屏幕输出,当然也可以使用 Fn + Up/Fn + Down/Fn + Right/Fn + Left,虽然很多键盘没有这些键。
在命令提示符下输入 run 命令(或者只是 r)让终端继续运行:
tfdbg> run
run 命令会导致 tfdbg 执行,直到下一个 Session.run() 调用结束,该调用使用测试数据集计算模型的准确性。tfdbg 加载运行时图时转储所有中间张量。运行结束后,tfdbg 将显示运行结束后在命令行界面中显示所有的中间张量值。例如:
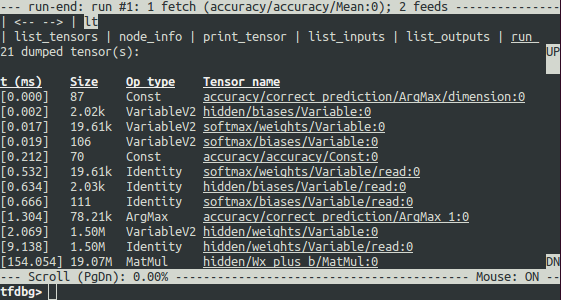
在执行运行完 run 之后,也可以通过运行命令 lt 获得张量列表。
tfdbg CLI 常用的命令
在 tfdbg> 提示符下(参考 tensorflow/python/debug/examples/debug_mnist.py 中的代码),尝试以下命令:
| Command | Syntax or Option | Explanation | Example |
|---|---|---|---|
lt |
列出转储中间张量 | lt |
|
-n <name_pattern> |
列出名称与给定正则表达式模式匹配的转储张量。 | lt -n Softmax.* |
|
-t <op_pattern> |
列出操作类型与给定正则表达式模式匹配的转储张量。 | lt -t MatMul |
|
-f <filter_name> |
列出与给定字符串匹配的转储张量。 | lt -f has_inf_or_nan |
|
-f <filter_name> -fenn <regex> |
列出只传递注册张量过滤器的张量,不包括与正则表达式匹配的名称的节点。 | lt -f has_inf_or_nan -fenn .*Sqrt.* |
|
-s <sort_key> |
根据 sort_key 对输出排序,sort_key 可能的值为 timestamp(默认)、dump_size、op_type 和 tensor_name。 |
lt -s dump_size |
|
-r |
按相反顺序排列。 | lt -r -s dump_size |
|
pt |
打印转储张量的值。 | ||
pt <tensor> |
打印张量值。 | pt hidden/Relu:0 |
|
pt <tensor>[slicing] |
使用 numpy-style数组切片来打印张量中的子数组。 | pt hidden/Relu:0[0:50,:] |
|
-a |
不截断打印结果很长的张量(大的张量可能需要花很长的时间来打印)。 | pt -a hidden/Relu:0[0:50,:] |
|
-r <range> |
筛选出指定数值区间内的元素。如果有多个区间可以结合使用。 | pt hidden/Relu:0 -a -r [[-inf,-1],[1,inf]] |
|
-n <number> |
打印转储对应于指定的 基于 0 的转储数值。被具有多转储的张量所需。 | pt -n 0 hidden/Relu:0 |
|
-s |
打印数值张量的摘要(仅适用于布尔型和数字类型的非空张量,如 int * 和 float *)。 |
pt -s hidden/Relu:0[0:50,:] |
|
-w |
使用 numpy.save() 将张量(可能已分片)的值写入一个 Numpy 文件 |
pt -s hidden/Relu:0 -w /tmp/relu.npy |
|
@[coordinates] |
根据坐标值导航到 pt 命令输出值的指定位置。 |
@[10,0] or @10,0 |
|
/regex |
less 风格的正则表达式搜索。 | /inf |
|
/ |
滚动到下一个正则表达式匹配的结果(如果有)。 | / |
|
pf |
打印 Session.run 的参数 feed_dict。 |
||
pf <feed_tensor_name> |
打印供给数据的值。 还要注意,pf 命令具有 -a,-r 和 -s 标志(未在下面列出),这些标志与 pt 命令的那些同名标志具有相同的语法和语义。 |
pf input_xs:0 |
|
| eval | 运行 Python 和 numpy 表达式。 | ||
eval <expression> |
运行 Python / numpy 表达式,用 np 来表示 numpy,调试的张量名需要加上到引号。 | eval "np.matmul((`output/Identity:0` / `Softmax:0`).T, `Softmax:0`)" |
|
-a |
打印表达式返回的结果,就算结果很长也不截断。 | eval -a 'np.sum(`Softmax:0`, axis=1)' |
|
-w |
使用 numpy.save() 将评估器的结果写入一个 Numpy 文件 |
eval -a 'np.sum(`Softmax:0`, axis=1)' -w /tmp/softmax_sum.npy |
|
ni |
显示结点信息 | ||
-a |
在输出中包含结点属性。 | ni -a hidden/Relu |
|
-d |
列出结点可用的调试转储。 | ni -d hidden/Relu |
|
-t |
显示结点创建时,Python 堆栈的变化。 | ni -t hidden/Relu |
|
li |
列出结点的输入 | ||
-r |
递归的列出结点的输入(输入树)。 | li -r hidden/Relu:0 |
|
-d <max_depth> |
限制 -r 模式下的递归深度。 | li -r -d 3 hidden/Relu:0 |
|
-c |
包含控制输入 | li -c -r hidden/Relu:0 |
|
-t |
显示输入节点的操作类型 | li -t -r hidden/Relu:0 |
|
lo |
列出结点输出的接收者 | ||
-r |
递归地列出节点的输出接收者(输出树)。 | lo -r hidden/Relu:0 |
|
-d <max_depth> |
限制 -r 模式下的递归深度。 |
lo -r -d 3 hidden/Relu:0 |
|
-c |
通过控制边缘列出多个接收者。 | lo -c -r hidden/Relu:0 |
|
-t |
Show op types of recipient nodes. | lo -t -r hidden/Relu:0 |
|
ls |
列出创建结点时所涉及的 Python 源文件。 | ||
-p <path_pattern> |
输出匹配给定正则表达式路径的源文件。 | ls -p .*debug_mnist.* |
|
-n |
输出匹配给定正则表达式的节点名称。 | ls -n Softmax.* |
|
ps |
打印 Python 源文件 | ||
ps <file_path> |
打印 Python 源文件 source.py,并标记创建了结点(如果有的话)的那些代码行。 | ps /path/to/source.py |
|
-t |
打印张量的注释,而不是默认的节点。 | ps -t /path/to/source.py |
|
-b <line_number> |
从给定行开始标记源码 source.py。 | ps -b 30 /path/to/source.py |
|
-m <max_elements> |
限制每行标记处显示的最大元素个数。 | ps -m 100 /path/to/source.py |
|
run |
继续下一个 Session.run() | run |
|
-n |
执行下一个 Session.run 而不进行调试,-n 添加到 run 命令的右边。 |
run -n |
|
-t <T> |
在没有调试的情况下执行 Session.run T - 1 次,然后运行调试。 -t 添加到 run 命令的右边。 |
run -t 10 |
|
-f <filter_name> |
继续执行 Session.run,直到任何中间张量触发指定的 Tensor 过滤器(导致过滤器返回 True)。 |
run -f has_inf_or_nan |
|
-f <filter_name> -fenn <regex> |
继续执行 Session.run,直到任何中间张量的节点名称与正则表达式不匹配时,触发指定的张量过滤器(导致过滤器返回 true)。 |
run -f has_inf_or_nan -fenn .*Sqrt.* |
|
--node_name_filter <pattern> |
执行下一个 Session.run,只查看名称与给定正则表达式模式匹配的结点。 |
run --node_name_filter Softmax.* |
|
--op_type_filter <pattern> |
执行下一个 Session.run,只查看符合给定正则表达式模式的操作类型的结点。 |
run --op_type_filter Variable.* |
|
--tensor_dtype_filter <pattern> |
执行下一个 Session.run,仅列出与给定正则表达式模式匹配的数据类型(dtypes)的转储张量。 |
run --tensor_dtype_filter int.* |
|
-p |
在性能分析模式下执行下一个 Session.run |
run -p |
|
ri |
显示当前运行的信息,包含获取的张量和输入(feed)的张量。 | ri |
|
config |
设置或显示 TFDBG UI 当前的配置信息。 | ||
set |
设置配置项,譬如 {graph_recursion_depth, mouse_mode}。 |
config set graph_recursion_depth 3 |
|
show |
显示当前的 UI 配置信息。 | config show |
|
version |
打印 TensorFlow 的版本信息及其关键依赖项。 | version |
|
help |
打印通用的帮助信息 | help |
|
help <command> |
打印命令所对应的帮助信息 | help lt |
请注意,每当你输入命令时,都会显示新的屏幕输出。 这有点类似于浏览器中的网页。 你可以通过点击命令行界面左上角附近的<-- 和 --> 文字箭头在这些屏幕之间导航。
tfdbg CLI 的其他特性
除了以上列出的命令之外,tfdebug CLI 还提供了以下的额外特性:
- 要导航到之前输入的 tfdbg 命令,可输入几个字符后,使用向上或向下按键。tfdbg 将显示以这些字符开头的命令的历史记录。
- 要浏览屏幕输出的历史记录,请执行以下操作之一:
- 使用
prev和next命令。 - 点击屏幕左上角附近的带下划线的
<--和-->链接。
- 使用
- 使用 Tab 自动补全命令和一些命令的参数。
要将屏幕输出重定向到文件而不是屏幕,可以 bash 样式重定向输出。例如,下面命令将 pt 命令的输出重定向到
/tmp/xent_value_slices.txt文件:tfdbg> pt cross_entropy/Log:0[:, 0:10] > /tmp/xent_value_slices.txt
找到 nans 和 infs
在第一个 Session.run() 调用中,碰巧没有出现有问题的数值。你可以使用命令 run 或 r 进入下一次运行。
提示:如果你反复输入
run或r,则可以依次的调用 Session.run()。你也可以使用 -t 标志来调用多次 Session.run(),例如:
tfdbg> run -t 10
不必在每次 Session.run() 之后,在 run-end 界面中重复输入 run 并手动搜索 nans 和 infs(例如,通过使用上表中所示的 pt 命令),你可以使用以下命令让调试器重复执行 Session.run() 直到第一个 nan 或 inf 值显示在图中。这在某些程序语言调试器中类似于条件断点:
tfdbg> run -f has_inf_or_nan
注意:上述命令可以正常工作,因为我们已经注册了一个名为
has_inf_or_nan的nans 和infs 的过滤器 (如前所述)。 如果你已经注册了其他过滤器,你可以使用 “run -f” 来运行 tfdbg,直到任何张量器触发该过滤器(导致过滤器返回 True)。
def my_filter_callable(datum, tensor):# A filter that detects zero-valued scalars.return len(tensor.shape) == 0 and tensor == 0.0sess.add_tensor_filter('my_filter', my_filter_callable)然后在 tfdbg run-start 提示符下继续运行,直到你的过滤器被触发:
tfdbg> run -f my_filter
有关 add_tensor_filter() 传入的 Callable 的返回值和签名的更多信息,请参见此API文档。
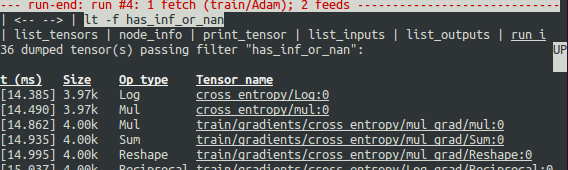
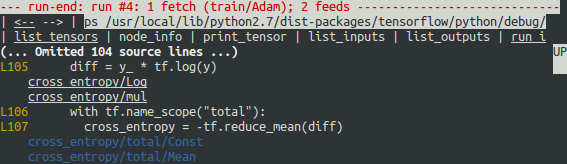
当屏幕显示在第一行显示时,在第四次 Session.run() 调用期间首先触发 has_inf_or_nan 过滤器:计算图上运行的一个 Adam Optimizer 前向-反向训练过程。在这次运行中,36 个(总共 95 个)中间张量包含 nan 或 inf 值。这些张量按时间顺序列出,其时间戳显示在左侧。在列表的顶部,你可以看到第一个张量,其中首先出现错误的数值是:cross_entropy / Log:0。
要查看张量的值,请单击带下划线的张量名称 cross_entropy / Log:0 或输入等效命令:
tfdbg> pt cross_entropy/Log:0
向下滚动一点,你会注意到一些分散的 inf 值。 如果 inf 和 nan 的实例难以察觉,你可以使用以下命令执行正则表达式搜索并高亮显示输出:
tfdbg> /inf
或者,以下面这种方式搜索:
tfdbg> /(inf|nan)
你还可以使用 -s 或 --numeric_summary 命令得到张量数值类型的快速摘要:
tfdbg> pt -s cross_entropy/Log:0
从摘要中,你可以看到 cross_entropy / Log:0 张量的 1000 个元素中有几个元素是 -infs(负的无穷大)。
为什么这些负无穷大的值会出现?要进一步调试,请通过单击顶部下划线的 node_info 菜单项来显示有关结点的 cross_entropy / Log 的更多信息,或输入等效的 node_info(ni)命令:
tfdbg> ni cross_entropy/Log
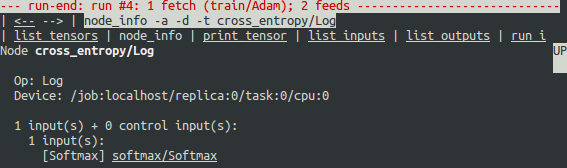
你可以看到该结点的操作类型为 Log,并且结点的输入是 Softmax。运行以下命令,仔细观察输入张量:
tfdbg> pt Softmax:0
检查输入张量中的值,搜索零:
tfdbg> /0\.000
确实有零。现在很清楚,不良数值的起源是采用零日志的结点 cross_entropy / Log。要了解 Python 源代码中的罪魁祸首行,请使用 ni 命令的 -t 标记来追溯构造此结点的代码位置:
tfdbg> ni -t cross_entropy/Log
如果你点击屏幕顶部的 “node_info”,tfdbg 会自动显示此结点构造的回溯。
从追溯中,你可以看到,此操作结点是在下面这一行中创建的:debug_mnist.py:
diff = y_ * tf.log(y)
tfdbg 有一个特性,可以轻松跟踪张量和操作是起源于 Python 源文件中的哪一行。tfdbg 可以在产生错误的代码行下面标记它产生的张量或者操作。要使用此特性,只需单击 ni -t <op_name> 命令的堆栈跟踪输出中的下划线行号,或使用 ps(或 print_source)命令,例如:ps /path/to/source.py。 例如,以下屏幕截图显示了 ps 命令的输出。
解决问题
要解决此问题,将 debug_mnist.py 错误行的代码:
diff = -(y_ * tf.log(y))
修改为系统内建的 softmax 交叉熵函数:
diff = tf.losses.softmax_cross_entropy(labels=y_, logits=logits)
带上 --debug 标记,重新运行:
python -m tensorflow.python.debug.examples.debug_mnist --debug
在 tfdbg 提示符下,输入以下命令:
run -f has_inf_or_nan`
确认没有张量被标记为包含 nan 或 inf 值,并且准确度现在继续上升而不是卡住,意味着我们的修改是成功的。
调试 TensorFlow 的 Estimators
这个章节解释了如何调试使用了 Estimator API 来调试 TensorFlow 程序。这些 API 的便利之处部分在于它们是内部管理 Session。 这使得前面部分中描述的 LocalCLIDebugWrapperSession 不适用。幸运的是,你仍然可以使用 tfdbg 提供的特殊钩子进行调试。
tfdbg 能够调试 tf-learn Estimator 的 tf.estimator.Estimator.train、tf.estimator.Estimator.evaluate 和 tf.estimator.Estimator.predict 方法。可以创建一个 LocalCLIDebugHook,并在 hooks 的参数中使用它。例如:
# 首先,让编译时的构建(BUILD)目标依赖于 "//tensorflow/python/debug:debug_py"# (如果你是使用 pip install 安装的 TensorFlow,那么你就不需要担心构建时的依赖的问题)from tensorflow.python import debug as tf_debug# 创建一个 LocalCLIDebugHook 并作为 monitor 参数的值传递给函数 fit()。hooks = [tf_debug.LocalCLIDebugHook()]# 调试 `train`:classifier.train(input_fn,steps=1000,hooks=hooks)
同样,为了调试 Estimator.evaluate() 和 Estimator.predict(),可以这样设置 hooks 参数的钩子,如下方代码所示:
# 调试 `evaluate`:accuracy_score = classifier.evaluate(eval_input_fn,hooks=hooks)["accuracy"]# 调试 `predict`:predict_results = classifier.predict(predict_input_fn, hooks=hooks)
debug_tflearn_iris.py 里面包含了如何将 tfdbg 与 Estimator 一起使用的完整示例。要运行这个例子,请输入下面的命令:
python -m tensorflow.python.debug.examples.debug_tflearn_iris --debug
LocalCLIDebugHook 允许你配置 watch_fn 来监视特定 Tensors 在不同次 Session.run() 调用之间的变化,而这个函数需要和 fetch 和 feed_dict 其他状态一样传递到 run 调用中,更多的信息可以查看 tfdbg.DumpingDebugWrapperSession.__init__。
使用 TFDBG 调试 Keras 模型
要在 tf.keras 中使用 TFDBG,需要让 Keras 后端使用一个 TFDBG-wrapped 的 Session 对象。下面是一个使用命令行界面包装器的例子:
import tensorflow as tffrom tensorflow.python import debug as tf_debugtf.keras.backend.set_session(tf_debug.LocalCLIDebugWrapperSession(tf.Session()))# 定义你的 keras 模型,变量名称为 “model”。# 调用 `fit()`、'evaluate()` 和 `predict()` 方法将进入 TFDBG CLI。model.fit(...)model.evaluate(...)model.predict(...)
通过稍作修改,前面的代码示例也适用于针对 TensorFlow 后端运行的非 TensorFlow 版本的 Keras。你只需要用 keras.backend 替换 tf.keras.backend。
使用 TFDBG 调试 tf-slim
TFDBG 支持使用 tf-slim 调试训练和评估。详述如下,训练和评估需要稍微有点不同的调试工作流
在 tf-slim 中调试训练
为了调试训练过程,我们为 slim.learning.train() 中的 session_wrapper 参数提供了 LocalCLIDebugWrapperSession 对象,例子如下:
import tensorflow as tffrom tensorflow.python import debug as tf_debug# ... 创建图和训练操作的代码 ...tf.contrib.slim.learning.train(train_op,logdir,number_of_steps=10,session_wrapper=tf_debug.LocalCLIDebugWrapperSession)
在 tf-slim 中调试评估
为了调试评估过程,TensorFlow 提供了 LocalCLIDebugHook 填入 slim.evaluation.evaluate_once() 的 hooks 参数。比如:
import tensorflow as tffrom tensorflow.python import debug as tf_debug# ... 用来创建流图,验证和最终的操作....tf.contrib.slim.evaluation.evaluate_once('',checkpoint_path,logdir,eval_op=my_eval_op,final_op=my_value_op,hooks=[tf_debug.LocalCLIDebugHook()])
离线调试远程运行的 Session
很多时候,你的模型正运行在远程机器上,或你无法用终端访问一个进程。为了在这种情况下调试模型,你可以使用 tfdbg 中的 offline_analyzer 库(下面将会描述)。 它可以对转储张量的文件夹进行操作,并且兼容低层的 Session API 和高层的 Estimators API。
调试远程的 tf.Sessions
如果你直接与 python 中的 tf.Session API 进行交互,你可以配置 RunOptions 协议(proto),它将会作为参数传递给 tfdbg.watch_graph 方法。当发生 Session.run() 调用(以较慢的性能为代价)时,这将导致中间张量和运行时的图转储到你选择的共享存储位置。 例子如下:
from tensorflow.python import debug as tf_debug# ... 初始化计算图和会话的代码...run_options = tf.RunOptions()tf_debug.watch_graph(run_options,session.graph,debug_urls=["file:///shared/storage/location/tfdbg_dumps_1"])# 确定已经为不同的 run() 调用指定不同的目录。session.run(fetches, feed_dict=feeds, options=run_options)
之后,在终端访问的环境中(例如,可以访问上面代码中指定的共享存储位置的本地计算机),你可以使用 tfdbg 中的 offline_analyzer 模块来加载和检查共享存储中的转储目录中的数据。例子如下:
python -m tensorflow.python.debug.cli.offline_analyzer \--dump_dir=/shared/storage/location/tfdbg_dumps_1
Session 的 DumpingDebugWrapperSession 包装器提供了一种更简单,更灵活的方法来生成可以离线分析的文件系统转储。 要使用它,只需将你的会话包装在一个 tf_debug.DumpingDebugWrapperSession 中。 例如:
# 首先,让你编译时构建(BUILD)目标依赖于 "//tensorflow/python/debug:debug_py"# (如果你是使用 pip install 安装的 TensorFlow,那么你就不需要担心构建时的依赖的问题)from tensorflow.python import debug as tf_debugsess = tf_debug.DumpingDebugWrapperSession(sess, "/shared/storage/location/tfdbg_dumps_1/", watch_fn=my_watch_fn)
watch_fn 接受一个 Callable 来允许你来监视特定 Tensors 在不同次 Session.run() 调用之间的变化,而这个函数需要和 fetch 和 feed_dict 其他状态一样传递到 run 调用中。
C++ 和其他语言
如果你的模型代码用 C ++ 或其他语言编写,你还可以修改 RunOptions 的 debug_options 字段来生成可以离线检查的调试转储。有关详细信息,请参阅此协议(proto)的定义。
调试远程运行的 Estimator
如果你的远程 TensorFlow 服务器运行着 Estimator,则可以使用非交互式 DumpingDebugHook。例子如下:
# 首先,让你的 BUILD 对象依赖于 "//tensorflow/python/debug:debug_py"# (如果你是使用 pip install 安装的 TensorFlow,那么你就不需要担心构建时的依赖的问题)from tensorflow.python import debug as tf_debughooks = [tf_debug.DumpingDebugHook("/shared/storage/location/tfdbg_dumps_1")]
那么这个钩子可以像本文前面所述的 LocalCLIDebugHook 示例一样来使用。当 Estimator 开始训练、评估或预测时,tfdbg 会创建具有如下命名模式的目录:/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>。每个目录对应于一次 Session.run() 调用,进而调用 fit() 或 evaluate()。你可以使用 tfdbg 提供的 offline_analyzer 以离线方式加载这些目录并在命令行界面中进行检查。例如:
python -m tensorflow.python.debug.cli.offline_analyzer \--dump_dir="/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>"
常见问题
Q:执行 lt 命令输出内容时,其左侧的时间戳可以反映非调试情况下 Session 中的实际性能吗?
A:不可以的,调试器将附加的专用调试结点插入计算图中以记录中间张量的值。这些结点会减慢计算图的执行。如果你对分析你模型的性能感兴趣,请参考下列方法
- tfdbg 的性能分析模式:
tfdbg> run -p。 - tfprof 和其他的 TensorFlow 性能分析工具。
Q:如何在 Bazel 中将 tfdbg 与我的 Session 链接?为什么会看到诸如 “ImportError:cannot import name debug” 之类的错误?
A:在你编译构建(BUILD)的规则中,声明依赖关系:“/tensorflow:tensorflow_py” 和 “/tensorflow/python/debug:debug_py” 。 其中,第一个依赖是你使用 TensorFlow 即使没有调试器支持的依赖关系;第二个依赖是用来启用调试器的。 然后,在你的 Python 文件中,添加下面的代码:
from tensorflow.python import debug as tf_debug# 然后用 local-CLI 包装器包装你的 TensorFlow 会话。sess = tf_debug.LocalCLIDebugWrapperSession(sess)
Q:tfdbg 是否可以帮助调试运行时的错误,如形状不匹配?
A:是的。 tfdbg 拦截运行时由操作生成的错误,并在命令行界面中向用户显示带有一些调试指令的错误。参见示例:
# 调试矩阵乘法中的形状不匹配python -m tensorflow.python.debug.examples.debug_errors \--error shape_mismatch --debug# 调试未初始化的变量python -m tensorflow.python.debug.examples.debug_errors \--error uninitialized_variable --debug
Q:如何让 tfdbg 包装的 Sessions 或钩子仅对主线程进行调试呢?
A:这是一个常见的用例,其中 Session 对象同时从多个线程使用。 通常来说,子线程处理后台任务,例如执行入队操作。这时,你一般只想调试主线程(或者只是一个子线程)。 你可以使用 LocalCLIDebugWrapperSession 中的 thread_name_filter 参数来实现线程选择性调试。 例如,想要只调试主线程,构造一个包装的会话,如下所示:
sess = tf_debug.LocalCLIDebugWrapperSession(sess, thread_name_filter="MainThread$")
上述示例依赖于一个事实,即 Python 主线程的默认名称为 MainThread。
Q:我正在调试的模型非常大。 tfdbg 转储的数据填满了我磁盘空闲的空间。 我该怎么办?
A: 在以下情况下,你可能会遇到此问题:
- 具有许多中间张量的模型
- 非常大的中间张量
- 很多的
tf.while_loop迭代
有三种可能的解决方法或解决方案:
LocalCLIDebugWrapperSession和LocalCLIDebugHook的构造函数提供一个参数dump_root,以指定 tfdbg 转储调试数据的路径。你可以使用它来让 tfdbg 将调试数据转储在具有较大可用空间的磁盘上。 例如:
# LocalCLIDebugWrapperSessionsess = tf_debug.LocalCLIDebugWrapperSession(dump_root="/with/lots/of/space")# For LocalCLIDebugHookhooks = [tf_debug.LocalCLIDebugHook(dump_root="/with/lots/of/space")]
确保 dump_root 指向的目录为空或不存在。tfdbg 会在退出之前清理转储目录。
- 减小运行期间使用的 batch 大小。
使用 tfdbg 的
run命令中的过滤选项,即只观察计算图中的特定结点。 例如:tfdbg> run --node_name_filter .*hidden.*tfdbg> run --op_type_filter Variable.*tfdbg> run --tensor_dtype_filter int.*
上面的第一个命令仅监视其名称与正则表达式模式(
.*hidden.*)匹配的结点。 第二个命令只监视名称与模式(Variable.*)匹配的操作结点。第三个只监视dtype与模式(int.*)匹配的张量(例如,int32)。
Q:我正在调试一个生产了不必要的无穷大或 NAN 的模型。即使在完全正常的条件下,也会在它们的输出张量中生成无穷大或 NANs。我如何在运行 run -f has_inf_or_nan 时跳过那些节点?
A:使用 --filter_exclude_node_names(简称 -fenn)标志位。例如,如果你知道有一个节点的名称与正则表达式 .*Sqrt.* 匹配,为了将节点改成不会生成无穷大或 NANs,而不管模型的行为是否正确,则可使用命令 run -f has_inf_or_nan -fenn .*Sqrt.* 将节点排除在无穷大/NAN 运行中。
Q:为什么无法在 tfdbg CLI 中选择文本?
A:这是因为 tfdbg CLI 默认启用终端中的鼠标事件。 这种鼠标掩码模式覆盖了默认终端交互过程,包括文本选择。你可以使用命令 mouse off 或 m off 重新启用文本选择。
Q:为什么当我调试如下代码时,tfdbg CLI 没有显示转储张量?
a = tf.ones([10], name="a")b = tf.add(a, a, name="b")sess = tf.Session()sess = tf_debug.LocalCLIDebugWrapperSession(sess)sess.run(b)
A:你看到没有数据转储的原因是因为执行的 TensorFlow 图中的每个节点都被 TensorFlow 运行时常数折叠起来了。在这个示例中,a 是一个常数张量;而且,获取的张量 b 实际上也是一个常数张量。因此,TensorFlow 为了优化图的运行性能,会将 a 和 b 折叠到一个结点上去。这也是为什么 tfdbg 不会产生任何中间张量转储数据的原因。但是,如果 a 是一个 tf.Variable 的话,如下例子所示:
import numpy as npa = tf.Variable(np.ones(10), name="a")b = tf.add(a, a, name="b")sess = tf.Session()sess.run(tf.global_variables_initializer())sess = tf_debug.LocalCLIDebugWrapperSession(sess)sess.run(b)
则不会发生常数折叠,tfdbg 应该是会显示转储的中间张量的。
Q:有用于 tfdbg 的 GUI 吗?
A:有。TensorBoard 调试插件是 tfdbg 的 GUI。它提供了计算图的检查,张量值的实时可视化,张量和条件断点的延续,以及张量和条件断点绑定到它们的图构造源代码中,所有这些都在浏览器环境中。想要开始尝试,请访它的 README。

若有收获,就点个赞吧
0 人点赞
