文章:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
什么是BN层
BN层(Batch Normalization)顾名思义是对一个batch的数据进行标准化,一般用在网络的中间层,其计算方式如下:
主要步骤:
- 计算每一个batch的均值;
- 计算每一个batch的方差;
- 使用计算得到的均值和方差,对数据进行归一化操作,获得0~1分布;
- 尺度变换与偏移:归一化之后的数据会被限制在正态分布下,使得网络的表达能力下降,因此引入尺度因子和平移因子(
 )使其具备了保留学习到的特征的能力(
)使其具备了保留学习到的特征的能力( ,此时恢复为原始特征)。
,此时恢复为原始特征)。
CNN中的BN层对batch中的channel做归一化,归一化维度为[N,H,W]。
第1个样本的第一个通道,加上第2个样本的第一个通道,……,第N个样本的第一个通道,得到第一个通道的均值(除以NHW而不是单纯除以N,最后得到的是代表这个batch的第一个通道的平均值的数字,而不是一个H×W的矩阵)。同样的方法求出方差。
BN的出发点
神经网络训练过程中,由于参数不断更新,除了输入层的数据外,后面网络每一层的输入数据分布是一直在发生变化的。而神经网络学习本质是学习到数据的分布,若每批训练数据的分布各不相同,那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练收敛速度。网络中间层在训练过程中,中间层数据分布的改变称之为“Internal Covariate Shift”。Batch Normalization的提出就是要解决该问题。
covariate shift:这个现象指的是训练集数据分布与预测集数据分布不一致。
主要作用
- 加快网络的训练收敛速度(网络参数初始化不敏感,允许更大的学习率);
- 控制梯度爆炸防止梯度消失;
- 增强泛化性能,防止过拟合(减少dropout,L2正则的依赖);
- 可以把训练数据彻底打乱。防止了每批训练的时候,某一个样本经常被挑选到。论文中指出这个操作可以提高1%的精度。
- 不再需要局部响应归一化。
几个概念
梯度消失
网络前向传播过程中,如果网络使用sigmod激活函数,经过sigmod单元,需要乘sigmoid的梯度,而sigmoid的梯度最大是0.25,若前向传播网络层的参数 ,则越靠近输入层的梯度就越小,导致网络训练过程中仅更新只是靠近输出层的部分,靠近输入层的部分几乎不更新,这就是梯度消失。
,则越靠近输入层的梯度就越小,导致网络训练过程中仅更新只是靠近输出层的部分,靠近输入层的部分几乎不更新,这就是梯度消失。
梯度爆炸
与梯度消失类似,若前向传播过程中的网络层参数 很大,大过了sigmoid带来的梯度减小的影响,即
很大,大过了sigmoid带来的梯度减小的影响,即 ,则在前向传播过程中梯度不断增加,导致梯度过大,这个现象就是梯度爆炸。
,则在前向传播过程中梯度不断增加,导致梯度过大,这个现象就是梯度爆炸。
过拟合
网络过度拟合训练数据,泛化性能差,对训练集外的数据无法进行良好的预测。
作用分析
加速网络训练收敛
在深度神经网络中,每一层的输入数据分布是一直在发生变化,将会导致网络非常难收敛和训练。若每个batch输入数据的分布一致,则网络可以更快的拟合这个分布,加快收敛速度。如下图所示,若每次输入数据的分布不同,假如当前网络层已经找到一个划分左上角数据的超平面,当下一批次数据是另一种分布(右下角)网络又要去学习划分这个分布数据的超平面。这样就会造成网络不断抖动,难以收敛。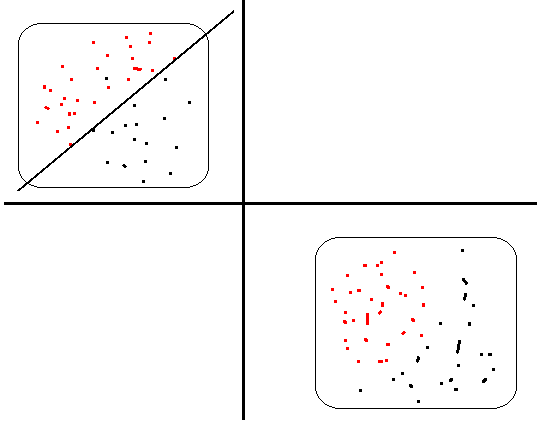
对网络参数初始化不敏感
训练数据如果分布在右上角,我们在初始化网络参数w和b的时候,可能得到的分界面是左下角那些线,需要经过训练不断调整才能得到穿过数据点的分界面,这个就使训练过程变慢了;如果我们将数据标准化后,得到的数据点就是坐标上的一个圆形分布,如图中间的数据点,这时候随便初始化一个w,b设置为0,得到的分界面已经穿过数据了,因此训练调整,训练进程会加快,故对网络参数初始化不敏感。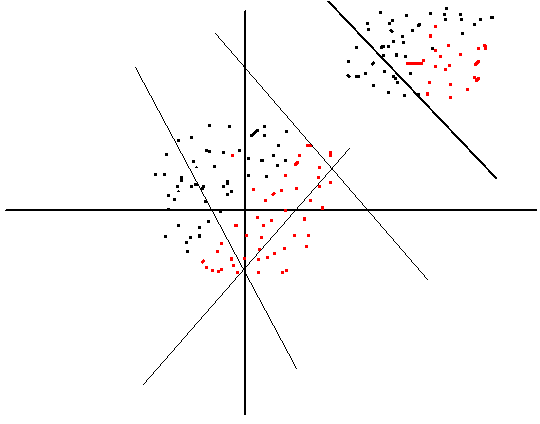
允许使用更大的学习率
未采用BN时,较大的学习率会导致输出结果的变化大,也就是中间层的输入分布变化大,BN解决了这个问题,缓解了网络对学习率的敏感性,可采用较大的学习率,加速网络学习。
控制梯度消失和梯度爆炸
经过BN后,网络层的输出值较小在0附近,这样能使得sigmoid的梯度更大,从而缓解梯度消失。
通过规范化操作将输出x规范化到均值为0,方差为1保证网络的稳定性。反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
防止过拟合
在网络的训练中,BN的使用使得一个mini-batch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
BN层的位置
BN层一般用在线性层和卷积层后面,而不是放在非线性单元后。因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。
BN中的参数更新
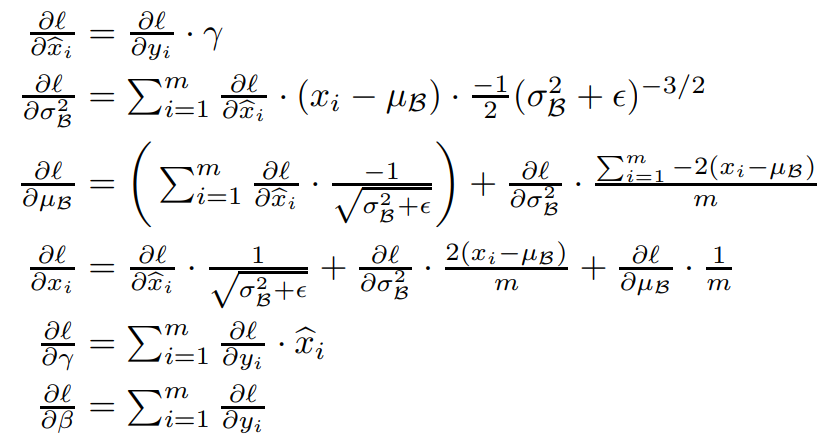
模型测试阶段的BN
在测试阶段,所有参数的取值是固定的,对BN层而言,意味着均值μ、方差σ、γ、β都是固定值。γ和β比较好理解,随着训练结束,两者最终收敛,预测阶段使用训练结束时的值即可。对于μ和σ,在训练阶段,它们为当前mini batch的统计量,随着输入batch的不同,μ和σ一直在变化。在测试阶段,输入数据可能只有1个,该使用哪个μ和σ,或者说,每个BN层的μ和σ该如何取值?一个建议的方案是采用训练收敛最后几批mini-batch的μ和σ的期望,作为预测阶段的μ和σ(下图7-11)。
参考

若有收获,就点个赞吧
0 人点赞
