前言
文章简单介绍了InnoDB存储引擎支持的行格式,不会深入探讨各实现细节。
由于个人水平有限,难免有很多疏漏和错误的地方,还请大家多多原谅,更多详细资料请移步参考资料。
一,为什么?
- 我们为什么需要学习行格式,价值和收益在哪里?
- 为什么行格式是这样设计的,或者说行格式应该如何设计?
1,我们为什么需要学习行格式?
The row format of a table determines how its rows are physically stored, which in turn can affect the performance of queries and DML operations. As more rows fit into a single disk page, queries and index lookups can work faster, less cache memory is required in the buffer pool, and less I/O is required to write out updated values. —- MySql8.0 Document
简单讲就是行格式决定了CRUD的基础性能。那我们只有了解MySQL底层数据是如何存储的,我们才能对程序性能有个直观的判断。
2,简单考虑行格式应该如何设计?
- 考虑可空类型如何表示及存储。
- 考虑变长数据类型如何表示及存储。
- 考虑字符集对变长数据类型的影响。
…更新时产生的碎片怎么更少,事务等怎么实现这里不涉及。
二,怎么做?
1. 假设自己实现行格式
首先我们简单的把数据类型分为定长,变长,可空几种,然后分别讨论应该如何存储
a)全定长数据类型时
这种情况比较简单,因为列的长度都是固定的,我们可以直接根据表结构,计算出每列数据的位置。
CREATE TABLE `fixed_columns` (`id` int NOT NULL,`id2` int NOT NULL,PRIMARY KEY (`id`))CHARACTER SET = asciiINSERT INTO `fixed_columns`(id, id2) VALUES(1, 2);
对于上组数据,我们可以简单推测出其存储格式应该是:
| 1(4个字节) | 2(4个字节) |
|---|---|
上述结构,我们可以根据表的结构和列的大小,快速计算出列值存放的位置。
那我可不可以不读取表结构来计算列的大小呢?答案当然是可以的,那就需要我们有额外的字段来存储每个字段的位置信息。
| 字段长度 | id | id2 | |
|---|---|---|---|
| 4 | 4 | 1 | 2 |
当然,上述结构还有很多细节方面的东西没有明确,比如存放字段长度位置的列所占大小等,还是老话,细节就不讨论了。
b)包含变长数据时
CREATE TABLE `variable_columns` (`id` int NOT NULL,`id2` varchar(10) NOT NULL,`id3` varchar(10) NOT NULL,PRIMARY KEY (`id`))CHARACTER SET = asciiINSERT INTO `variable_columns`(id, id2, id3) VALUES(1, 'aaa', 'bb');
对于上组数据,定长部分,按照我们之前的逻辑,其存储格式应该是:
| 1(4个字节) |
|---|
那变长部分应该如何存储?
笨办法:不管多长,直接按最大长度存储,不足补0,这样处理逻辑跟定长数据一致且对更新友好。但是会浪费存储空间。
好点的版本:存[真实数据]+[字段长度],那应该如何组织呢?
| 字段长度 | id | id2 | id3 | ||
|---|---|---|---|---|---|
| 4 | 3 | 2 | 1 | ‘aaa’ | ‘bb’ |
c)包含可空数据时
CREATE TABLE `null_columns` (`id` int NOT NULL,`id2` varchar(10) NOT NULL,`id3` varchar(10) NOT NULL,`id4` varchar(10),PRIMARY KEY (`id`))CHARACTER SET = asciiINSERT INTO `null_columns`(id, id2, id3) VALUES(1, 'aaa', 'bb');
对于上组数据,定长及变长部分,按照我们之前的逻辑,其存储格式应该是:
| 字段长度 | id | id2 | id3 | ||
|---|---|---|---|---|---|
| 4 | 3 | 2 | 1 | ‘aaa’ | ‘bb’ |
那可空的数据该如何存储?
笨办法:把可空字段等同于字段长度为0的字段,那格式如下
| 字段长度 | id | id2 | id3 | |||
|---|---|---|---|---|---|---|
| 4 | 3 | 2 | 0 | 1 | ‘aaa’ | ‘bb’ |
上面我们简单探讨了下如何设计一个行格式,但是离优秀的行格式差距还很大,肉眼可见的可以优化的空间很多,但我们的目的不是自定义一个行格式,而是作为一个开发者来看,我们如何自己解决这个问题。其次大家可以充分发挥想想,设计一种自己的行格式,一起分享分享。
2. MySQL支持的行格式
Row Format Compact Storage Characteristics Enhanced Variable-Length Column Storage Large Index Key Prefix Support Compression Support Supported Tablespace Types REDUNDANTNo No No No system, file-per-table, general COMPACTYes No No No system, file-per-table, general DYNAMIC(8.0default)Yes Yes Yes No system, file-per-table, general COMPRESSEDYes Yes Yes Yes file-per-table, general
a)REDUNDANT的特征(兼容老版本MySQL)
- 每条索引记录包含6字节的头信息。用于链接相邻的记录.
- 在聚簇索引中的记录项包含用户定义的全部字段,和额外6字节的事务id字段+7字节的回滚指针字段.
- 如果没有定义主键,每行将包含6字节的row id.
- 定长的字符串列(CHAR(10)),在定长的字符集情况下,存储空间不会被截短.
- 定长列长度大于768个字节时会被编码成变长列,其存储在溢出页.
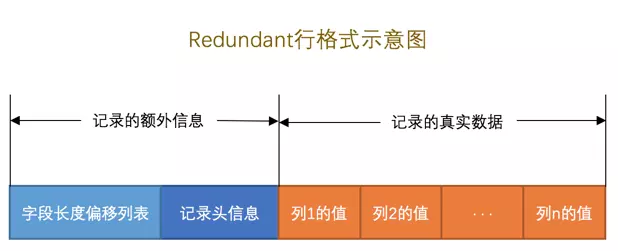
- 字段长度偏移列表占用字节规则:记录的真实数据占用的总大小来判断
- NULL值列表:将列对应的偏移量值的第一个比特位作为是否为
NULL的依据,该比特位也可以被称之为NULL比特位。 - CHAR(M)的存储格式
b)COMPACT

- COMPACT行格式相比与REDUNDANT格式节约了大于20%的存储空间,代价是花费更多的CPU资源。(选择问题)
- 变长字段长度列表占用字节规则:M,W,L
- NULL值列表:按位标记
- CHAR(M)的存储格式
思考:
- 变长字段长度列表和NULL值列表可以交换顺序吗?为什么?
- 该格式是否还有进一步优化的空间?在哪里?
c)DYNAMIC
d)COMPRESSED
3. 行格式设置
新增:CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称;修改:ALTER TABLE 表名 ROW_FORMAT=行格式名称;设置默认行格式:SET GLOBAL innodb_default_row_format=行格式名称;
4. 如何查看表的行格式
SHOW TABLE STATUS IN 表名;SELECT NAME, ROW_FORMAT FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='数据库名/表名';查看默认行格式:SELECT @@innodb_default_row_format;
三,参考资料
- 《MySQL 是怎样运行的:从根儿上理解 MySQL》
- 《MySQL技术内幕:InnoDB存储引擎(第2版)》
- MySQL官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-row-format.html

若有收获,就点个赞吧
0 人点赞
