一,索引的代价
- 空间上:索引页要占用空间
- 时间上:每次对表中的数据进行增、删、改操作时,都需要去修改各个
B+树索引
一个表上索引建的越多,就会占用越多的存储空间,在增删改记录的时候性能就越差
二,B+树索引适用的条件
CREATE TABLE person_info(id INT NOT NULL auto_increment,name VARCHAR(100) NOT NULL,birthday DATE NOT NULL,phone_number CHAR(11) NOT NULL,country varchar(100) NOT NULL,PRIMARY KEY (id),KEY idx_name_birthday_phone_number (name, birthday, phone_number));
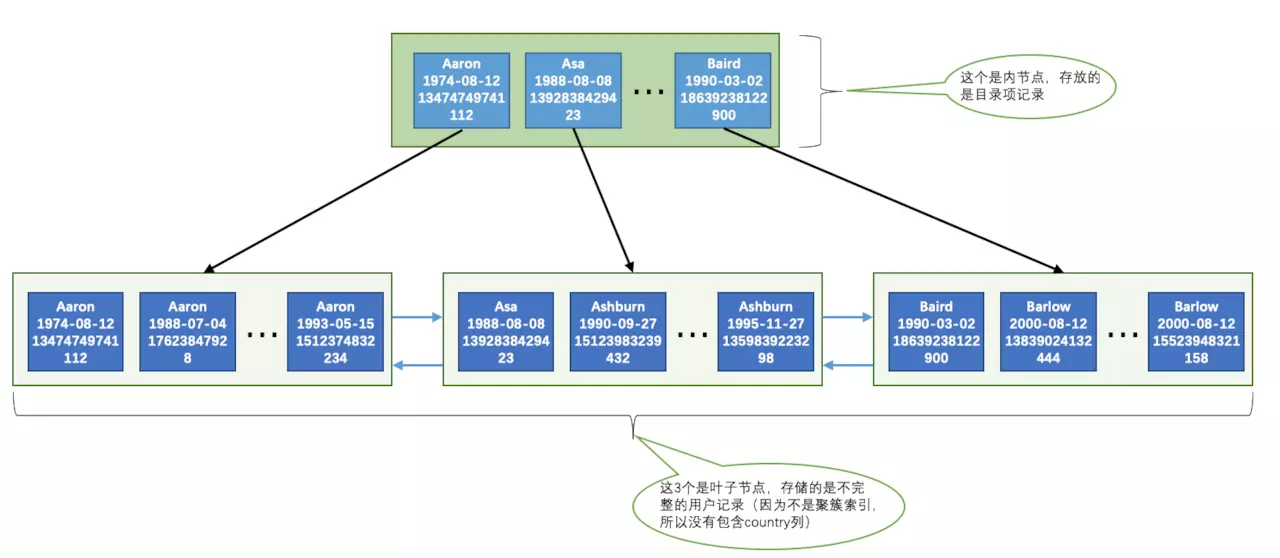
- 先按照
name列的值进行排序。 - 如果
name列的值相同,则按照birthday列的值进行排序。 - 如果
birthday列的值也相同,则按照phone_number的值进行排序。
1. 全值匹配
如果我们的搜索条件中的列和索引列一致的话
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239';
2. 匹配左边的列
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27';
如果我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中从最左边连续的列
SELECT * FROM person_info WHERE name = 'Ashburn' AND phone_number = '15123983239';
3. 匹配列前缀
这些字符串的前n个字符,也就是前缀都是排好序的,所以对于字符串类型的索引列来说,我们只匹配它的前缀也是可以快速定位记录的
SELECT * FROM person_info WHERE name LIKE 'As%';
4. 匹配范围值
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';
所有记录都是按照索引列的值从小到大的顺序排好序的,所以这极大的方便我们查找索引列的值在某个范围内的记录。
如果对多个列同时进行范围查找的话,只有对索引最左边的那个列进行范围查找的时候才能用到B+树索引
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';
5. 精确匹配某一列并范围匹配另外一列
对于同一个联合索引来说,虽然对多个列都进行范围查找时只能用到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进行范围查找
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';
6. 用于排序
SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;
对于联合索引有个问题需要注意,ORDER BY的子句后边的列的顺序也必须按照索引列的顺序给出
不可以使用索引进行排序的几种情况
- ASC、DESC混用
对于使用联合索引进行排序的场景,我们要求各个排序列的排序顺序是一致的
- WHERE子句中出现非排序使用到的索引列
如果WHERE子句中出现了非排序使用到的索引列,那么排序依然是使用不到索引的
- 排序列包含非同一个索引的列
有时候用来排序的多个列不是一个索引里的,这种情况也不能使用索引进行排序
- 排序列使用了复杂的表达式
要想使用索引进行排序操作,必须保证索引列是以单独列的形式出现,而不是修饰过的形式
7. 用于分组
SELECT name, birthday, phone_number, COUNT(*) FROM person_info GROUP BY name, birthday, phone_number
如果有了索引的话,恰巧这个分组顺序又和我们的B+树中的索引列的顺序是一致的,而我们的B+树索引又是按照索引列排好序的,这不正好么,所以可以直接使用B+树索引进行分组。
三,回表的代价
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow'
索引不包含查询的数据,需要回到聚簇索引中查找。
- 会使用到两个
B+树索引,一个二级索引,一个聚簇索引。 - 访问二级索引使用
顺序I/O,访问聚簇索引使用随机I/O。
覆盖索引
最好在查询列表里只包含索引列SELECT name, birthday, phone_number FROM person_info WHERE name > 'Asa' AND name < 'Barlow'
四,如何挑选索引
1. 只为用于搜索、排序或分组的列创建索引
SELECT birthday, country FROM person_name WHERE name = 'Ashburn';
2. 考虑列的基数
最好为那些列的基数大的列建立索引,为基数太小列的建立索引效果可能不好
3. 索引列的类型尽量小
- 数据类型越小,在查询时进行的比较操作越快(这是CPU层次的东东)
- 数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘
I/O带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
4. 索引字符串值的前缀
只索引字符串值的前缀的策略是我们非常鼓励的,尤其是在字符串类型能存储的字符比较多的时候。
索引列前缀对排序的影响
使用索引列前缀的方式无法支持使用索引排序,只好乖乖的用文件排序喽
5. 让索引列在比较表达式中单独出现
如果索引列在比较表达式中不是以单独列的形式出现,而是以某个表达式,或者函数调用形式出现的话,是用不到索引的
6. 主键插入顺序
最好单调递增,避免页分裂
7. 冗余和重复索引
避免重复定义,考虑覆联合索引。

若有收获,就点个赞吧
0 人点赞
