既然是纸质资料全开 资料来源:
- 头歌网站的作业(跟实验报告部分重叠)
- 课后实验报告的作业,4个实验的综合报告
- 雨课堂的选择题,5套题
看你得分的欲望有多强烈了,全打出来, 然后这里做一个简单的梳理,题目我的不放上来了。
把上面的几点弄出来,没什么好总结的了,也就是一个搬运工
如果有ppt,做一个ppt的总结吧
链接:
https://kdocs.cn/join/gutam8o 邀请你加入「spark课件-2021」,一起文档协作
第1章 大数据技术概述
这部分可以把之前大数据手写A4纸的拿过来
只要前面概述那一部分
大数据原理与应用
Linux基础命令
参考云计算的Linux命令
云计算技术
第2章 Scala语言基础
2.2 Scala基础
2.2.1基本数据类型和变量

2.2.2输入输出
import io.StdIn._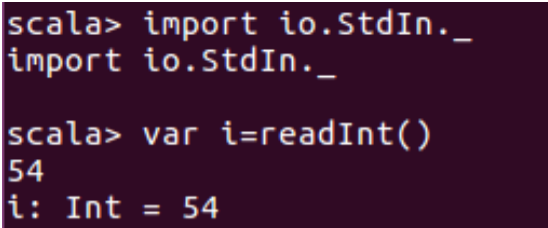
print和println
- 读取文件
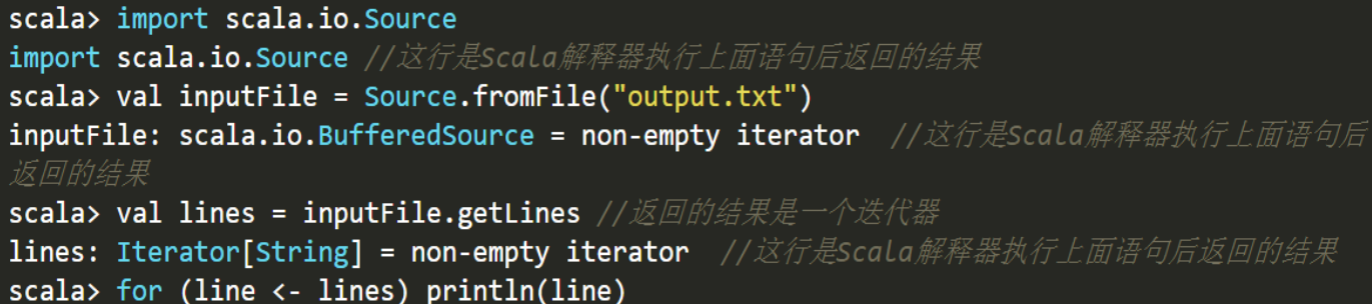
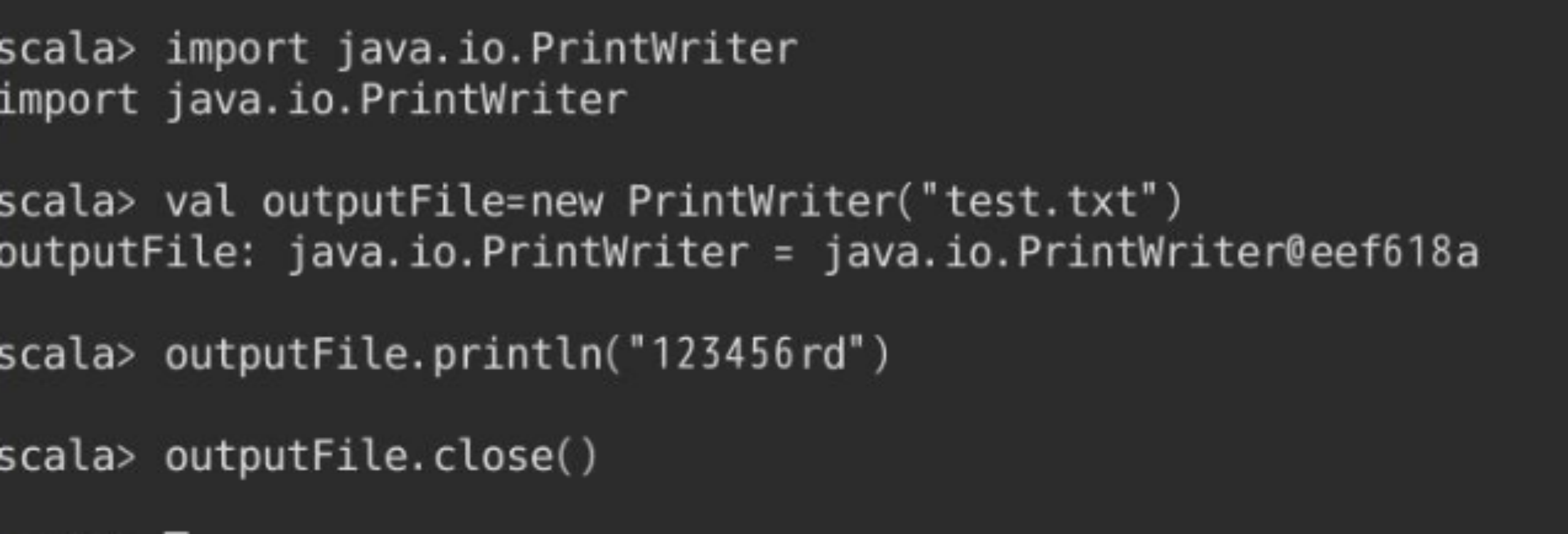
- 新建文件,写入内容
2.2.3控制结构
2.2.3.1 if条件表达式
有一点与Java不同的是,Scala中的if表达式的值可以赋值给变量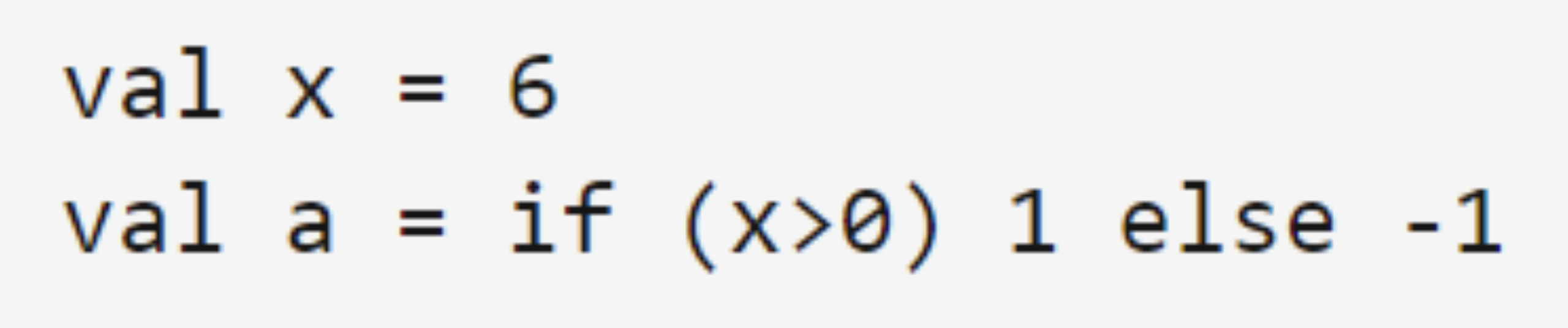
2.2.3.2 while循环
2.2.3.3 for循环

其中,“变量<-表达式”被称为“生成器(generator)”
“守卫(guard)”的表达式”:过滤出一些满足条件的结果。基本语法:
for (变量 <- 表达式 if 条件表达式) 语句块
for结构可以在每次执行的时候创造一个值,然后将包含了所有产生值的集合作为for循环表达式的结果返回,集合的类型由生成器中的集合类型确定。
for (变量 <- 表达式) yield {语句块}
2.2.3.5 对循环的控制
为了提前终止整个循环或者跳到下一个循环,Scala没有break和continue关键字。Scala提供了一个Breaks类(位于包scala.util.control)。Breaks类有两个方法用于对循环结构进行控制,即breakable和break:
将需要控制的语句块作为参数放在breakable后面,然后,其内部在某个条件满足时调用break方法,程序将跳出breakable方法。

2.2.4数据结构
2.2.4.1 数组(Array)
2.2.4.2 元组(Tuple)
元组是对多个不同类型对象的一种简单封装。定义元组最简单的方法就是把多个元素用逗号分开并用圆括号包围起来。
使用下划线“._”加上从1开始的索引值,来访问元组的元素。
如果需要在方法里返回多个不同类型的对象,Scala可以通过返回一个元组实现。
2.2.4.3 容器(Collection)
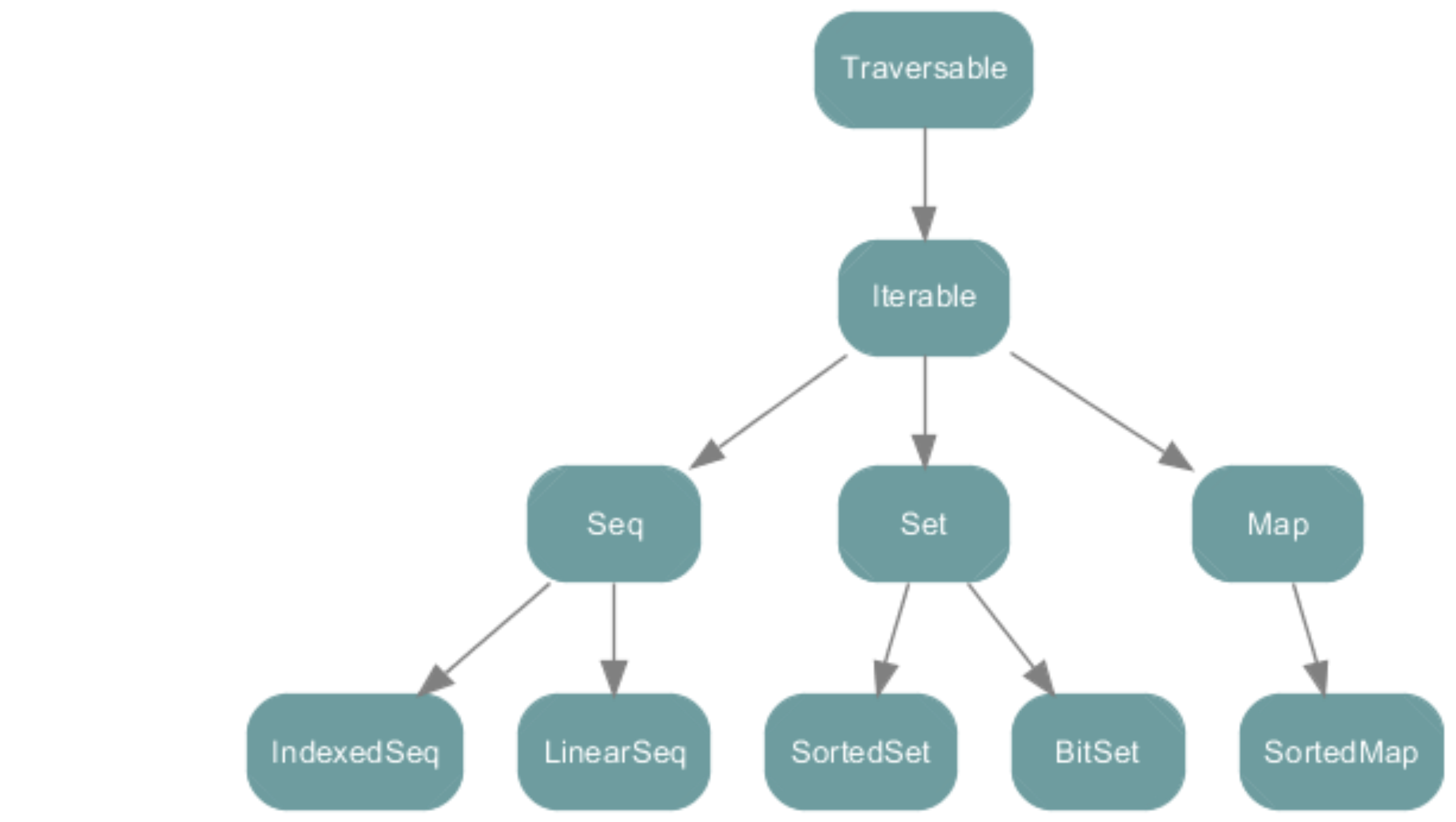
2.2.4.4 序列(Sequence)
序列(Sequence): 元素可以按照特定的顺序访问的容器。序列中每个元素均带有一个从0开始计数的固定索引位置。
序列容器的根是collection.Seq特质。其具有两个子特质 LinearSeq和IndexedSeq。LinearSeq序列具有高效的 head 和 tail 操作,而IndexedSeq序列具有高效的随机存储操作。
实现了特质LinearSeq的常用序列有列表(List)和队列(Queue)。实现了特质IndexedSeq的常用序列有可变数组(ArrayBuffer)和向量(Vector)。
- 2.2.4.4 序列—-列表(List)
列表(List): 一种共享相同类型的不可变的对象序列。
列表有头部和尾部的概念,可以分别使用head和tail方法来获取
head返回的是列表第一个元素的值
tail返回的是除第一个元素外的其它值构成的新列表,这体现出列表具有递归的链表结构
构造列表常用的方法是通过在已有列表前端增加元素,使用的操作符为::,例如:
Scala还定义了一个空列表对象Nil,借助Nil,可以将多个元素用操作符::串起来初始化一个列表
val intList = 1::2::3::Nil 与val intList = List(1,2,3)等效
注意:除了head、tail操作是常数时间O(1),其它按索引访问的操作都需要从头开始遍历,因此是线性时间复杂度O(N)。
- 2.2.4.4 序列—-向量(vector)
Vetor可以实现所有访问操作都是常数时间。O(1)
- 2.2.4.4 序列—-Range
Range类:一种特殊的、带索引的不可变数字等差序列。其包含的值为从给定起点按一定步长增长(减小)到指定终点的所有数值。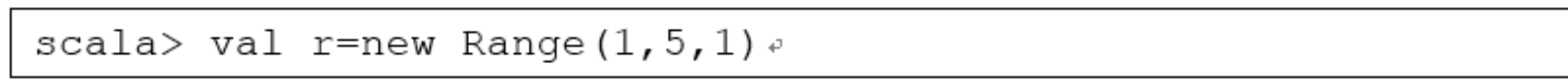


until 不包含终点
2.2.4.5 集合(Set)
集合(set):不重复元素的容器(collection)。
列表中的元素是按照插入的先后顺序来组织的,但是,“集合”中的元素并不会记录元素的插入顺序,而是以“哈希”方法对元素的值进行组织,所以,它允许你快速地找到某个元素
集合包括可变集和不可变集,分别位于scala.collection.mutable包和scala.collection.immutable包,缺省情况下创建的是不可变集
基本运算符号
连接
可以使用 ++ 运算符或 Set.++() 方法来连接两个集合。如果元素有重复的就会移除重复的元素。
交集
可以使用 Set.& 方法或 Set.intersect 方法来查看两个集合的交集元素。
2.2.4.6 映射(Map)
映射(Map):一系列键值对的容器。键是唯一的,但值不一定是唯一的。可以根据键来对值进行快速的检索
Scala 的映射包含了可变的和不可变的两种版本,分别定义在包scala.collection.mutable 和scala.collection.immutable 里。
默认情况下,Scala中使用不可变的映射。 如果想使用可变映射,必须明确地导入scala.collection.mutable.Map


2.2.4.7 迭代器(Iterator)
2.3 面向对象编程基础
2.3.1 类
1.类的定义
class Counter{//这里定义类的字段和方法}
2.给类增加变量和方法 
没有返回值就使用 Unit
3.使用new关键字创建一个类的实例化。
new Counter //或者new Counter() 可以不加()
如果是代码文件调用
进入scala,:load Counter1.scala 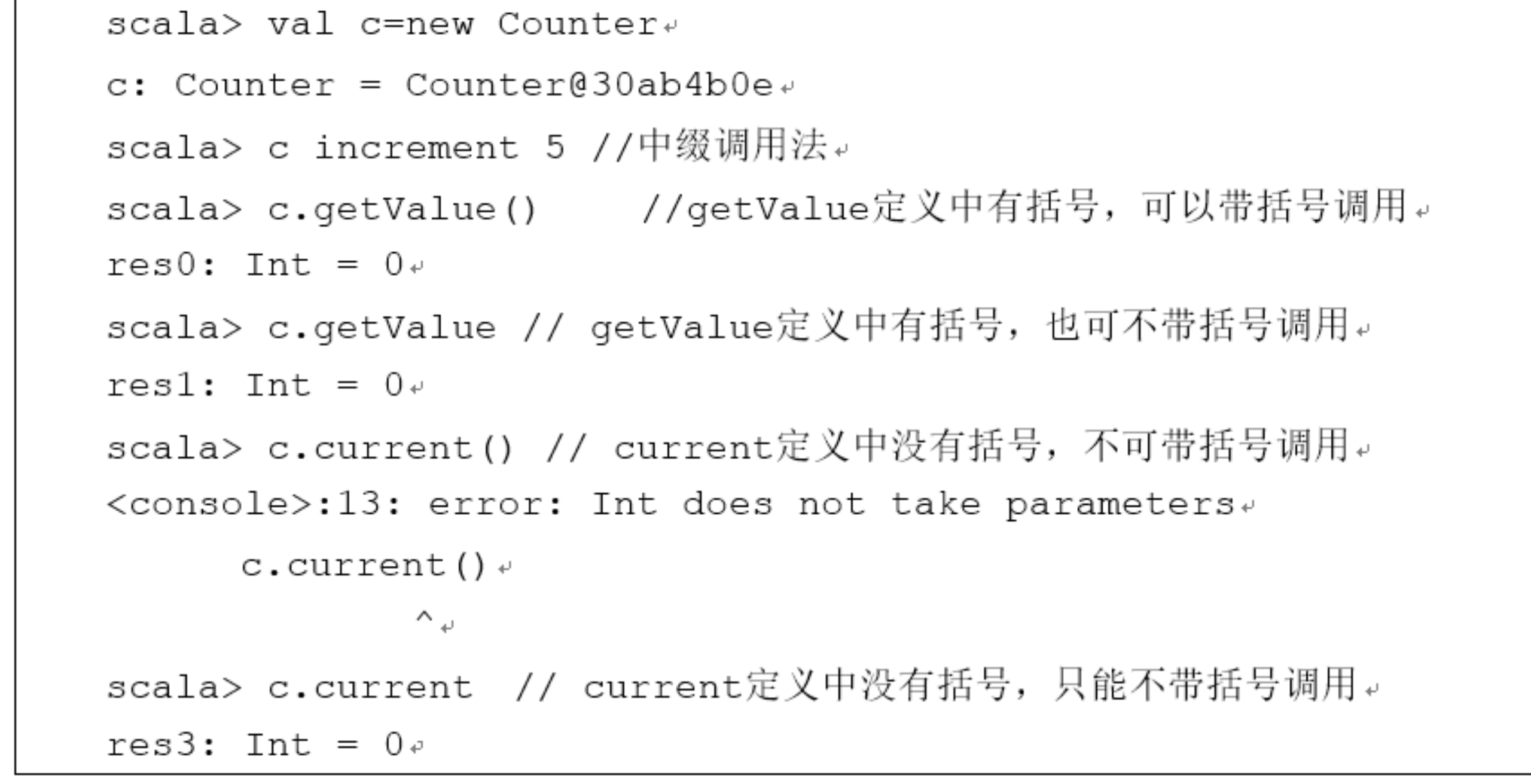

Scala允许方法重载。只要方法的完整签名(包括方法名、参数类型列表、返回类型)是唯一的,多个方法可以使用相同的方法名。
2.3.1.4 构造器
Scala类的定义主体就是类的构造器,称为主构造器。在类名之后用圆括号列出主构造器的参数列表。
主构造器的参数前可以使用val或var关键字,Scala内部将自动为这些参数创建私有字段,并提供对应的访问方法
2.3.2 对象
2.3.2.1 单例对象
object 关键字定义单例对象,静态方法,不需要实例化 
2.3.2.2 伴生对象
- 当一个单例对象和它的同名类一起出现时,这时的单例对象被称为这个同名类的“伴生对象” (companion object)。相应的类被称为这个单例对象的“伴生类”
- 类和它的伴生对象必须存在于同一个文件中,可以相互访问私有成员。
- 没有同名类的单例对象,被称为孤立对象(standalone object)。一般情况下,Scala程序的入口点main方法就是定义在一个孤立对象里。
2.3.2.3 应用程序对象
2.3.2.4 apply方法和update方法
Scala自动调用Array类的伴生对象Array中的一个称为apply的方法,来创建一个Array对象myStrArr。
apply方法调用约定:用括号传递给类实例或单例对象名一个或多个参数时,Scala 会在相应的类或对象中查找方法名为apply且参数列表与传入的参数一致的方法,并用传入的参数来调用该apply方法。
update方法的调用约定: 当对带有括号并包括一到若干参数的对象进行赋值时,
编译器将调用对象的update方法,并将括号里的参数和等号右边的值一起作为update方法的输入参数来执行调用。
apply 工厂方法,生成对象
unapply 提取,反向解构操作
根据对象,取出构造函数时的参数
2.3.3 继承
2.3.3.1 抽象类
如果一个类包含没有实现的成员,则必须使用abstract关键词进行修饰,定义为抽象类。 
2.3.3.2 扩展类(子类)
Scala只支持单一继承,而不支持多重继承。在类定义中使用extends关键字表示继承关系。定义子类时,需要注意:
- 重载父类的抽象成员(包括字段和方法)时,override关键字是可选的;而重载父类的非抽象成员时,override关键字是必选的。
- 只能重载val类型的字段,而不能重载var类型的字段。因为var类型本身就是可变的,所以,可以直接修改它的值,无需重载;
- 子类不仅仅可以派生自抽象类,还可以派生自非抽象类,如果某个类不希望被其它类派生出子类,则需要在类定义的class关键字前加上final关键字。
-
2.3.3.3 类层级结构
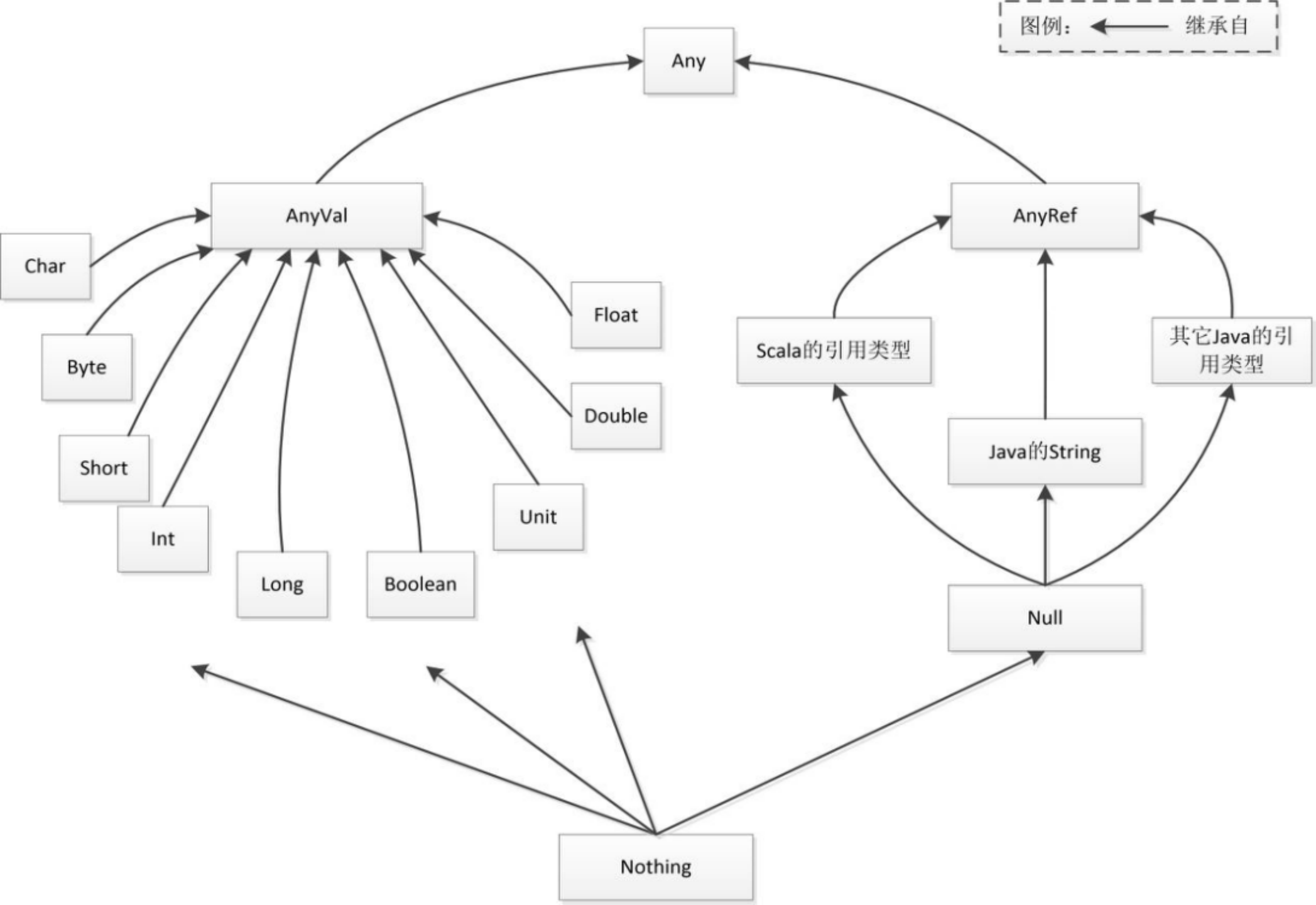
Null是所有引用类型的子类,其唯一的实例为null,表示一个“空”对象,可以赋值给任何引用类型的变量,但不能赋值给值类型的变量。
Nothing是所有其它类型的子类,包括Null。Nothing没有实例,主要用于异常处理函数的返回类型。2.3.4 参数化类型
2.3.5 特质(trait)
Java中提供了接口,允许一个类实现任意数量的接口。
- Scala中没有接口的概念,而是提供了“特质(trait)”,它不仅实现了接口的功能,还具备了很多其他的特性
- Scala的特质是代码重用的基本单元,可以同时拥有抽象方法和具体方法
Scala中,一个类只能继承自一个超类,却可以实现多个特质,从而重用特质中的方法和字段,实现了多重继承
特质既可以包含抽象成员,也可以包含非抽象成员。包含抽象成员时,也不需要abstract关键字。
- 特质可以使用extends继承其它的特质,并且还可以继承类。
- 特质的定义体就相当于主构造器,与类不同的是,不能给特质的主构造器提供参数列表,而且也不能为特质定义辅助构造器。
2.3.6 模式匹配
2.3.6.1 match语句

match结构中不需要break语句来跳出判断,Scala从前往后匹配到一个分支后,会自动跳出判断。
case后面的表达式可以是任何类型的常量,而不要求是整数类型。
可以在match表达式的case中使用守卫式(guard)添加一些过滤逻辑
2.3.6.2 case类的匹配
- case类是一种特殊的类,它们经过优化以被用于模式匹配。 当定义一个类时,如果在class关键字前加上case关键字,则该类称为case类。
- Scala为case类自动重载了许多实用的方法,包括toString、equals和hashcode方法。
- Scala为每一个case类自动生成一个伴生对象,其包括模板代码
- 一个apply方法,因此,实例化case类的时候无需使用new关键字;
- 一个unapply方法,该方法包含一个类型为伴生类的参数,返回的结果是Option类型,对应的类型参数是N元组,N是伴生类中主构造器参数的个数。Unapply方法用于对对象进行解构操作,在case类模式匹配中,该方法被自动调用,并将待匹配的对象作为参数传递给它。

每一个case子句中的Car(…),都会自动调用Car.unapply(car),并将提取到的值与Car后面括号里的参数进行一一匹配比较。 第一个case和第二个case是与特定的值进行匹配。 第三个case由于Car后面跟的参数是变量,因此将匹配任意的参数值。
2.3.7 包
2.4 函数式编程基础
2.4.1 函数定义与使用
2.4.1.1 函数式编程简介
2.4.1.2 函数的定义和使用
def 方法名(参数列表):结果类型={方法体} def counter(value: Int): Int = { value += 1}
匿名函数——lambda表达式
匿名函数(函数字面量):函数变量的值 (num: Int) => num * 2
定义形式: (参数) => 表达式
//如果参数只有一个,参数的圆括号可以省略
2.4.1.3 占位符语法
当函数的每个参数在函数字面量内仅出现一次,可以省略“=>”并用下划线“_”作为参数的占位符来简化函数字面量的表示,第一个下划线代表第一个参数,第二个下划线代表第二个参数,依此类推。
2.4.5 针对容器的操作
遍历操作
- 映射是指通过对容器中的元素进行某些运算来生成一个新的容器。两个典型的映射操作是map方法和flatMap方法。
映射操作
- map方法(一对一映射):将某个函数应用到集合中的每个元素,映射得到一个新的元素,map方法会返回一个与原容器类型大小都相同的新容器,只不过元素的类型可能不同。
- flatMap方法(一对多映射):将某个函数应用到容器中的元素时,对每个元素都会返回一个容器(而不是一个元素),然后,flatMap把生成的多个容器“拍扁”成为一个容器并返回。返回的容器与原容器类型相同,但大小可能不同,其中元素的类型也可能不同。


过滤操作
- 过滤:遍历一个容器,从中获取满足指定条件的元素,返回一个新的容器。
- filter方法:接受一个返回布尔值的函数f作为参数,并将f作用到每个元素上,将f返回真值的元素组成一个新容器返回。

规约操作
- 规约操作是对容器元素进行两两运算,将其“规约”为一个值。
- reduce方法:接受一个二元函数f作为参数,首先将f作用在某两个元素上并返回一个值,然后再将f作用在上一个返回值和容器的下一个元素上,再返回一个值,依此类推,最后容器中的所有值会被规约为一个值。

拆分操作
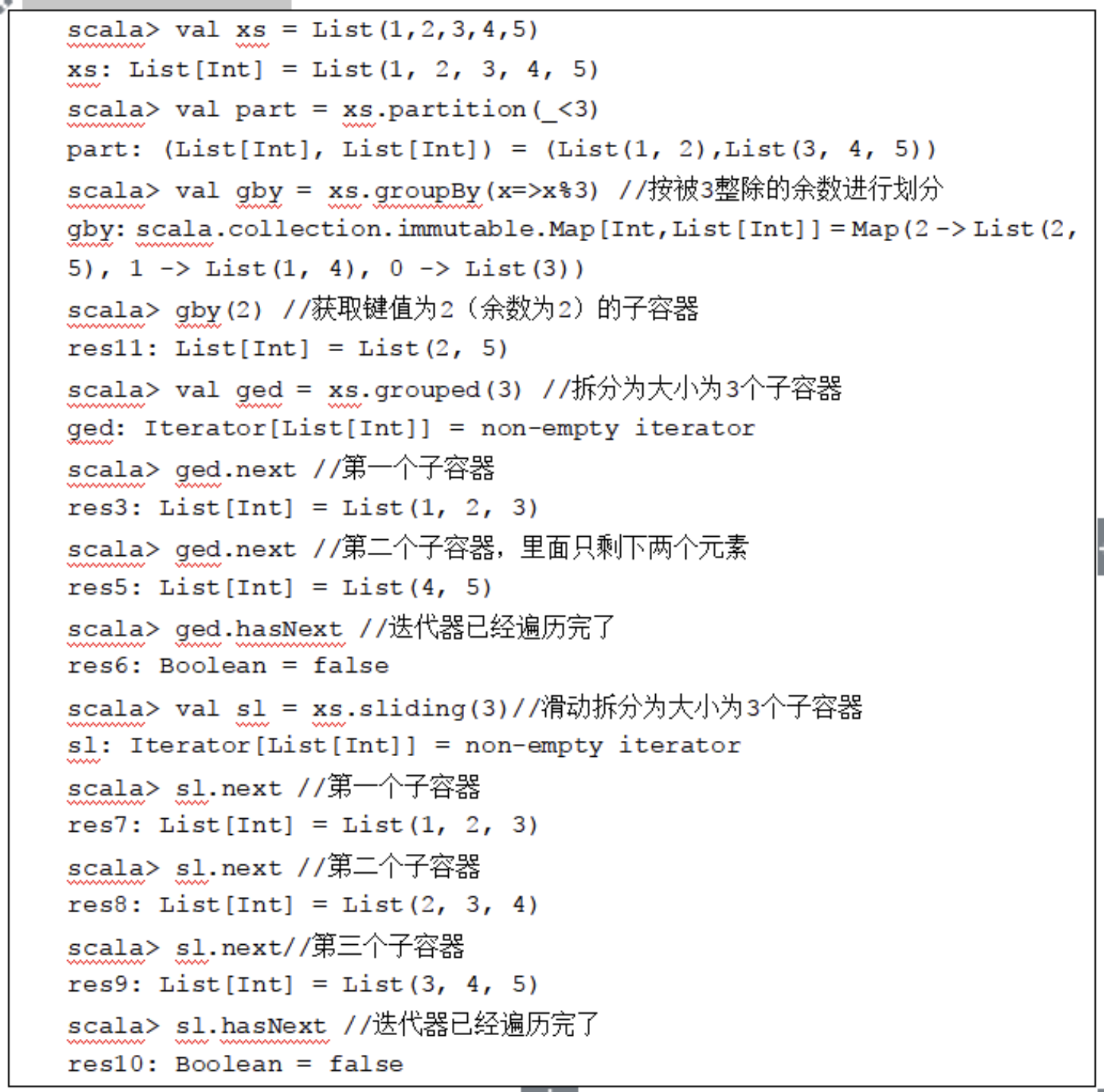
- 拆分操作是把一个容器里的元素按一定的规则分割成多个子容器。常用的拆分方法有partition、groupedBy、grouped和sliding。
- partition方法:接受一个布尔函数对容器元素进行遍历,以二元组的形式返回满足条件和不满足条件的两个集合。
- groupedBy方法:接受一个返回U类型的函数对容器元素进行遍历,将返回值相同的元素作为一个子容器,并与该相同的值构成一个键值对,最后返回的是一个映射。
- grouped和sliding方法:接受一个整型参数n,将容器拆分为多个与原容器类型相同的子容器,并返回由这些子容器构成的迭代器。其中,grouped按从左到右的方式将容器划分为多个大小为n的子容器(最后一个的大小可能小于n);sliding使用一个长度为n的滑动窗口,从左到右将容器截取为多个大小为n的子容器。
第3章 Spark的设计与运行原理
3.1 Spark概述
Spark具有如下几个主要特点:
- 运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
- 容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
- 运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
3.1.3 Spark与Hadoop的对比
| MapReduce | Spark |
|---|---|
| 数据存储结构:磁盘HDFS文件系统的split | 使用内存构建弹性分布式数据集RDD 对数据进行运算和cache |
| 编程范式:Map + Reduce | DAG: Transformation + Action |
| 计算中间结果落到磁盘,IO及序列化、反序列化代价大 | 计算中间结果在内存中维护 存取速度比磁盘高几个数量级 |
| Task以进程的方式维护,需要数秒时间才能启动任务 | Task以线程的方式维护 对于小数据集读取能够达到亚秒级的延迟 |
3.2 Spark生态系统
3.3 Spark运行架构
3.3.1 基本概念
- RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
- Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
- Application:用户编写的Spark应用程序
- Task:运行在Executor上的工作单元
- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作
- Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
3.3.4 RDD运行原理
1.RDD设计背景
2.RDD概念
3.RDD特性
4.RDD之间的依赖关系
5.阶段的划分
6.RDD运行过程
RDD典型的执行过程如下:
- RDD读入外部数据源进行创建
- RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
- 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
这一系列处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果 优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单
Shuffle操作
- 什么是Shuffle操作
- MapReduce中的Shuffle操作
- Spark中的Shuffle操作
窄依赖和宽依赖
- 是否包含Shuffle操作是区分窄依赖和宽依赖的根据
- RDD之间的依赖关系——窄依赖和宽依赖
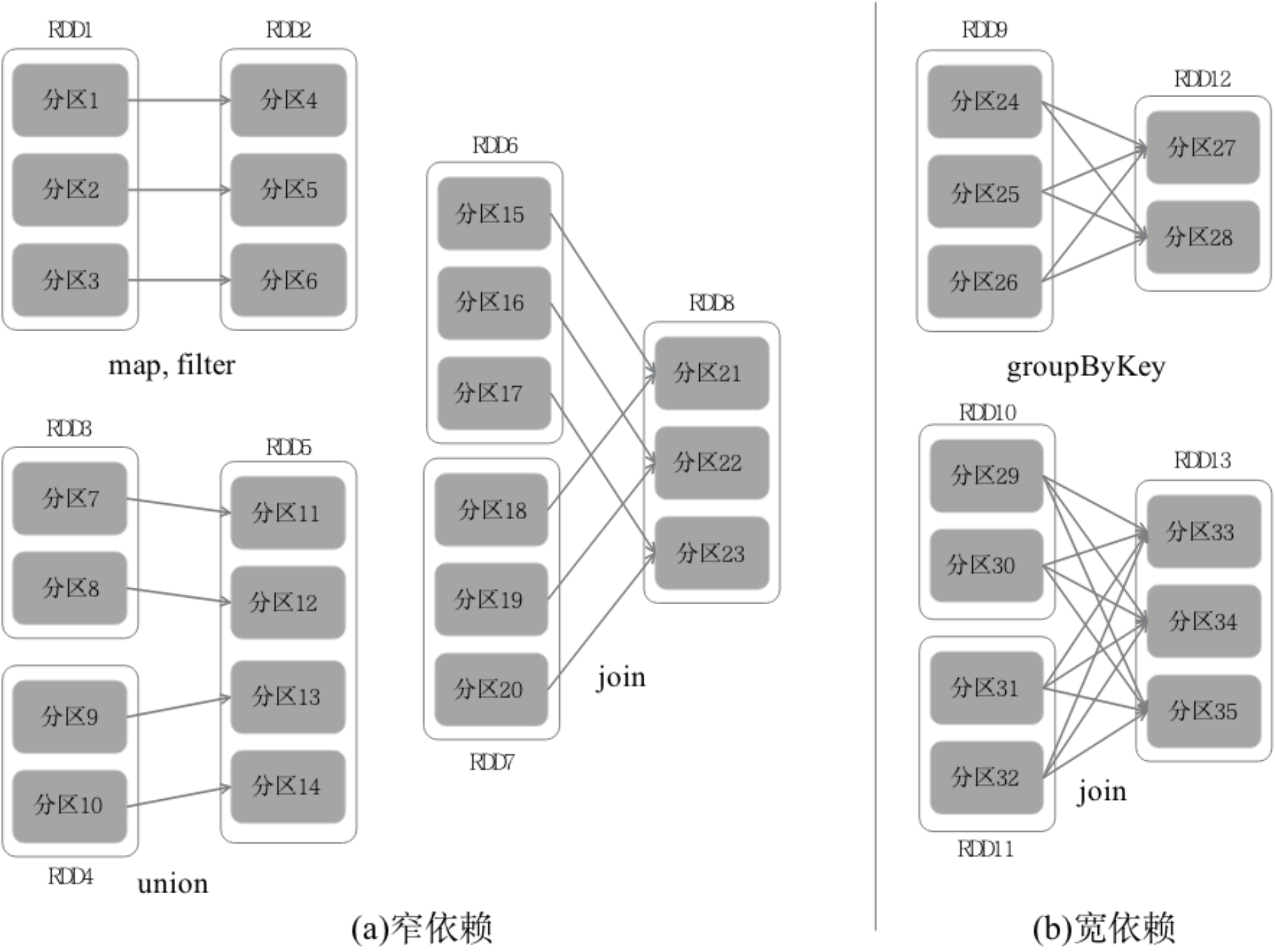
- 窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
- 宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
3.4 Spark的部署方式
第4章 Spark环境搭建和使用方法
4.4.6 启动Spark集群

4.4.7 关闭Spark集群

第5章 RDD编程
5.1.2 RDD操作
常用的RDD转换操作API
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果 |
5.1.3 持久化
持久化(缓存)机制避免重复计算的开销
persist()方法对一个RDD标记为持久化
持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
5.1.4 分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
分区的作用
(1)增加并行度
(2)减少通信开销
第6章 Spark SQL
6.1.1 从Shark说起
Shark的设计导致了两个问题:
- 一是执行计划优化完全依赖于Hive,不方便添加新的优化策略
- 二是因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
6.3 DataFrame的创建
在创建DataFrame时,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,例如:
- spark.read.json(“people.json”):读取people.json文件创建DataFrame;在读取本地文件或HDFS文件时,要注意给出正确的文件路径;
- spark.read.parquet(“people.parquet”):读取people.parquet文件创建DataFrame;
- spark.read.csv(“people.csv”):读取people.csv文件创建DataFrame。
6.5 DataFrame的常用操作
1.printSchema()
2.select()
3.filter()
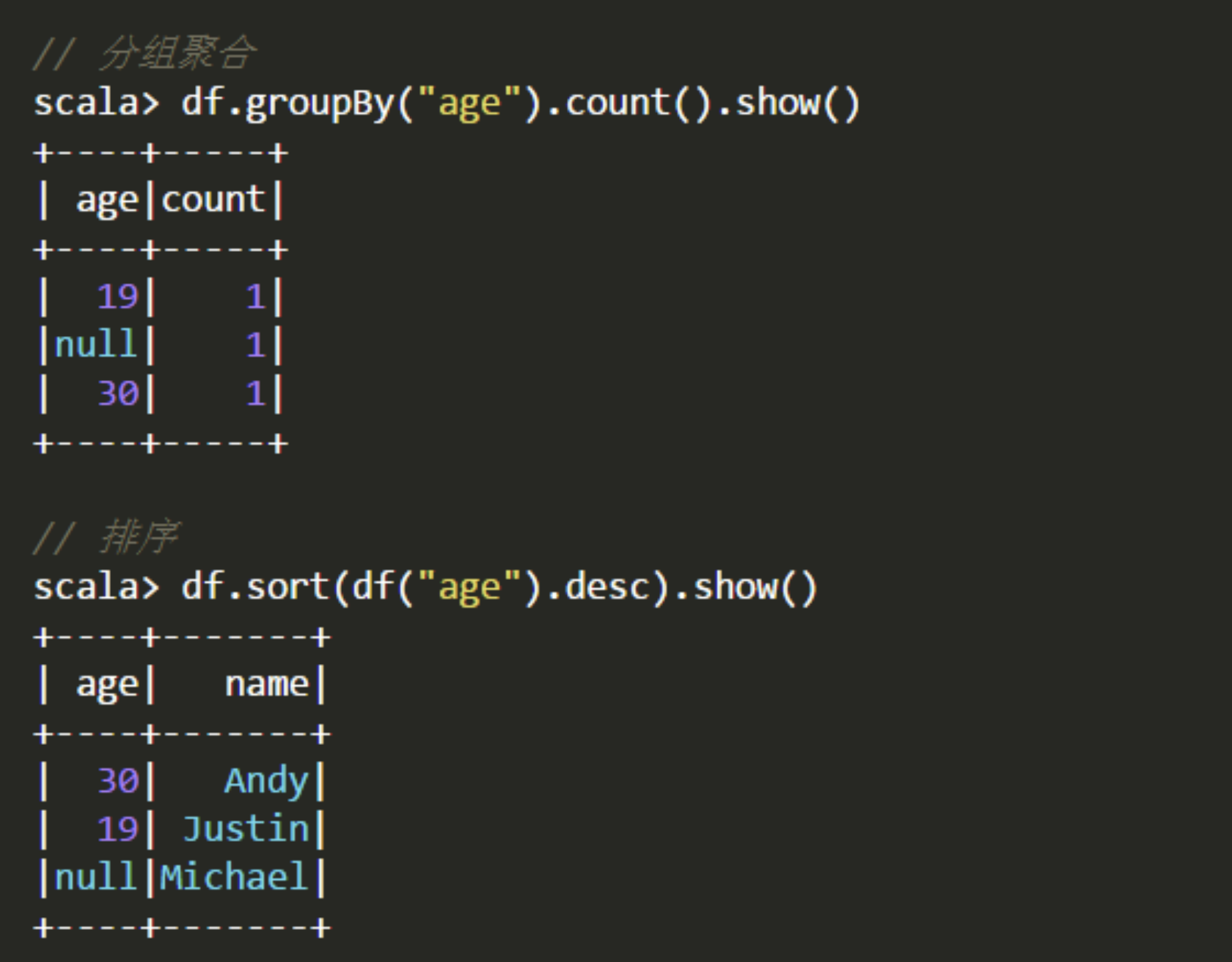
4.groupby()
5.sort()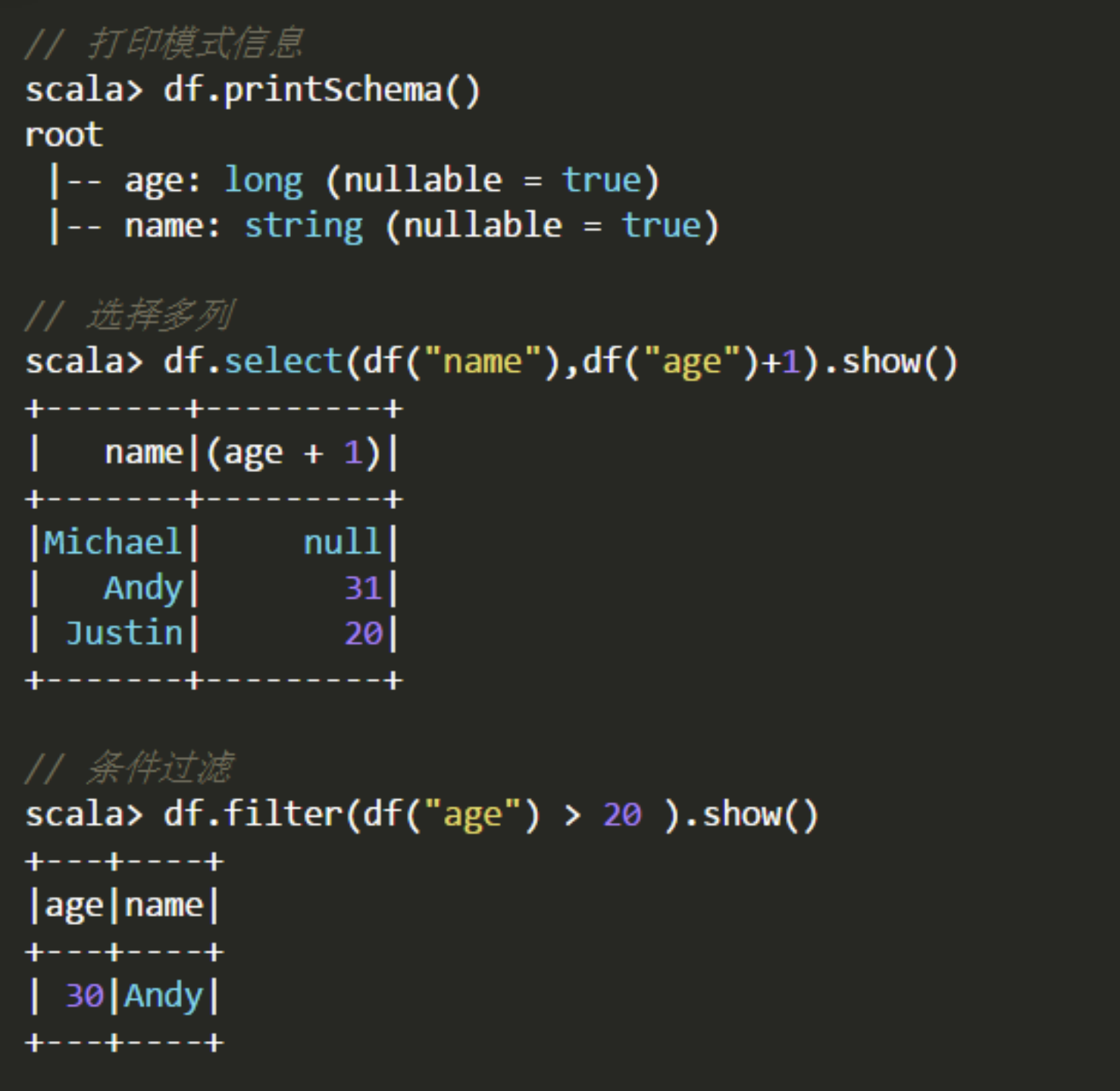
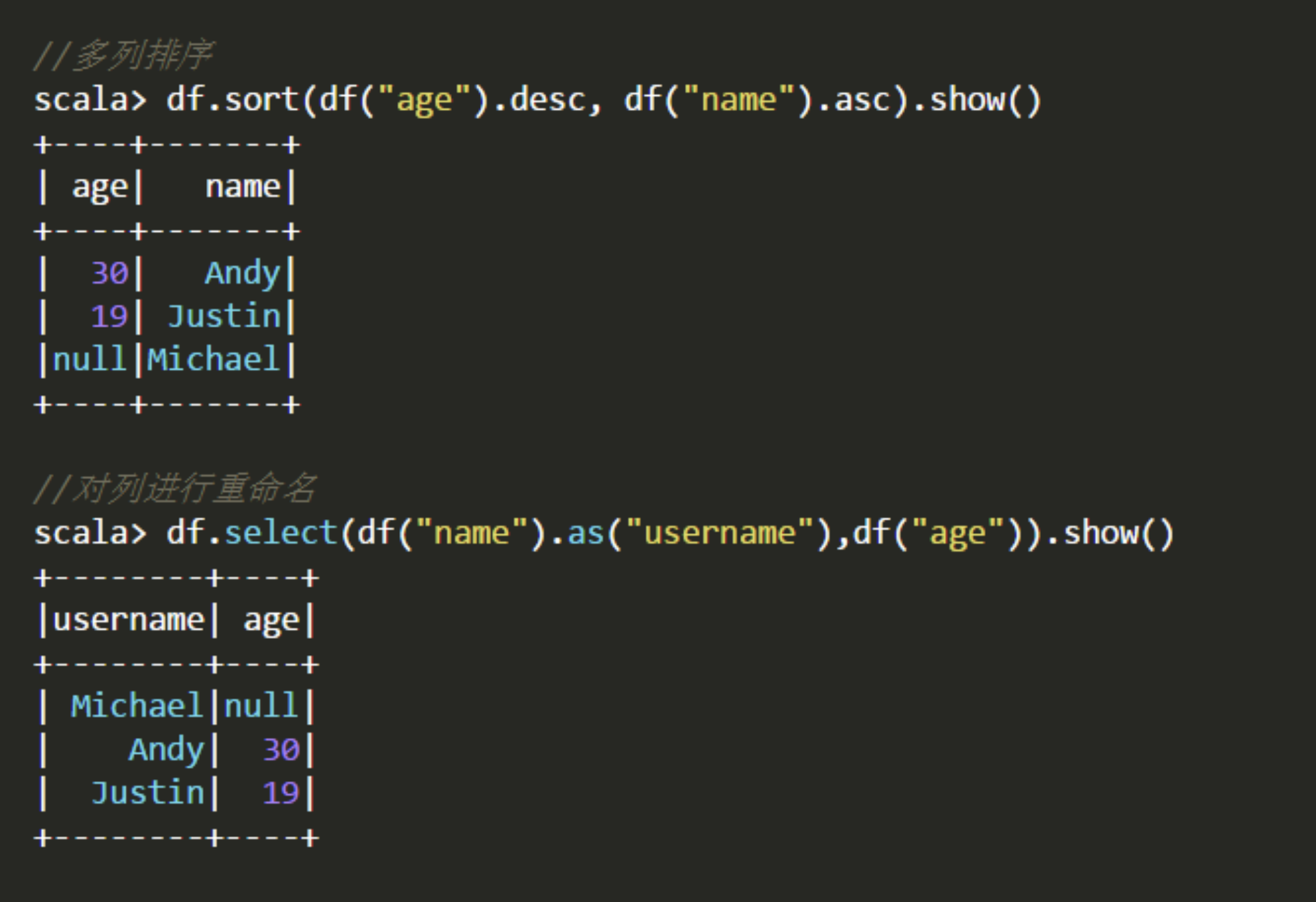
6.6.1 利用反射机制推断RDD模式
```scala scala> case class Person(name: String, age: Long) //定义一个case class defined class Person scala> val peopleDF = spark.sparkContext. | textFile(“file:///usr/local/spark/examples/src/main/resources/people.txt”). | map(_.split(“,”)). | map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF() peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
scala> peopleDF.createOrReplaceTempView(“people”) //必须注册为临时表才能供下面的查询使用 scala> val personsRDD = spark.sql(“select name,age from people where age > 20”) //最终生成一个DataFrame,下面是系统执行返回的信息 personsRDD: org.apache.spark.sql.DataFrame = [name: string, age: bigint] scala> personsRDD.map(t => “Name: “+t(0)+ “,”+”Age: “+t(1)).show() //DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用t(0)和t(1)来获取值 //下面是系统执行返回的信息 +—————————+ | value| +—————————+ |Name:Michael,Age:29| | Name:Andy,Age:30| +—————————+
<a name="qdhc4"></a>
### 6.6.2 使用编程方式定义RDD模式
```scala
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
//生成字段
scala> val fields = Array(StructField("name",StringType,true), StructField("age",IntegerType,true))
fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(name,StringType,true), StructField(age,IntegerType,true))
scala> val schema = StructType(fields)
schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age, IntegerType,true))
//从上面信息可以看出,schema描述了模式信息,模式中包含name和age两个字段
//shcema就是“表头”
//下面加载文件生成RDD
scala> val peopleRDD = spark.sparkContext.
| textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:26
//对peopleRDD 这个RDD中的每一行元素都进行解析
scala> val rowRDD = peopleRDD.map(_.split(",")).
| map(attributes => Row(attributes(0), attributes(1).trim.toInt))
rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:29
//上面得到的rowRDD就是“表中的记录”
//下面把“表头”和“表中的记录”拼装起来
scala> val peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: int]
//必须注册为临时表才能供下面查询使用
scala> peopleDF.createOrReplaceTempView("people")
scala> val results = spark.sql("SELECT name,age FROM people")
results: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> results.
| map(attributes => "name: " + attributes(0)+","+"age:"+attributes(1)).
| show()
+--------------------+
| value|
+--------------------+
|name: Michael,age:29|
| name: Andy,age:30|
| name: Justin,age:19|
+--------------------+
第7章 Spark Streaming
一、静态数据和流数据
很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘和OLAP(On-Line Analytical Processing)分析工具从静态数据中找到对企业有价值的信息 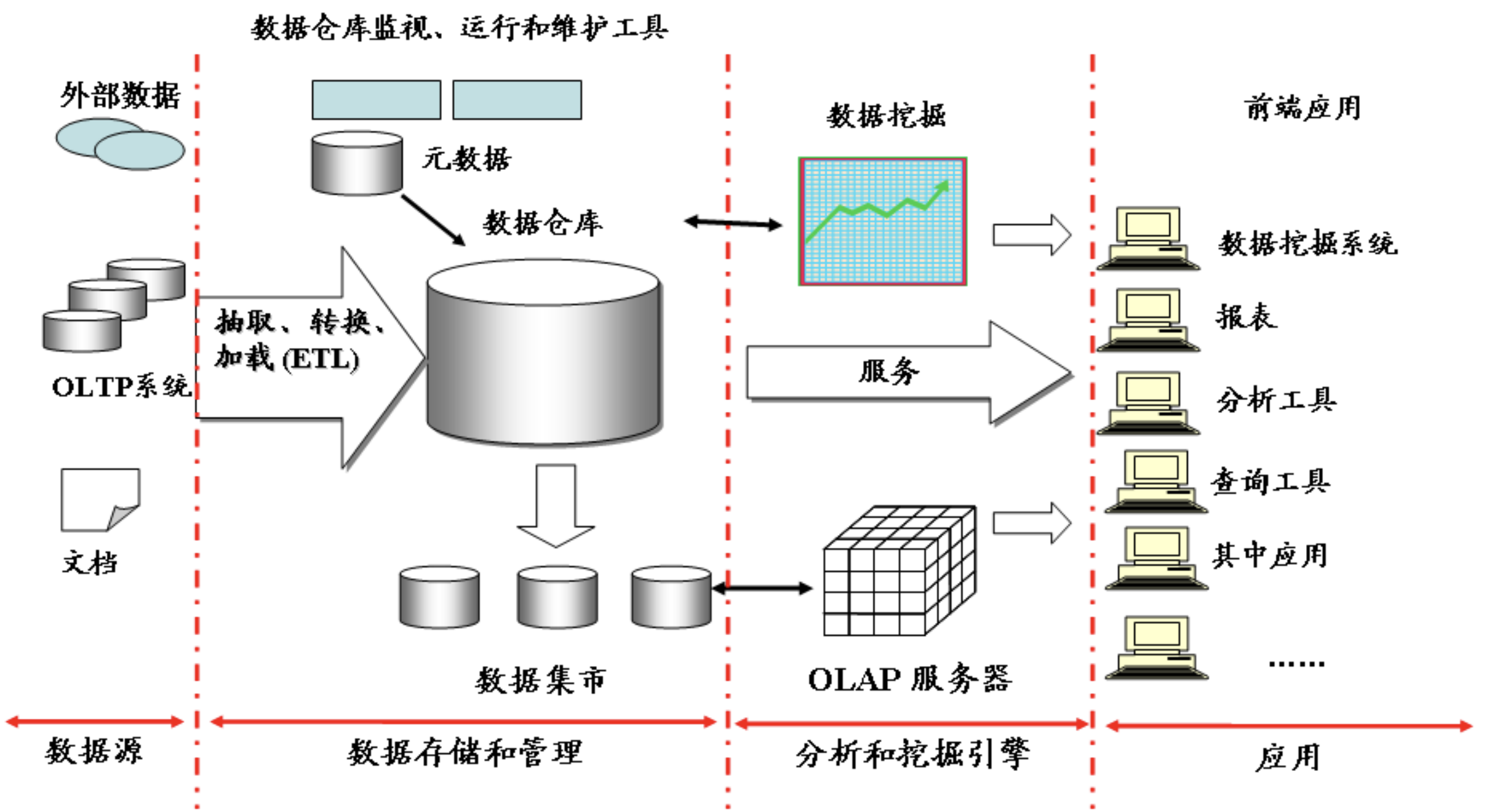
流数据具有如下特征:
- 数据快速持续到达,潜在大小也许是无穷无尽的
- 数据来源众多,格式复杂 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储
- 注重数据的整体价值,不过分关注个别数据
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序
Spark Streaming程序的基本步骤
编写Spark Streaming程序的基本步骤是:
1.通过创建输入DStream来定义输入源
2.通过对DStream应用转换操作和输出操作来定义流计算
3.用streamingContext.start()来开始接收数据和处理流程
4.通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)
5.可以通过streamingContext.stop()来手动结束流计算进程
scala> import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(1))
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))

若有收获,就点个赞吧
0 人点赞
