跟数据仓库一样,纸质资料全开,就没什么问题了
把所有的作业,报告打印出来吧
HiveQL查询
- GROUP BY 子句
在SELECT子句的后面只可以有两类表达式:聚合函数和进行分组的列名 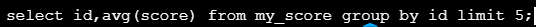
即,若使用了GROUP BY子句,在SELECT子句中只能出现分组字段、聚合函数,不能出现其他字段。
HAVING 子句
HAVING子句通常与GROUP BY子句一起使用,在完成对分组结果统计之后, 可以使用HAVING 子句对分组的结果做进一步筛选。
排序
order by
Hive中的Order by和传统Sql中的Order by一样,对查询结果做全局排序,会新启动一个Job进行排序,会把所有数据放到同一个Reduce中进行处理,不管数据多少,不管文件多少,都启用一个Reduce进行处理。 ASC——升序
DESC——降序
sort by
是局部排序,会在每个Reduce端做排序,保证了局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的,除非只有一个reducer)。
set mapred.reduce.tasks=3; hive> select * from my_score sort by id desc,courseid asc;
开窗查询

若有收获,就点个赞吧
0 人点赞
