正则表达式概念
- 使用单个字符串来描述匹配一系列符合其语法规则的字符串;
- 对字符串的一种逻辑公式;
- 处理文本和数据;
通配符
- 代表任意多个字符
- ? 代表单个字符
- . 当前目录
- .. 当前目录的上一级目录
- [0-9]: 单个字符为0~9
- [a-z]:
- [A-Z]
- [A-Za-z]
[0-9A-Za-Z]
[[:digit:]]:单个数字
[[:upper:]]:单个大写字符
[[:lower:]]:单个小写字符
[[:space:]]:单个空格
获取当前目录下以一个数字开头以.任意结尾的文件:glob.glob(‘./[0-9].*’)
以任意多个字符开头以.gif结尾的文件:glob.glob(‘*.gif’)
以任意单个字符开头以.gif结尾的文件:glob.glob(‘?.gif’)
任意目录下的以任意多个字符开头以.txt结尾的文件,采用递归方式:glob.glob(‘*/.txt’, recursive=True)
当前目录下的所有目录,采用递归方式:glob.glob(‘./**/‘, recursive=True)
特殊字符类
单字符匹配
[ ]匹配括号内多个字符中的任意一个字符
[^ ]表示匹配除了括号内的任意一个字符
- [pP]ython
- westos[pP]
- [aeiou]
- [a-z]:匹配任意一个小写字母
- [A-Z]:匹配任意一个大写字母
- [a-zA-Z0-9]:匹配任意一个小写或大写字母或数字
- [^aeiou]
- [^0-9]:匹配除了数字的任意一个字符
- . 匹配除了\n之外的任意字符;要匹配包括 ‘\n’ 在内的任何字符,请使用 ‘[.\n]’
- \d 匹配一个数字字符, 等价于[0-9]
- \D 匹配一个非数字字符, 等价于[^0-9]
- \s 匹配单个任何的空白字符;包括空格、制表符、换页符等等,等价于 [ \f\n\r\t\v]。
- \S 匹配除了单个任何的空白字符;等价于 [^ \f\n\r\t\v]。
- \w 字母数字或者下划线, [a-zA-Z0-9_]
- \W 除了字母数字或者下划线, [^a-zA-Z0-9_]
多字符匹配
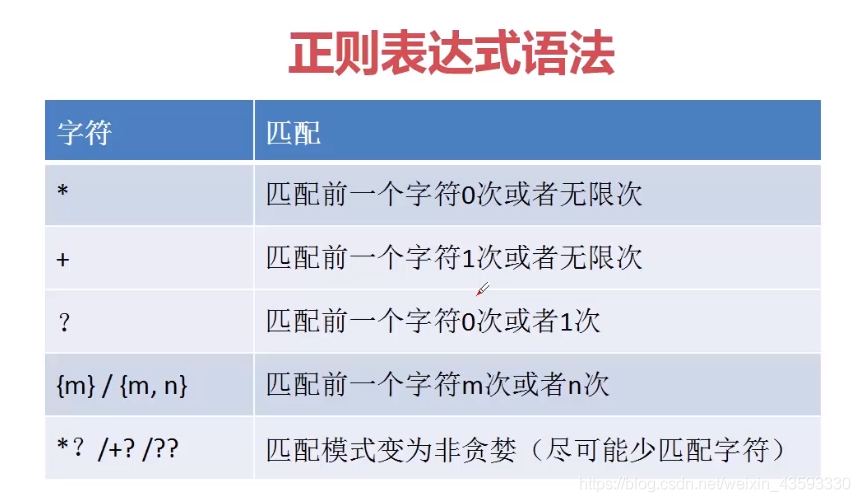
# [A-Z][a-z] Adasdas = 0到无穷大
ma = re.match(r’[A-Z][a-z]‘,’Afsdsdf’)
# [a-zA-z]+[\w] + = 1到无穷大
ma = re.match(r’[a-zA-z]+[\w]*’,’_ht11’)
# [1-9]?[0-9] ? = 0到1
ma = re.match(r’[1-9]?[0-9]’,’87’)
边界匹配

^: 在[]前面表示以什么开头,在[]里面表示除括号内字符之外的任意一个字符^:
以什么开头
$:
以什么结尾
$:
分组匹配
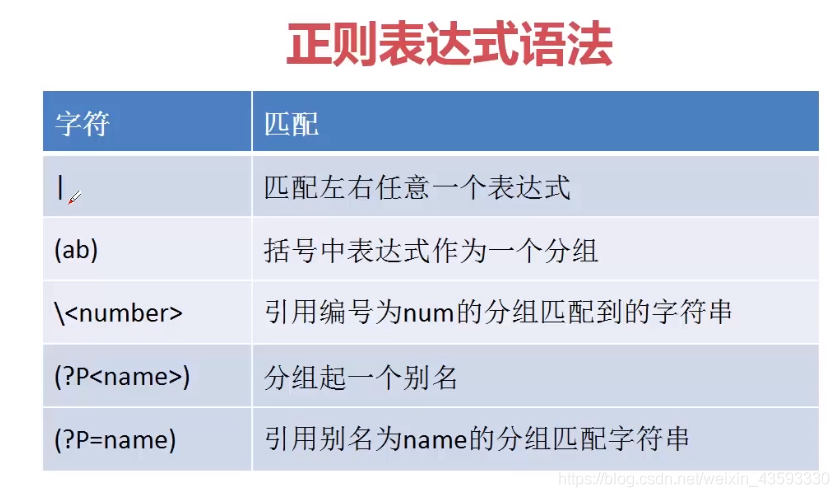
常用方法
1、search(pattern,string,flags=0)在一个字符串中查找匹配
2、findall(pattern,string,flags=0)
找到匹配,返回所以匹配部分的列表
3、sub(patten,repl,string,count=0,flags=0)
将字符串中匹配正则表达式部分替换为其他值
使用sub方法后会返回一个新的字符串 原字符串不变
4、split(patten,repl,string,count=0,flags=0)
根据匹配分割字符串,返回分割字符串组成的列表

若有收获,就点个赞吧
0 人点赞
