网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引;
网页抓取:用爬虫(或者机器人)自动替你完成网页抓取数据工作,一般是先存储起来,放到数据库或者电子表格中,以备检索或者进一步分析使用。
滚雪球功能:找到链接、获得Web页面、抓取指定信息、存储;可使用自动化方式完成。
Python语言的重要特色:利用强大的软件工具包(许多都是第三方提供)。你只需要编写简单的程序,就能自动解析网页,抓取数据。
Python爬虫案例—豆瓣电影
一、什么是爬虫?
按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和有限性,根据用户需求定向抓取相关网页并分析,已经成为主流的爬取策略。
爬虫的本质?
模拟浏览器打开网页,获取网页中我们想要的那部分数据存储到数据库中。
二、蜘蛛的爬行原理
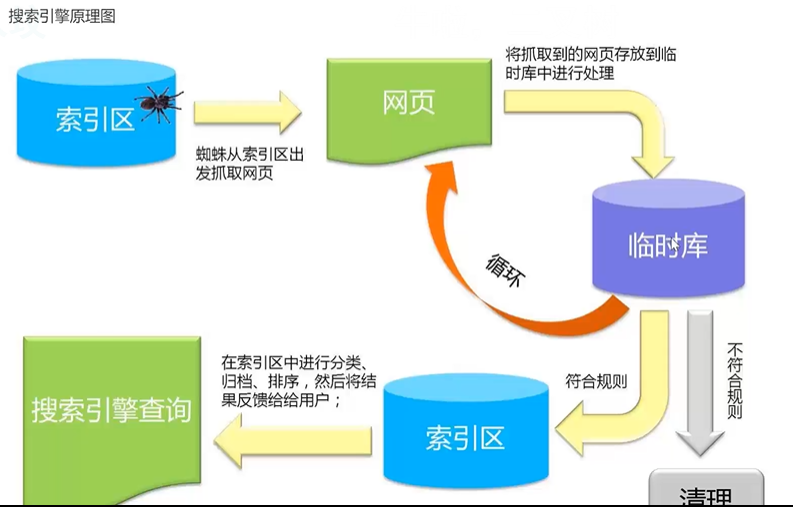
爬虫:索引区到临时库;
数据可视化:临时库到搜索引擎查询;
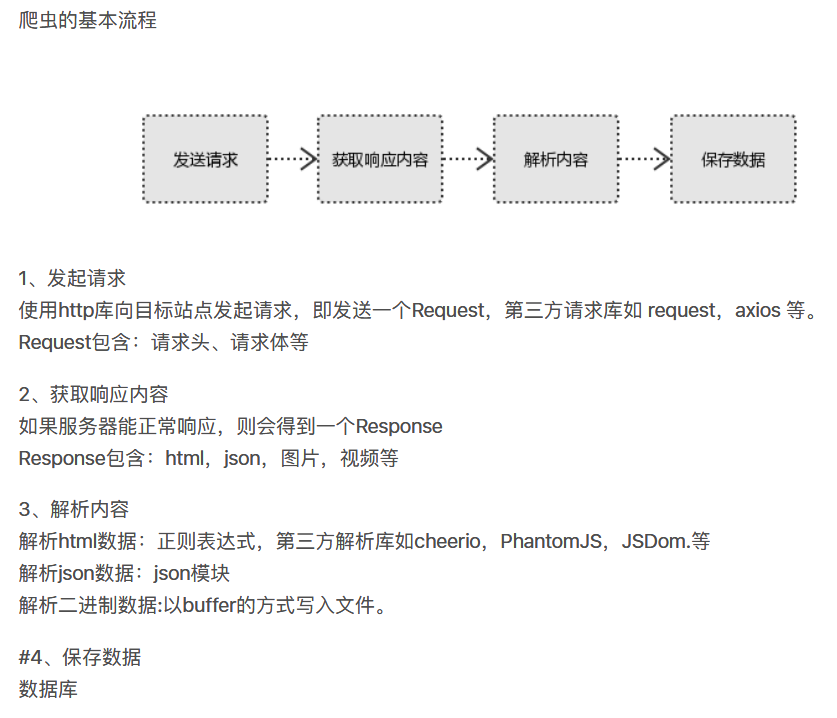
三、基本流程

1、准备工作


2、获取数据
beautifulsoup:将html文件
案例地址:https://movie.douban.com/top250

若有收获,就点个赞吧
0 人点赞
