前言
近些年随着深度学习的兴起,Python受到的关注日益增长。不过在应用开发领域,Python很难与运行效率更高的 Java、GO等抗衡。前端除了传统的三驾马车之外,Dart与Swift也在移动端及嵌入式领域不断地开疆拓土,Python生态中的Kivy框架带来的影响相对有限。本文探索了一种使用Python新兴框架开发自然语言处理应用的途径,虽然称不上是多大的创新,但是目前互联网上还没有相应的尝试。这些框架都巧妙地利用了Python 3.5之后新的特性,随着版本的不断更新,相信会带来更多有趣的应用。
Ⅰ. Hanlp
HanLP是一系列模型与算法组成的NLP工具包,目前HanLP 2.0版本正处于alpha测试阶段。我们可以使用该工具包快速构建分词、词性标注、命名实体识别、依存句法分析、语义依存分析等功能。
Hanlp 2.0 是直接支持 Java 和 Python接口的,这点与 Hanlp 1.x版本不同。1.x版本主要支持 java,使用python调用实际调用的是 pyhanlp相关接口。具体项目详情可以登录相关项目主页:
https://github.com/hankcs/HanLP
由于Hanlp 2.0基于 TensorFlow 2.1,因此需要先安装最新版 TensorFlow:
pip install tensorflow==2.1
我用的是云服务器,没有安装GPU版本,直接安装会安装 TensorFlow 1.x 的版本,可以使用以下命令升级:
pip install tensorflow --upgrade
完成后可以测试一下是否安装成功:
import tensorflow as tf print(tf.__version__)
'2.1.0'
显示了正确的版本号,就可以继续安装 Hanlp:
pip install hanlp
Hanlp会自动根据已经安装的tensorflow版本进行安装,安装完成后同样测试一下:
import hanlpprint(hanlp.__version__)
'2.0.0-alpha.38'
打印 hanlp.pretrained.ALL 可以列出HanLP中的所有预训练模型,一共有41个:
print(hanlp.pretrained.ALL)
{'CHNSENTICORP_BERT_BASE_ZH': 'https://file.hankcs.com/hanlp/classification/chnsenticorp_bert_base_20200104_164655.zip',... 'TENCENT_AI_LAB_EMBEDDING': 'https://ai.tencent.com/ailab/nlp/data/Tencent_AILab_ChineseEmbedding.tar.gz#Tencent_AILab_ChineseEmbedding.txt'}
这里只列出本文中要用到的四个模型:
| 模型名称 | 类型 |
|---|---|
| PKU_NAME_MERGED_SIX_MONTHS_CONVSEG | 中文分词 |
| rules.tokenize_english | 英文分词 |
| MSRA_NER_BERT_BASE_ZH | 中文命名实体识别 |
| CTB7_BIAFFINE_DEP_ZH | 中文依存句法分析 |
1. 中文分词
引入模型:
import hanlptokenizer = hanlp.load('PKU_NAME_MERGED_SIX_MONTHS_CONVSEG')
单句分词:
tokenizer('商品和服务')
['商品', '和', '服务']
批量并行分词:
tokenizer(['萨哈夫说,伊拉克将同联合国销毁伊拉克大规模杀伤性武器特别委员会继续保持合作。','上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观。','HanLP支援臺灣正體、香港繁體,具有新詞辨識能力的中文斷詞系統'])
[['萨哈夫', '说', ',', '伊拉克', '将', '同', '联合国', '销毁', '伊拉克', '大', '规模', '杀伤性', '武器', '特别', '委员会', '继续', '保持', '合作', '。'],['上海', '华安', '工业', '(', '集团', ')', '公司', '董事长', '谭旭光', '和', '秘书', '张晚霞', '来到', '美国', '纽约', '现代', '艺术', '博物馆', '参观', '。'],['HanLP', '支援', '臺灣', '正體', '、', '香港', '繁體', ',', '具有', '新詞', '辨識', '能力', '的', '中文', '斷詞', '系統']]
2. 英文分词
英文本身是不需要分词的,因此这里直接使用基于规则的普通函数:
tokenizer = hanlp.utils.rules.tokenize_englishtokenizer("Don't go gentle into that good night.")
['Do', "n't", 'go', 'gentle', 'into', 'that', 'good', 'night', '.']
3.中文命名实体识别
中文命名实体识别是字符级模型,输入使用 list将字符串转换为字符列表。输出格式为 (entity, type, begin, end)。
recognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)recognizer([list('上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观。'), list('萨哈夫说,伊拉克将同联合国销毁伊拉克大规模杀伤性武器特别委员会继续保持合作。')])
[[('上海华安工业(集团)公司', 'NT', 0, 12),('谭旭光', 'NR', 15, 18),('张晚霞', 'NR', 21, 24),('美国', 'NS', 26, 28),('纽约现代艺术博物馆', 'NS', 28, 37)],[('萨哈夫', 'NR', 0, 3),('伊拉克', 'NS', 5, 8),('联合国销毁伊拉克大规模杀伤性武器特别委员会', 'NT', 10, 31)]]
4.中文依存句法分析
句法分析器的输入是单词列表及词性列表,输出是 CoNLL-X 格式 [^conllx] 的句法树。
syntactic_parser = hanlp.load(hanlp.pretrained.dep.CTB7_BIAFFINE_DEP_ZH)print(syntactic_parser([('蜡烛', 'NN'), ('两', 'CD'), ('头', 'NN'), ('烧', 'VV')]))
1 蜡烛 _ NN _ _ 4 nsubj _ _2 两 _ CD _ _ 3 nummod _ _3 头 _ NN _ _ 4 dep _ _4 烧 _ VV _ _ 0 root _ _
由于预训练模型都较大,需要预留好足够的存储空间。
个人经验是最好在云服务器上下载,如果是下载到本地最好提前下载,并且晚上下载速度会快一些。
下面介绍 FastAPI 以及对 NLP 功能的接口封装。
Ⅱ. FastAPI
2005年就有人说过:“Python是一门web框架比关键字还多的语言“。近几年主要流行的Python Web框架是Django和Flask。不过Django较为繁重,Flask常常被人诟病其异步性能。
自从 Python3.5 中正式将协程做为底层技术引入之后,关于如何构建标准异步web框架的讨论就源源不绝。之后便诞生了一些基于 ASGI 的 web 框架,如:API Star、Uvicorn、Starlette、FastAPI等等。
其中FastAPI是个比较有趣的项目:它并非一个从零开始的项目,而是基于Starlette和Pydantic,其中Starlette又是基于Uvicorn的。
这里我们可以看一下FastAPI的源码,在dependencies文件夹下的 utils.py 引用部分:
from fastapi.dependencies.models import Dependant, SecurityRequirementfrom fastapi.security.base import SecurityBasefrom fastapi.security.oauth2 import OAuth2, SecurityScopesfrom fastapi.security.open_id_connect_url import OpenIdConnectfrom fastapi.utils import PYDANTIC_1, get_field_info, get_path_param_namesfrom pydantic import BaseConfig, BaseModel, create_modelfrom pydantic.error_wrappers import ErrorWrapperfrom pydantic.errors import MissingErrorfrom pydantic.utils import lenient_issubclassfrom starlette.background import BackgroundTasksfrom starlette.concurrency import run_in_threadpoolfrom starlette.datastructures import FormData, Headers, QueryParams, UploadFilefrom starlette.requests import Requestfrom starlette.responses import Responsefrom starlette.websockets import WebSocket
因此可以将FastAPI视做对Starlette的高级封装,并引入了Pydantic来对数据进行数据验证和设置管理。
单从性能上来说应该是 Uvicorn > Starlette > FastAPI :
项目官网列出了FastAPI的主要优点:
- 性能快:高性能,可以和NodeJS和Go相提并论;
- 快速开发:开发功能速度提高约200%至300%;
- 更少的Bug:减少40%开发人员容易引发的错误;
- 直观:完美的编辑支持,补全功能缩减了debugging的时间;
- 简单: 易于使用和学习,减少阅读文档的时间;
- 代码简洁:很大程度上减少代码重复。每个参数可以声明多个功能,减少bug的发生;
- 标准化:基于并完全兼容API的开发标准:
OpenAPI(以前称为Swagger)和JSON Schema。
1. 安装
直接使用 pip安装:
pip install fastapi
如果用于生产,那么你还需要一个ASGI服务器,如Uvicorn或Hypercorn:
pip install uvicorn
2. 创建FastAPI项目
创建main.py文件
from fastapi import FastAPI# 实例化app = FastAPI()# 创建一个get请求@app.get("/")def first_fuc():return {"Hello": "World"}# 再创建一个get请求@app.get("/any/{item_id}")def second_fuc(item_id: int, q: str = None):return {"item_id": item_id, "q": q}
如果代码需要用到异步async/await,使用async def,如下所示:
from fastapi import FastAPIapp = FastAPI()@app.get("/")async def first_fuc():return {"Hello": "World"}@app.get("/any/{item_id}")async def second_fuc(item_id: int, q: str = None):return {"item_id": item_id, "q": q}
3. 运行项目
运行服务器:
uvicorn main:app --reload
命令
uvicorn main:app --reload指的是:
- main:main.py文件
- app:app = FastAPI() 在main.py内创建的对象。
- —reload:在代码更改后重新启动服务器。只有在开发时才使用这个参数。

4. 检查项目
在浏览器中打开网址:http://127.0.0.1:8000
可以看见json格式的响应数据: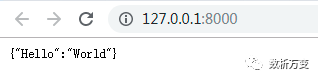
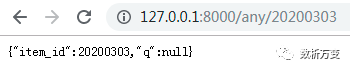
这样便创建了一个API:
- url:/ 和 / any / {item_id},两个url都可以接收HTTP请求。
- / 和 / any / {item_id} 都采用GET方式的HTTP请求方法
- / any / {item_id}包含路径参数item_id,格式为int
- / any / {item_id}还包含一个可选的参数q,格式为str
5. 交互的API文档
现在进入 http://127.0.0.1:8000/docs
便会得到自动的交互式API文档,该文档由 Swagger UI 提供。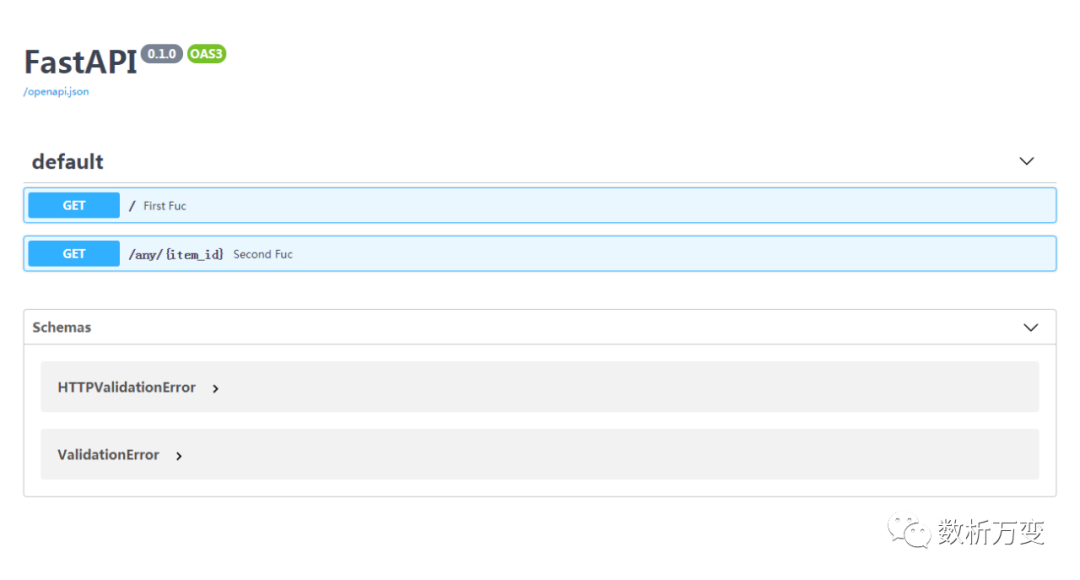
在这个界面可以点开不同的HTTP请求,然后进行接口测试,具体效果见下方动图: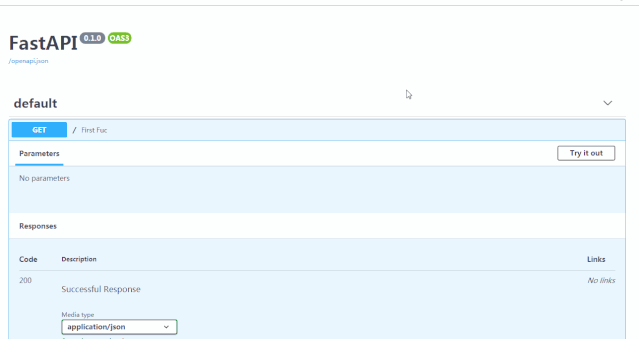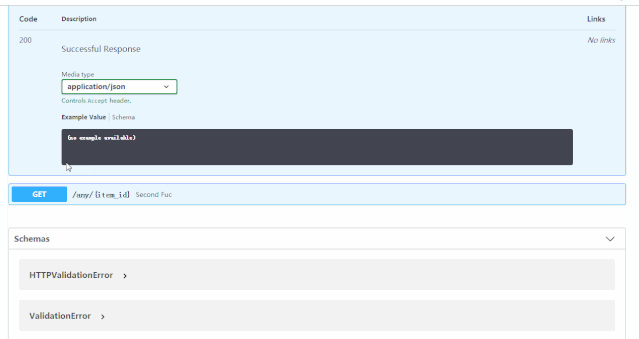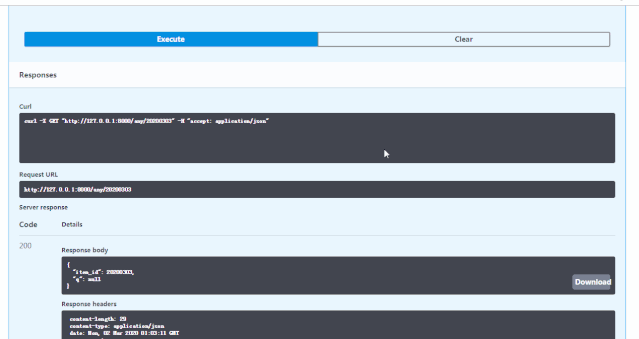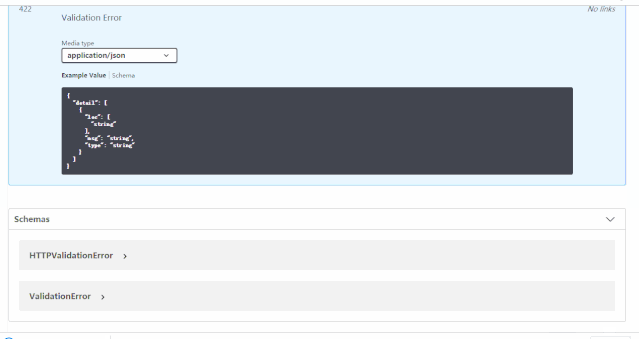
6. 备用API文档
现在,转到 http://127.0.0.1:8000/redoc
这里是备用自动文档(由ReDoc提供)。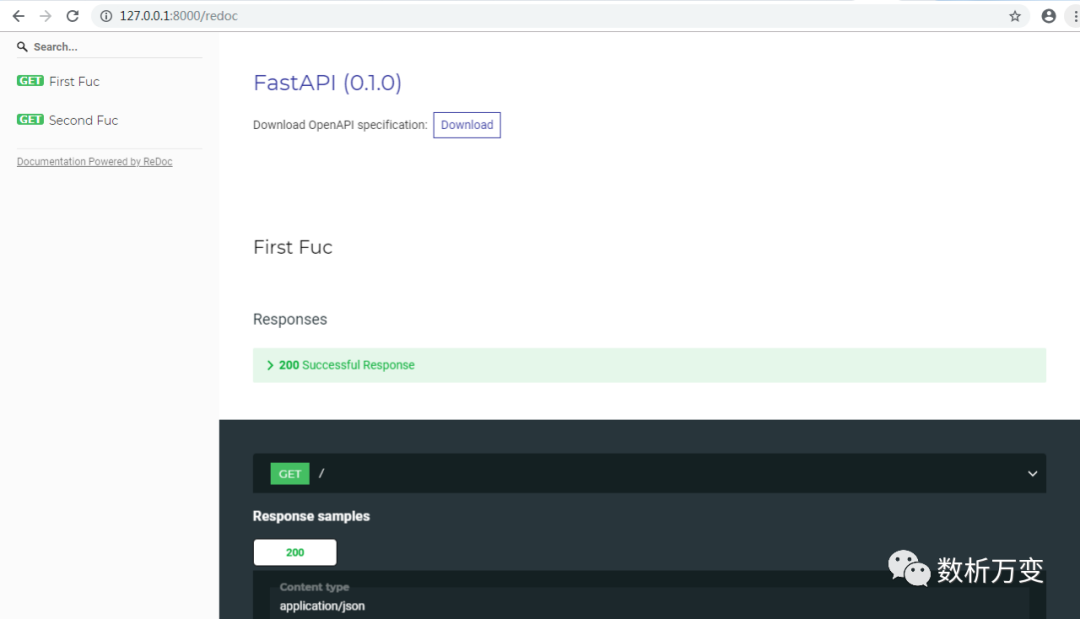
7. 下载API接口文档
如果需要提供API接口,那么只需要一行命令,即可下载api文件,一般保存为api.json
curl -o api.json http://127.0.0.1:8000/openapi.json
8. 对hanlp进行接口封装
我们需要调用 Hanl p的四个模型功能中,两个模型的输入是字符串,两个模型的输入是列表,此处统一为列表。
设计接口的输入为以下格式的 JSON 字符串:
{"model_name": str,"input": list,}
接口的返回输出为:
{"success": bool,"rlt": list}
下面直接贴出全部的后端代码:
#!/usr/bin/python# -*- coding: UTF-8 -*-from fastapi import FastAPIfrom pydantic import BaseModelimport hanlp# 应用实例化app = FastAPI()# 导入Hanlp相关模型tokenizer_zh = hanlp.load('PKU_NAME_MERGED_SIX_MONTHS_CONVSEG')tokenizer_en = hanlp.utils.rules.tokenize_englishrecognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)syntactic_parser = hanlp.load(hanlp.pretrained.dep.CTB7_BIAFFINE_DEP_ZH)# 定义数据格式class Data(BaseModel):model_name: strinput: list# 中文分词接口@app.post('/tok_zh')def split_cn(data_zh: Data):msg = data_zh.inputrlt = [tokenizer_zh(x) for x in msg]return {'success': True, 'rlt': rlt}# 英文分词接口@app.post('/tok_en')def split_en(data_en: Data):msg = data_en.inputrlt = [tokenizer_en(x) for x in msg]return {'success': True, 'rlt': rlt}# 中文命名实体识别@app.post('/ner')def ner(data_zh: Data):msg = data_zh.inputrlt = [recognizer(x) for x in msg]return {'success': True, 'rlt': rlt}# 中文依存句法分析接口@app.post('/parser')def parser(data_zh: Data):msg = data_zh.inputrlt = syntactic_parser(msg)return {'success': True, 'rlt': rlt}
如果希望程序支持异步执行,只需要将以上代码中 def 修改为 async def 即可。
9. 在服务器上启动项目
由于使用了云服务器,所以在运行时要设置 ip 以及端口号:
uvicorn main:app --reload --host 0.0.0.0 --port 80
其中 --host 是设置ip地址,0.0.0.0意思就是使用本机的公网 ip, 然后 --port:80 是指将端口号设置为80。
根据云服务器的安全策略,使用其他端口需要进入控制台,开放相应端口的外网访问权限。
更多的设置可以通过 uvicorn --help 进行查询。项目启动后如果显示以下内容则表示启动成功。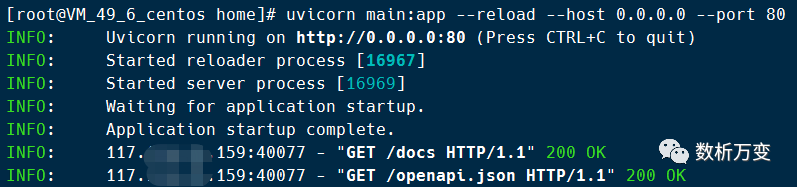
然后在浏览器中输入 ip 地址/docs 进入到如下接口页面便可以对接口进行调试: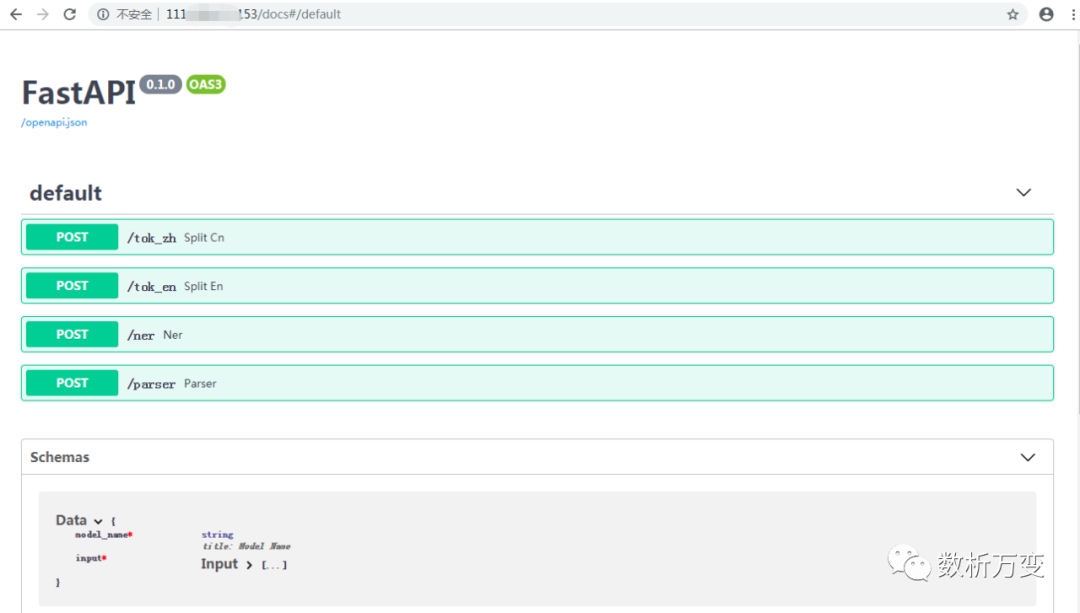
从图中可以看出一共有四个接口,都是 POST 类型的,后面有相对路径和函数名。具体测试方法与上文相同,不再赘述。
Ⅲ. Streamlit
要说2019年开源社区的宝藏项目,Streamlit绝对排的上号。本公众号在之前的文章《使用Python快速制作一个疫情数据分析应用》中也有简单介绍。官方宣称它是:The fastest way to build custom ML tools。
具体有多块呢?可见下图展示的例子,使用两百多行代码就制作了一个用于自动驾驶的车辆检测应用: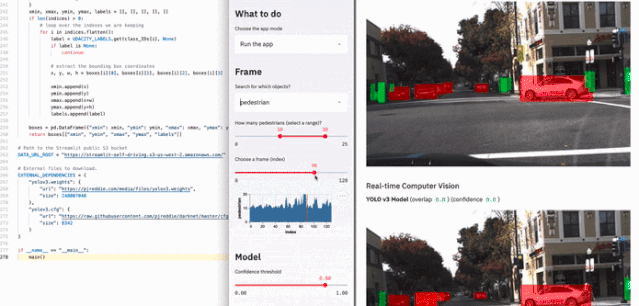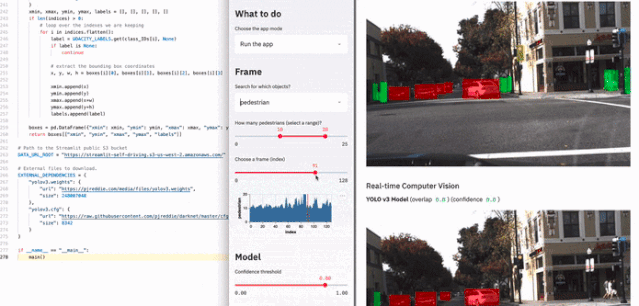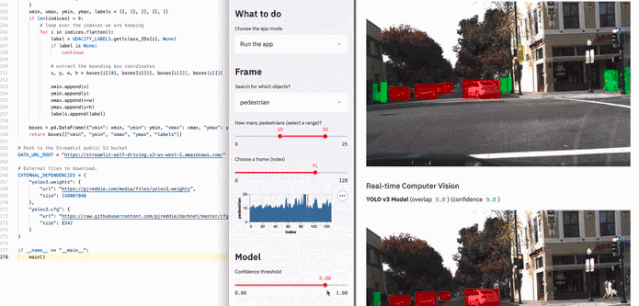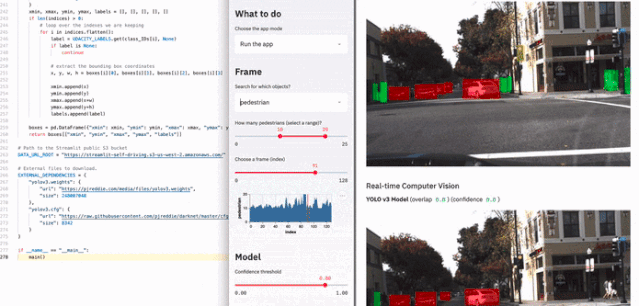
当然 Streamlit 相对于传统前端还是有很多的问题,比如:控件数量较少;可修改的自由度有限;没有传统的递归,每次请求都相当于重新运行整个脚本或者要使用 cache 改进性能。
不过将其作为快速应用的开发,以及机器学习工具的配置式前端,都是十分不错的。毕竟相比花费一、两周制作一个完美的页面,一个小时就能展示模型能力更加吸引 AI 开发者。
同样直接贴出使用Streamlit搭建前端的代码:
#!/usr/bin/python# -*- coding: UTF-8 -*-import streamlit as stimport requests# 定义接口查询函数def send2back(data_bin):rlt = requests.post('http://111.229.217.153:80/ner', json=data_bin).json()st.title("自然语言处理APP")html_tmp = """<div style="background-color:tomato;padding:10px"><h2 style="color:white;text-align:center;">基于Hanlp与FastAPI制作</h2></div>"""st.markdown(html_tmp, unsafe_allow_html=True)st.markdown('---')option = st.selectbox('请选择你想要使用的功能:',('', '中文分词', '英文分词', '中文命名实体识别', '中文依存句法分析'))content = st.text_input('请输入待分析的内容:')if option == '中文分词':if st.button("中文分词") & (content != ''):data_bin = {'model_name': 'tok_zh', 'input': [content]}rlt = requests.post('http://111.229.217.153:80/tok_zh', json=data_bin).json()st.text(rlt['rlt'][0])elif option == '英文分词':if st.button("英文分词") & (content != ''):data_bin = {'model_name': 'tok_en', 'input': [content]}rlt = requests.post('http://111.229.217.153:80/tok_en', json=data_bin).json()st.text(rlt['rlt'][0])elif option == '中文命名实体识别':if st.button("命名实体识别") & (content != ''):data_bin = {'model_name': 'ner', 'input': [list(content)]}rlt = requests.post('http://111.229.217.153:80/ner', json=data_bin).json()st.write(rlt)elif option == '中文依存句法分析':if st.button("依存句法分析") & (content != ''):data_bin = {'model_name': 'parser', 'input': [content]}rlt = requests.post('http://111.229.217.153:80/parser', json=data_bin).json()st.write(rlt)else:pass
调用后台接口的是Python的HTTP库 requests。如果后台使用了 async def异步函数,那么建议将 requests 替换为同为异步的 aiohttp。
将以上代码保存为文件 front.py,在终端中运行:
streamlit run front.py
运行成功后终端便会显示: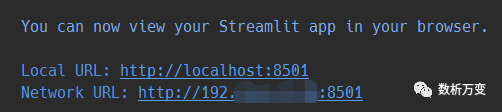
因为我是在本地电脑上运行,默认端口是8501,如果在服务器上运行,需要配置 ip 地址和端口号。详见官方文档:https://docs.streamlit.io/
在浏览器中输入:http://localhost:8501/
便可看到我们NLP应用的界面: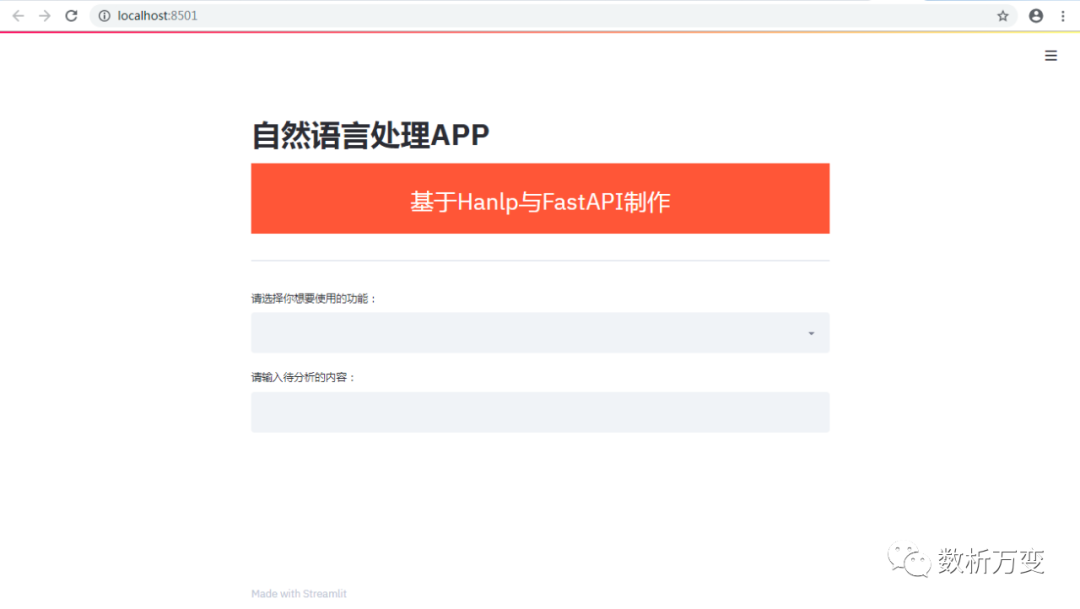
然后我们测试一下:
Streamlit的另外一个优点是:开发出来的应用可以基于设备自适应,因此在手机端浏览也会有较好的体验效果。有兴趣的小伙伴可以自行尝试。
Ⅳ. 进阶
以上简单介绍了使用 FastAPI以及 Streamlit开发一款基于Hanlp的自然语言处理应用的方法。
完整的开发流程还应包括反向代理设置,以及使用容器工具打包。这些在本文中不是重点,就不一一展开了。
本文提到的三种框架中:
- Hanlp 基于Tensorflow;
- FastAPI 基于 Scarlett和P ydantic;
- Streamlit 依赖于 tornado。
这揭示了一种APP开发的趋势:使用更高级的框架,尽可能地忽略掉底层的细节,以此达到快速开发和迭代的目的。
不过这并不意味着以后开发人员就不用弄懂web的各种细节。
相反,只有明白底层细节才能快速上手高级框架,并且不至于跌入高度抽象的陷阱当中。想要去个性化地定制系统或者提高性能,就必须深入了解其底层架构。
这里只是对这种思路的一种尝试,后面我会继续探索将更多新的框架纳入生产中的 pipeline。比方说 AllenNLp、FastAI以及流计算框架Flink等等。
欢迎关注我的公众号“数析万变”,原创技术观点第一时间推送。
文章已于2020-03-13修改

若有收获,就点个赞吧
0 人点赞
