层次分析法(Analytic Hierarchy Process,AHP)由美国运筹学家托马斯·塞蒂(T. L. Saaty)于20世纪70年代中期提出,用于确定评价模型中各评价因子/准则的权重,进一步选择最优方案。该方法仍具有较强的主观性,判断/比较矩阵的构造在一定程度上是拍脑门决定的,一致性检验只是检验拍脑门有没有自相矛盾得太离谱。
一、层次分析法概述
人们在对社会、经济以及管理领域的问题进行系统分析时,面临的经常是一个由相互关联、相互制约的众多因素构成的复杂系统。层次分析法则是为研究这类复杂的系统,提供了一种新的、简洁的、实用的决策方法。
层次分析法(AHP 法):是一种简便、灵活的多维准则决策的数学方法,它可以实现由定性到定量的转化,把复杂的问题系统化、层次化。在应用时首先要明确所要最终解决的问题,然后建立包含最高层、中间层和最低层组合排序的层次分析结构模型,它的信息主要是基于人们对于每一层次中各因素相对重要性作出的判断,这种判断按1-9分值对比打分,做出判断矩阵。
层次分析法(AHP法)是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。
AHP法的核心是将决策者的经验判断定量化,增强了决策依据的准确性,在目标结构较为复杂且缺乏统计数据的情况下更为实用。应用AHP法确定评价指标的权重,就是在建立有序递阶的指标体系的基础上,通过比较同一层次各指标的相对重要性来综合计算指标的权重系数。
二、层次分析法原理
层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排定。
层次分析法的特点是在对复杂的决策问题的本质、影响因素及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。尤其适合于对决策结果难于直接准确计量的场合。
三、层次分析法的步骤和方法
1. 建立层次结构模型
利用层次分析法研究问题时,首先要把与问题有关的各种因素层次化,然后构造出一个树状结构的层次结构模型,称为层次结构图。一般问题的层次结构图分为三层,如图所示。
- 最高层为目标层(O):问题决策的目标或理想结果,只有一个元素。(决策的目的、要解决的问题)
- 中间层为准则层(C):包括为实现目标所涉及的中间环节各因素,每一因素为一准则,当准则多于9个时可分为若干子层。(主因素,考虑的因素、决策的准则)
- 最低方案层(P):方案层是为实现目标而供选择的各种措施,即为决策方案。(决策时的备选方案,也可为中间层的子因素)
一般来说,各层次之间的各因素,有的相关联,有的不一定相关联;各层次的因素个数也未必一定相同。十几种,主要是根据问题的性质和各相关因素的类别来确定。
层次分析法所要解决的问题是关于最低层对最高层的相对权重问题,按此相对权重可以对最底层中的各种方案、措施进行排序,从而在不同的方案中作出选择或形成选择方案的原则。
- 最高层:决策的目的、要解决的问题
- 中间层:主因素,考虑的因素、决策的准则
- 最低层:决策时的备选方案,也可为中间层的子因素
层次分析法的多级递阶层次模型分为三类:完全相关性结构(上层每一因素与下层所有因素均有联系)、完全独立性结构(上层每一因素都有独立的下层要素)、混合型结构(前述两种结构的混合结构)。本例为完全独立性结构,如下图。
 层次分析法涉及多层次的因素打分与赋权,首先针对中间层的主因素进行AHP单排序。
层次分析法涉及多层次的因素打分与赋权,首先针对中间层的主因素进行AHP单排序。
2. 构造判断(成对比较)矩阵
构造比较矩阵主要是通过比较同一层次上的各因素对上一层相关因素的影响。而不是把所有因素放在一起比较,即将同一层的各因素进行两两对比。比较时采用相对尺度标准度量,尽可能地避免不同性质的因素之间相互比较的困难。同时,要尽量依据实际问题具体情况,减少由于决策人主观因素对结果造成的影响。
设要比较 n 个因素  对上一层(如目标层)
对上一层(如目标层) 的影响程度,即要确定它在 中所占的比重。对任意两个因素
的影响程度,即要确定它在 中所占的比重。对任意两个因素  和
和  ,用
,用  表示 和 对 的影响程度之比,按1~9的比例标度来度量
表示 和 对 的影响程度之比,按1~9的比例标度来度量  。于是,可得到两两成对比较矩阵
。于是,可得到两两成对比较矩阵  ,又称为判断矩阵,显然
,又称为判断矩阵,显然
因此,又称判断矩阵为正互反矩阵。
比例标度的确定:取1-9的9个等级, 取的倒数,1-9标度确定如下:
取的倒数,1-9标度确定如下:







由正互反矩阵的性质可知,只要确定 A 的上(或下)三角的  个元素即可。在特殊情况下,如果判断矩阵A的元素具有传递性,即满足
个元素即可。在特殊情况下,如果判断矩阵A的元素具有传递性,即满足
则称A为一致性矩阵,简称为一致阵。
2.1. 构造判断/比较矩阵
通过各因素之间的两两比较确定合适的标度:将不同因素(因素  与 因素
与 因素 )两两作比获得的值 填入到矩阵
)两两作比获得的值 填入到矩阵 的 行 列的位置,成对比较矩阵中的取值 可参考Satty的提议,如下表所示。
的 行 列的位置,成对比较矩阵中的取值 可参考Satty的提议,如下表所示。
通过各因素之间的两两比较确定合适的标度:将不同因素(因素 与 因素 )两两作比获得的值 填入到矩阵的行列的位置,成对比较矩阵中的取值可参考下表所示。
| 因素i比因素j | 分值 |
|---|---|
| 同等重要 | 1 |
| 稍微重要 | 3 |
| 较强重要 | 5 |
| 强烈重要 | 7 |
| 极端重要 | 9 |
| 两相邻判断的中间值 | 2,4,6,8 |
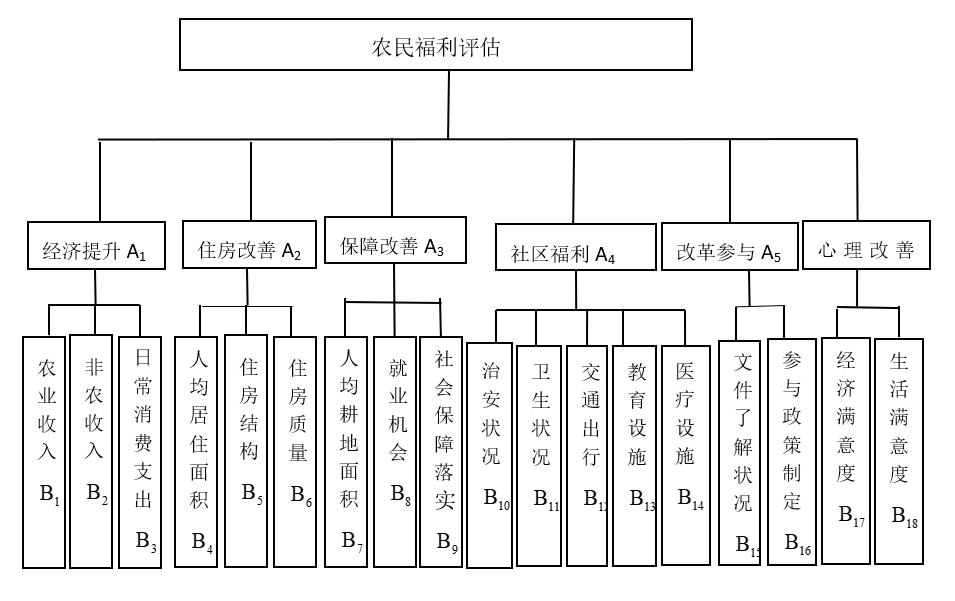
本例的中间层主因素有经济提升、住房改善、保障改善、社区福利、改革参与 心理改善,构建矩阵的如下表所示。对角线上恒定为1, 因为是和自己做比。
| 评价 | 经济提升 | 住房改善 | 保障改善 | 社区福利 | 改革参与 | 心理改善 |
|---|---|---|---|---|---|---|
| 经济提升 | 1 | a12 | a13 | a14 | a15 | a16 |
| 住房改善 | a21 | 1 | a23 | a24 | a25 | a26 |
| 保障改善 | a31 | a32 | 1 | a34 | a35 | a36 |
| 社区福利 | a41 | a42 | a43 | 1 | a45 | a46 |
| 改革参与 | a51 | a52 | a53 | a54 | 1 | a55 |
| 心理改善 | a61 | a62 | a63 | a64 | a65 | 1 |
对上表进行简化即可获得如下矩阵,该矩阵称为判断/比较矩阵:

2.2. 计算因子/准则权重
显然判断矩阵MMM是正互反矩阵,即满足以下条件:

进一步,将满足以下条件的正互反矩阵称为一致性矩阵:

直观的理解:如果i对j的重要程度是a,j对k的重要程度是b,那么i对k的重要程度应该a*b,类似于传递性。
一致性矩阵具有如下重要性质:若一致性矩阵  的最大特征值
的最大特征值  对应的特征向量为
对应的特征向量为
, 则 。
。
结合判断矩阵的构建可知表示因素 相对于因素 的重要性,而
,因此可以将 与
与 分别作为因素 与因素 的绝对重要性,也即因素 与因素 的权重,从而
分别作为因素 与因素 的绝对重要性,也即因素 与因素 的权重,从而  即为各因素的权重向量。还须对向量 进行归一化处理:每个权重除以权重和作为自己的值,最终总和为1。
即为各因素的权重向量。还须对向量 进行归一化处理:每个权重除以权重和作为自己的值,最终总和为1。
然而判断矩阵 一般不满足一致性,但是仍将其当做一致矩阵来处理,从而获得一组权重,但是这组权重能不能被接受,需要进行一致性检验。
2.3. 一致性检验
一致性检验是指对判断矩阵 确定不一致的允许范围。n 阶一致阵的唯一非零特征根为 n,n 阶正互反阵 的最大特征根  时, 为非一致矩阵,
时, 为非一致矩阵, 比 n 大的越多, 的不一致性越严重; 当且仅当
比 n 大的越多, 的不一致性越严重; 当且仅当 时, 为一致矩阵。因此可由
时, 为一致矩阵。因此可由  是否等于 n 来检验判断矩阵是否为一致矩阵。
是否等于 n 来检验判断矩阵是否为一致矩阵。
具体的一致性指标用  计算,越小,说明一致性越大。
计算,越小,说明一致性越大。 ,有完全的一致性; 接近于0,有满意的一致性; 越大,不一致越严重。
,有完全的一致性; 接近于0,有满意的一致性; 越大,不一致越严重。
考虑到一致性的偏离可能是由于随机原因造成的,因此引入随机一致性指标  衡量随机因素所造成的一致性偏离的大小:
衡量随机因素所造成的一致性偏离的大小:
随机一致性指标RI和判断矩阵的阶数有关,一般情况下,矩阵阶数越大,则出现一致性随机偏离的可能性也越大,指标通过查表获得:
| 矩阵阶数 n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.9 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
最终使用的检验统计量为检验系数CR,公式如下:
当  时,认为判断矩阵的一致性是可以接受的,否则须要对判断矩阵作适当修正。
时,认为判断矩阵的一致性是可以接受的,否则须要对判断矩阵作适当修正。
3. 层次单排序及一致性检验
3.1 相对权重向量确定
(1)和积法
取判断矩阵n个列向量归一化后的算术平均值,近似作为权重,即
类似地,也可以对按行求和所得向量作归一化,得到相应的权重向量。
(2)求根法(几何平均法)
将A的各列(或行)向量求几何平均后归一化,可以近似作为权重,即
(3)特征根法
设想把一大石头Z分成n个小块 ,其重量分别为
,其重量分别为 ,则将n快小石头作两两比较,记
,则将n快小石头作两两比较,记 的相对重量为
的相对重量为 ,于是可得到比较矩阵
,于是可得到比较矩阵
显然,A为一致性正互反矩阵,记 ,即为权重向量,且
,即为权重向量,且
则
这表明W为矩阵A的特征向量,且n为特征根。
事实上:对于一般的判断矩阵A有 ,这里
,这里 是A的最大特征根, 为 对应的特征向量。
是A的最大特征根, 为 对应的特征向量。
3.2 一致性检验
以下为AHP单排序的示例代码
import numpy as npclass AHP:#传入的np.ndarray是的判断矩阵def __init__(self,array):self.array = array# 记录矩阵大小self.n = array.shape[0]# 初始化RI值,用于一致性检验RI_list = [0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]self.RI = RI_list[self.n-1]#获取最大特征值和对应的特征向量def get_eig(self):#numpy.linalg.eig() 计算矩阵特征值与特征向量eig_val ,eig_vector = np.linalg.eig(self.array)#获取最大特征值max_val = np.max(eig_val)max_val = round(max_val.real, 4)#通过位置来确定最大特征值对应的特征向量index = np.argmax(eig_val)max_vector = eig_vector[:,index]max_vector = max_vector.real.round(4)#添加最大特征值属性self.max_val = max_val#计算权重向量Wweight_vector = max_vector/sum(max_vector)weight_vector = weight_vector.round(4)#打印结果print("最大的特征值: "+str(max_val))print("对应的特征向量为: "+str(max_vector))print("归一化后得到权重向量: "+str(weight_vector))return weight_vector#测试一致性def test_consitst(self):#计算CI值CI = (self.max_val-self.n)/(self.n-1)CI = round(CI,4)#打印结果print("判断矩阵的CI值为" +str(CI))print("判断矩阵的RI值为" +str(self.RI))#分类讨论if self.n == 2:print("仅包含两个子因素,不存在一致性问题")else:#计算CR值CR = CI/self.RICR = round(CR,4)#CR < 0.10才能通过检验if CR < 0.10 :print("判断矩阵的CR值为" +str(CR) + ",通过一致性检验")return Trueelse:print("判断矩阵的CR值为" +str(CR) + ",未通过一致性检验")return False
从理论上分析得到:如果A是完全一致的成对比较矩阵,应该有
但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵的一致性要求,转化为要求: 的绝对值最大的特征值和该矩阵的维数相差不大。
检验成对比较矩阵A一致性的步骤如下:
计算衡量一个成对比较矩阵A (n>1 阶方阵)不一致程度的指标CI:
RI是这样得到的:对于固定的n,随机构造成对比较阵A,其中a i j是从1,2,…,9,1/2,1/3,…,1/9中随机抽取的.这样的A是不一致的,取充分大的子样得到A的最大特征值的平均值。
注解:
- 从有关资料查出检验成对比较矩阵A 一致性的标准RI:RI称为平均随机一致性指标,它只与矩阵阶数n 有关(一般不超过9个)。
- 按下面公式计算成对比较阵A 的随机一致性比率CR:
- 判断方法如下: 当CR<0.1时,判定成对比较阵A 具有满意的一致性,或其不一致程度是可以接受的;否则就调整成对比较矩阵A,直到达到满意的一致性为止。
例子的矩阵
特征向量: 0.47439499 0.26228108 0.0544921 0.09853357 0.11029827 (相加等于1)
算法过程 先对数组进行列相加——- [2.04285714,3.91666667,17 ,10.5 ,10.33333333]
再用等到的结果除以原矩阵得到一个新的矩阵:
再对矩阵进行行相加等到———-[2.37197494 1.31140538 0.2724605 0.49266783 0.55149136]
在进行归一化处理(上面的结果被阶数除)得到上面的特征向量(结果发现品德的影响最大)
AW = 特征向量原矩阵(一开始的),然后拿到每一行的和—— [2.42456102 1.34394248 0.27386595 0.50012206 0.55461416]
所以可得 (AW/阶数特征向量) 5.07293180152562
计算得到 ,查得RI=1.12
,查得RI=1.12
这说明A 不是一致阵,但A 具有满意的一致性,A 的不一致程度是可接受的。
3.3 AHP总排序
总排序本质上是对最底层重复AHP单排序过程,此处不再赘述,仅给出子因素总权重计算公式以及一致性检验统计量公式。
若中间层 包含
包含 个因素主因素
个因素主因素 ,其层次总排序权值分别为
,其层次总排序权值分别为 ,最底层
,最底层 包含
包含 个子因素
个子因素 ,它们对于因素
,它们对于因素 的层次单排序权值分别为
的层次单排序权值分别为 。当
。当 与无联系时,
与无联系时, 。则最底层的子因素总权重公式为
。则最底层的子因素总权重公式为
用 与
与 分别表示对主因素对应的子因素
分别表示对主因素对应的子因素 进行单排序所计算的与值,则一致性检验公式为:
进行单排序所计算的与值,则一致性检验公式为:
4. 计算组合权重和组合一致性检验
(1)组合权重向量
现在来完整地解决例2的问题,要从三个候选人y 1 , y 2 , y 3中选一个总体上最适合上述五个条件的候选人。对此,对三个候选人y = y 1 , y 2 , y 3分别比较他们的品德( x 1 ),才能( x 2 ),资历( x 3 ),年龄( x 4 ),群众关系( x 5 )。
先成对比较三个候选人的品德,得成对比较阵:
经计算, 的权向量
的权向量

故B 1的不一致程度可接受。ω x 1 ( Y )可以直观地视为各候选人在品德方面的得分。
类似地,分别比较三个候选人的才能,资历,年龄,群众关系得成对比较阵



(2)组合一致性指标
可得 5个特征向量

然后在通过
第一个人:(0.08199023_0.47439499 (一开始的那个特征向量)+0.59488796_0.26228108 +0.42857143_0.0544921 +0.63274854_0.09853357 +0.34595035*0.11029827 ) = 总得分
后两个人类似
最后得
- 第一个人得 0.31878206
- 第二个人得 0.23919592
- 第三个人得 0.44202202
所以3号是第一候选人
四、案例说明
实例:人们在日常生活中经常会碰到多目标决策问题,例如假期某人想要出去旅游,现有三个目的地(方案):风光绮丽的杭州( )、迷人的北戴河(
)、迷人的北戴河( )和山水甲天下的桂林(
)和山水甲天下的桂林( )。假如选择的标准和依据(行动方案准则)有5个:景色、费用、饮食、居住和旅途。
)。假如选择的标准和依据(行动方案准则)有5个:景色、费用、饮食、居住和旅途。
1. 建立层次结构模型

2. 构造判断矩阵

构造所有相对于不同准则的方案层判断矩阵:
(1)相对于景色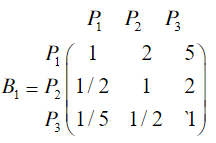
(2)相对于费用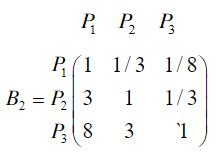
(3)相对于居住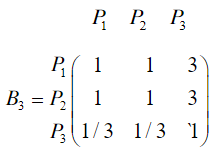
(4)相对于饮食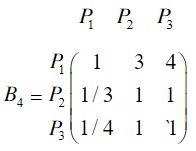
(5)相对于旅途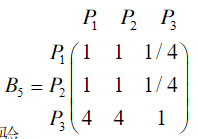
3. 层次单排序及一致性检验
求得判断矩阵A的最大特征根与特征向量:


4. 一致性检验
对于判断矩阵A进行一致性检验:
查表知平均随机一致性指标RI,从而可检验矩阵一致性:
同理,对于第二层的景色、费用、居住、饮食、旅途五个判断矩阵的一致性检验均通过。
利用层次结构图绘出从目标层到方案层的计算结果:
5. 层次总排序
五、优点与缺点
人们在进行社会的、经济的以及科学管理领域问题的系统分析中,面临的常常是一个由相互关联、相互制约的众多因素构成的复杂而往往缺少定量数据的系统。层次分析法为这类问题的决策和排序提供了一种新的、简洁而实用的建模方法。
在应用层次分析法研究问题时,遇到的主要困难有两个:
- 如何根据实际情况抽象出较为贴切的层次结构;
- 如何将某些定性的量作比较接近实际定量化处理。层次分析法对人们的思维过程进行了加工整理,提出了一套系统分析问题的方法,为科学管理和决策提供了较有说服力的依据。
但层次分析法也有其局限性,主要表现在:
- 它很大程度上依赖于人们的经验,主观因素的影响很大,它至多只能排除思维过程中的严重非一致性,却无法排除决策者个人可能存在的严重片面性。
- 当指标量过多时,对于数据的统计量过大,此时的权重难以确定。AHP至多只能算是一种半定量(或定性与定量结合)的方法。

算法流程
那么整套算法实际上是用了两次重要性权重。
准则层,从准则的重要性矩阵(nxn矩阵)中,抽取重要性权重。它的现实意义是 每个准则的重要程度。
也就是说,输入的是nxn一个矩阵,值是每个准则两两之间重要度,输出的是这n个准则各自的权重。
方案层,对每个准则,m个方案都有个mxm矩阵(总共是n个mxm矩阵)。也就是说,对每个准则,都可以算出m个方案的重要性权重。
然后n个重要性权重组合起来,与准则层的重要性权重相乘。就得到了每个方案的重要性权重。
代码
import numpy as npimport pandas as pdimport warningsclass AHP:def __init__(self, criteria, b):self.RI = (0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49)self.criteria = criteriaself.b = bself.num_criteria = criteria.shape[0]self.num_project = b[0].shape[0]def cal_weights(self, input_matrix):input_matrix = np.array(input_matrix)n, n1 = input_matrix.shapeassert n == n1, '不是一个方阵'for i in range(n):for j in range(n):if np.abs(input_matrix[i, j] * input_matrix[j, i] - 1) > 1e-7:raise ValueError('不是反互对称矩阵')eigenvalues, eigenvectors = np.linalg.eig(input_matrix)max_idx = np.argmax(eigenvalues)max_eigen = eigenvalues[max_idx].realeigen = eigenvectors[:, max_idx].realeigen = eigen / eigen.sum()if n > 9:CR = Nonewarnings.warn('无法判断一致性')else:CI = (max_eigen - n) / (n - 1)CR = CI / self.RI[n]return max_eigen, CR, eigendef run(self):max_eigen, CR, criteria_eigen = self.cal_weights(self.criteria)print('准则层:最大特征值{:<5f},CR={:<5f},检验{}通过'.format(max_eigen, CR, '' if CR < 0.1 else '不'))print('准则层权重={}\n'.format(criteria_eigen))max_eigen_list, CR_list, eigen_list = [], [], []for i in self.b:max_eigen, CR, eigen = self.cal_weights(i)max_eigen_list.append(max_eigen)CR_list.append(CR)eigen_list.append(eigen)pd_print = pd.DataFrame(eigen_list,index=['准则' + str(i) for i in range(self.num_criteria)],columns=['方案' + str(i) for i in range(self.num_project)],)pd_print.loc[:, '最大特征值'] = max_eigen_listpd_print.loc[:, 'CR'] = CR_listpd_print.loc[:, '一致性检验'] = pd_print.loc[:, 'CR'] < 0.1print('方案层')print(pd_print)# 目标层obj = np.dot(criteria_eigen.reshape(1, -1), np.array(eigen_list))print('\n目标层', obj)print('最优选择是方案{}'.format(np.argmax(obj)))return objif __name__ == '__main__':# 准则重要性矩阵criteria = np.array([[1, 2, 7, 5, 5],[1 / 2, 1, 4, 3, 3],[1 / 7, 1 / 4, 1, 1 / 2, 1 / 3],[1 / 5, 1 / 3, 2, 1, 1],[1 / 5, 1 / 3, 3, 1, 1]])# 对每个准则,方案优劣排序b1 = np.array([[1, 1 / 3, 1 / 8], [3, 1, 1 / 3], [8, 3, 1]])b2 = np.array([[1, 2, 5], [1 / 2, 1, 2], [1 / 5, 1 / 2, 1]])b3 = np.array([[1, 1, 3], [1, 1, 3], [1 / 3, 1 / 3, 1]])b4 = np.array([[1, 3, 4], [1 / 3, 1, 1], [1 / 4, 1, 1]])b5 = np.array([[1, 4, 1 / 2], [1 / 4, 1, 1 / 4], [2, 4, 1]])b = [b1, b2, b3, b4, b5]a = AHP(criteria, b).run()
输出:
准则层:最大特征值5.072084,CR=0.014533,检验通过准则层权重=[0.47583538 0.26360349 0.0538146 0.09806829 0.10867824]方案层方案0 方案1 方案2 最大特征值 CR 一致性检验准则0 0.081935 0.236341 0.681725 3.001542 8.564584e-04 True准则1 0.595379 0.276350 0.128271 3.005535 3.075062e-03 True准则2 0.428571 0.428571 0.142857 3.000000 -4.934325e-16 True准则3 0.633708 0.191921 0.174371 3.009203 5.112618e-03 True准则4 0.344545 0.108525 0.546931 3.053622 2.978976e-02 True目标层 [[0.318586 0.23898522 0.44242878]]最优选择是方案2

若有收获,就点个赞吧
0 人点赞
