
本系列将围绕NLP中的文本相似度这一主题,从最基本的字面距离度量相似度、基于统计方法,最后介绍文本语义匹配相似度相关算法,并且根据平时自己在项目中或者学习中的一些实战经验,结合代码进行分析和讲解。

在自然语言处理中,会经常涉及到要计算两个文本(字、词、句子、段落、篇章)之间的相似性。比如:
- 信息检索系统:通过文本相似度计算与输入关键词相似的words,提高检索的召回率;
- 问答系统:需要计算每个query与候选集的相似度;
- 机器翻译:通常分析语句的相似度来完成双语的翻译,而能否准确定义并计算相似度影响翻译的效果;
- 推荐系统:计算文本与推荐候选集的相似度。
- …
文本相似度可以分为:
- 基于统计的方法,主要是无监督学习,一般用于句子、段落……较大粒度的文本;
- 基于语义的方法,大部分是基于深度学习的有监督学习,一般用于词语或句子……较小粒度的文本。
文本相似度定义
文本相似度可以理解为,通过采取一定的方法,计算两个不同文本之间的相似程度,通常最终的计算结果用百分数值来衡量文本之间的相似程度。中文相似度按照文本长度分类:字与字、词与词、句与句、段与段、章与章。
与之相对应的,还有一个概念——文本距离——指的是两个文本之间的距离。文本距离和文本相似度是负相关的——距离小,“离得近”,相似度高;距离大,“离得远”,相似度低。业务上不会对这两个概念进行严格区分,有时用文本距离,有时则会用文本相似度。
**
相似度度量方法
说到文本相似度的度量方法,就会想到几个度量文本间距离的方法,接下来先介绍几个比较重要,也是很基础的文本距离概念,因为这些距离都是现有很多NLP算法在底层应用的比较多的方法,也是比较文本相似度的基础知识。
(1)编辑距离(Levenshtein 距离、莱文斯坦距离)
维基百科定义:莱文斯坦(Levenshtein)距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。而编辑操作可以是将一个字符替换、修改成另一个字符,或者在一个字符串中插入一个字符,亦或删除字符串中的某一个字符。
举个例子:比如现在有两个字符串“kitten”和“sitting”,从“kitten”到“sitting”需要经过以下3个步骤,所以它们的编辑距离是3:
kitten -> sitten
sitten -> sittin
sittin -> sitting
值得注意的是编辑距离的计算与文本的顺序是有关系的,比如中文字符“恋爱”和“爱恋”它们的编辑距离不是0,而是2。
爱恋 -> 恋恋
恋恋 -> 恋爱
应用:编辑距离有着广泛的应用,例如,拼写检查、光学字符的校正系统、基于翻译记忆库的自然语言翻译的辅助软件。在中文字符串近似匹配的应用中,如果两个文本的编辑距离足够小,说明两个文本的相似度高。但是编辑距离计算相似度,虽然准确度高,但是召回率很低,比如中文字符“度假自由行”和“自由行度假”,中文意思完全一样,但是编辑距离是5,表示相似度很低。
顾名思义,编辑距离指的是将文本 A 编辑成文本 B 需要的最少变动次数(每次只能增加、删除或修改一个字)。
例 :计算 “椰子” 和“椰子树”之间的编辑距离。
因为将 “椰子” 转化成 “椰子树”,至少需要且只需要 1 次改动(反过来,将“椰子树” 转化成“椰子”,也至少需要 1 次改动,如下图),所以它们的编辑距离是 1。
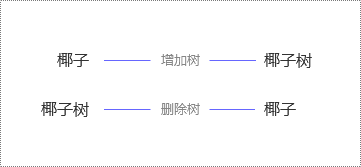
因此,编辑距离是对称的,即将 A 转化成 B 的最小变动次数和将 B 转化成 A 的最小变动次数是相等的。
同时,编辑距离与文本的顺序有关。
比如,“椰子”和 “子椰”,虽然都是由“椰”“子” 组成,但因为顺序变了,编辑距离是 2(如下图),而不是 0。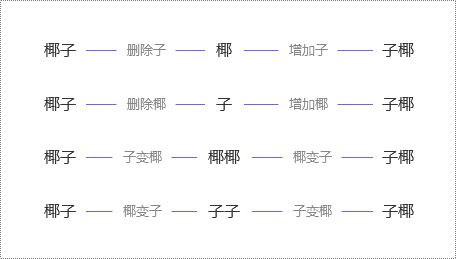
适用场景:
编辑距离算出来很小,文本相似度肯定很高。如果用算法语言来说的话,就是准确率很高(即虽然会漏掉一些好的 case,但可以确保选出来的 case 一定非常好)。
不适用场景:
反过来说,虽然准确率很高,但召回率不高。在某些业务场景中,漏掉的 case 会引起严重后果,比如 “批发零售” 和“零售批发”,人的理解应该非常相似,可编辑距离却是 4,相当于完全不匹配,这显然不符合预期。
(2)欧氏距离(Euclidean Distance)
定义:欧式距离是很容易理解的距离度量方法,在二维空间中,套用小学课本里的知识就是“两点之间直线最短”,而空间中两点之间的直线距离就是我们所说的欧氏距离。
假设二维空间中有两个对象X、Y,都包括N维特征,X=(x1,x2,x3,..,xn),Y=(y1,y2,y3,..,yn),计算X和Y的欧式距离,常用的方法如下:
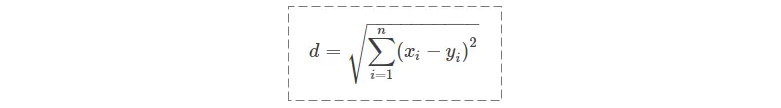
因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高和体重两个单位不同的指标使用欧式距离结果就会无效,远离事实真相。
例:计算 “产品经理” 和“产业经理是什么”之间的欧氏距离
过程如下:
- 文本向量 A=(产,品,经,理),即 x1 = 产,x2 = 品,x3 = 经,x4 = 理,x5、x6、x7 均为空;
- 文本向量 B=(产,业,经,理,是,什,么),即 y1 = 产,y2 = 业,y3 = 经,y4 = 理,y5 = 是,y6 = 什,y7 = 么。
这里规定,若 xi=yi,则 xi-yi=0;若 xi≠yi,|xi-yi|=1。
所以,欧氏距离d是 2
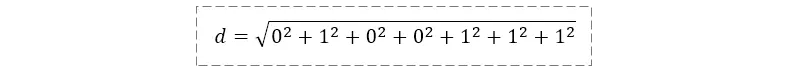
适用场景:
编码检测等类似领域。两串编码必须完全一致,才能通过检测,这时一个移位或者一个错字,可能会造成非常严重的后果。比如下图第一个二维码是 “这是一篇文本相似度的文章”,第二个是 “这是一篇文本相似度文章”。从人的理解来看,这两句话相似度非常高,但是生成的二维码却千差万别。
不适用场景:
文本相似度,意味着要能区分相似 / 差异的程度,而欧氏距离更多的只能区分出是否完全一样。而且,欧氏距离对位置、顺序非常敏感,比如 “我的名字是孙行者” 和“孙行者是我的名字”,在人看来,相似度非常高,但是用欧氏距离计算,两个文本向量每个位置的值都不同,即完全不匹配。
(3)曼哈顿距离(Manhattan Distance)
定义:曼哈顿距离也称出租车几何,是由十九世纪的赫尔曼·闵可夫斯基所创词汇,是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。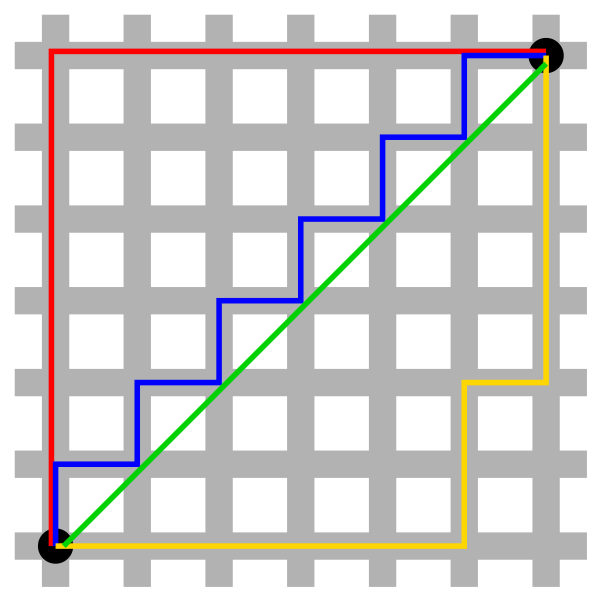
上图是摘自维基百科的一张图,其中红蓝黄皆为曼哈顿距离,绿色为欧式距离。
和欧氏距离非常相似(把平方换成了绝对值,拿掉了根号),公式如下:
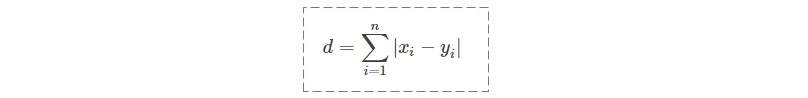
适用场景同欧氏距离。
(4)余弦距离(Cosine distance)
定义:余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
下图所示的就是余弦计算公式,使用这个公式我们可以很方便的计算余弦距离。
或者余弦相似度公式为:
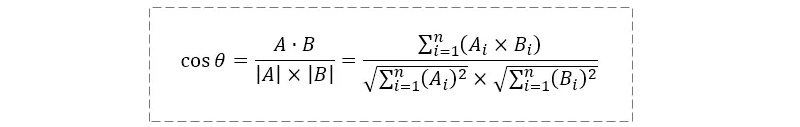
其中,A、B 分别是文本一、文本二对应的 n 维向量。
例:文本一是 “一个雨伞”,文本二是 “下雨了开雨伞”,计算它们的余弦相似度。
它们的并集是 {一,个,雨,伞,下,了,开},共 7 个字。
- 若并集中的第 1 个字符在文本一中出现了 n 次,则 A1=n(n=0,1,2……)。
- 若并集中的第 2 个字符在文本一中出现了 n 次,则 A2=n(n=0,1,2……)。
依此类推,算出 A3、A4、……、A7,B1、B2、……、B7,最终得到:
- A=(1,1,1,1,0,0,0)。
- B=(0,0,2,1,1,1,1)。
将 A、B 代入计算公式,得到
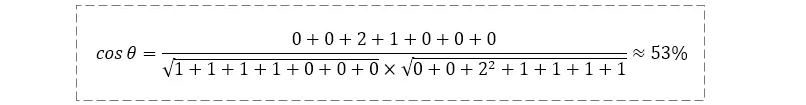
S1: "为什么我的眼里常含泪水,因为我对这片土地爱得深沉"S2: "我深沉的爱着这片土地,所以我的眼里常含泪水"
第一步,分词:
我们对上述两段话分词分词并得到下面的词向量:
S1: [为什么 我 的 眼里 常含 泪水 因为 我 对 这片 土地 爱得 深沉 ,]
S2: [我 深沉 的 爱 着 这片 土地 所以 我 的 眼里 常含 泪水 ,]
第二步,统计所有词组:
将S1和S2中出现的所有不同词组融合起来,并得到一个词向量超集,如下:
[眼里 这片 为什么 我 的 常含 因为 对 所以 爱得 深沉 爱 着 , 泪水 土地]
第三步,获取词频:
对应上述的超级词向量,我们分别就S1的分词和S2的分词计算其出现频次,并记录:
S1: [1 1 1 2 1 1 1 1 0 1 1 0 0 1 1 1]
S2: [1 1 0 2 2 1 0 0 1 0 1 1 1 1 1 1]
第四步,复杂度计算:
通过上述的准备工作,现在我们可以想象在空间中存在着两条线段:SA和SB,二者均从原点([0, 0, …])出发,指向不同的方向,并分别终结于点A [1 1 1 2 1 1 1 1 0 1 1 0 0 1 1 1]和点B[1 1 0 2 2 1 0 0 1 0 1 1 1 1 1 1],其中点A和点B的坐标与我们上述的词频一致。到了这一步,我们可以发现,对于句子S1和S2的相似度问题,已经被我们抽象到如何计算上述两个向量的相似问题了。
通过上文介绍的余弦定理,我们知道当两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,我们就认定这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
**
对于上述两句话,在经过余弦计算后,得到的相似度为0.766(其夹角大概是40度),还是比较接近于1,所以,上面的句子S1和句子S2是基本相似的。由此,我们就得到了文本相似度计算的处理流程是:
- 找出两篇文章的关键词;
- 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频;
- 生成两篇文章各自的词频向量;
- 计算两个向量的余弦相似度,值越接近于1就表示越相似;**
适用场景:**
余弦相似度和杰卡德相似度虽然计算方式差异较大,但性质上很类似(与文本的交集高度相关),所以适用场景也非常类似。
余弦相似度相比杰卡德相似度最大的不同在于它考虑到了文本的频次,比如上面例子出现了 2 次 “雨”,和只出现 1 次“雨”,相似度是不同的;再比如“这是是是是是是一个文本” 和“这是一个文文文文文文本”,余弦相似度是 39%,整体上符合 “相同的内容少于一半,但超过 1/3” 的观感(仅从文本来看,不考虑语义)。
不适用场景:
向量之间方向相同,但大小不同的情况(这种情况下余弦相似度是 100%)。
比如 “太棒了” 和“太棒了太棒了太棒了”,向量分别是(1,1,1)和(3,3,3),计算出的相似度是 100%。
这时候要根据业务场景进行取舍,有些场景下我们认为它们意思差不多,只是语气程度不一样,这时候余弦相似度是很给力的;有些场景下我们认为它们差异很大,哪怕意思差不多,但从文本的角度来看相似度并不高(最直白的,一个 3 个字,一个 9 个字),这时候余弦相似度就爱莫能助了。
(5)汉明距离(Hamming distance)
定义:汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,我们以d(x,y)表示两个字x,y之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,就是汉明距离。
汉明距离有一个最为鲜明的特点就是它比较的两个字符串必须等长,否则距离不成立。它的核心原理就是如何通过字符替换,将一个字符串替换成另外一个字符串。
维基百科给定了几个样例:
“karol_in” 和 “kathrin” 的汉明距离为 3.
(下标 2 3 4 替换)
“karo**lin” 和 “kers__tin” 的汉明距离为 3.
(下标 1 3 4 替换)
1011101 和 1001001 的汉明距离为 2.
(下标 2 4 替换)
2173896 和 22337**_96 的汉明距离为 3.
(下标 1 2 4 替换)
Hamming distance在信息论中,表示为两个「等长」字符串之间对应位置的不同字符的个数。换句话说,汉明距离就是将一个字符串变换成另外一个字符串所需要「替换」的字符个数。如下图所示:
- 0110与1110之间的汉明距离是1;
- 0100与1001之间的汉明距离是3;
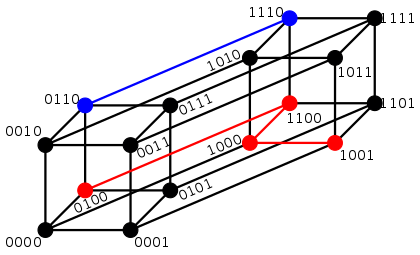
汉明距离图示
总结:
欧氏距离、曼哈顿距离和余弦距离适用于基于词向量的相似度计算,汉明距离适用于基于字符的文本相似度计算。
分词
在了解了上述一系列的距离含义之后,我们已经基本了解了衡量相似度的一个判定方法,但是对于一段文本内容来说,我们对什么来计算距离呢?这就涉及到了第二个基础知识:分词。
分词方法
为了实现对文本相似度的比较,我们需要分析文本的内容,也就必然会涉及到对文本进行分词处理。而说到分词,其中涉及的内容不比任何一个其他知识点要少,考虑到不是本文重点讲述,此处仅仅简单的列举了下当前分词算法的几种方向,有兴趣的同学可以就此列表再去细细琢磨
- 基于词表的分词方法
- 正向最大匹配法(forward maximum matching method, FMM)
- 逆向最大匹配法(backward maximum matching method, BMM)
- N-最短路径方法
- 基于统计模型的分词方法
- 基于N-gram语言模型的分词方法
基于序列标注的分词方法
- ansj分词器
- 中科院计算所NLPIR
- 哈工大的LTP
- 清华大学THULAC
- 斯坦福分词器 (Github)
- Hanlp分词器
- KCWS分词器
文本相似度
上一章介绍了五种比较常见的文本距离,接下来就开始引入我们的主题——文本相似度的算法了。总的来说,计算文本相似度的算法共分为4类:
- 基于词向量:余弦相似度、曼哈顿距离、欧氏距离
- 基于具体字符:编辑距离、汉明距离、simhash、N-gram 相似度
- 基于概率统计:Jaccard 相似度
- 基于词嵌入模型:word2vec、doc2vec、WMD、SWMD
N-gram 相似度(N-gram 距离)
N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念。假设有一个字符串 ,那么该字符串的N-Gram就表示按长度 N 切分原词得到的词段,也就是该字符串中所有长度为 N 的子字符串。
设想如果有两个字符串,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量去定义两个字符串间的N-Gram距离。
但是仅仅是简单地对共有子串进行计数显然也存在不足,这种方案显然忽略了两个字符串长度差异可能导致的问题。比如字符串 girl 和 girlfriend,二者所拥有的公共子串数量显然与 girl 和其自身所拥有的公共子串数量相等,但是我们并不能据此认为 girl 和girlfriend 是两个等同的匹配。
所以为了解决该问题,便有人提出了以非重复的N-Gram分词为基础来定义 N-Gram距离,可以用下面的公式来表述: 
其中,GN(S) 和GN(T)分别表示字符串S和T中N-Gram的集合,N一般取2或3。
当N=2时:
公式:s字符串2分词后长度 + t字符串2分词后长度 - 公共长度
两个字符串中,相同的n-gram越多时,两个字串就会被认为更加相似;当两个字符串完全相等时,距离为0 。
举个例子:以 N = 2 为例对字符串Gorbachev和Gorbechyov进行分段,可得如下结果(我们用下画线标出了其中的公共子串)。
Go**,or,rb,ba,ac,ch,he,ev
Go,or,rb,be,ec,ch**,hy,yo,ov
结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9
Jaccard 相似度
Jaccard相似度就是计算两个句子之间词集合的交集和并集的比值。比值越大,表示两个句子越相似,在涉及大规模并行运算的时候,该方法在效率上有一定的优势,公式如下: 
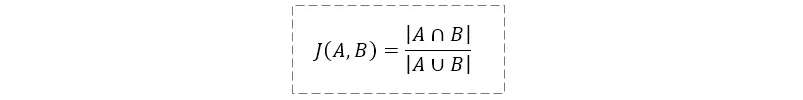
如果要计算 Jaccard 距离,公式稍作变更即可:
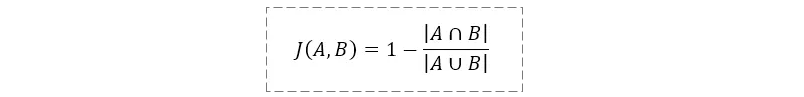
例:计算 “荒野求生” 和“绝地求生”的杰卡德相似度。
因为它们交集是 {求,生},并集是 {荒,野,求,生,绝,地},所以它们的杰卡德相似度 = 2/6=1/3。
杰卡德相似度与文本的位置、顺序均无关。比如 “王者荣耀” 和“荣耀王者”的相似度是 100%。无论 “王者荣耀” 这 4 个字怎么排列,最终相似度都是 100%。
在某些情况下,会先将文本分词,再以词为单位计算相似度。比如将 “王者荣耀” 切分成 “王者 / 荣耀”,将“荣耀王者” 切分成“荣耀 / 王者”,那么交集就是{王者,荣耀},并集也是{王者,荣耀},相似度恰好仍是 100%。
适用场景:
对字 / 词的顺序不敏感的文本,比如前述的 “零售批发” 和“批发零售”,可以很好地兼容。
长文本,比如一篇论文,甚至一本书。如果两篇论文相似度较高,说明交集比较大,很多用词是重复的,存在抄袭嫌疑。
不适用场景:
重复字符较多的文本,比如 “这是是是是是是一个文本” 和“这是一个文文文文文文本”,这两个文本有很多字不一样,直观感受相似度不会太高,但计算出来的相似度却是 100%(交集 = 并集)。
对文字顺序很敏感的场景,比如 “一九三八年” 和“一八三九年”,杰卡德相似度是 100%,意思却完全不同。
#-*-coding:utf-8 -*-
# 计算jaccard系数
def jaccard(p,q):
c = [a for i in p if v in b]
return float(len(c))/(len(a)+len(b)-len(b))
p = ['shirt','shoes','pants','socks']
q = ['shirt','shoes']
print (jaccard(p,q))
print (jaccard(p,q))
输出的结果为0.5
Jaro 相似度
Jaro 相似度据说是用来判定健康记录上两个名字是否相同,公式如下:
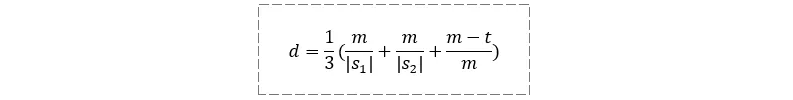
其中,m 是两个字符串中相互匹配的字符数量; 和
和  表示两个字符串的长度(字符数量);t 是换位数量。
表示两个字符串的长度(字符数量);t 是换位数量。
这里着重说一下 “匹配” 和 “换位” 的概念,先列一个公式,我称之为 “匹配阈值”:

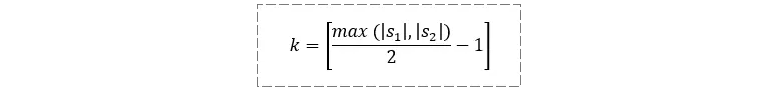
当 s1 中某字符与 s2 中某字符相同,且它们的位置相距小于等于 k 时,就说它们是匹配的。
比如 “我明白了” 和“快一点告诉我”,按公式算出 k=2。虽然两个字符串中都有 “我” 字,但一个在第 1 位,另一个在第 6 位,相距为 5,大于 k 值,所以这两个字符串没有任何一个字符是匹配的。
再比如 “我明白了” 和“明白了我”,k=1,所以这两个字符串的 “明”“白”“了” 是匹配的,但是 “我” 是不匹配的,所以它们有 3 个字符是匹配的。
换位的意思,是将 s1 和 s2 匹配的字符依次抽出来,看它们顺序不一样的字符有多少个,这个数就是换位数量。
例:计算 “我表白了一个女孩” 和“近几天我白表了一次情”的 Jaro 相似度。
|s1|=8,|s2|=10,k=4,匹配的字符有 5 个,即 m=5,分别是 “我”“表”“白”“了”“一”。
将 s1 中的匹配字符依次抽出来,得到一个向量 r1=(我,表,白,了,一)。
将 s2 中的匹配字符依次抽出来,得到一个向量 r2=(我,白,表,了,一)。
比对 r1 和 r2,发现有 2 个位置的值不一样(第 2 位和第 3 位),所以换位数 t=2。
于是,d=1/3[5/8+5/10+(5-2)/5]=57.5%。
适用场景:
对位置、顺序敏感的文本。文本位置的偏移,很容易使匹配字符数 m 变少;文本顺序的变换,会使换位数量 t 增大。它们都会使 Jaro 相似度减小。换句话说,如果某业务场景下需要考虑文本位置偏移、顺序变换的影响,既不希望位置或顺序变了相似度却保持不变,又不希望直接一刀切将相似度变为 0,那 Jaro 距离是十分合适的。
不适用场景:
未知
整体来说,Jaro 距离是比较综合的文本相似度算法,从换位字符数来看,有点像编辑距离;从匹配字符的抽取来看,又有点像 “交集”。
最后,对例做个横向对比:“我表白了一个女孩” 和“近几天我白表了一次情”。
- 编辑距离算出来是 8,s1 长度是 8,s2 长度是 10,编辑距离等于 8,从数据上看非常不相似,与人的感官差异很大。
- 杰卡德相似度算出来是 38.5%,数值比较低,和人的感官差异较大。
- 余弦相似度算出来是 55.9%,和 Jaro 距离算出来差不多,都是 50%+,比较符合人的感官——超过一半的内容是相同的,同时有将近一半内容是不同的。
- 如果在此例中,调整字符顺序,让换位数量 t 变大,匹配数量 m 变小,余弦相似度不变,Jaro 相似度会降低。
Simhash 相似度
基于余弦复杂度,通过两两比较文本向量来得到两个文本的相似程度是一个非常简单的算法。然而两两比较也就说明了时间复杂度是O(n2),那么在面对互联网海量信息时,考虑到一个文章的特征向量词可能特别多导致整个向量维度很高,使得计算的代价太大,就有些力不从心了。因此,为了在爬取网页时用于快速去重,Google发明了一种快速衡量两个文本集相似度的算法:simhash。
简单来说,simhash中使用了一种局部敏感型的hash算法。所谓局部敏感性hash,与传统hash算法不同的是(如MD5,当原始文本越是相似,其hash数值差异越大),simhash中的hash对于越是相似的内容产生的签名越相近。
原理
simhash的主要思想是降维,将文本分词结果从一个高维向量映射成一个0和1组成的bit指纹(fingerprint),然后通过比较这个二进制数字串的差异进而来表示原始文本内容的差异。下面我们通过图文方式来解释下这个降维和差异计算的过程。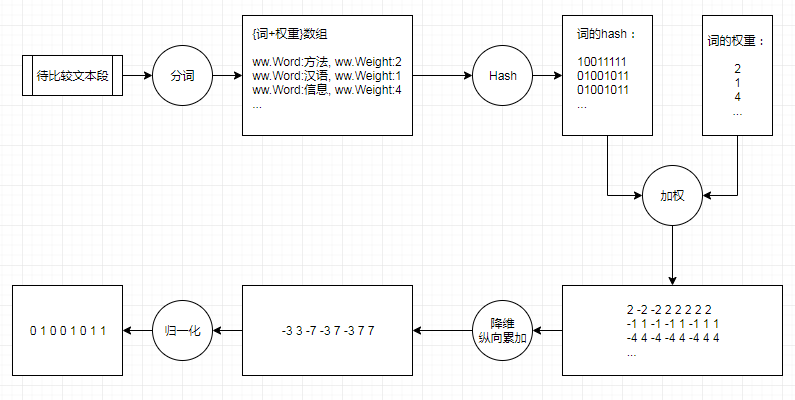
simhash算法流程实例
在simhash中处理一个文本的步骤如下:
第一步,分词:
对文本进行分词操作,同时需要我们同时返回当前词组在文本内容中的权重(这基本上是目前所有分词工具都支持的功能)。
第二步,计算hash:
对于每一个得到的词组做hash,将词语表示为到01表示的bit位,需要保证每个hash结果的位数相同,如图中所示,使用的是8bit。
第三步,加权
根据每个词组对应的权重,对hash值做加权计算(bit为1则取为1做乘积,bit为0则取为-1做乘积),如上图中,
- 10011111与权重2加权得到[2 -2 -2 2 2 2 2 2];
- 01001011与权重1加权得到[-1 1 -1 -1 1 -1 1 1];
- 01001011与权重4加权后得到[-4 4 -4 -4 4 -4 4 4];
第三步,纵向相加:
将上述得到的加权向量结果,进行纵向相加实现降维,如上述所示,得到[-3 3 -7 -3 7 -3 7 7]。
第四步,归一化:
将最终降维向量,对于每一位大于0则取为1,否则取为0,这样就能得到最终的simhash的指纹签名[0 1 0 0 1 0 1 1]
第五步,相似度比较:
通过上面的步骤,我们可以利用SimHash算法为每一个网页生成一个向量指纹,在simhash中,判断2篇文本的相似性使用的是海明距离。什么是汉明距离?前文已经介绍过了。在在经验数据上,我们多认为两个文本的汉明距离<=3的话则认定是相似的。
实现
结果
我们使用了调换一段长本文的语序来测试simhash的效果:
文本1:
"沉默螺旋模式中呈现出民意动力的来源在于人类有害怕孤立的弱点,但光害怕孤立不至于影响民意的形成," +
"主要是当个人觉察到自己对某论题的意见与环境中的强势意见一致(或不一致时),害怕孤立这个变项才会产生作用。 " +
"从心理学的范畴来看,社会中的强势意见越来越强,甚至比实际情形还强,弱势意见越来越弱,甚至比实际情形还弱,这种动力运作的过程成–螺旋状"
文本2:
"从心理学的范畴来看,害怕孤立这个变项才会产生作用。社会中的强势意见越来越强,甚至比实际情形还强,弱势意见越来越弱," +
"主要是当个人觉察到自己对某论题的意见与环境中的强势意见一致(或不一致时),甚至比实际情形还弱,这种动力运作的过程成–螺旋状 " +
"但光害怕孤立不至于影响民意的形成,沉默螺旋模式中呈现出民意动力的来源在于人类有害怕孤立的弱点"
通过计算,结果得到二者的指纹是一模一样,其汉明距离为0.
srcFingerPrint: [1 0 0 0 0 0 1 0 1 0 1 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0]
dstFingerPrint: [1 0 0 0 0 0 1 0 1 0 1 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0]
--- PASS: TestSimHashSimilar (0.85s)
similarity_test.go:57: SimHashSimilar distance: 0
PASS
适用性
注意一:
我们再来看一个文章主旨类似,但是内容相关性较低的文本比较示例:
文本1:
"关于区块链和数字货币的关系,很多人或多或少都存在疑惑。简单来说,区块链是比特币的底层运用,而比特币只是区块链的一个小应用而已。" +
"数字货币即虚拟货币,最早的数字货币诞生于2009年,其发明者中本聪为了应对经济危机对于实体货币经济的冲击。比特币是最早的数字货币,后来出现了以太币、火币以及莱特币等虚拟货币,这些虚拟货币是不能用来交易的。" +
"狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构, 并以密码学方式保证的不可篡改和不可伪造的分布式账本。" +
"广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算方式。"
文本2:
"区块链技术为我们的信息防伪与数据追踪提供了革新手段。区块链中的数据区块顺序相连构成了一个不可篡改的数据链条,时间戳为所有的交易行为贴上了一套不讲课伪造的真是标签,这对于人们在现实生活中打击假冒伪劣产品大有裨益; " +
"市场分析指出,整体而言,区块链技术目前在十大金融领域显示出应用前景,分别是资产证券化、保险、供应链金融、场外市场、资产托管、大宗商品交易、风险信息共享机制、贸易融资、银团贷款、股权交易交割。" +
"这些金融场景有三大共性:参与节点多、验真成本高、交易流程长,而区块链的分布式记账、不可篡改、内置合约等特性可以为这些金融业务中的痛点提供解决方案。" +
"传统的工业互联网模式是由一个中心化的机构收集和管理所有的数据信息,容易产生因设备生命周期和安全等方面的缺陷引起的数据丢失、篡改等问题。区块链技术可以在无需任何信任单个节点的同时构建整个网络的信任共识,从而很好的解决目前工业互联网技术领域的一些缺陷,让物与物之间能够实现更好的连接。"
通过计算,当我们选择前top10高频词作为衡量时,结果得到二者的指纹是如下,其汉明距离为4:
srcFingerPrint: [1 0 1 1 0 1 0 0 0 1 1 1 1 1 1 0 1 0 0 1 0 1 1 1 0 0 0 1 0 0 0 1]
dstFingerPrint: [1 0 1 1 0 1 0 0 0 1 1 1 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 1 0 1 0 1]
--- PASS: TestSimHashSimilar (0.84s)
similarity_test.go:58: SimHashSimilar distance: 4
PASS
当我们选择前top50高频词作为衡量时,结果得到二者的指纹是如下,其汉明距离为9:
srcFingerPrint: [1 0 1 1 0 1 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 1 1 0 1 0 0 0 0 1 0 1]
dstFingerPrint: [1 0 1 1 0 1 0 1 0 0 1 0 1 1 0 0 1 1 0 1 1 1 1 0 0 0 0 1 0 0 0 1]
--- PASS: TestSimHashSimilar (0.83s)
similarity_test.go:58: SimHashSimilar distance: 9
PASS
所以我们发现了一个对结果判定很重要的参数:分词数量。在上面的示例中,当我们选择10个分词时,其汉明距离仅为4,几乎符合了我们对文本相似(汉明距离3)的判断。而随着topN数量的增加,引入了更多的词组,其汉明距离越来越大,这也说明了
,当大文本内容出现时,选择合适的topN分词数量进行比较对结果的影响是十分大的。
注意二:
另外一点需要需要注意的是,simhash的优点是适用于高维度的海量数据处理,当维度降低,如短文本的相似度比较,simhash并不合适,以我们计算余弦相似度的文本为例,
S1: "为什么我的眼里常含泪水,因为我对这片土地爱得深沉"
S2: "我深沉的爱着这片土地,所以我的眼里常含泪水"
得到的结果如下:
srcFingerPrint: [1 1 1 0 1 0 0 1 1 1 0 1 0 0 0 0 1 0 1 1 1 0 1 0 1 0 1 1 0 0 1 0]
dstFingerPrint: [1 0 1 0 0 0 1 1 0 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 1 1 1 1 0 0 1 0]
--- PASS: TestSimHashSimilar (0.86s)
similarity_test.go:53: SimHashSimilar distance: 12
PASS
也就是结果的汉明距离为12,远远大于我们预定的汉明距离3,这样的结果跟我们通过预先相似度计算出来的0.76分(相比于1分)相差很远,可见simhash对于短文本的相似度比较还是存在一些偏差的。
SimHash算法是GoogleMoses Charikear于2007年发布的一篇论文《Detecting Near-duplicates for web crawling》中提出的, 专门用来解决亿万级别的网页去重任务。
SimHash是局部敏感哈希(locality sensitve hash)的一种,其实主要思想就是数据降维,将高维的特征向量映射成低维的特征向量,再通过比较两个特征向量的汉明距离来确定文章之间的相似性。SimHash算法的大致流程:
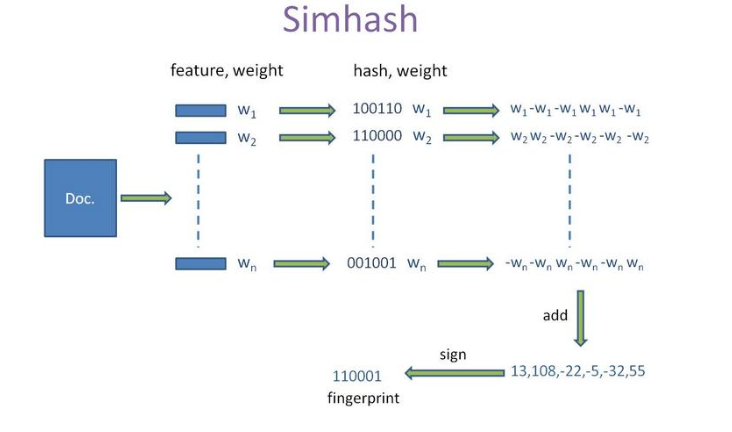
- 分词、计算权重:首先对文本进行分词,可以用TF-IDF计算每个词的权重,得到n个(feature,weight)对;
- 计算关键词hash值:对计算得到的的关键词(feature),进行哈希操作,计算hash值,这样就得到一个长度为n位的二进制,得到(hash:weight)的集合。
- 加权求和:在获取的hash值的基础上,根据对应的weight值进行加权,即W=hash*weight。hash为1则和weight正相乘,为0则和weight负相乘。例如一个词的hash值是(010111)权重是5,那么经过加权求和后得到的结果为[-5,5,-5,5,5,5]。
- 向量求和:将上述得到的各个关键词的向量进行求和,例如对[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]进行求和后得到[-7,1,-9,9,3,9],这样最终生成一个长度为64的序列,代表文档的向量。
- 生成simhash值:对于上面生成的序列,大于0为1, 其他的为0,从而得到文本的simhash值。例如,[-7,1,-9,9,3,9]得到 010111,而010111就是文本的 simhash值。
- 相似度计算:根据不同文本的simhash值计算彼此之间的汉明距离,一般汉明距离<=3代表相似度较高。
SimHash是用来进行海量的网页数据去重的算法,具有高效率。
在互联网时代,我们每天会打开各种新闻资讯app浏览新闻,时间长了就会发现同一篇文章会同时被多个网站转载,说转载还算比较好听,难听的就是抄袭。
抄袭的手段就像我们初中生写作文一样,有低级的也有高级的。通常大多数情况下,都是改动很少(去头去尾、改个标题)就发表了。
在新闻资讯推荐的时候,对于这种重叠度较高的文章,是需要避免过多的出现在用户的浏览选项中的,因为没有太多的意义。所以判重并不是等于的关系,而是相似判断,这个判别的算法就是SimHash。
BM25
BM25是什么?
Okapi BM25(BM代表最佳匹配)是搜索引擎根据其与给定搜索查询的相关性对匹配文档进行排名的排名函数。是Stephen E. Robertson和KarenSpärckJones等人在70年代和80年代开发的概率检索框架。
原文链接:
https://nlp.stanford.edu/IR-book/html/htmledition/okapi-bm25-a-non-binary-model-1.html
简单来说,BM25是一种检索算法,用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
比如说现在有一个query和若干搜索结果D,最终的结果是要计算已知query和每个搜索结果d的相关度得分。首先,需要对每个query进行解析,得到语素(单词)Q(i),然后分别计算每个Q(i)与搜索结果D之间的相似度,最后对Q(i)与D的相似度进行加权求和,将结果作为query与D之间的相关度得分。
实际应用中,一般都是先用BM25算法对语料做一下简单的rank,将结果作为模型的训练语料,等模型训练好之后再对BM25的rank结果进行重新排序(Rerank),而重新排序的结果也是要比第一次BM25排序的结果要好的多。
BM25算法的计算公式:
Q是指某个query,其包含关键词
D表示文档集,avgdl是语料库全部文档的平均长度,k k1和b是参数,原文中给出的建议是 
词语频率(Term Frequency), 简称 “TF”
是一个很简单的度量标准:一个特定的词语在文档出现的次数。可以把这个值除以该文档中词语的总数,得到一个分数。例如文档中有 100 个词, ‘the’ 这个词出现了 8 次,那么 ‘the’ 的 TF 为 8 或 8/100 或 8%
逆向文件频率 (Inverse Document Frequency),简称 “IDF”
它由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。越是稀有的词,越会产生高的 “IDF”
判断一个词与一个文档的相关性的权重,方法有多种,BM25用的是IDF值(见上文),将IDF项展开见下面的公式:
其中,N为索引中的全部文档数, 为包含了
为包含了 的文档数。根据IDF的定义可以看出,对于给定的文档集合,包含了的文档数越多,的权重则越低。也就是说,当很多文档都包含了时,的区分度就不高,因此使用来判断相关性时的重要度就较低。
的文档数。根据IDF的定义可以看出,对于给定的文档集合,包含了的文档数越多,的权重则越低。也就是说,当很多文档都包含了时,的区分度就不高,因此使用来判断相关性时的重要度就较低。
接下来看一下BM25计算公式的后半部分,其实就是关键词与文档D的相关性得分 ,一般形式如下图:
,一般形式如下图:

其中,k1,k2,b为调节因子,都是经验值,可以参考论文中的设置,一般有:
公式中fi为 在文档D中的出现频率,
在文档D中的出现频率, 为词在查询语句
为词在查询语句 中的出现频率。由于绝大多数情况下一条简短的查询语句中,词只会出现一次,即
中的出现频率。由于绝大多数情况下一条简短的查询语句中,词只会出现一次,即 ,因此公式可以简化为:
,因此公式可以简化为:
 为文档d的长度,
为文档d的长度, 为所有文档的平均长度。意即该文档
为所有文档的平均长度。意即该文档 的长度和平均长度比越大,则
的长度和平均长度比越大,则 越大,则相关度越小,
越大,则相关度越小, 为调节因子,越大,则文档长度所占的影响因素越大,反之则越小。
为调节因子,越大,则文档长度所占的影响因素越大,反之则越小。
白话举例就是:
- 一个为:诸葛亮在哪里去世的?
- document1的内容为:诸葛亮在五丈原积劳成疾,最终去世;
- document2的内容为:司马懿与诸葛亮多次在五丈原交锋;
- 而document3为一整本中国历史书的内容。
显然document3中肯定包含了大量[诸葛亮]、[哪里]、[去世]这些词语,可是由于document3文档长度太大,所以非常大,所以和中每个词的相关度非常小。

WMD
什么是WMD?
WMD是2015年提出的一种衡量文本相似度的方法,是英文Word Mover’s Distance(简称WMD,词移距离)的首字母简称,是度量两个文本文档之间距离的一种方式(方法),用于判断两个文本之间的相似度,即WMD距离越大相似度越小,WMD距离越小文本相似度越大
论文:
http://proceedings.mlr.press/v37/kusnerb15.pdf
WMD的几个优点:
效果出色:利用word2vec的领域迁移能力
无监督:不依赖标注数据,没有冷启动问题
模型简单:仅需要词向量的结果作为输入,没有任何超参数
可解释性:将问题转化成线性规划,有全局最优解
灵活性:可以人为干预词的重要性
字符串的编辑距离主要是从字符串层面来度量文本之间的相似性,而WMD则通过寻找两个文本之间所有词最小距离之和的配对来度量文本的语义相似度。
WMD是EMD(Earth Mover’s Distance)在NLP领域的延伸。EMD距离是一类运输问题:假设m个工厂需要将货物运输到n个仓库,每个工厂有一定数量的货物  ,每个仓库的最大容量为
,每个仓库的最大容量为  ,工厂与仓库间距离为
,工厂与仓库间距离为  ,在运送量为
,在运送量为  时其成本为
时其成本为  。工厂内货物总量为
。工厂内货物总量为  ,仓库总容量为
,仓库总容量为  。则运输问题的优化目标是在运输货物总量为
。则运输问题的优化目标是在运输货物总量为  情况下最小化成本。
情况下最小化成本。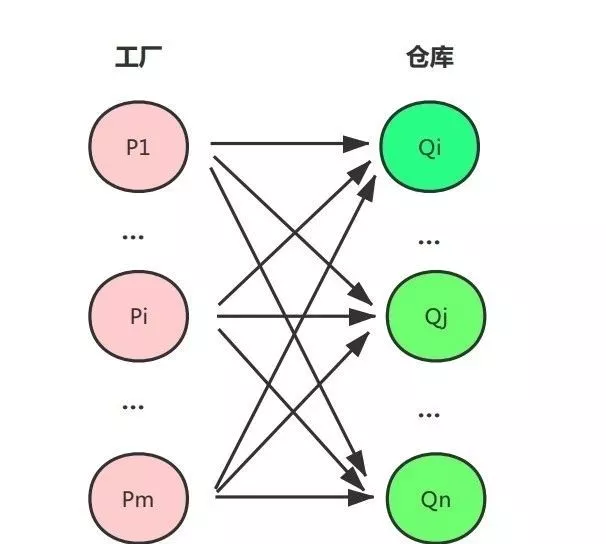
在利用WMD计算两条文本的相似度时,会进行以下步骤:
- 利用word2vec将词编码成词向量
- 去掉停用词
- 计算出每个词在文本中所占权重,一般用词频来表示
- 对于每个词,找到另一条文本中的词,确定移动多少到这个词上。如果两个词语义比较相近,可以全部移动或移动多一些。如果语义差异较大,可以少移动或者不移动。用词向量距离与移动的多少相乘就是两个词的转移代价
- 保证全局的转移代价加和是最小的
- 文本1的词需要全部移出,文本2的词需要全部移入
论文中给出的例子是,两个短文本“Obama speaks to the media in Illinois”、“The President greets the press in Chicago”,那么从第一句子转移到第二个句子的示意图如下(已去除停用词):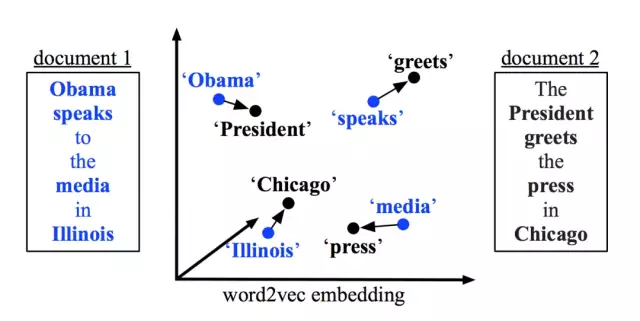
针对示意图中的词移距离则表示为:
distance(“Obama”->”President”)+distance(“speaks”->”greets”)+…
那么词到词之间的距离,即如 distance(“Obama”->”President”)该怎么计算?很明显要计算两个词之间的距离,我们需要先进行数值化(向量化),为了解决使用BOW、TF-IDF中不同词之间毫无相关性的缺点,WMD模型通过word2vec将词语向量化后,使用欧式距离公式计算两个词语之间的距离。
接下来用数学公式描述一下WMD所解决的问题:
定义 ,
,  表示一个文档 中的词
表示一个文档 中的词  转移到另一个文档
转移到另一个文档  中的词
中的词  所占的权重,
所占的权重, 表示词 本身在文档 中所拥有的权重,
表示词 本身在文档 中所拥有的权重,  表示词 本身在文档 中所拥有的权重,
表示词 本身在文档 中所拥有的权重,  表示词 与词 的距离。
表示词 与词 的距离。
其实就是转换成了一个最小化线性规划问题,还有两个约束条件:
但是WMD也有不足之处:
- WMD这个算法用在聚类效果比较好(查询哪些文档相近),但是分类上不是很好;
- WMD算法基于KNN的分类精度虽然高于其他方法,但是计算成本依然高;
Doc2vec和语义相似度

若有收获,就点个赞吧
0 人点赞
