1. 数据仓库
1.1 基本概念
- 数据仓库也是一个数据库,可以利用数据仓库来保存数据,但是又区别于通常常用的数据库
- 数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用于企业或组织的决策分析处理。
- 面向主题:数据仓库中的数据是按照一定的主题进行组织的
- 主题:用户使用数据仓库进行决策时所关心的重点方面
- 集成:数据仓库是一个集成的数据库,数据仓库中的数据来自于分散的操作型数据,把分散的操作型数据从原来的数据中抽取出来,然后进行加工和处理,然后满足一定的要求,这样的数据才能进入数据仓库。(原来的数据可以来自各种关系型数据库、文本等等)。
- 不可更新:数据仓库主要是为决策分析提供数据,涉及到的操作主要是数据的查询,一般不会再数据仓库中做更新和删除,并且数据仓库中的数据随着时间的推移是不产生变化的集合。
- 面向主题:数据仓库中的数据是按照一定的主题进行组织的
1.2 数据仓库的结构和建立过程
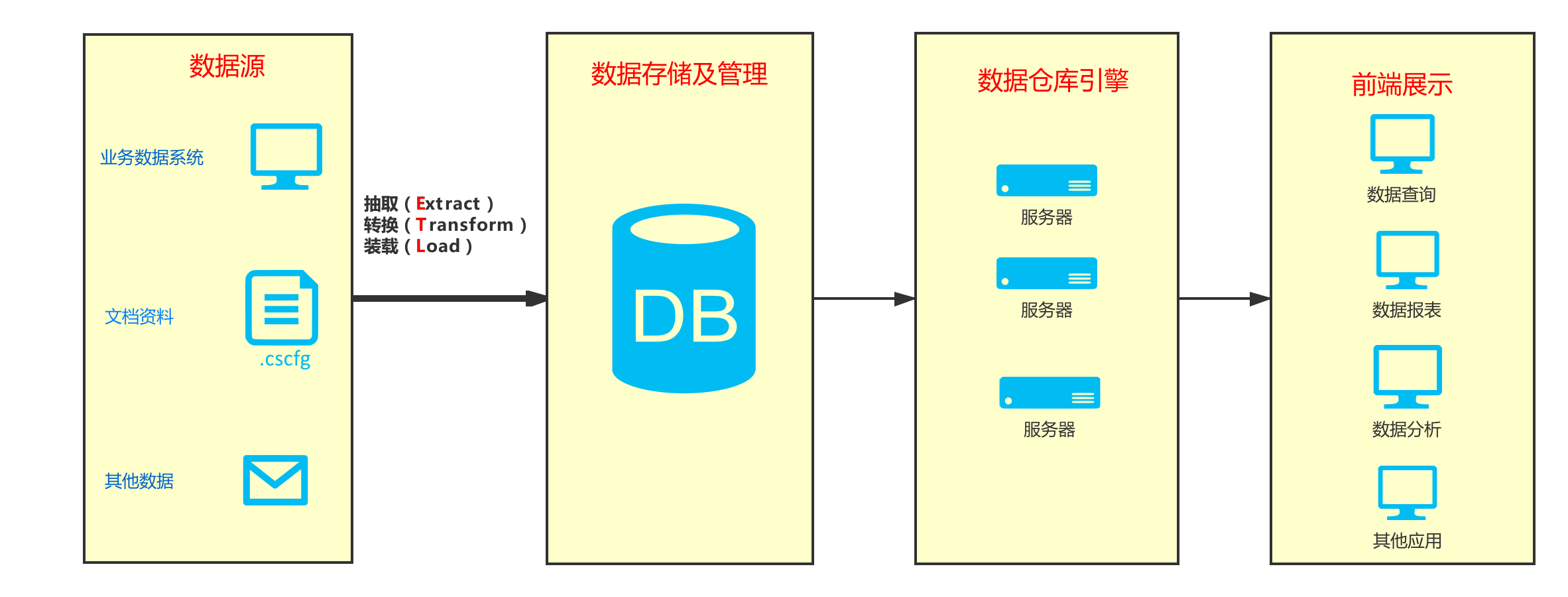
1.2.1 数据源
数据各种来源,如各种关系型数据库数据、非关系型数据库数据、文本文件等。
1.2.2 数据的存储及管理
将如上的数据进行 ETL(抽取,转换,装载)后单独存在一个数据库里面。这个数据库就是数据仓库
- 抽取:把数据源的数据按照一定的方式读取出来,然后进行转换。
- 转换:因为不同数据源的数据,数据格式不一样,不一定满足要求,所以需要按照我们所需要的格式按照一定的规则进行转换。
- 装载:将转换后满足格式的数据存入到数据仓库中,这样数据仓库就建立起来。对外提供服务。
1.2.3 数据仓库引擎
数据仓库中的数据想要对外提供服务,则需要数据仓库引擎,在数据仓库引擎中包含不同的服务器,不同的服务器提供不同的服务。比如数据查询,数据分析等等。
1.3 OLTP 应用和 OLAP 应用
1.3.1 典型的 OLTP 应用
银行转账:扣钱和加钱的操作应该同时成功,同时失败。所以必须要有事务的保证。
OLTP的系统面向的是事务。操作的频率非常高
1.3.2 OLAP
联机分析处理。
典型的应用系统为:商品推荐系统。这种应用是基于原来的历史数据,通过数据的分析和挖掘,然后提供给别的系统使用。主要面向的查询。
1.4 数据仓库中的数据模型
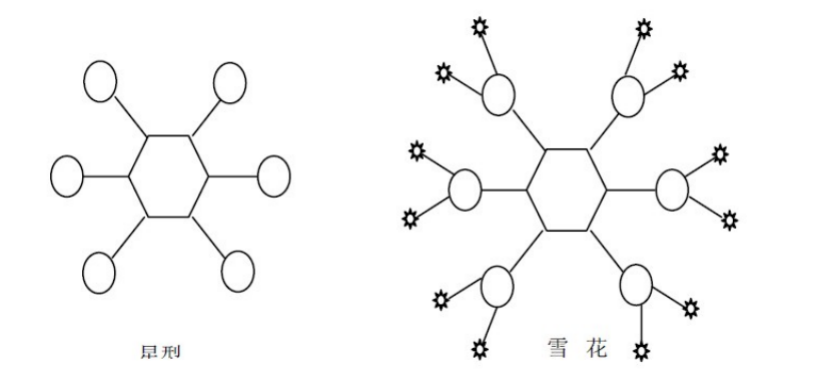
1.4.1 星型模型
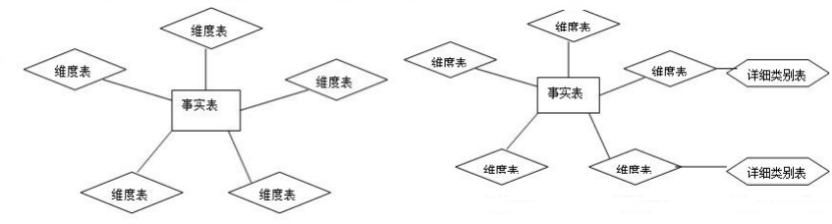
1. 星型模式:是一种多维的数据关系,它由一个事实表和一组维表组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。强调的是对维度进行预处理,将多个维度集合到一个事实表,形成一个宽表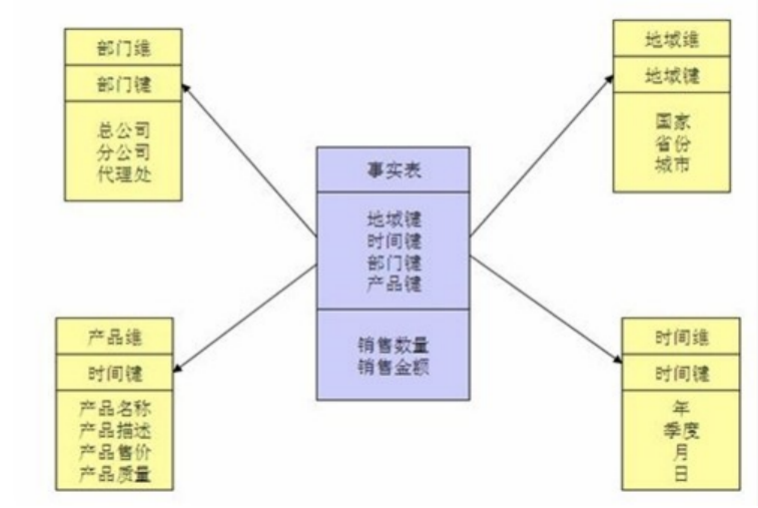
1.4.2 雪花模型
雪花模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 “层次 “ 区域,这些被分解的表都连接到主维度表而不是事实表。
1.4.3 星型模式 vs 雪花模型建模特点
| 多 | 少 | |
| 容易 | 难 | |
| 少 | 多 | |
| 快 | 慢 | |
| 高 | 低 | |
| 增加事实表的宽度 | 事实表字段较少,降低数据库存储负担。 |
关于表格中冗余度和对事实表的影响说明:星型模型会将所有的分析维度都作为事实表的一个直接维度,数据冗余较大的。但是,在一张表中表达出所有的类别属性,对数据库的存储空间较大的。在此基础上,对星型架构的基础上扩展雪花架构,一定程度上降低了分析查询的性能,提升了数据仓库的存储容量。
星型模型和雪花模型.docx
2. Hive
- Hive 是建立在 Hadoop HDFS 上的数据仓库。所以 Hive 的数据是保存在 HDFS 上。
- Hive 可以用来进行数据的提取转换加载(ETL)
- Hive 定义了简单的类似 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据
- Hive 允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的mapper 和 reducer无法完成的复杂的分析工作。
- Hive 是 SQL 解析引擎,他将 SQL 语句转移成 M/R,然后再 Hadoop 执行。
- Hive 的表和数据其实就是 HDFS 的目录/文件
2.1 Hive 的体系结构
2.1.1 Hive 的元数据
- Hive将元数据存储在数据库中(metastore),支持 mysql、derby 等数据库。
- Hive 中的元数据:包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的目录等。
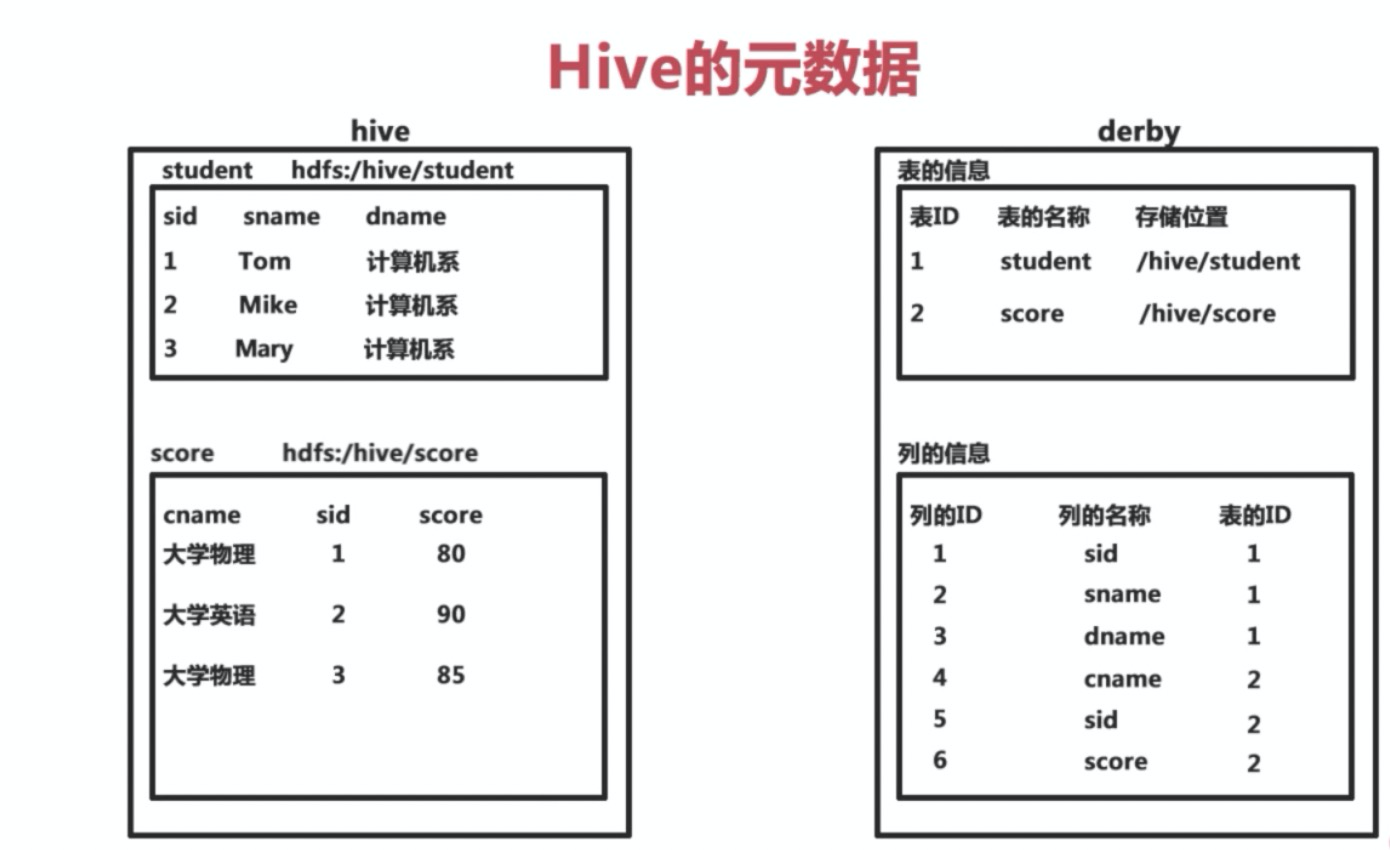
Hive 的元素默认会创建在 Derby 数据库中。
2.1.2 HQL 如何在 Hive 中进行查询
解析器,编译器、优化器完成 HQL 查询语句从
词法分析、
语法分析、
编译(类似于.java文件编译成.class文件)、
优化以及查询计划(plan)的生成,
生成的查询计划存储在 HDFS 中,并在随后又 MapReduce 调用执行。
2.1.3 Hive 的体系结构
- Hadoop
- 用 HDFS 进行存储,利用 MapReduce 进行计算
- 元数据存储(MetaSrore)
- 通常是存储在关系数据库如 mysql、Derby 中。
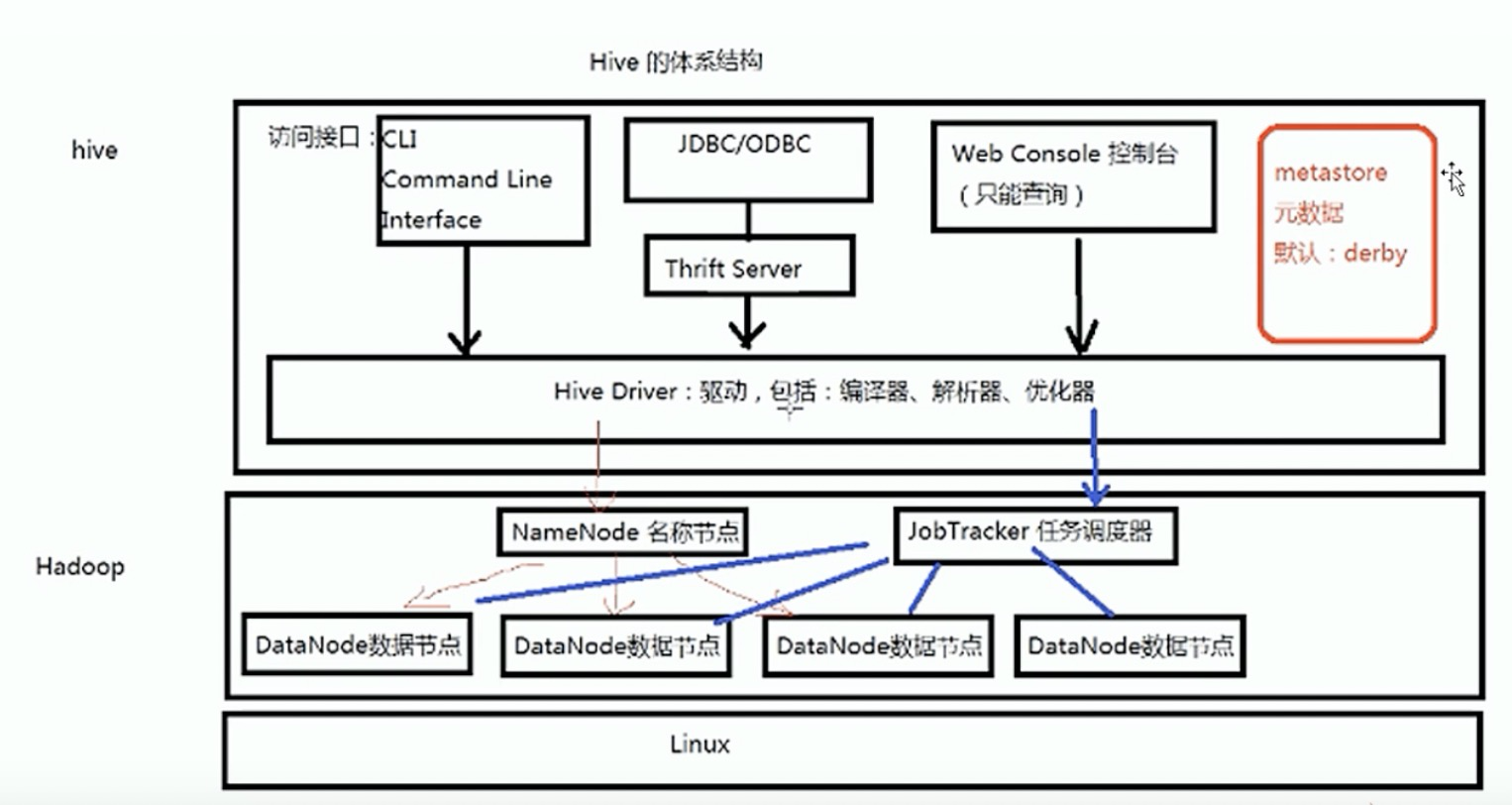
- 最底层是操作系统,之上便是 Hadoop 集群,
- Hadoop 集群:
- NameNode 名称节点,用来管理整个 Hadoop 集群的工作,
- DataNode 数据节点,用来存取数据,而 hive 中的数据最终就是存在了 Hadoop 的 DataNode 上。
- Jobtracker 任务调度器用来执行一条 HQL 语句,这条 HQL 语句会被解析成一个 MapReduce 的作业然后提交到 Hadoop 集群上进行运行,得到的结果最终返回给客户端。
- 在 Hadoop 集群之上构建 hive数据仓库,由于在 hive 中需要操作 Hadoop 集群中 HDFS 文件系统里面的数据,所以在 hive 底层中是 hive 的驱动,即解析器,编译器、优化器,他们负责 HQL 的解析和执行,有了 hive 驱动之后就可以提供不同的访问接口。
- web 控制台智能进行查询。
2.2 hive管理
2.2.1 hive 的启动方式
- CLI(命令行)方式
- web 界面方式,需要配置
- 远程服务启动方式
这部分可以使用开发中心的默认工作流 ODS 层进行常用的命令。
比如:
--查看所有表show tables;--查看函数show functions;--查看表结构desc 表名--查询数据select ** from **
这里需要注意的是如果我们查询所有的列,如: select * from ** ,这种语句是不会执行 MapReduce 的,但是当查询具体列的时候,则会调用 MapReduce。
2.3 hive数据类型
2.3.1 基本数据类型
- 整数类型: tinyint、smallint、int、bigint
- 浮点数类型: float、double
- 布尔类型:boolean
- 字符串类型:string、char、varchar
create table person(
pid int,
pname string,
married boolean,
salary double
);
desc person;
2.3.2 复杂数据类型
- Array:数据类型,由一系列相同数据类型的元素组成
- Map:集合类型,包含 key—> value 键值对,可以通过 key 来访问元素
- struct:结构类型,可以包含不同数据类型的元素,这些元素可以通过点语法的方式得到所有元素。
create table student(
id int,
name varchar(24),
grade array<float>
);
2.3.3 时间类型
- Date
- Timestamp
2.4 Hive 数据存储
- 基于 HDFS,最终存储在 HDFS 中,表名对应 HDFS 中一个文件夹,数据则是对应该文件夹下的数据
- 没有专门的数据存储格式
- 存储结构主要包括:数据库、文件、表、视图
- 创建表时,可以指定 Hive 数据的列分隔符和行分隔符
2.5 hive 中数据模型
- 表
- Table 内部表
- Partition 分区表
- External Table 外部表
- Bucket Table 桶表
- 视图
2.5.1 内部表
- 与数据库中的 Table 在概念上类似
- 每一个 Table 在 Hive 中都有一个对应的目录存储数据
- 所有的 Table 数据(不包括 External Table)都保存在这个目录中
- 删除表时,元数据和数据都会被删除
create table user(id int, name string);
-- 这样默认会将表创建在 /user/hive/warehhouse 目录下
-- 指定保存的位置
create table user2(id int, name string) location '指定的位置';
--指定分隔符,如果未指定分隔符则默认是制表符
create table user3(id int, name string)
row format delimited fields terminated by ',';
2.5.2 分区表
- Partition对应与数据库中的 Partition 列的密集索引
- 在 hive 中,表的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存在对应的目录下。
--按照性别进行分区
create table user(
id int,
name string)
partitioned by (gender string)
row format delimited fields terminated by ',';
2.5.3 外部表
- 指向已经在 HDFS 中存在的表数据,可以创建 Partition
- 他和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
- 外部表只有一个过程,加载数据和创建数据同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接,当删除一个外部表是,仅仅删除该链接。
2.5.4 桶表
- 桶表是对数据进行哈希取值,然后放到不同的文件中存储。
create table user(
id int,
name string,
age int)
clustered by(name) into 5 buckets;
--将名字进行哈希运算然后放到 5 个桶中。
2.5.5 视图
- 视图是一种虚表,是一个逻辑概念,可以跨越多张表。
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
- 视图可以简化复杂的查询
create view empInfo as
select e.empno, e.ename, e,sal*12 annlsal, d.dname
from emp e, dept d
where e.deptno = d.deptno

若有收获,就点个赞吧
0 人点赞
