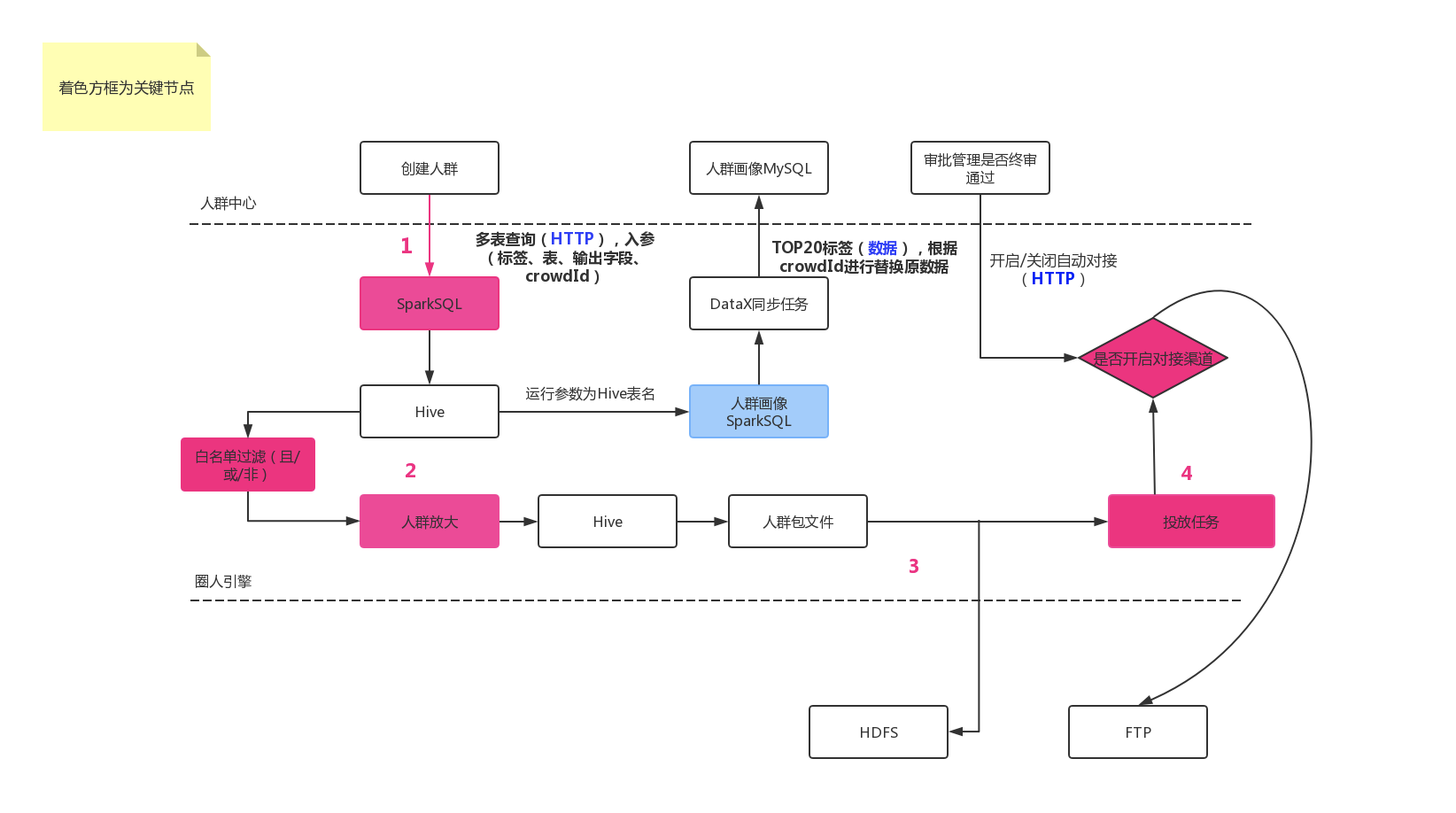
圈人引擎
1. hadoop/hive/spark
第一:先说下Hive是什么?
一个建立在分布式存储系统(这里指HDFS)上的SQL引擎。为什么要有Hive呢?因为有了Hadoop后,大家发现存储和计算都有了,但是用起来很困难。去厂商那里一看,清一色Oracle、DB2、TD啥啥的,客户被惯的只会用SQL来处理业务,难一点都交给乙方来做。
最终就是在 MR(MapReduce)外包一层,可以继续使用 SQL,这样就形成了 hive。本质上来说,它还是一个面向读的、面向分析的SQL工具。
第二:hive on MapReduce
hive 最终的数据是存在 Hadoop 体系的 HDFS 中,hive 的 SQL 语句会被解析在某些时候回使用 MapReduce 来操作。
这样就形成了 SQL—-hive—-MapReduce 的连线。(SQL 被 hive 解析成任务被 MapReduce执行)。
第三:spark
MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,而spark是能够在内存中进行计算,及时依赖磁盘进行复杂的运算。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。一句话就是MapReduce 在磁盘中计算慢,而 spark在内存中计算快。
第四:hive on spark
将Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。这样可以提高Hive查询的性能。
第五:Hive on Spark 与 SparkSql
hive on spark大体与SparkSQL结构类似,只是SQL引擎不同,但是计算引擎都是spark
结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。而且大家的引擎都是spark。
第六:使用场景
6.1 Hive on Mapreduce场景
Hive的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据
Hive适合处理离线非实时数据。6.2 SparkSQL场景
Spark既可以运行本地local模式,也可以以Standalone、cluster等多种模式运行在Yarn、Mesos上,还可以运行在云端例如EC2。此外,Spark的数据来源非常广泛,可以处理来自HDFS、HBase、 Hive、Cassandra、Tachyon上的各种类型的数据。
实时性要求或者速度要求较高的场所。
更详细的看这个文档。
2.项目理解
结合流程图,来得出为什么会需要加入在圈人引擎中需要使用 sparksql(实时性要求和查询速度要求)。
node 服务通过调用开发中心的接口,来实现离线任务

若有收获,就点个赞吧
0 人点赞
