Distributed RPC
distributed RPC(分布式RPC) (DRPC) 的设计目的是充分利用Storm的计算能力实现高密度的并行实时计算。Storm topology(拓扑)接受若干个函数参数作为输入,然后输出这些函数调用的结果。
严格的来说,DRPC不能够算作Storm的一个特性,因为它是一种基于Storm 原语(Stream,Spout,Bolt,Topology)实现的设计模式。DRPC可以脱离Storm,打包出来作为一个独立的库,但是它和Storm集成在一起更有用。
High level 概述
Distributed RPC通过 “DRPC sever”(Storm包含了这个实现)来进行协调。DRPC server 负责接收 RPC 请求,发送请求到 Storm 对应的 topology(拓扑),再从 Storm topology(拓扑)上得到结果,最后发送给等待的客户端。从客户端的角度来看,DRPC调用和普通的RPC调用没有什么区别。例如,以下是一个使用参数 “http://twitter.com”,调用 “reach” 函数计算结果的例子:
DRPCClient client = new DRPCClient("drpc-host", 3772);String result = client.execute("reach", "http://twitter.com");
Distributed RPC 工作流如下:
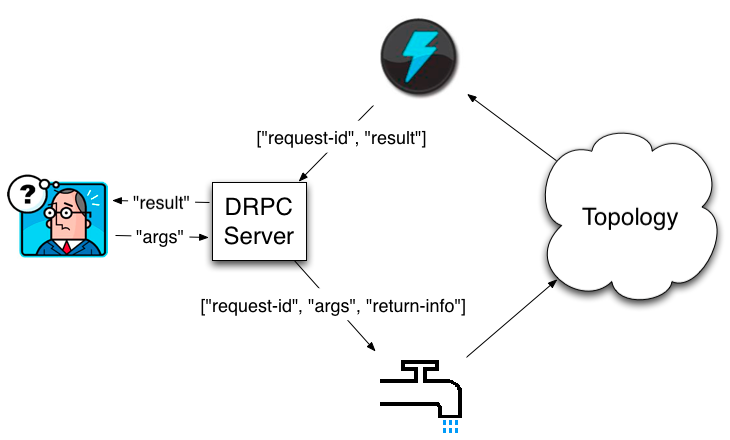
客户端发送要调用的函数名称和函数所需参数到 DRPC server。实现该函数的 topology(拓扑)使用一个 DRPCSpout 从 DRPC server 接收一个 function invocation stream (函数调用流)。DRPC sever 每一个函数调用都会给予一个唯一性的 id , topology(拓扑)计算完结果,使用一个叫做 ReturnResults 的 bolt 连接到DRPC server,根据函数调用的 id 将结果返回。 DRPC sever 使用 id 来匹配client等待的是哪个结果,unblock 等待的client,将结果返回。
LinearDRPCTopologyBuilder
Storm 有一个 topology(拓扑) 构造器叫 LinearDRPCTopologyBuilder,可以自动化 DRPC 所涉及的几乎所有步骤,这些包括:
- 建立 spout
- 返回结果到 DRPC server
- 给 bolts 提供聚合 tuples 的功能
我们一起来看一个简单的例子。下面实现了一个DRPC togology(拓扑),返回输入参数添加一个”!”。
public static class ExclaimBolt extends BaseBasicBolt {public void execute(Tuple tuple, BasicOutputCollector collector) {String input = tuple.getString(1);collector.emit(new Values(tuple.getValue(0), input + "!"));}public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("id", "result"));}}public static void main(String[] args) throws Exception {LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");builder.addBolt(new ExclaimBolt(), 3);// ...}
正如你所看到的,我们需要做的事情非常少。当创建 LinearDRPCTopologyBuilder 的时候,你告诉它相应topology(拓扑)的 DRPC 函数名称。一个单一的 DRPC sever 可以协调很多函数,函数与函数之间使用函数名称进行区分。你声明的第一个bolt 会得到一个二维的 tuple,tuple的第一个参数是 request id ,第二个字段是请求的参数。 LinearDRPCTopologyBuilder 希望最后一个 bolt 会输出一个二维的[id,result]格式的输出流。最后,所有中间结果产生的 tuples 必须包含 request id 作为第一个字段。
在这个例子中,ExclaimBolt 简单的在 tuple 的第二个 field 后添加了一个 “!” 符合。LinearDRPCTopologyBuilder 帮我们协调处理了这些事情:连接 DRPC server,并将结果返回。
DRPC 本地模式
DRPC 可以以本地模式运行,下面是以本地模式运行上面例子的代码:
LocalDRPC drpc = new LocalDRPC();LocalCluster cluster = new LocalCluster();cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));System.out.println("Results for 'hello':" + drpc.execute("exclamation", "hello"));cluster.shutdown();drpc.shutdown();
首先你创建一个 LocalDRPC 对象。这个对象在进程内模拟了一个 DRPC server,就像 LocalCluster 在进程内模拟一个storm集群。然后创建 LocalCluster 对象在本地模式运行topology(拓扑)。LinearDRPCTopologyBuilder 有单独的方法创建本地 topology(拓扑)和远程的topolgy(拓扑)。在本地模式里面,LocalDRPC 对象不会和任何端口绑定,所以 topology(拓扑)需要知道对象和哪个 DRPC 交互。这就是为什么createLocalTopology 需要一个 LocalDRPC 作为输入。
启动 topology(拓扑)后,你可以使用 LocalDRPC 的 execute 方法做 DRPC 调用。
DRPC远程模式
在一个真实集群上面使用DRPC也是非常简单的,有三个步骤:
- 启动 DRPC servers
- 配置 DRPC severs 的地址
- 提交 DRPC topologies(DRPC 拓扑)到Storm集群。
可以使用 storm 脚本启动一个DRPC server,就像启动 Nimbus 和 UI 节点一样。
bin/storm drpc
下一步,你可以配置 Storm 集群知道 DRPC sever(s) 的地址。DRPCSpout 需要知道这个DRPC地址,从而得到函数调用的请求。这个可以配置 storm.yaml 文件或者通过代码配置在 topology(拓扑)参数中。通过 storm.yaml 配置像下面这样:
drpc.servers:- "drpc1.foo.com"- "drpc2.foo.com"
最后,你使用 StormSubmitter 运行 DRPC topologies(拓扑),和你提交其他 topologies 一样。如果要以远程调用的方式运行上面的例子,用下面的代码:
StormSubmitter.submitTopology("exclamation-drpc", conf, builder.createRemoteTopology());
createRemoteTopology 是用来创建符合 Storm cluster 的 topologies(拓扑).
一个更复杂的例子
上面的例子只是用来说明 DRPC 的概念。我们来看一个更复杂的例子,需要使用 Storm 并行计算的 DRPC 功能。我们将看到这个例子是用来计算 Twitter 上每个URL的访问量(reach)。
一个URL的访问量(reach)是每个在Twitter上的URL暴露给不同的人的数量。为了计算访问量,你需要:
- 得到所有 tweet 这个 URL 的人。
- 得到步骤1中所有人的粉丝
- 对所有粉丝进行去重
- 对步骤3的粉丝求和。
单个 URL 的访问量计算会涉及成千上万次数据库调用以及数以百万的粉丝记录。这是一个很大很大的计算量。正如你即将看到的,在 Storm 上实现这个功能是很简单的。在单机上,访问量可能需要几分钟才能完成;在 Storm 集群上,即使是很难计算的 URLs 也会在几秒内计算出访问量。
一个访问量的 topology 的例子定义在 storm-starter:这里。下面是你如何定义这个访问量的topology。
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");builder.addBolt(new GetTweeters(), 3);builder.addBolt(new GetFollowers(), 12).shuffleGrouping();builder.addBolt(new PartialUniquer(), 6).fieldsGrouping(new Fields("id", "follower"));builder.addBolt(new CountAggregator(), 2).fieldsGrouping(new Fields("id"));
这个topolgoy(拓扑)执行有四个步骤:
GetTweeters得到tweet指定URL的用户列表。这个Bolt将输入流[id, url]转换成输出流[id, tweeter]。每个urltuple 被映射成多个tweetertuples。GetFollowers得到步骤1 tweeters的followers。该Bolt将输入流[id, tweeter]转换成[id, follower]。在所有的任务中,当有人是多个 tweet 相同 url 的粉丝,那么 follower 的tuple就会重复。PartialUniquer按照follower id 对followers流进行分组。相同的follower进入同一个任务。所以PartialUniquer的每个任务会收到完全独立的followers结果集。一旦PartialUniquer接受到针对request id 的所有 follower tuple,就会发出它 followers 子集的计数。- 最后,
CountAggregator获取到每一个PartialUniquer任务中接受到部分结果,累加结果后计算出访问量。
我们来看一下 PartialUniquer bolt:
public class PartialUniquer extends BaseBatchBolt {BatchOutputCollector _collector;Object _id;Set<String> _followers = new HashSet<String>();@Overridepublic void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {_collector = collector;_id = id;}@Overridepublic void execute(Tuple tuple) {_followers.add(tuple.getString(1));}@Overridepublic void finishBatch() {_collector.emit(new Values(_id, _followers.size()));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("id", "partial-count"));}}
PartialUniquer 继承 BaseBatchBolt 实现了 IBatchBolt 接口。一个 batch bolt 提供了将一批tuples 作为整体进行处理的API。每一个 request id 都会创建一个新的 batch bolt 实例,Storm会在适合时候负责清理实例。
当 PartialUniquer 在 execute 方法中接受到一个 follower tuple,将 follower 添加到 request id 对应的 HashSet。
Batch bolt 提供了 finishBatch 方法,当这个任务的batch 所有的 tuples 处理完后进行调用。这次调用中,PartialUniquer 发送一个 tuple,包含 followers id 去重后的数量。
在内部实现上,CoordinatedBolt 用于检测指定的 bolt 是否已经收到指定 request id 的所有 tuples 元组。CoordinatedBolt 使用 direct streams 管理这个协调过程。
topology 的其他部分是容易理解。正如你看到,访问量计算的每一个步骤都是并行的,通过DRPC实现也是非常容易的。
Non-linear DRPC topologies(拓扑)
LinearDRPCTopologyBuilder 只处理 “linear” DRPC 拓扑,计算过程可以像计算访问量一样分解成一系列步骤。不难想象,这需要一个更加复杂的 topology(拓扑),带有分支和合并的 bolts。现在,要完成这种计算,你需要放弃直接使用 CoordinatedBolt。请务必在邮件列表中讨论关于 non-linear DRPC topologies(拓扑)的应用场景,以便为 DRPC topologies(拓扑)提供更一般的抽象。
LinearDRPCTopologyBuilder 是如何运行的。
- DRPCSpout 发出 [args, return-info],其中 return-info 包含 DRPC Server的主机和端口号,以及 DRPC Server 为该次请求生成的唯一id号
- 构造一个 Storm 拓扑包含以下部分:
- DRPCSpout
- PrepareRequest(生成一个请求id,为return info创建一个流,为args创建一个流)
- CoordinatedBolt wrappers和direct groupings
- JoinResult(将结果与return info拼接起来)
- ReturnResult(连接到DRPC Server,返回结果)
- LinearDRPCTopologyBuilder是建立在Storm基本元素之上的高层抽象。
Advanced
KeyedFairBolt 用于组织同一时刻多个请求的处理过程
如何直接使用
CoordinatedBolt

若有收获,就点个赞吧
0 人点赞
