一、引言
对于大多数的技术管理者来讲,并非一定像研究员一样成为某个领域内的顶级专家,最为关键的能力则是具有系统化的知识、技能积累,能够高质量的做出决策,推动组织进步。通常来讲公司的技术体系建设可以分为:「基础设施」、「业务中台」、「专有技术」几部分,这几部分内容通常会比较容易抽象,可以从复杂的业务系统中剥离出来,比较容易进行体系性建设。过去几年中,我曾主导过几个公司的技术体系建设,一路走来,对这一过程体会颇深。本文作为系列文章,仅从「小型公司到中型公司」这一特殊的发展阶段,谈谈如何进行「基础设施」方面的技术体系建设。
1、为什么选择「小型公司到中型公司」?
对于小型公司来讲,能够快速完成产品交付获取市场回报,缓解生存压力最为重要。加之人员流动频繁、招募不到优秀人才等等客观因素,与业界头部公司相比,技术上必然存在不小的差距,这是无可争辩的客观事实。值得注意的是,近几年,很多学术背景优秀的团队在资本的推动下进入创业赛道,成为某一细分领域的独角兽。这样的团队往往在细分领域上有一定的技术优势,但在整体的工程、技术能力上与头部公司相比仍然存在不小的差距。
当小型公司缓解了基本的生存压力后,向中型公司迈进的过程中,必然追求发展质量,这也是本文选题的原因。
2、技术体系建设的意义
技术体系是技术整体性的表现形式,把相关的各种技术有机的联系起来形成统一的整体,能够提高整个研发过程的效率、质量并且降低研发成本。技术体系建设往往决定了一个公司能否走的更远,发展的更好。
很多公司的研发人员都会经常抱怨,公司管理混乱、没有规范、权责不清、没有知识积累、无可复用组件,这些都是缺少技术体系建设的表现。不管是提效也好,降本也好,最终的目的还是通过技术体系的建立,构建起一个良好的研发文化,毕竟只有文化上的认同,才能够一起相向而行。
二、基础设施
抛开具体的技术点而言,比如是选择ClickHouse好还是选择Drois更好,通常「基础设施」建设包含以下重要的内容,实际上这些内容也与当下流行的DevOps有很多重合之处。本文作为系列文章的开始,主要介绍可观测部分。
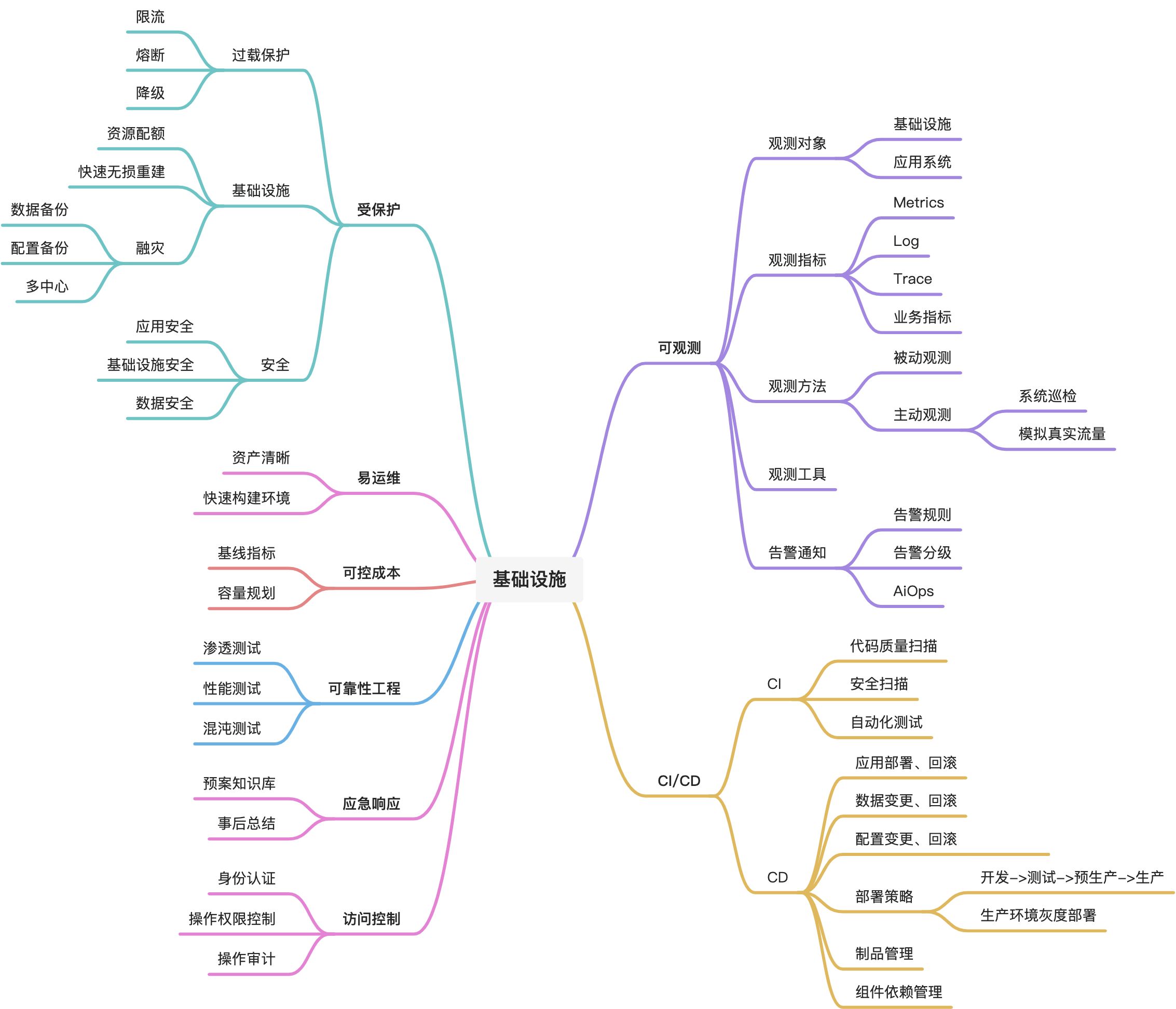
三、可观测建设历程
管理学大师彼得德鲁克有一句话:“如果你无法衡量它,你就无法管理它”。
2018年,可观测性(Observability)被引入IT领域,CNCF率先出现了Observability的分组。此后「可观测性」逐渐取代「监控」,成为云原生技术领域最热门的话题之一。在「可观测性」出现之前,我们常常使用「监控」这一概念,两者有很多相似之处,甚至有人认为「可观测性」就是「监控」,无非是换了一个名字而已。实际上两者还是有些区别,相比较而言,监控是以运维视角被动地解决故障为目标,而可观测则是融入开发与业务部门的视角,面向SLA/SLO,具备比原有监控更广泛、更主动的能力,主要体现在:
- 排错(Degugging),即运用数据去诊断故障出现的原因。
- 剖析(Profiling),即运用数据进行性能分析。
- 依赖分析(Dependency Analysis),即运用数据厘清系统之间的依赖关系并进行关联分析。
通常来讲,观测对象主要集中在应用系统、基础设施两部分,这里基础设施特指网络、主机、数据库等部分,对于应用系统来讲通常使用APM采集Metrics、Trace、Log等数据,而基础设施部分通常仅采集Metrics、Log。就观测方法来讲,有被动、主动两种方法,被动观测很好理解,通过APM等工具采集数据,而主动观测则是开发一些程序主动访问系统进行系统健康检测。
在近几年的工程实践中,结合公司的具体业务特点我也先后设计了几版可观测系统。在系统建设的过程中,无论哪个版本都始终坚持以保证SLA/SLO的视角进行建设,逐步细化到各个层级。
1、1.x版
在1.x版本的架构设计中,基础设施部分采用Prometheus + Grafana + AlertManager的设计方案,而应用部分则采用集成Prometheus Exporter Client方式采集Metrics,日志统一使用ELK进行收集。这套方案的开发成本很低,在研发+运维的共同努力下很快就构建起了一套可观测系统。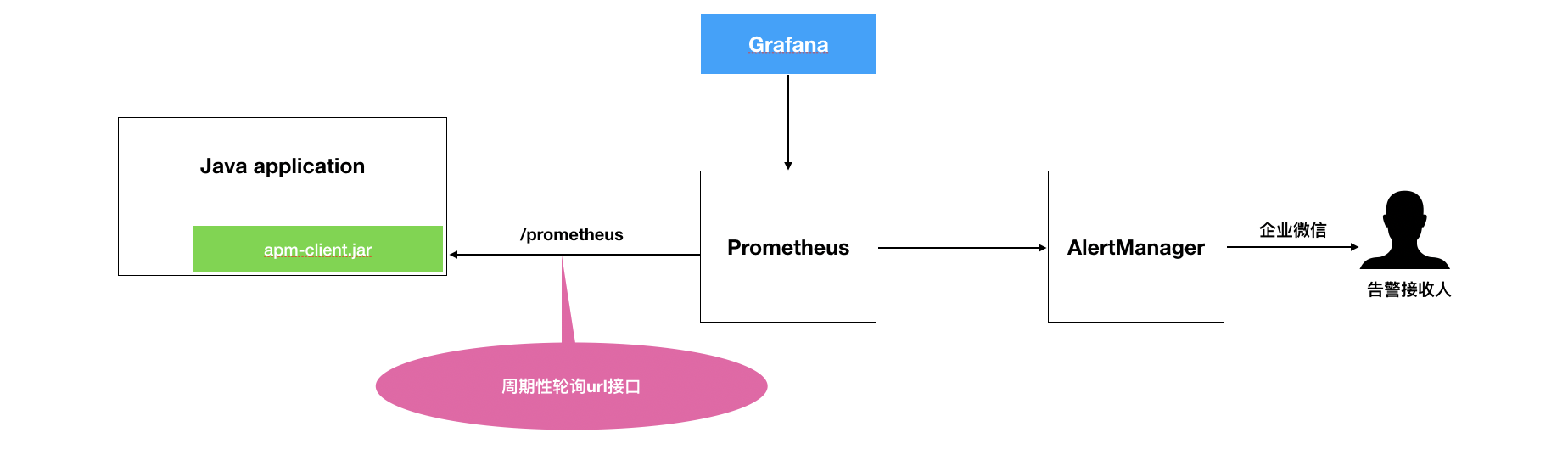
小结一下,这套方案尽管满足了基本的业务所需,但仍有一些缺点:
- 对于应用有侵入性改造,必须集成Prometheus Exporter Client。
- 只能采集到Metrics,采集不到 Trace。
- 应用必须包含Web环境,否则无法通过/prometheus接口获取Metrics。
- 只能进行后端监控,对前端没有覆盖。
- 没有开放告警规则修改能力,只能运维修改。
- 基础设施、应用没有进行关联,例如主机产生告警后,不能快速定位主机上运行的服务是否受到影响以及上下游服务是否受到影响。
2、2.x版
为了解决1.x中的一些问题(trace收集、运行时修改告警规则、尽可能无侵入),先后调研了PinPoint、Skywalking、Elastic Apm等几个Agent方式的开源Apm工具。
就调研结果来看,Pinpoint部署过于复杂,需要Hbase环境,首先被排除。Skywalking不能运行时修改告警配置也被排除在外(6.5.0 之后可以)。Elastic Apm经过调研后也无法满足我们的需求。综合来看,无论哪个Apm工具都不能很好满足需求,需要定制开发。最初希望通过修改Skywalking来实现我们的需求,很遗憾按照官方文档没有编译成功,最终我们通过修改Elastic Apm来完成2.x系统建设,整体架构如下:
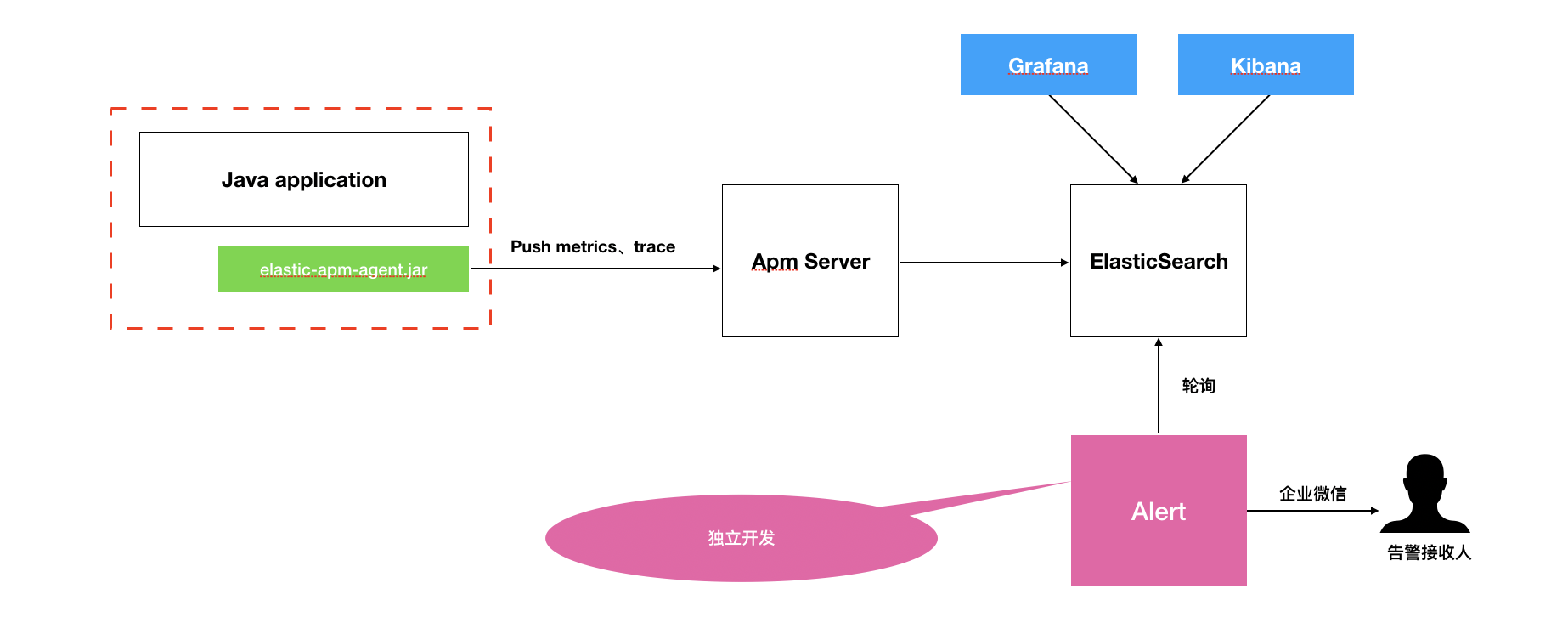
上文提到要解决运行时修改告警配置这个问题,为此我们开发了一个独立的Alert告警系统,并参考PromQL的语法、语义,使用Antlr实现了语法解析器,周期性查询ElasticSearch来判断是否有异常发生。例如:
示例1
avg(dubbo{appname=”qdp-polaris-server”} by interface range 5m) > 2000,计算5分钟内qdp-polaris-server系统各个dubbo接口的平均响应时间,如果超过2000ms则产生报警。 相当于SQL:
select
avg(响应时间)
from
metrics_table
where
interface_type = ‘dubbo’ and timestamp between now() - 5m and now()
group by interface
示例2
avg(http{appname=“qdp-polaris-server”, url ~= “.xxx.”} range 5m) > 2000,计算5钟内qdp-polaris-server系统http接口名称匹配正则表达式.xxx.的接口平均响应时间,如果超过2000ms则产生报警。
示例3
avg(jvm.memory{appname=”kafka-connect-platform-web”} by ip range 5m) > 1024,计算5分钟内kafka-connect-platform-web系统各实例jvm堆内存利用率,如果超过1024MB则产生报警。
示例4
值得注意的是,很多后端程序并未严格遵守Http Status Code规范,即使程序内部已经出现错误,仍然向前端返回Status Code 200,只不过在Response Body中自定义了错误码。为了统计接口响应成功率,我们采用变通性方法,使用AOP拦截接口调用,通过自定义指标来记录接口返回是否成功,不在通过Http Status Code进行判断。响应的告警表达式则写成如下:
count(event{appname=”qdp-skyline-web”, keyword ~=”.ERROR.“} range 5m) > 5
计算 5 分钟内 qdp-skyline-web 系统中匹配.ERROR.的总数,如果超过 5 次则产生报警。
小结一下,相比于1.x设计方案,2.x有了一些进步,使用Agent方式无侵入性的添加了采集功能,并且可以采集到Trace,服务也不需要Web环境,同时也面向研发开放了服务告警配置能力,其他方面则没有进步。
3、3.x版
2.x版成功上线之后,我离开公司加入到一个新的创业团队中,开启了另一段建设旅程。这个团队继承了之前的一些积累,以Skywalking作为基础构建了一套Apm系统。基础设施部分则仍然采用了Prometheus + Grafana + AlertManager的方案。
实际的使用过程中,如同使用其他开源软件一样,也遇到了开源软件能用但不好用的普遍性问题。例如,Skywalking无法以全局视角清晰的展示各系统的Error情况,为此我们开发了一个「报错大盘」,清晰的展示了指定时间段内各系统的Error情况。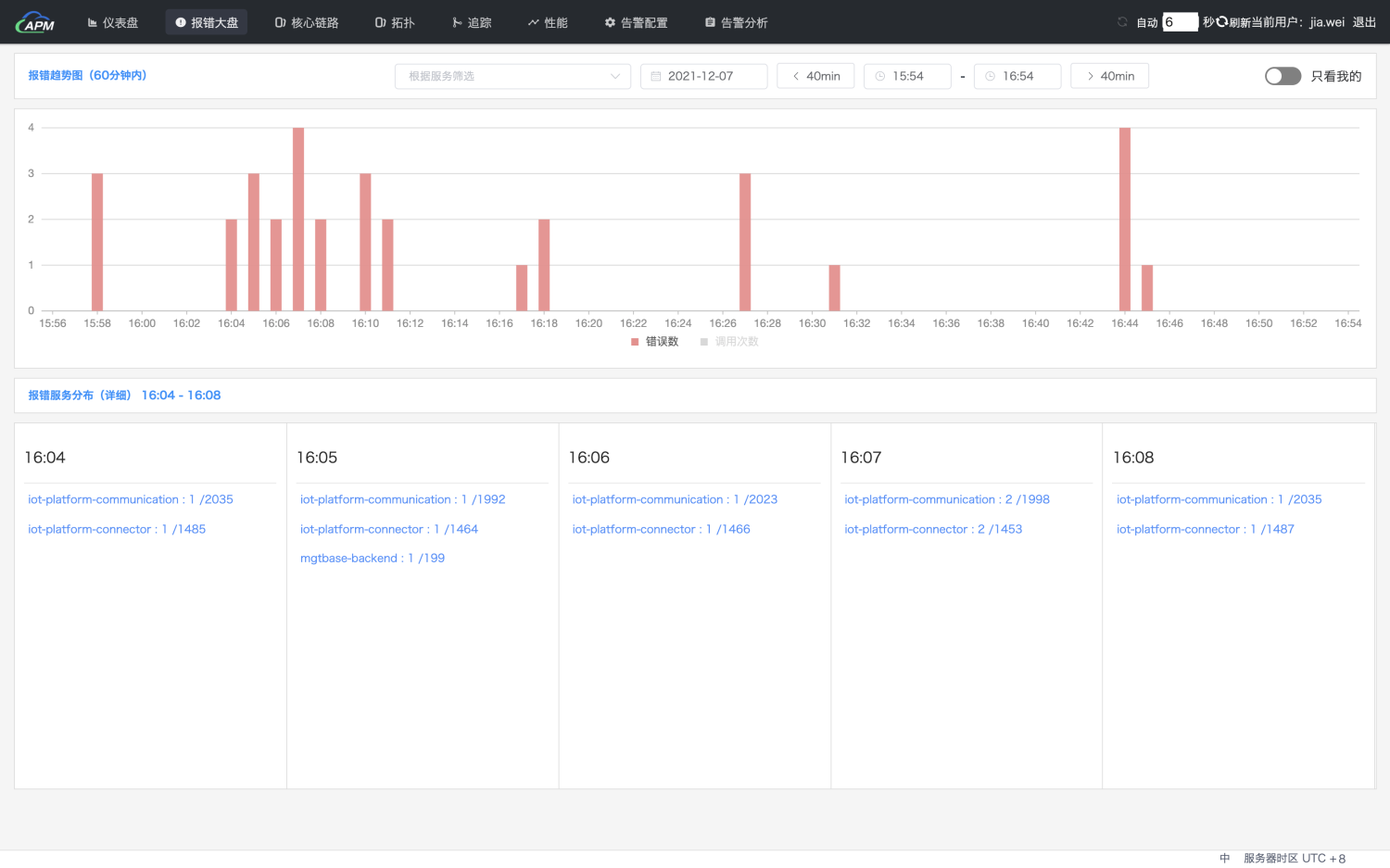
线上系统维护过程中,也经常面临这样的一些问题:
- 某个服务的上下游服务是什么,这些上下游服务的运行状态如何。
- 服务依赖了哪些基础设施,这些基础设施的运行状态如何。
为了解决这些问题,我们从Skywalking后端存储中,周期性增量同步了Trace数据,生成了服务拓扑关系,并使用Cmdb管理服务与中间件的依赖关系。当选择一个服务后,可以看到这个服务的上下游依赖关系以及所关联基础设施的运行状态,基础设施部分的观测则仍然通过Prometheus + Grafana的方案。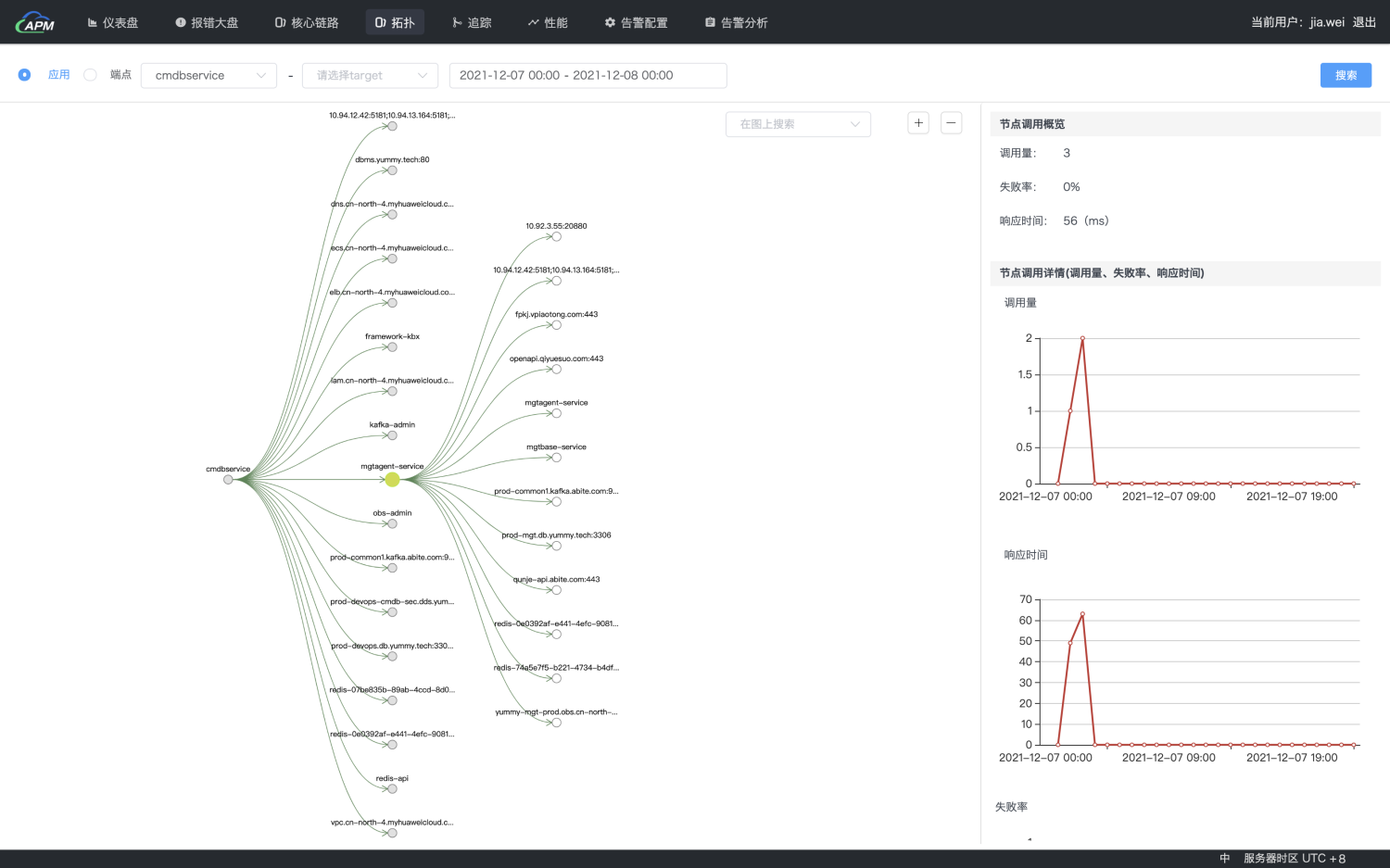
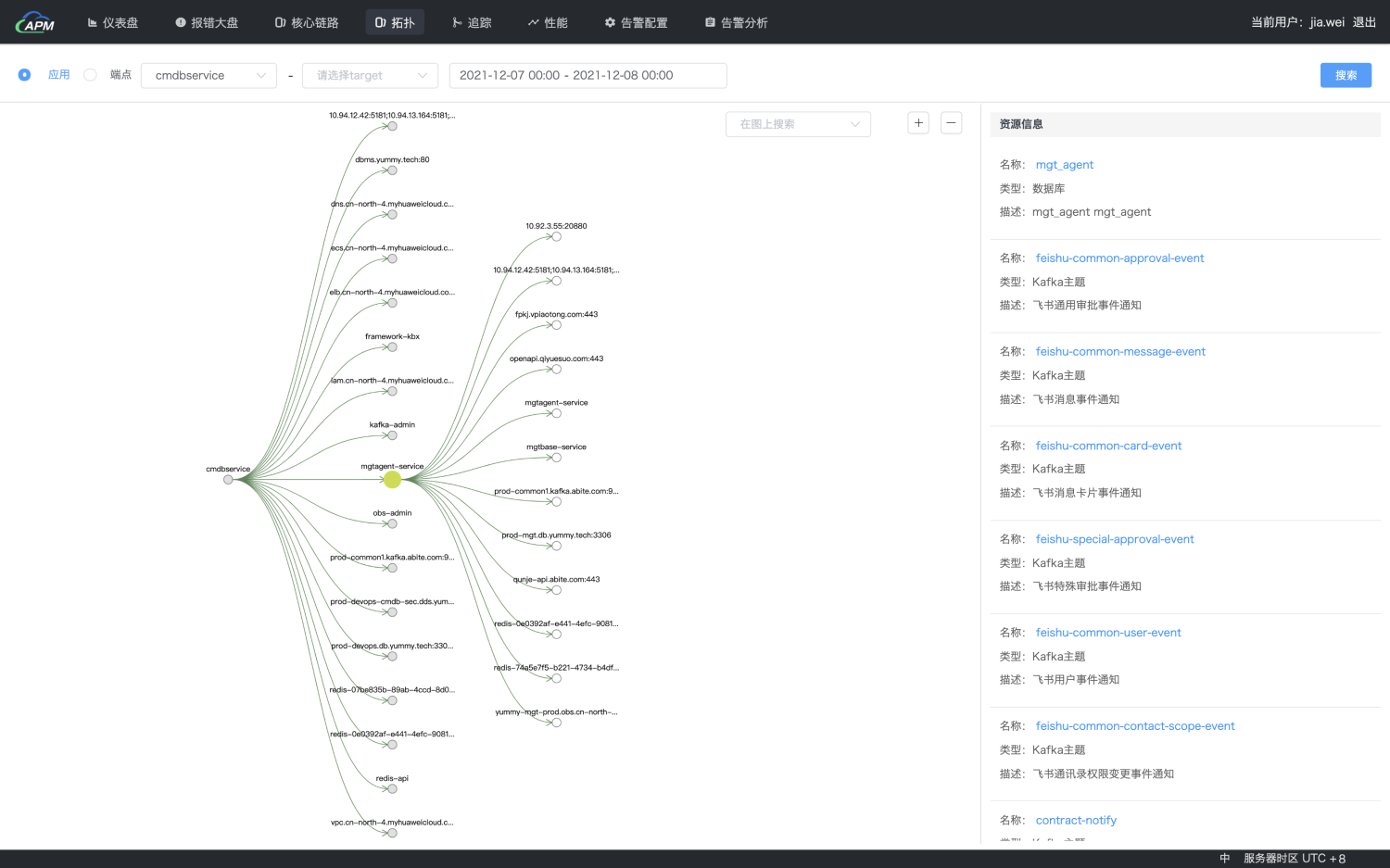
需要提及的是,Skywalking内置了服务拓扑关系,但性能非常差,这也是我们开发上述功能的原因,为了提高这部分的处理性能,我们采用了Lambda架构,周期性生成拓扑快照,同时与增量拓扑叠加实现拓扑结构查询功能。
由于系统的复杂性以及告警规则设置的差异性,线上告警是经常发生的,为了避免被告警轰炸,又开发了核心链路监控功能,仅关注核心链路请求响应时间、错误率两个重要指标,通过这两个指标可以快速判断业务主流程是否正常。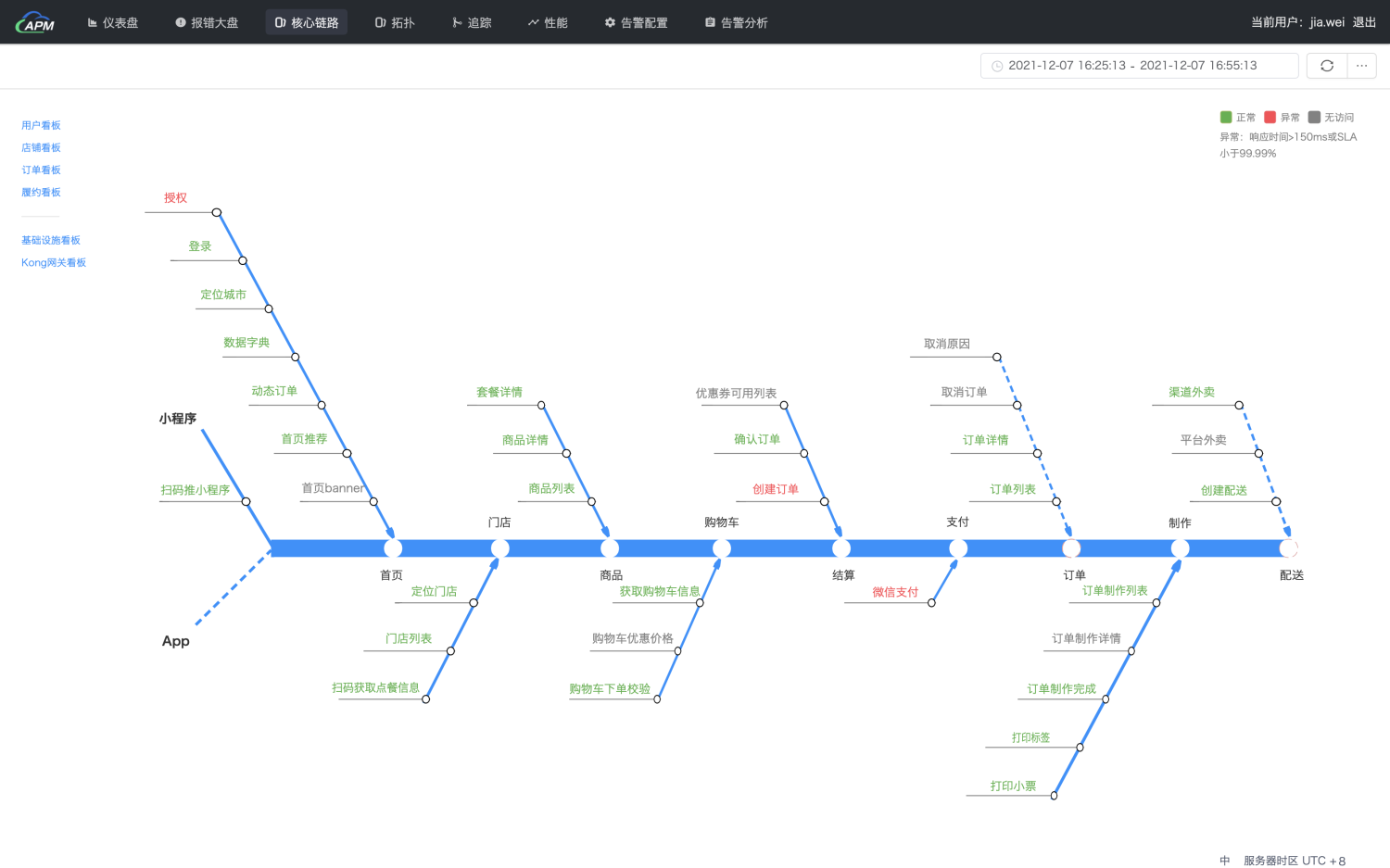
小结一下,3.x开发完成后,基本实现了全方位的观测、 监控,满足了业务所需,但整体架构仍然是各个系统的拼凑,「数据集成」、「信息流转」、「使用便捷」等方面仍然有待提高。
4、引入观测云
使用开源的Apm工具确实能够构建起一套可观测系统,但仍然需要进行一些扩展开发,实际上就是为了满足「数据集成」、「信息流转」以及「使用便捷」,这个过程的建设无疑是漫长且复杂的。最近接触到观测云这套SaaS化的可观测产品,并且引入到实际的业务系统中,非常好的满足了业务所需,同时也带来了业界的最佳实践。
很多公司都存在这样一个普遍现象,技术型团队都面临着一个灵魂级的拷问,存在的意义在哪。为了证明自身及团队价值,很多团队不惜余力的重复造轮子,而不是考虑引入成熟的产品方案。这是比较考验技术管理者决策能力之处,从整个社会发展来看,协作分工是必然趋势及结果,技术团队还是需要集中精力做自己的主营业务。
观测云有些非常新颖、实用的特性,能够非常方便的进行可观测系统建设:
- 内置60余种数据监控视图模板,例如:MySQL监控,Docker容器监控、云监控等等,无需手动搭建,开箱即用。
- 支持采集主机、容器、进程、多云等部分,统一监测,从整体观测基础设施状态。并且可以实现连接不同来源数据,一键式关联相关指标、链路、日志等数据,实现数据的平滑跳转分析。
- 可以通过快照方式保持监控图表,并通过链接分享给团队成员,提高整体的协作性。
- 内置DQL语言,能够使用通过编程的方式做一些扩展开发功能。
- 通过DataFlux Fuc能够与外部系统相结合,快速整合其他系统。
四、OpenTelemetry
谈到可观测,必然要谈及OpenTelemetry,OpenTelemetry由以下几部分组成:
- 跨语言的标准规范(Specification):定义了数据、上下文、API、概念术语等的规范。这是OTel的核心,它使得所有观测数据有机地统一起来,这样观测平台才能自动比对、自动过滤,同时也为AI提供了高质量的数据。
- 接收、处理、输出观测数据的工具(Collector):一个用于接收OTel观测数据的工具,并支持通过配置pipeline对观测数据进行处理,输出给指定的后端。
- 各种语言的SDK(SDK):基于OTel标准的API实现的各种语言的SDK,用来支持自定义开发观测数据采集器。
- 采集器(Instrumentation):开箱即用的观测数据采集器。
OpenTelemetry的目标是宏大的,最近国内很多公司也都在拥抱OpenTelemetry,期待OpenTelemetry能够像Linux一样一统江湖。
五、AIOPS
最后再谈谈AIOps,AIOps这几年经历了大起大落,赞赏有之,批评有之。从理论上讲这是基于规则的可解释性与基于机器学习的不可解释性之争。从实践上讲这是系统快速迭代导致的数据快速变化与模型稳定性之争。
AIOps Handbook收集了很多AIOps方面的资料,感兴趣的朋友可以去看看,在我过往的项目实践中还没有引入AIOps。
六、附录
1、常见工具
- Netflix Dispatch
- PagerDuty
- VictorOps
- Splunk
- SigNoz
- Skywalking
- Pinpoint
- Elastic Apm
- Jager
- Prometheus
- Grafana
- AlertManager
- Mimir
- Loki
- Tempo
2、推荐阅读
[1] 唐文. 海量运维、运营规划之道[M]. 北京:电子工业出版社, 2014
[1] 唐文. 大型网站性能监测、分析与优化[M]. 北京:电子工业出版社, 2016

若有收获,就点个赞吧
0 人点赞
