关于作者
- 黄雷:腾讯云高级工程师,曾负责构建腾讯云云监控新一代多维业务监控系统,擅长大规模分布式监控系统设计,对golang后台项目架构设计有较深理解,后加入TKE团队,致力于研究Kubernetes相关运维技术,拥有多年Kubernetes集群联邦运维管理经验,目前在团队主要负责大规模集群联邦可观测性提升,主导研发了腾讯云万级Kubernetes集群监控告警系统,智能巡检与风险探测系统。
陈冰心:腾讯云容器产品经理,现负责腾讯云集群运维中心监控、日志、巡检等产品策划工作。对大规模分布式监控系统有深入了解,在监控和可观测性领域积累了大量的经验,深刻理解用户运维场景,负责腾讯云云原生prometheus监控和容器基础监控的产品迭代,致力于为用户提供稳定易用的监控服务。
序
欢迎大家给此文档提issue github
无论你是运维,还是开发,为自己的业务配置面板和告警来监控程序的运行状况算是职业必备技能了。
如果你觉得官方文档过于复杂,想光速学会最核心最常用的内容,此文适合你。本文主要内容
本文不介绍基于Prometheus + Grafana监控系统的构建和运维相关内容,只介绍Prometheus的采集配置,PromQL,Grafana的面板配置中最核心的知识点。其中还提供一些笔者的经验和技巧供读者参考,在实践中非常实用。
本文假设读者的业务是运行于Kubernetes下。
本文特别适用于需要采集业务指标并自己配置面板的开发/运维朋友。带着问题
如果你不知道文本内容是否是你已经掌握的,可以试着回答以下几个问题,如果难以回答,可以参考一下本文的内容:
Prometheus有哪些指标类型?
- 如何在代码里暴露指标?
- Target是什么?
- 如何正确配置服务发现?
- Instant vector, Range vector, Scalar是什么?
- 如何对Instant vector做*法?
- 什么是Staleness机制?
- 如何使用Grafana变量?
-
本文的阅读顺序
本文尽可能划分更多目录便于查询,且每个小节尽可能短小精干,便于快速学习,章节之间有一定递进关系,如果读者是零基础,强烈建议从头开始阅读。
指标的采集
我们先来看下如何将自己需要的指标暴露出来,并能报到Prometheus去。
基本概念
Time Series/Label
Time Series(后边直接称Series) 表示一条随时间变化的曲线,横坐标是时间,纵坐标是该时间的数值。
Series还包含一些不变的KV对,称为Label(也称维度),用于表示该曲线的含义。
需要注意的是,Series的Label集合是固定的,一旦Label的个数,或者Key,或者Value有任何变动,它就是另外一个Series了。
例如cpuusage{node=”1.1.1.1”,cpu=”0”} 和 cpuusage{node=”1.1.1.1”,cpu=”1”} 是2条不同的Series
再例如cpuusage{node=”1.1.1.1”,cpu=”0”} 和 cpuusage{node=”1.1.1.1”} 也是2条不同的Series
Tip: Prometheus将指标名字也保存为Label,叫__name,所以cpu_usage{node=”1.1.1.1”} 和 {__name=”cpu_usage”,node=”1.1.1.1”}是等价的。指标采集方式
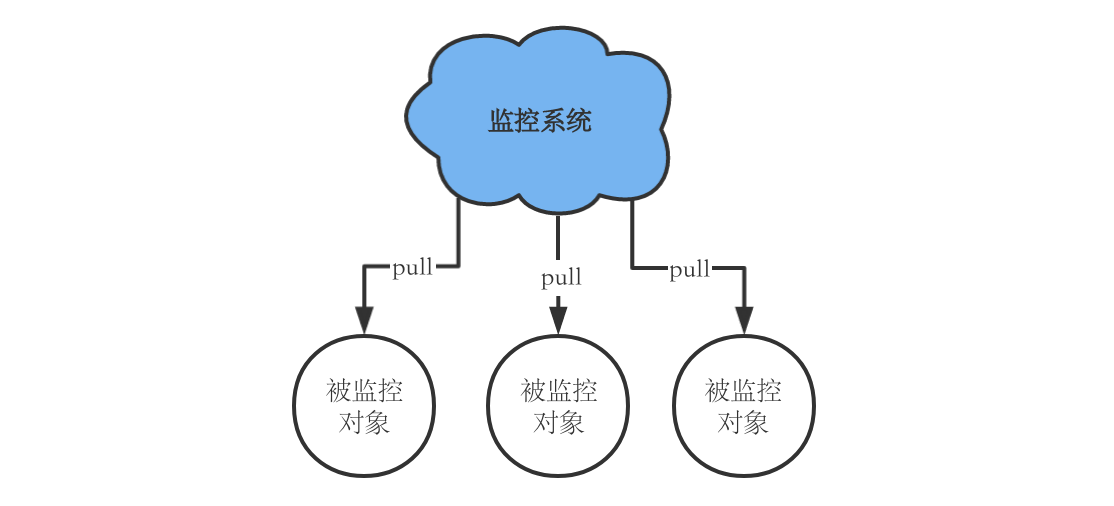
最常见的指标采集方式有两种
pull: 监控系统周期性得对被监控对象发起采集请求,被监控对象将他想上报的指标的当前值按约定的格式返回给监控系统。
- push: 被监控对象周期性得将指标数据推送到监控系统。
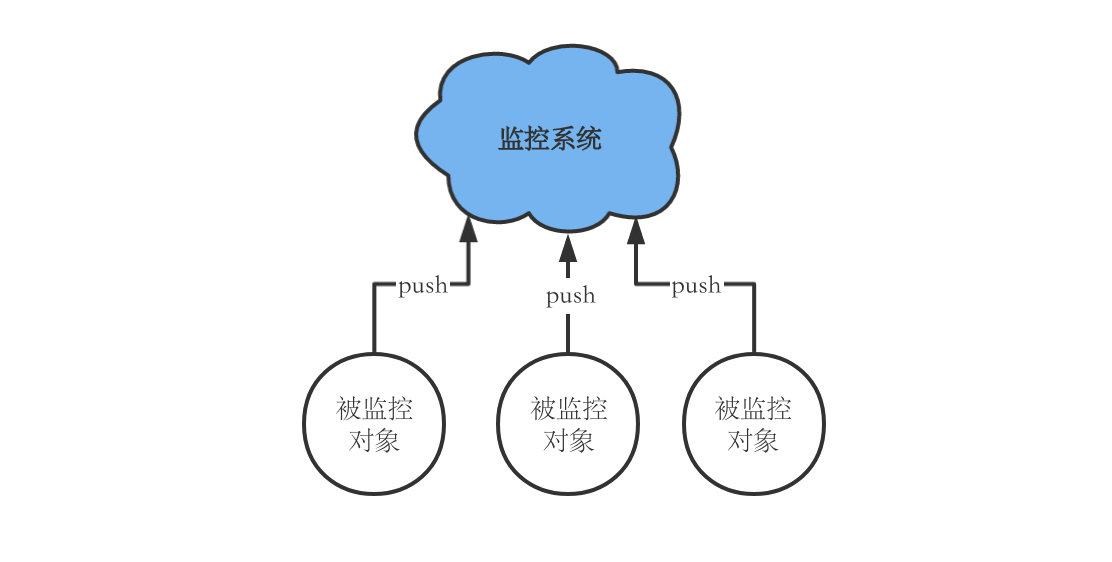
Tip: Prometheus最常用的方式是pull,即周期性的去监控对象那里拉数据,这就要求Prometheus到被监控对象方向的网络是连通的。
先要暴露指标
首先,我们就要学会如何让我们的服务对外暴露指标集合,并能在Prometheus来pull的时候,把指标返回给它。
指标的设计
不同的指标,其所代表的含义不同,为此Prometheus提供了提供了4种指标类型,可以在生成指标的时候指定。
Counter
Counter就是一个非负递增值,只增不减,适用于例如总请求数这类指标,我们在查询的时候,可以通过查询语句,在Counter的数据上计算出增长率等。
Gauge
Gauge没啥限制,可增可减,适用于例如内存使用量这种指标。
Histogram
Histogram是桶统计类型,它会自动将你定时的指标变成3个指标,例如你指定一个Histogram叫a,那就会生成
- a_bucket{le=”某个桶值,例如100”}用于统计打点值低于100的次数。
- a_sum表示打点值的和
- a_count表示打点次数
Summary
Summary是百分位统计类型,会在客户端对于一段时间内(默认是10分钟)的每个采样点进行统计,并形成分位图。 它也会生成3个指标,例如你指定一个Summary叫a,那就会生成
- a{quantile=”0.99”} p99百分位数,这个0.99是定义指标时指定的,可以指定好几个。
- a_sum表示打点值的和
- a_count表示打点次数
提供Pull接口(go为例)
Prometheus的被监控对象采用Http接口来暴露设计好的指标。
三步学会在代码中打点
Prometheus提供了lib用于在代码中定义指标,打点,暴露采集接口。这里以golang为例。
https://github.com/prometheus/client_golang/blob/master/examples/random/main.go 在代码里生成指标只要做3步。

- 暴露/metrics接口
- 打点
其他语言也有对应的库。
https://prometheus.io/docs/instrumenting/clientlibs/
metrics接口的返回值
我们将指标暴露到了/metrics这个http接口上,那指标是以什么格式返回的呢?Prometheus的指标格式非常简单,就是一行一个指标,一行的格式为
指标{label集合} 这次的采集值 时间戳(可有可无)
cpu{node=”0”} 100 cpu{node=”1”} 101 cpu{node=”2”} 102
Tip: 你可以直接curl这个http接口来查看暴露的指标集合是否符合预期
使用exporter来暴露指标
如果不方便改原来的代码,或者监控对象不是程序而是某个基础设施比如虚拟机,就可以开发一个程序专门做指标暴露,将需要的指标进行收集后以Prometheus的格式暴露,这个程序就叫Exporter。然后让Prometheus去采集Exporter。
社区有很多开发好的exporter,比如mysql的Exporter,jvm的Exporter等等,按需自取。 https://prometheus.io/docs/instrumenting/exporters/ 你也可以基于前面介绍的指标生成的方法来写自己的exporter
再让Prometheus来采(采集配置)
数据有了,接口也暴露了,该告诉Prometheus来采了,这要通过Prometheus配置文件来实现。
基本格式
先来看下配置文件基本格式,最重要的就是job了。
global: # 全局配置,对所有采集生效 scrape_interval: 15s # 默认采集间隔 external_labels: # 这些label会被加到所有采集到的指标上 cluster: a replica: b scrape_configs: # 最重要,所有采集配置都在这里了 - job_name: “job1” # 采集任务,下面介绍 …. - job_name: “job2” ….
一个job就是一个采集任务,它有四个需要配置的部分,我们在后面会一一进行光速学习。
scrape_configs: - job_name: “job1” kubernetes_sd_configs: # 1. 服务发现,有哪些对象(Target)需要监控,这里以K8s为例子 … relabel_configs: # 2. 被发现的对象会自带一些label,这一步可以修改添加label,也可以根据label过滤掉采集对象。 … metrics_path: /metrics # 3. 定义发起采集请求的方式,例如path scheme: https # 3. 定义发起采集请求的协议,例如https metric_relabel_configs: # 4. 针对采集过来的指标,进行lable的添加修改,也可以根据label过滤掉一些指标 …
采集对象(Target)核心概念
在学习服务发现之前,我们先学习一下采集对象(Target)到底是啥,以及如何过滤出我们想要的Target,这是使用服务发现的前提。
什么是Target
Target就是采集对象,他的信息表现为一系列label的集合,服务发现类型不同,Target的label集合也不同,具体需要去官方文档查,但实际上记住一些最常用的就行。�
例如如果用k8s服务发现去监控Pod,Prometheus会把每个Pod的每个Container变成包含以下label集合的Target,注意,是每个人Pod的每个Container是一个Target(可以指定namespace)。
Target的特殊label
除了上边一些由和特定服务发现有关的label,实际上有一些特殊的label是每个Target都有的,无论你是用k8s服务发现,还是用其他的。例如下边是最常用的。
- address:这个是采集地址,比如上边的由Pod转换过来的Target,这个label值就自动设置为pod的ip。
- scheme:这个是采集用的协议,默认是http,如果配置文件里设置了,就会用配置文件里的。
- metrics_path:这个是采集用的path,默认是/metrics,如果配置文件里配了,就会用配置文件里的。
注意:Prometheus最终真正发起采集的时候,用的是上边这几个label的值来作为真正请求的参数,而不是配置文件里写的,也就是说,只要改这些值,就可以改变最终请求的动作,比如,如果改了某个Target的address_,那请求的url就变了,我们可以通过relabel_config来做这些事。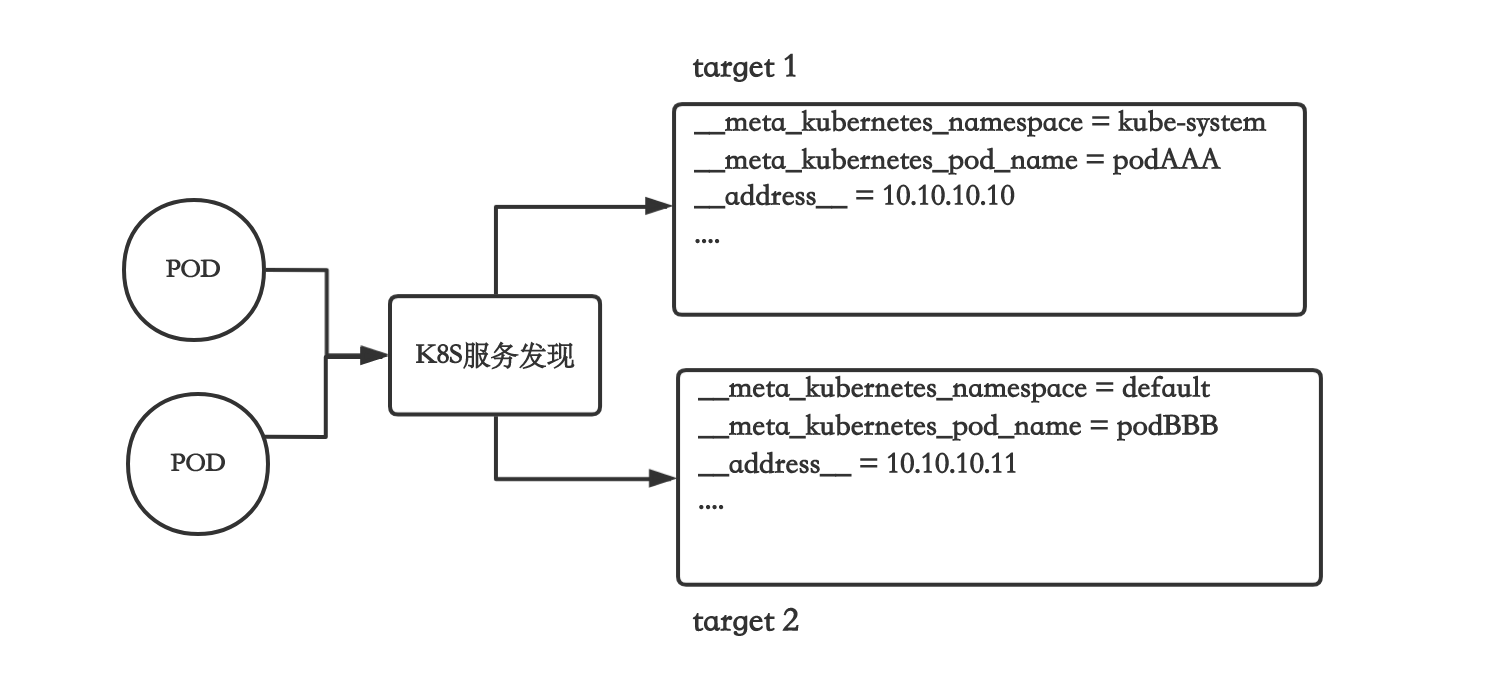
过滤Target
上边这些label非常有用,我们可以通过他们的值来过滤出我们要的Target。 在job的配置中有个relabel_config就是干这事的
下边这个例子就是过滤出Pod名字是test的Target,抛弃其他的。
- job_name: “test” relabel_configs: # 可以设置多个匹配规则 - action: keep # keep是保留匹配的,抛弃不匹配的,可写drop, drop就是抛弃满足条件的,留下其他的继续往下匹配 source_labels: - meta_kubernetes_pod_name # 目标label regex: “test” # 目标label的目标值,支持正则
上述例子的语义就是保留所有meta_kubernetes_pod_name为test的Target,其他全扔了,最终采集也只会采集这些保留的Target。
注意:这些匹配规则是可以写多个的。
重命名label
你肯定会问,上边那些label的命名挺香的,为什么要重命名,这是因为Prometheus有个潜规则。
Target中,所有以开头的label,不会保留到该Target所采集的指标中,而不以开头的label,会被加到所有从该Target采集的指标上。
另外有2个特殊的label会被加到指标上,一个是instance,它由address自动重命名过来,还有个job,它由Target所在的job的jobname转换过来。
正因为上边的规则,所以我们需要将想保留的label重命名一下,不要以开头,才能将其保留到实际的指标上去。
例如下边就是在所有采集的指标上加上pod_name这个label
- job_name: “test” relabel_configs: # 可以设置多个匹配规则 - action: replace # 从某个label中取值写入到另外一个label source_labels: - metakubernetespodname # 目标label,由于它是开头,默认就不会被保留 regex: (.) # 用正则从目标label的值中取值,. 表示取全部 target_label: pod_name # 新label的名字,它不是开头,就会被加到所有指标上 replacement: ${1} # ${1} 是上边正则中第一个括号的值
上边例子的语义就是从__meta_kubernetes_pod_name的值中匹配出(.*)并设置到名为pod_name的新label中取。
修改label的值
我们还可以修改Target的label值。为什么要修改呢,最典型的例子就是修改特殊label的值,例如通过修改address来修改采集Target时使用的url。
例如下边就是将采集的url的端口修改为8001
- jobname: “test” relabelconfigs: # 可以设置多个匹配规则 - action: replace # 从某个label中取值写入到另外一个label sourcelabels: - meta_kubernetes_pod_ip # 目标label regex: (.*) target_label: “address“ # 该值会被覆盖掉 replacement: “${1}:8001” # 现在address_就变成了 podIP:8001
上边例子的语义就是从meta_kubernetes_pod_ip的值中匹配出(.*),并将address设置成匹配出的值:8001。
服务发现(以k8s场景为例)
掌握了上边介绍了relabel_configs后,我们再来学服务发现,就会非常简单。 还记得吗,服务发现就是把采集对象全部转换成一个个的label集合,然后我们再通过前边介绍的relabel_config来过滤,修改Target。
Prometheus提供了大量服务发现的方式,其基本原理都一样,即把某些对象转换成Target,再通过relabel_config来过滤出想要监控的Target。
可以参考官方配置文件 寻找符合自己需求的服务发现机制,本文只介绍基于k8s的。
直接指定ip
最简单的服务发现就是在配置文件里直接写上你要采集的对象列表。
scrape_configs: - job_name: “test” static_configs: - targets: - 127.0.0.1:9091 # 采集对象列表 labels: node: node1 # 可以给采集到的指标加上默认的label
用label选择采集某些Pod
Prometheus自带k8s方式的服务发现,支持将Pod转化成上边介绍的label集合,也就是Target。 
这里特别要注意的是�,pod的所有k8s label会被转换成前缀是metakubernetes_pod_label的label。 由于Prometheus的k8s label的key不能包含一些特殊字符比如. / 等等,所以这些字符都会变成下划线_ 例如如果label是app.kubernetes.io **就会转换成meta_kubernetes_pod_label_app_kubernetes_io**
根据上边的特性,我们如果要过滤出包含app.kubernetes.io=test这样的k8s label的pod,就可以用以下配置
scrape_configs: - job_name: “job1” kubernetes_sd_configs: # 使用k8s服务发现 - role: pod # 发现的是pod,还可以是node,endpoint等 relabel_configs: # 可以设置多个匹配规则 - action: keep # keep是保留匹配的,抛弃不匹配的,可写drop, drop就是抛弃满足条件的,留下其他的继续往下匹配 source_labels: - __meta_kubernetes_pod_label_app_kubernetes_io # 对应k8s label是app.kubernetes.io regex: “test” # 目标label的目标值,支持正则
定义采集请求
前边我们介绍了如何过滤Target以及如何改label,那如何在配置文件里定义向Target发起采集时候的配置呢
修改采集的path
配置文件里有个metricspath
scrapeconfigs: - job_name: “job1” metrics_path: “/metrics” # 默认就是metrics
配置文件里的值会被设置到该Job的每个Target的__metrics_path这个label上,你也可以直接用relabel_config修改这个label来达到目的。
使用https请求
如何你的采集对象走的是https连接,就需要修改请求协议,最典型的就是采集apiserver的指标,一般都是https的。
scrape_configs: - job_name: “job1” metrics_path: “/metrics” # 默认就是metrics scheme: “https” # 默认是http
如果需要鉴权的话,有3种方式
修改和过滤采集到的指标
我们上边介绍了如何使用relabelconfigs来修改Target的label,那如果要修改最终采集到的指标所包含的label,或者我们要过滤指标掉一些指标,有没有办法呢?那肯定是有的。
Prometheus对指标的管理也是一个个的label的集合,而指标名,其实就是名为name的label。
例如 cpuusagetotal{node=”node1, cpu=”cpu0”} 1 {_name=”cpu_usage_total”,node=”node1, cpu=”cpu0”} 1 是同个东西
如果要过滤指标,那我们其实就是根据namelabel来做过滤不就行了吗,在配置文件中,我们用metric_relabel_configs配置来做这个事,他的配置方法和relabel_configs一模一样,唯一区别就是metric_relabel_configs是针对指标的,而relabel_configs是针对Target的。
例如我们只想保留指标名为cpu_usage_total 和 mem_usage_bytes的指标,就可以这么做
scrape_configs: - job_name: “job1” metrics_path: “/metrics” # 默认就是metrics metric_relabel_configs: # 主要和relabel_configs区分 - action: keep source_labels: - __name # 指标的名字 regex: “cpu_usage_total|mem_usage_bytes” # 使用了正则,只保留cpu_usage_total或mem_usage_bytes
检查采集是否正常
前面我们介绍了采集对象(Target)的概念,以及如何通过服务发现和relabel来过滤出,那如果判断我们的配置是生效,且采集是正常的呢?
查看up指标
最简单的方式是查一下某个你暴露的指标,有数据就说明采集成功了,如果没有数据,那就可以先看一个特殊的指标up。
Prometheus会为每个Target存储一条特殊的指标,叫up,它表示针对这个Target的采集是否成功,1表示成功,0表示失败,up会带有Target经过relabel之后label集合,最常用的例如job,instance等等。
你可以通过查看某个Target对应的up值,来判断采集是否正常。
查看Targets列表
如果你发现up不是0也不是1,而是没有任何数据咋办?
这就说明Target被过滤掉了,即采集配置里的relabelconfigs配置不正确,Prometheus提供了一个接口用于获得所有被采集的Targets和被过滤的Targets,如果采集失败,还可以看到上次失败的原因。
被监控的Target会放在activeTargets里,被过滤掉的会放在droppedTargets里
官方文档
$ curl http://localhost:9090/api/v1/targets { “status”: “success”, “data”: { “activeTargets”: [ { “discoveredLabels”: { “address“: “127.0.0.1:9090”, “metrics_path“: “/metrics”, “scheme“: “http”, “job”: “prometheus” }, “labels”: { “instance”: “127.0.0.1:9090”, “job”: “prometheus” }, “scrapePool”: “prometheus”, “scrapeUrl”: “http://127.0.0.1:9090/metrics“, “globalUrl”: “http://example-prometheus:9090/metrics“, “lastError”: “”, # 上次失败的原因在这里 “lastScrape”: “2017-01-17T15:07:44.723715405+01:00”, “lastScrapeDuration”: 0.050688943, “health”: “up”, “scrapeInterval”: “1m”, “scrapeTimeout”: “10s” } ], “droppedTargets”: [ { “discoveredLabels”: { “address“: “127.0.0.1:9100”, “metrics_path“: “/metrics”, “scheme“: “http”, “scrape_interval“: “1m”, “_scrape_timeout“: “10s”, “job”: “node” }, } ] } }
Target信息是没法从Grafana上查看的,如果你能直接登录Prometheus原生的web页面,则可以在这里看到。
最佳实践
不要把随机值放在label里
这里强烈建议不要把随机值,或者变化较快的值放在label里,如timestamp,request_args,thread_id等等,这是因为只要label的值一变,就会产生另外一个Series,而Prometheus或者类Prometheus的监控系统,都会把近期出现的Series信息缓存在内存中,如果短期内出现大量Series,可能导致系统OOM。
Tip 如果想记录一些经常变动的Label集合,应该使用日志系统,而不是监控系统。
指标名规范
Prometheus对指标的名称只做最基本的规则校验,并没有做规范校验,所以理论上你可以给指标取任何符合规则的名称,例如CPU的使用率,你可以叫XPUXXXX,但是这样会导致指标的含义非常不清楚,不仅不知道指标值的含义,也不知道单位,只有暴露指标的人指标这是什么鬼。
这里建议大家按以下规则来给指标取名。
服务名指标名称指标单位指标类型
例如
prometheus_http_requests_total
honor_timestamps配置有啥用
在job里有一项名为honor_timestamps的配置
scrape_configs: - job_name: “job1” honor_timestamps: true ….
这是做什么的呢?还记得吗,数据上报的格式里其实最后有个可有可无的时间戳。
指标{label集合} 这次的采集值 时间戳(可有可无)
honor_timestamps的作用就是告诉Prometheus要不要使用这个时间戳,如果设置成false,那Prometheus会忽略上报的时间戳,直接采用服务端当前的时间,这可能导致数据出现些许不精确,那总是设置为true不就行了?不行!
这是因为Prometheus存在一个名为Staleness的机制,导致honor_timestamps=true的采集配置才上来的指标,会在停止上报后继续在服务端保留5分钟,影响查询和聚合的准确性,我们将在下一章的最佳实践里详细解释这个机制的影响。
为了保持数据准确性,honor_timestamps应该尽可能设置为true。
查看你的数据(PromQL)
Prometheus真正牛逼之处就在于这章要介绍的PromQL了,它用于查询你上报上去的监控数据,不仅提供丰富的指标聚合能力,甚至还能支持类似关系型运算的操作!
基本概念
在学习PromQL之前,有几个非常非常关键的概念需要去理解一下,很多朋友配置PromQL的时候全靠试,报错也不知道为啥,本质原因就是没有理解这几个概念。
Instant vector
Instance vector表示一个Series集合,但是每个Series只有最近的一个点,而不是线。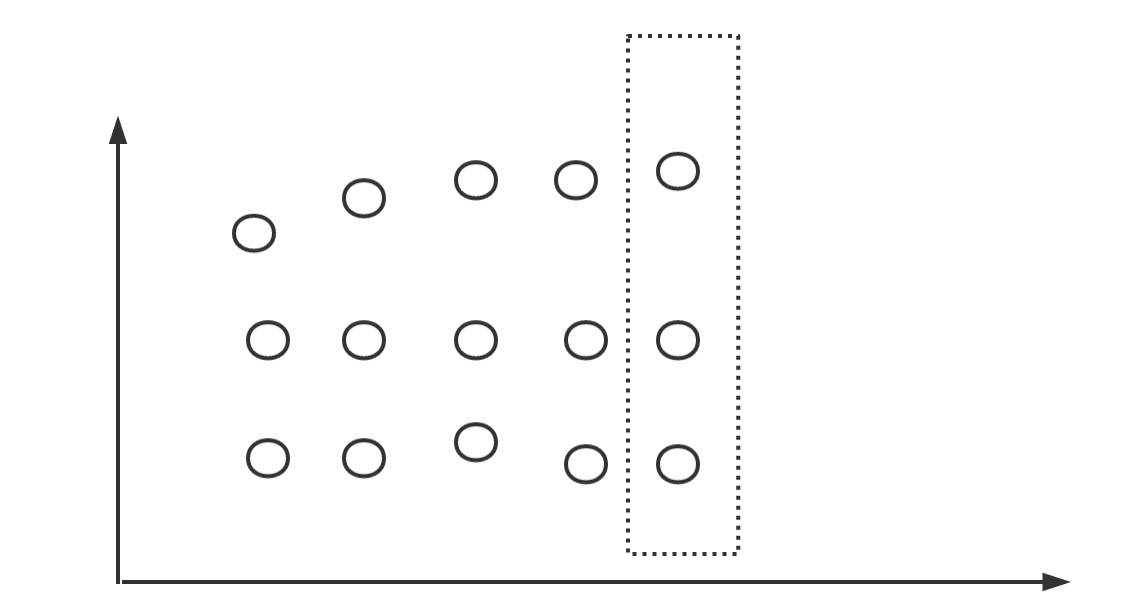
这样的话我们就可以将当前点的值也看成一个特殊的label,叫value,然后我们把Series的label key放横坐标,value放纵坐标,就可以变成一张类似关系型数据库里的表,每行是一个Series。
| name | node | cpu | value |
|---|---|---|---|
| cpu_usage | node0 | cpu0 | 1.1 |
| cpu_usage | node1 | cpu1 | 2 |
| cpu_usage | node2 | cpu0 | 3 |
Range vector
Range vector表示一段时间范围里的Series,每个Series包含多个点。
Range vector也可以表示成一张二维表,只不过需要把时间戳也加到表里,每行表示某个时间点下的某个Series。
| name | node | cpu | value | timestamp |
|---|---|---|---|---|
| cpu_usage | node0 | cpu0 | 1.1 | 00:00:00 |
| cpu_usage | node0 | cpu0 | 2 | 00:00:01 |
| cpu_usage | node1 | cpu0 | 3 | 00:00:00 |
Tip: 特别注意,Range vector 和我们看到的指标面板有本质区别,这个在后面会有解释。
Scalar
Scalar不是一个Series,而是一个数值,例如直接在语句里写个100,这就是一个Scalar,Prometheus提供了一个函数,可以将只有一个Series的Instance vector转换成Scalar。
可以看到Scalar是没有任何Label的。
简单的查询
Prometheus 有2个查询接口,我们先看第一个
GET /api/v1/query #某个时间点的瞬时数据,这数据有可能是Instant vector,有可能是Range vector,根据你的查询语句而定。
查询Instant vector
最简单的查询就是输入一个指标名称,例如
container_cpu_usage_seconds_total
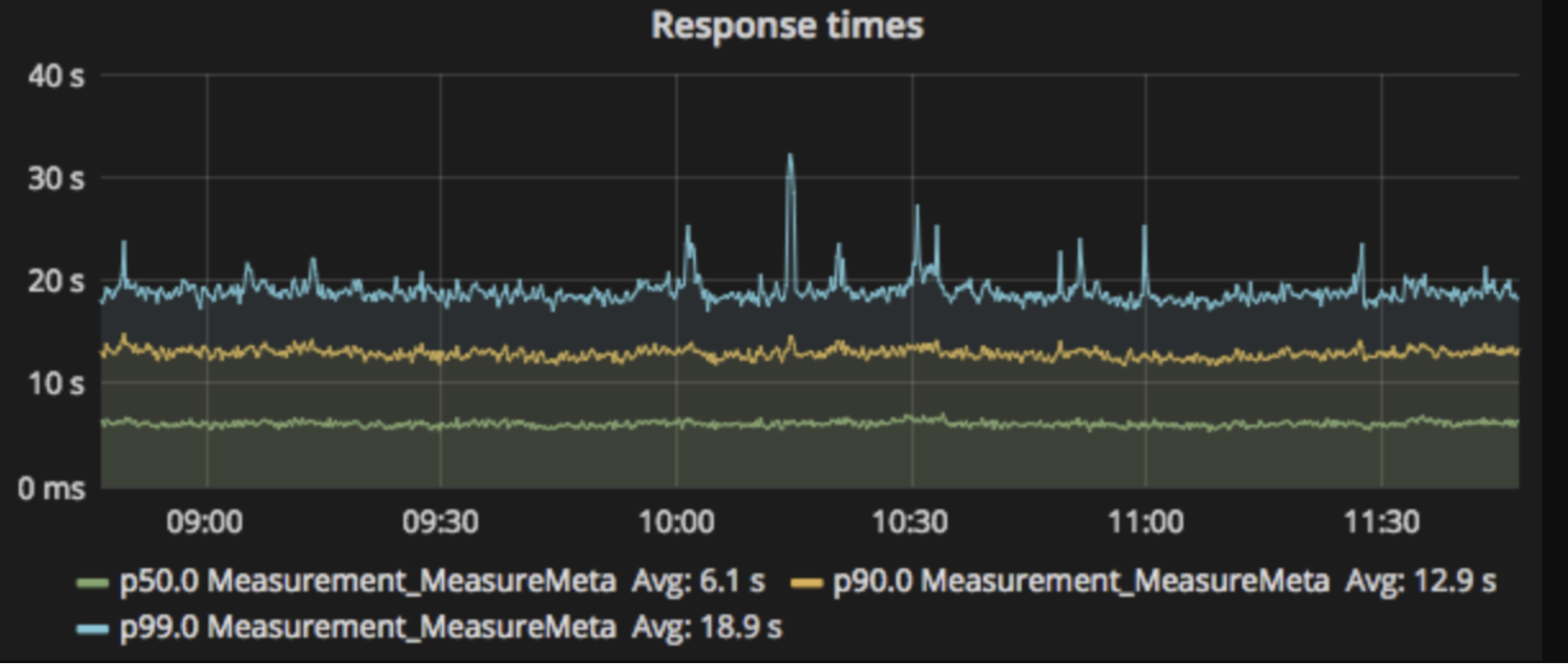
表示返回所有指标名为cpu_usage的Instant vector.
你也可以加上一些label来过滤出某个符合条件的Series
container_cpu_usage_seconds_total{pod=”csi-provisioner-66cf4d475-f4887”}
你还可以加上对数据大小的过滤,例如 > 0.1
container_cpu_usage_seconds_total{pod=”csi-provisioner-66cf4d475-f4887”} > 0.1
查询Range vector
我们也可以直接查Range vector,方法就是在指标后边跟上时间范围
container_cpu_usage_seconds_total{pod=”cls-provisioner-66cf4d475-f4887”,container=”cls-provisioner”}[1m] 
上边语句表示查询最近1m的Range vector,注意图中,Time是变化的,而不像Instant vector查询那样是固定的。
Tip: 为什么区分这2种vector呢,原因就在于后边介绍的聚合查询入参是有数据类型要求的
聚合查询
什么叫聚合?聚合就是针对查出来的Instant vector,Range vector做一些函数运算,得到新的Instant vector或者Scalar。
可见,聚合函数的输入可以是Instant vector,Range vector,但是输出只会是Instant vector或者Scalar
可以在官方文档查看所有的聚合函数,本文只介绍最常用的。
sum,avg,max等基本统计
这类函数先根据label将入参Instant vector进行分组,然后按sum,avg等方式统计组内Series,每个组输出一个新的Series,所有分组输出的Series合在一起重新构成一个新的Instant vector作为输出。
例如sum函数
sum(container_cpu_usage_seconds_total{}) 没有指定用于分组的label,则所有Series分为一组,即最终输出的Instant vector也只有一个Series,即所有container_cpu_usage_seconds_total指标值的合。
sum(container_cpu_usage_seconds_total{}) by(namespace) 按namespace这个label来分组,namespace一样的分到一起,即计算namespace相同的container_cpu_usage_seconds_total指标的合 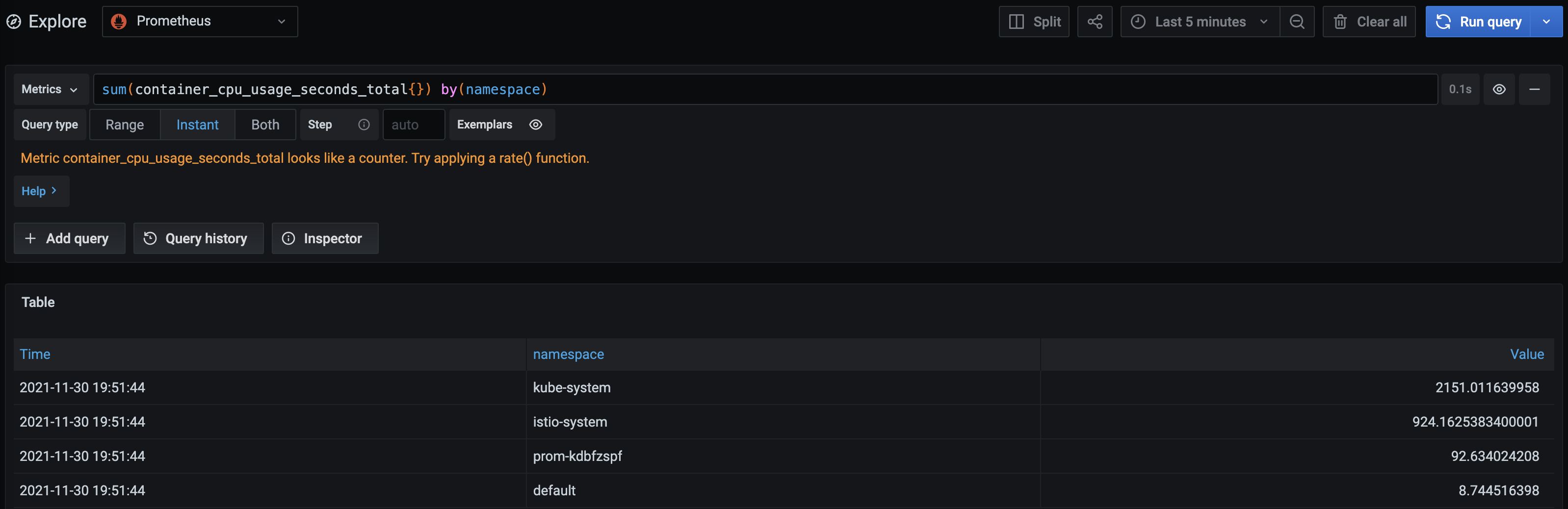
irate, increase等Range统计
这类函数入参都是Range vector,即一段时间范围的点,他们都是根据统计类型计算每个Series在此段时间范围内所有的点并获得一个点,计算完后,每个Series只会剩下一个点,作为当前时间戳下的数值,即Range vector计算完后会变成Instant vector。
例如irate,表示在Series所有点中,拿最后2个,计算增长率。
irate(container_cpu_usage_seconds_total{}[1m]) 还记得Range vector的查询方式吗,指标后边带上时间范围即可
由于这类函数都是针对每个Series计算的,不会对Series进行分组,所以不支持by这类分组关键字。
多重聚合
所有聚合语句的结果,要吗是Instance vector,要吗是Scalar。所以,聚合的结果还可以作为参数输入给入参是Instance vector的函数如sum这类。
例如
avg( sum(container_cpu_usage_seconds_total{}) by(namespace) ) 计算所有namespace的平均值
又例如
avg( irate(container_cpu_usage_seconds_total{}[1m]) )
值得注意的是,没法把聚合过的数据传给需要Range vector作为参数的函数,如irate,所以下边的语句是会报错的
irate(avg(container_cpu_usage_seconds_total{})) 
Binary operators
前面的聚合函数都是针对一个Instant vector或者Range vector的。我们前面提过,Instant vector实际上可以表示成一张二维表,那如果有2个Instant vector,那Prometheus就可以针对这2张表(即2个Instant vector)做binary operate,结果是一个新的Instant vector。
Prometheus支持如 +,-,,/,and, or等,更多可以可以参考官方文档
我们就以 为例,假设有A, B两个能得到Instant vector的语句(直接查,聚合都可)。
A B 取A中每个Series,在B中找到和它所有Label(不含指标名)的key和value都相等的Series,把他两的值相乘,作为A中那个Series的值,如果没找到,则抛弃这个Series。
特别注意!,如果在B中找到不止一个满足条件的Series,整条计算语句将报错,所以A对应的Series在B中需要有唯一性。
我们也可以指定只按某些label去匹配
A on(pod,container) B 取A中每个Series,在B中找到和它pod, container这2个label都相等的Series,把他两的值相乘,作为A中那个Series的值,如果没找到,则抛弃这个Series。
你如果试一下就会发现,用这种方式聚合出来的结果,label只有pod, container,其他label全没了,怎么才能保留A中的所有label呢,我们要加下group_left
A on(pod,container) group_left B 取A中每个Series,在B中找到和它pod, container这2个label都相等的Series,把他两的值相乘,作为A中那个Series的值,如果没找到,则抛弃这个Series。结果的label集合采用左边A的
还有最后一个问题,如果你希望把B中的一些label,附加到A原来的label集合里,用来扩展A原来的label集合,能做到吗?能!
A on(pod,container) group_left(mylabel1, mylabel2) B 取A中每个Series,在B中找到和它pod, container这2个label都相等的Series,把他两的值相乘,作为A中那个Series的值,如果没找到,则抛弃这个Series。结果的label集合采用左边A的。不仅如此,还会从匹配的B中Series上复制出mylabel1,mylabel2追加到结果的label集合上。;
从表格到面板
上边我们介绍了很多聚合函数,结果都只是Instant vector,但是我们往往需要生成指标面板,而不是一张表格。
Prometheus提供了一个range_query API,用于根据一个可生成Instant vector的语句,查询一段时间的结果。
GFT /api/v1/range_query?query=查询语句 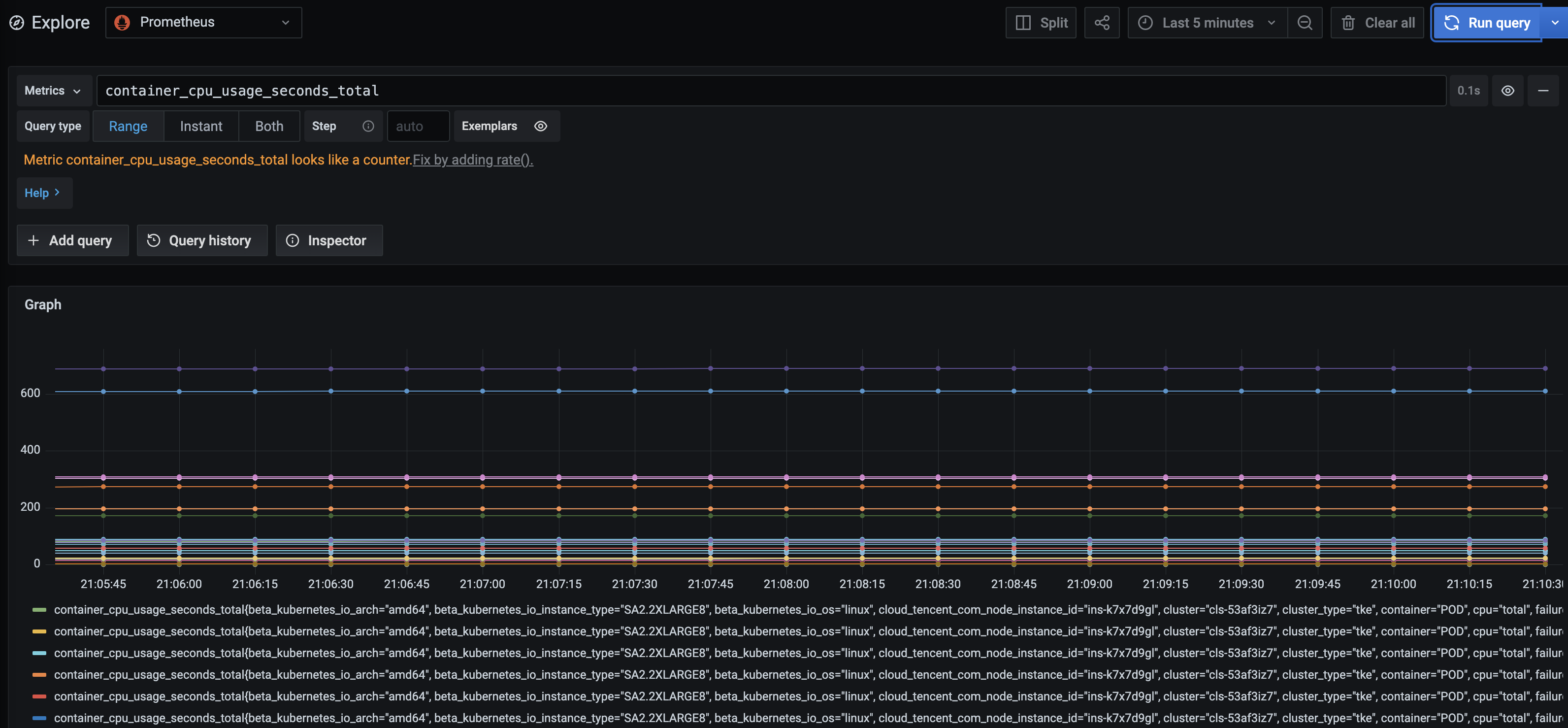
注意,它的核心原理是对给定时间范围内每个时间点,都执行一下查询语句,得到一段时间的Instant vector集合,所以range_query的查询语句结果只能是Instant vector或者Scalar,不能是Range vector。所以是不能输入类似cpu{}[1m]这类语句的,要通过前面介绍的聚合,聚成Instant vector或者Scalar。
最佳实践
注意格式,增加可读性
PromQL是会忽略所有空格换行的,所以如果你的查询语句非常复杂,嵌套了一层又一层的聚合,建议整理一下语句的格式。
例如
sum(irate(cpu_usage[1m])) by (pod) —-可写成—- sum( irate(cpu_usage[1m]) ) by (pod)
加速查询:用Recording rules
有些查询语句,特别是Range vector的计算,会非常消耗服务端的算力,一旦指标数多,或者查询的时间范围比较大,查询的速度就会很慢,因为要针对查询时间范围内每个时间点都执行一次查询语句的。
针对经常用的一些查询语句,应该使用Prometheus的聚合规则能力(Recording rules)。
Recording rules就是周期性得计算查询的语句,并将结果重新存储到系统中,命名为一个新的指标
groups: - name: example rules: - record: test_metrics expr: sum by (job) (http_inprogress_requests) 上述规则就表示,周期性得计算sum by (job) (http_inprogress_requests)这个语句当前结果,并把结果存储成新的指标,名字叫test_metrics 平时查的时候就直接查test_metrics这个指标,由于它已经是计算结果了,所以查询的时候,就不会再计算一次查询语句,查询速度非常快。
读者需要判断自己使用的监控系统是否支持Recording rules
honor_timestamps和Staleness
我们在前面提到过honor_timestamps,这个配置项用于Prometheus去决定要不要采纳上报上来的时间戳的,同时我们提到如果设置为true会收到Staleness机制的影响,那什么是Staleness呢?它对查询有啥影响呢?
我们假设查询的是T1时刻的Instant vector,那Series最后一个点的时间戳相距离T1多久能被认为属于这个Instant vector呢?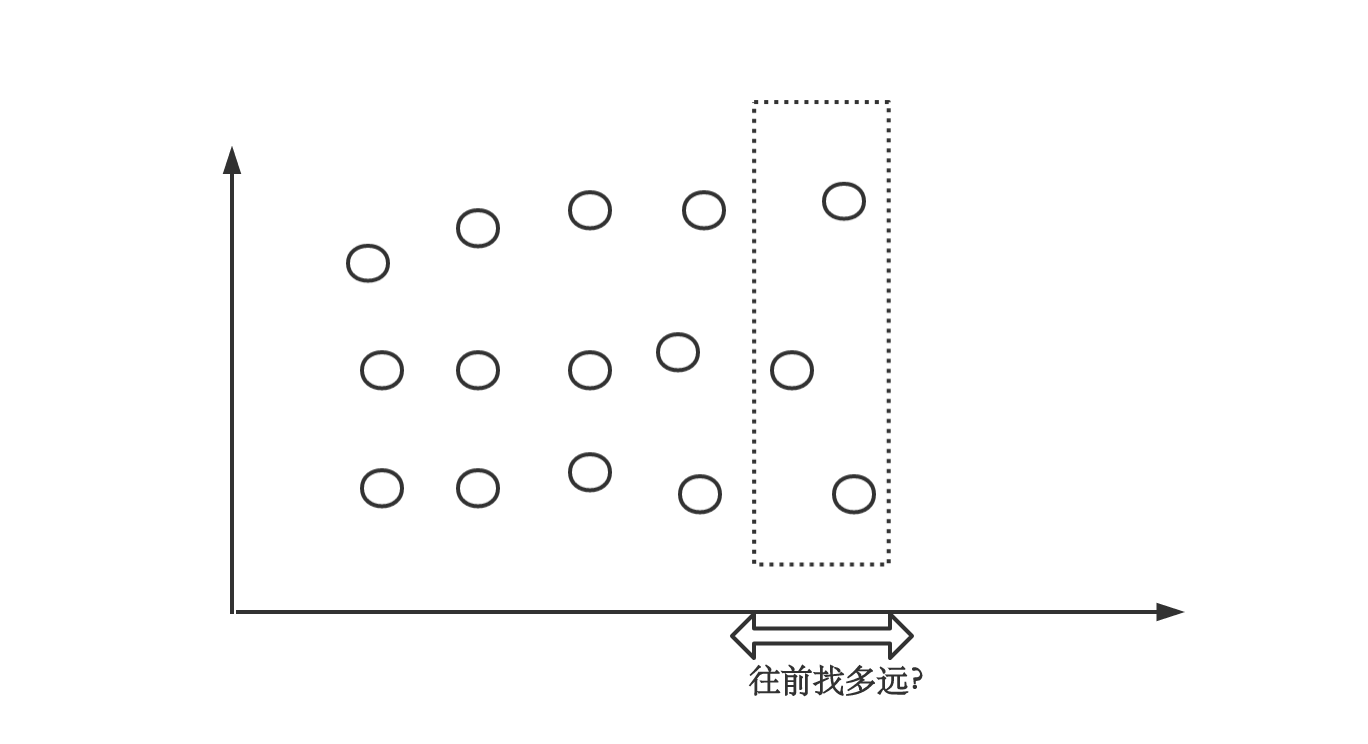
默认情况下是5m,也就是Prometheus会找5m内最后一个点,作为这次Intant vector的结果,但是这不就有个问题了吗,如果我有个Series最后一次上报是4m前,我现在也能查到数据了?更甚者,我sum一下也会把4m前的数据也给算进去,延迟也太大了吧。所以,Prometheus加了Staleness mark。
一个Series如果上次采集有数据,这次采集没有,会将其标志为Staleness,在查询的时候,如果最近的点是Staleness点,则认为Series已消失,不会放在结果集合了。
但是有个例外,如果honor_timestamps被设置为true,则该job采集到的指标都不会标记为Staleness,也就是4m前的点确实会被查到,从而影响查询和聚合的准确性,这就是为什么说honor_timestamps不能总设置为true,要视你查询诉求而定。
光速配置Grafana面板
Grafana是一个用来展示各种各样数据的开源软件,通常情况下我们都使用Grafana来实现对Prometheus数据的可视化。
基本使用
当我们登录Grafana之后,很容易就能找到新建Grafana面板的入口: 点击后会出现面板的配置页面,面板提供各种各样的样式和格式选项,目前支持四个面板类型:图像,状态,面板列表,表格。我们将从查询语句说起介绍如何获取指标值,如何进行标题和单位的设置,以及如何通过加入分割线来整理你的Grafana面板。
查询语句
每个面板都提供一个QueryEditor,我们可以通过在下图红色框内编写语句来控制面板展示不同的图表。
在上一小节我们介绍了PromQL的相关内容,这里就要用到啦,在红框内我们通过输入PromQL语句查询面板内想要显示的的内容。 支持在同一个面板内添加多个Query。
设置标题
设置单位
我们通过右边的Axes完成对横纵坐标的配置,即为我们想要显示的数据选择合适的单位。
在配置界面分Left Y(左Y轴)、Right Y(右Y轴)、X-Axis(X轴)。 2个Y轴主要用于在一副图例上展示2种度量单位数据,用左/右Y轴来区分(该功能需结合Add series override使用),如左Y轴展示CPU使用百分比,右Y轴展示内存使用百分比。基础使用中我们可以关掉右Y轴。 X轴默认是时间轴,表示数据按时间显示(例如,按小时或分钟分组)。除此之外还支持序列(Series)和直方图。 在Unit中,IEC是以二进制进行计算的,即1024KB = 1MB,所以磁盘、内存我们可以使用IEC中的单位。对于Rate类型的数据我们选择Percent进行显示。 以红框中的Y轴为例,Unit用来配置Y值的显示单位,Scale用来配置Y值的刻度,默认是线性的。 Y-Min定义最小的Y值,Y-Max定义最大的Y值。(默认均为自动) Decimals用来控制Y值显示小数点的位数。 Label用来设置横纵坐标的名称。 通过取消Show中的相应框,可以隐藏坐标轴。
配置Thresholds
Thresholds允许向面板中添加任意的直线或分段,以便在图表跨越特定阈值时更容易查看。我们可以依据需求在面板内更改背景或值的颜色,来对不同的区域的值进行区分,进一步提升数据可视化体验。 比如当我们定义一个Threshold规则,如果CPU超过50%的区域显示为warning状态,则可以添加如下配置: 此时面板中y值为0.5的位置会显示一条阈值分割线,所有高于该阈值的区域会显示为warining状态,我们可以通过可视化的方式直观看到超过阈值的数据。
最终可以得到类似的面板。
加入变量
Variables变量提供了动态获取面板值的功能。设置成功的变量会以下拉菜单的形式显示在Dashboard的顶部,当变量发生改变时Dashboard中所有依赖该变量的数据都会进行动态的变更,我们可以通过选择下拉菜单中不同的变量值,来动态查看该变量对应的面板信息。
在哪里设置变量呢?我们需要打开General Setting页面,选择Variables菜单并点击New来进行新变量的配置。
图中新增的变量对于划线路径的Dashboard生效,即对当前路径下的所有面板有效。
创建变量
在这里我们主要介绍几种常用的变量: Query类型是我们最常用的类型,他的可选值可通过查询语句生成,我们最常用的就是通过label_values来生成
label_values(metrics_name{}, label_name) 获取label_name的所有可能值
例如我们想出现一个可以选所有pod的下拉框
可以创建一个名为pod的变量,然后Query使用label_values来动态生成可选项,例子中就是从container_cpu_usage_seconds_total这个指标的pod这个label获得所有可能的值作为可选项。
变量的依赖关系
我们先选择Pod,然后希望第二个变量能出现这个Pod所有的container,也就是如图的2个下拉框该怎么做?
在变量的label_values中可以引用其他变量,我们可以创建第二个名为container的变量,在Query语句中加入label过滤,只看目前pod变量所选中的。
要注意的是变量有顺序,只能引用排在前面的变量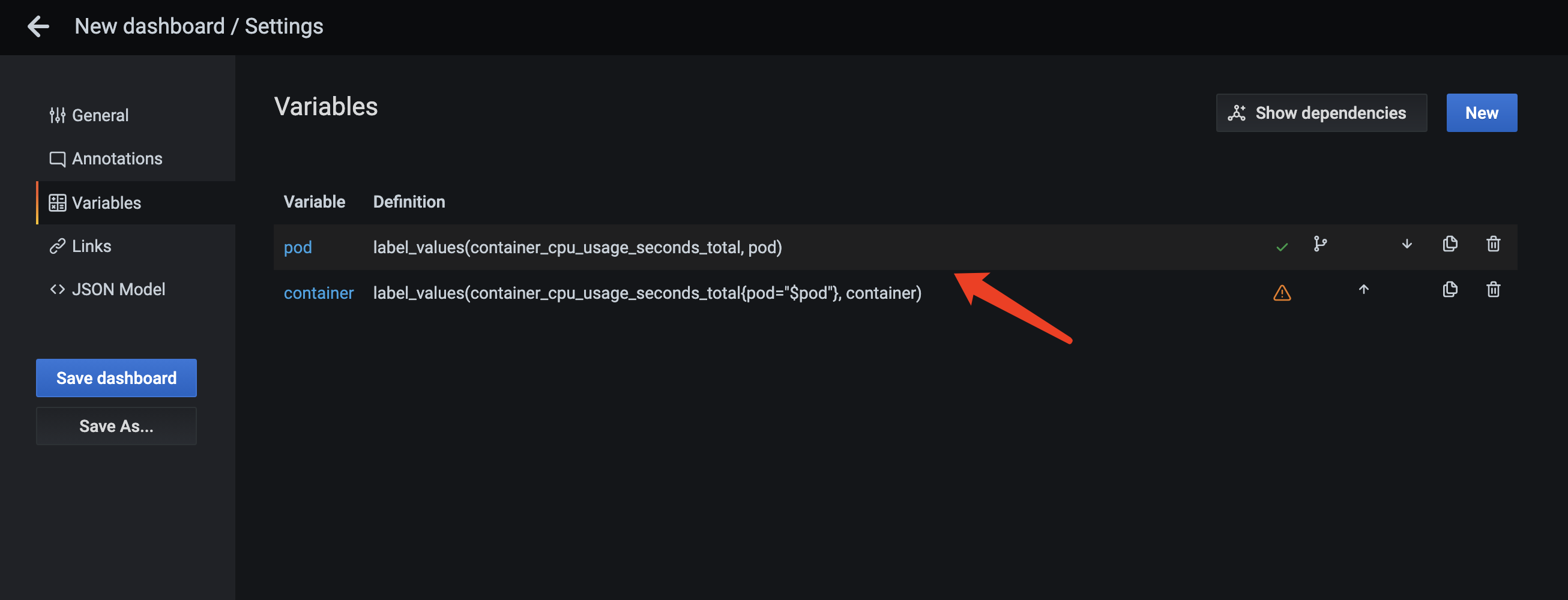
支持ALL和多选
我们也可以支持ALL和多选。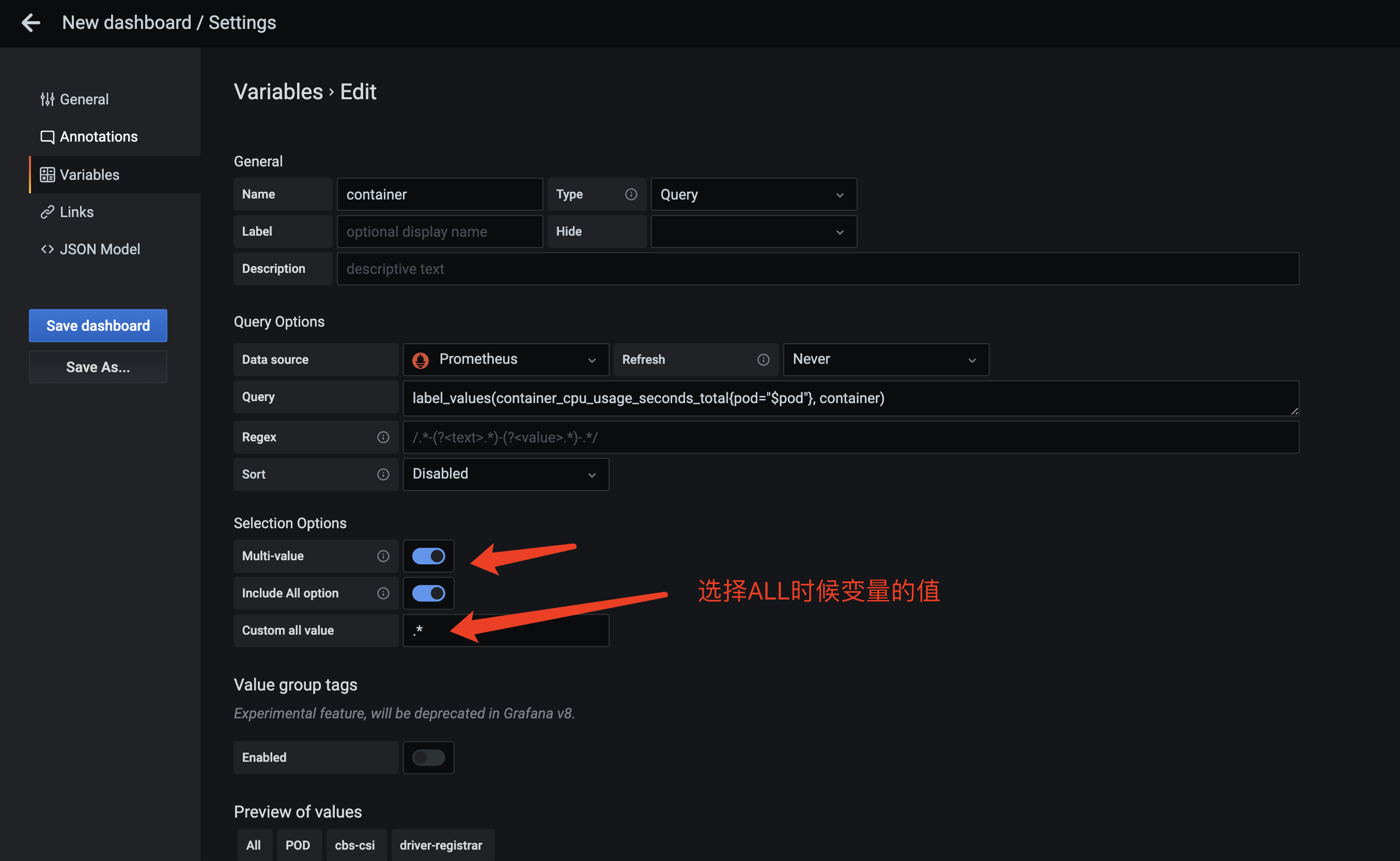
这里我们为什么设置ALL时候变量的值是.?因为Prometheus可以用=~来做label的正则匹配,.表示匹配全部,当我们使用变量的时候,就可以写
label=~”$container” 相当于 label=~”.*” 这不就是选择全部吗
查询语句中使用变量
有了变量,我们就可以在面板的查询语句中引用,从而让面板根据变量的变化,展示不同的对象的指标。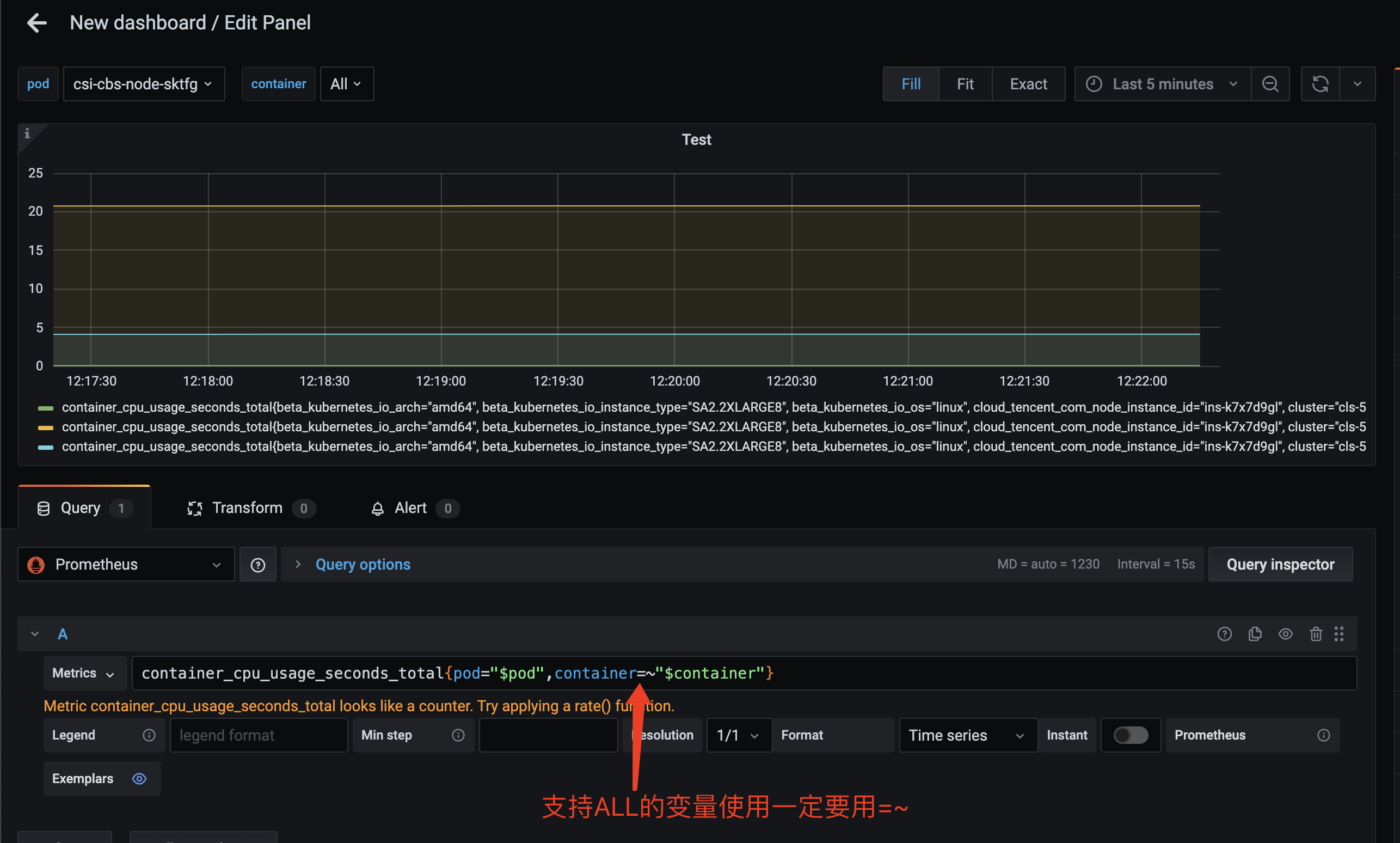
使用表格
配置表格
在部分场景下,针对那些只关注当前值的情况,表格是更好的可视化方式,这一小节我们介绍如何配置一个Grafana表格。 首先,按需求填写PromQL语句获取数据,在 Query中设置Format为Table,并打开 Instant。 然后,展开右侧Panel中的Visualization,并选择Table.
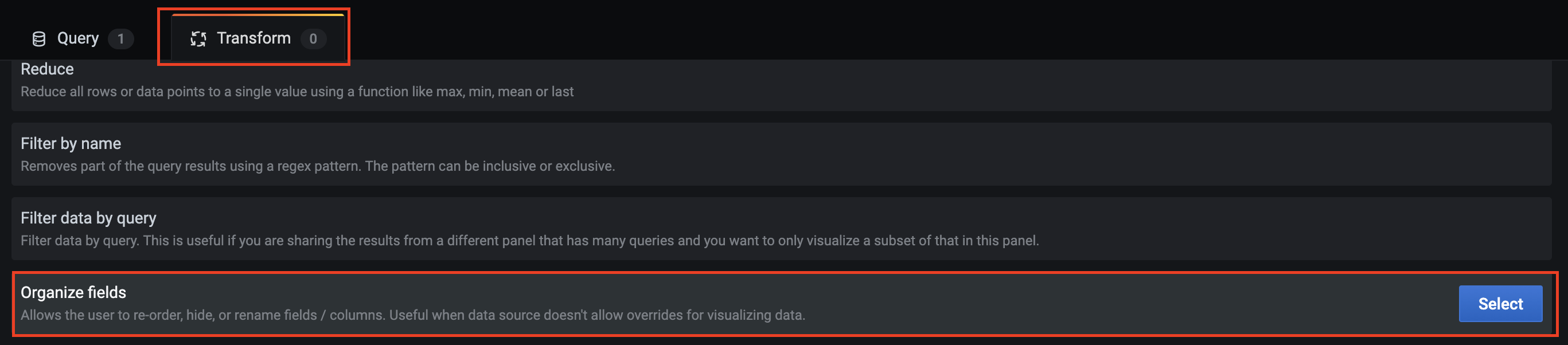
接着,打开Transform中的Organize fields,可以对表格字段进行整理,比如重命名表头,或隐藏不显示的列等等。
接下来我们通过Field tab来设置Cell display mode 和Unit.比如在Custom options中设置列宽,单元格显示模式等,在Standard options中对Unit进行设置,在Thresholds中设置阈值来分割或标记表格。
表格项加入超链接
我们可以通过在表格项中加入超链接完成数据的跳转,比如在统计分析表的某一列中插入对应的趋势图信息url,点击url可以直接跳转到趋势图中。 要实现这一功能,我们需要将自定义变量与Datalink结合使用。具体操作方式如下: 1.配置一个url变量,该变量用于动态得到请求的图; 2.利用配置的url变量生成想要链接跳转的图; 3.给当前图表添加一个links; 在Overrides选项卡下选择想要插入url的列名(下图列名为url,可以在Transform中的Organize fields中对已有列名进行重命名),并点击Add override property选择Data link: 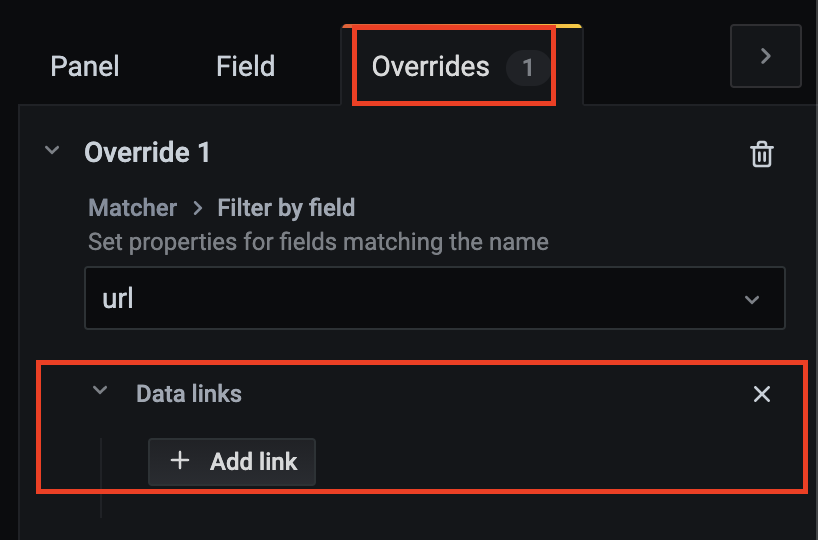 点击Add link按钮,在页面中输入Title和实际的url地址,即我们前面设置的想要跳转的图在Dashboard中所在的地址,该地址支持变量调用。
点击Add link按钮,在页面中输入Title和实际的url地址,即我们前面设置的想要跳转的图在Dashboard中所在的地址,该地址支持变量调用。 4.点击保存即配置完成。
最佳实践
导入导出面板
导入导出功能方便不同Grafana之间进行面板的复用,您也可以在Grafana官网下载现有的模板,只需少许更改即可展示自己的数据。 可以通过如下方式在Grafana进行面板的导出,即导出成为文件格式进行面板的分析。 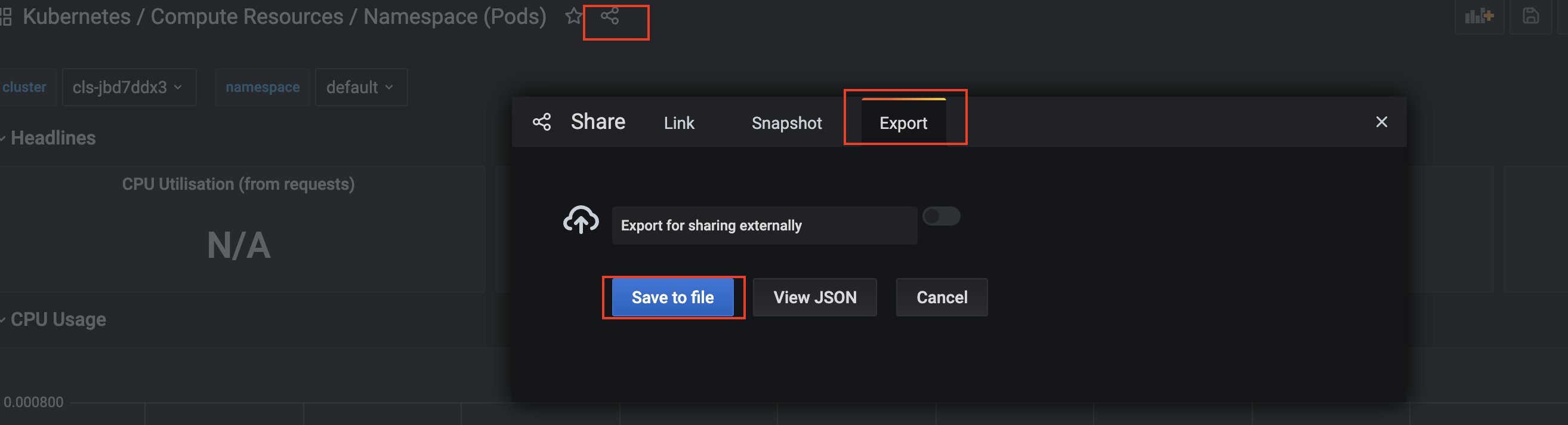 当你拿到其它的面板文件或模版文件,也可以通过导入功能将文件导入到Grafana。
当你拿到其它的面板文件或模版文件,也可以通过导入功能将文件导入到Grafana。
整理你的面板
在整理面板之前我们先来明确几个概念:
- Dashboard(仪表板):是由一行或多行的面板组成。仪表板可以看做一个展示单元(栏目),该单元由一行或多行组件构成,每行又可以由一个面板或多个面板组成。
- Row(行): 仪表板内的逻辑分隔符,用于将面板组合在一起。一行里可以有一列或多列面板。
- Panel(面板):Grafana 的可视化构建块,所有的数据展示都是在面板上实现的。
使用row管理多个panel
通过设置仪表板中的Row可以按照需求对面板进行分割和重新组合,将那些想要进行对照查看或联系较紧密的面板放在同一个Row中,即可以通过Row来组织和管理一组相关的Panel,从而提升我们的可视化体验。
点击Add Panel图标,在弹出的页面中选择Convert to row:
点击Convert to row后会生成新的行,点击新生成行旁边的配置图标,可以对用来分割面板的行进行命名: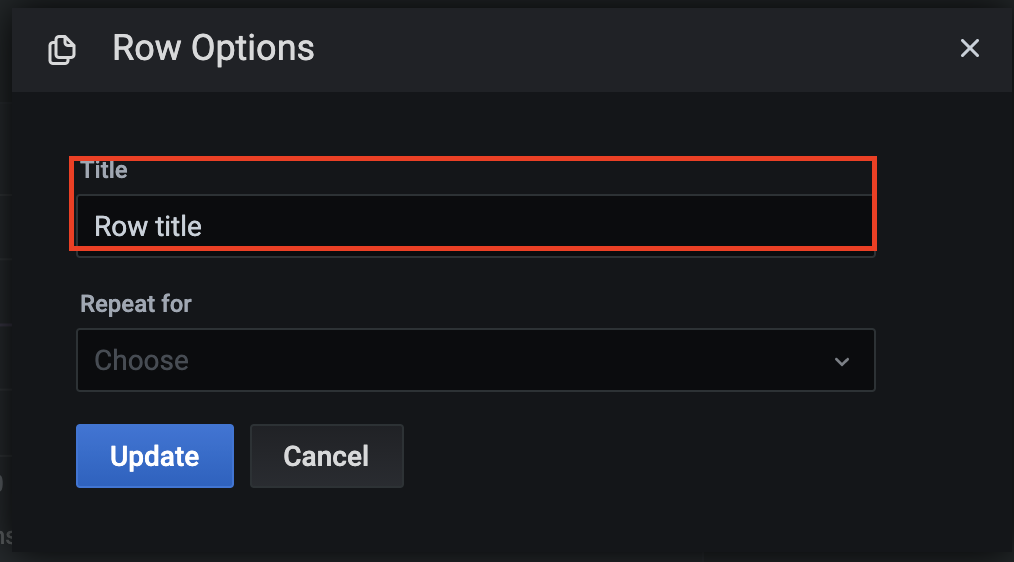
接下来只需要将已有的面板或新建的面板直接拖动进相应的行即可。
可以关闭,展开某个Row下的所有面板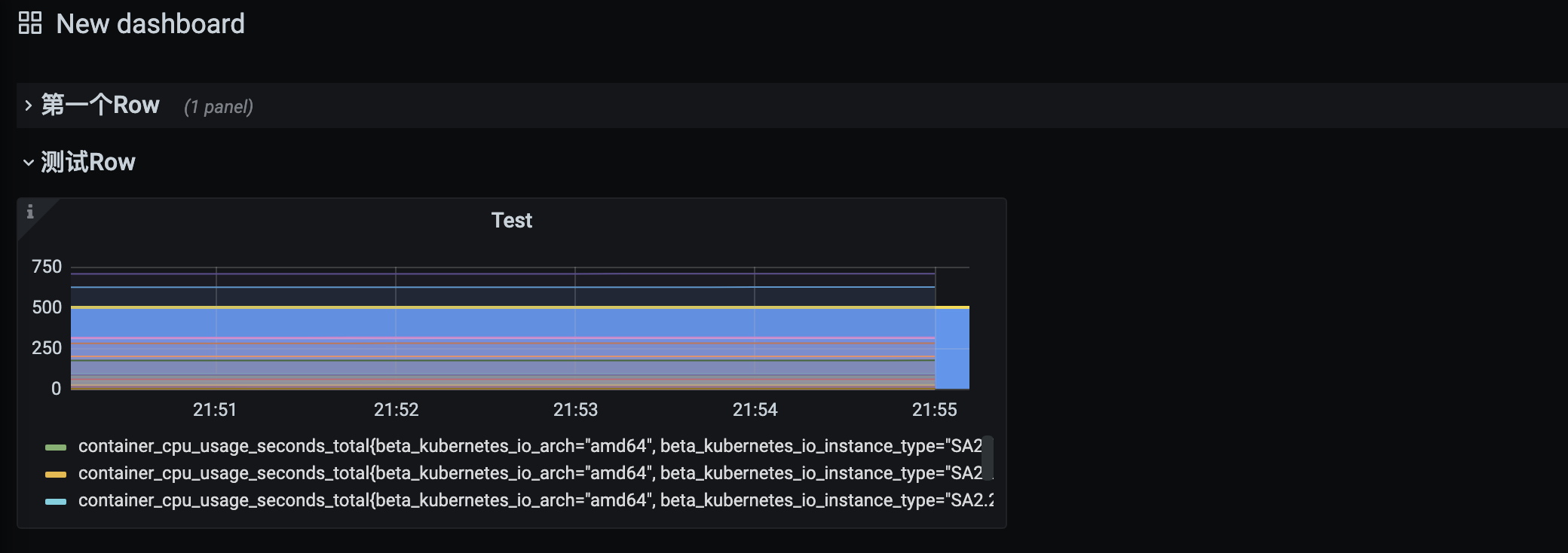
将Dashboard整理到目录
当我们有很多个Dashboard的时候,Grafana支持我们将Dashboard整理到不同的目录中。
首先我们需要新建目录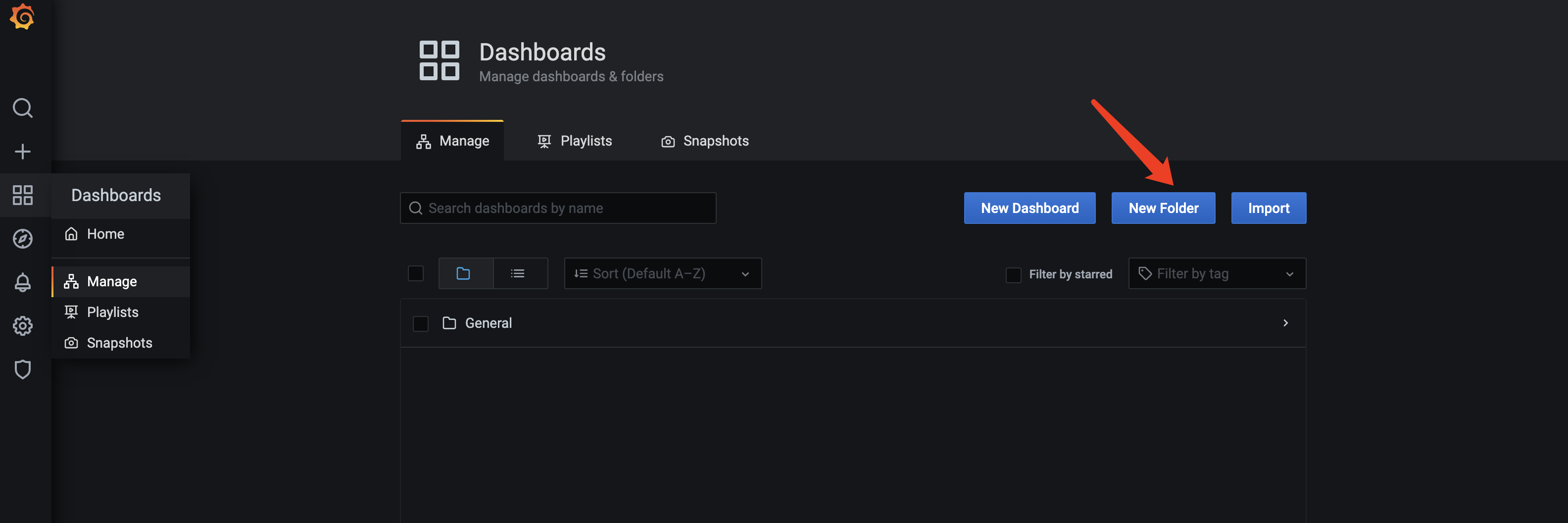
然后可以在Dashboard的Setting里,设置归属于哪个目录
总结
本文首先介绍了服务如何暴露Prometheus格式的指标,如何配置Prometheus来采集指标,之后介绍了PromQL的一些核心概念,常用的几种聚合函数类型,Binary operators以及多重聚合,最后还介绍了Grafana的基本使用和常用技巧。本文对还分享了一些笔者工作中总结的一些最佳实践,供读者参考。

若有收获,就点个赞吧
0 人点赞
