内容信息(例如商品属性)和初始用户评分对于抓住用户对新商品的偏好都非常有价值。但是,用于项目冷启动问题的先前方法要么1)将内容信息合并到协同过滤中以执行混合推荐,要么2)在不考虑内容信息的情况下主动选择用户以对新项目进行评分,然后进行协同过滤。本文通过主动学习和物品属性信息,为物品冷启动问题提出了一种新颖的推荐方案。具体来说,我们根据商品的属性和用户的评分历史来设计有用的用户选择条件,并将这些条件组合到优化框架中以选择用户。通过利用反馈评分,用户以前的评分和商品的属性,我们可以为其他未选中的用户生成准确的评分预测。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | FMFC-DB |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Recommender Systems, Active Learning |
| 4 | 核心内容 | 物品冷启动问题 |
| 5 | 论文PDF | 2019TKDE-Addressing the item cold-start problem by attribute-driven active learning.pdf |
| 6 | GitHub代码 |
二、研究背景
在本文中,作者将重点放在项目冷启动问题上,对于尚无评分的项目需要进行推荐。在以前的方法中,利用内容信息(例如项目属性)来解决此类问题。但是,对于同一用户,具有相似属性的商品可能会有不同的兴趣。如图1所示(数据是从IMDB1收集的),电影Taken在发行后受到很多人的青睐,平均收视率等于8.0。当后续电影Taken 3于2014年首次发行时,它可以看作是一部“冷”电影。由于这两部电影的类型,编剧和许多演员都是相同的,因此,如果我们利用电影属性来执行混合推荐,那么我们可能会将这部“冷”电影推荐给以前喜欢Taken的用户。但是,从图中可以看出,Take 3的总体评分的峰值下降到了6,这意味着许多用户可能会偏爱Taken,但对Taken 3的评价却较低,即向之前喜欢Taken的用户推荐Taken 3可能不准确。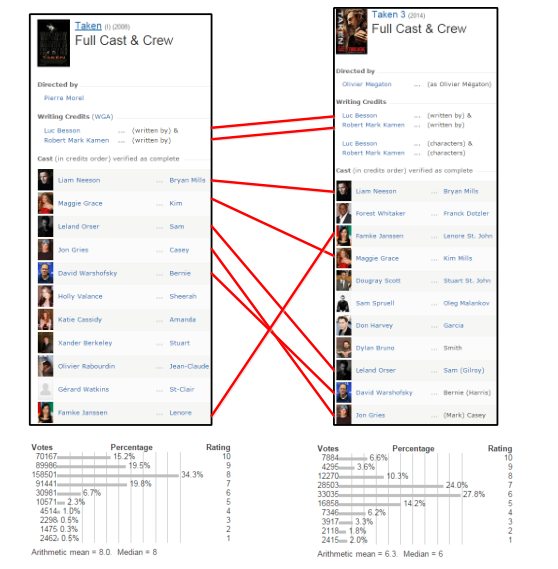
因此,这种仅基于电影属性来处理冷启动问题的方法并不准确。一种自然的解决方案是首先选择一小部分用户观看这部“冷”电影,其反馈可以使我们对用户对这部“冷”电影的偏好有更多的了解。然后,我们可以执行更准确的推荐。有趣的是,这类似于机器学习文献中主动学习的关键思想。
将主动学习应用于推荐系统的大多数作品都集中在用户冷启动问题[5],[6],[7]上。新用户的喜好通常是通过直接采访新用户感兴趣的内容,或要求他对精心构建的种子集中的几项进行评分。种子集可以根据受欢迎程度,竞争程度和覆盖范围来构建[6]。这些构造的种子集中的项目将由每个新用户进行评分。但是,商品的冷启动问题有所不同,因为无法采访商品,并且通常没有用户愿意对每个新商品进行评分。因此,我们需要构建不同的用户集来对不同的新项目进行评分,以确保不总是选择同样的用户进行评分请求。另外,必须仔细构造每个新项目的用户设置,以便在给定数量的评分请求的情况下,我们可以尽可能多地了解新项目。
但是,通过主动学习来解决物品冷启动问题,已经进行了有限的工作。 [8],[9]使用主动学习的想法,但忽略了项目的属性信息。同时,他们根据有限的条件选择用户。实际上,新商品的属性使我们对该商品有所了解,可以用来改进我们的用户选择策略。例如,我们倾向于选择喜欢新项目中现有属性的用户,因为这些用户更愿意给出评分。
在本文中,作者提出了一个针对项目冷启动问题的新颖推荐框架,该框架利用项目的属性来改进推荐系统中的主动学习方法。
三、传统方法
The Item Cold-start Problem
为了解决项目的冷启动问题,一种常见的解决方案是通过组合内容信息和协同过滤来执行混合推荐[15],[16],[17],[18]。在[15]中提出了一种基于回归的隐变量模型,以解决存在物品特征时的冷热物品推荐。项目的隐因子是通过低秩矩阵分解获得的。 [17]解决了凸优化问题,而不是矩阵分解,以改善这项工作。 [16],[19]中提出了另一种基于Boltzmann机器的方法来解决项目的冷启动问题。LCE [20]利用数据的流形结构来改善混合推荐的性能。其他作品则处于不同的设置下,其中几乎没有新项目的评分,但不知道任何项目的属性信息。 [21],[22]使用评估者的隐因子的线性组合,通过评估者的权重来估算新商品的隐因子。
Active Learning in Recommender Systems
推荐系统中大多数主动学习方法着眼于用户冷启动问题,他们在其中选择要由新注册用户评分的项目[4],[23]。我们简要介绍这些方法,因为大多数方法也可以适应我们的新项目任务。流行度策略[7],[24]和覆盖率策略[24]是两种基于注意力机制的代表性方法,其中前一种选择用户经常评价的商品,后一种选择高度合作的商品与其他物品一起评分。减少不确定性的方法旨在减少评分估计[13],[14],[24],模型参数[25],[26]和决策边界[27]的不确定性。减少错误的方法尝试通过以下两种方法之一来减少测试集上的预测误差:1)优化训练集[7],[24]或2)的性能指标(例如最小化RMSE)或直接控制影响预测误差的因素在测试集[28],[29]上。 [30]使用一些初始评分在非属性的情况下进行个性化的主动学习。也有组合策略[13],[31],[32]同时考虑多个目标。当应用于我们的新项目任务时,其中一些研究需要对新项目进行一些初始评分,而这些评分在我们的任务中不可用。其他研究不需要初始评分,但无论内容信息如何,都可以进行主动学习。但是,新项目的内容信息使我们对新项目有所了解,我们可以利用它来更好地进行主动学习。另外,诸如流行度策略[7],[24]和覆盖率策略[24]之类的方法总是选择同一组用户,这对用户体验产生了负面影响。 [8],[9]的工作还解决了主动学习方案中的项目冷启动问题。但是,它们都专注于纯协同过滤模型,也不考虑内容信息。
The Exploitation-exploration Trade-off
一些研究还考虑了E&E之间的权衡[13],[14]。许多有前景的解决方案来自对多臂老虎机问题的研究[33]。这些解决方案的关键思想是,根据现有知识(即开发)和通过这些决策(例如探索)将获得的新知识,同时优化一个人的决策,以最大程度地通过一系列行动获得回报。 α-Greedy算法[34]选择概率为1-α的具有最佳估计平均回报的手臂,否则随机选择另一手臂。类似于UCB的算法(UCB指的是上限置信区间)[35],[36],[37]首先计算所有分支的置信区间,然后选择具有最大置信上限的分支。值得注意的是,具有较高平均回报(开发)和高不确定性(探索)的臂将具有较大的置信区间上限。汤普森采样算法[38],[39],[40]首先计算每个臂的平均奖励的概率分布,然后从每个分布中提取一个值,最后选择绘制值最大的臂。我们的任务和多臂老虎机问题有一些共同的特点,例如两者都在考虑开发与开发之间的权衡。但是,它们之间存在一些关键差异。在多臂老虎机问题中,一个接一个地选择臂,并在选择每个臂后立即产生奖励。因此,许多解决方案(例如类似UCB的算法,汤普森采样算法)都是基于先前的奖励来设计其选择策略的。但是,在我们的设置中,在不知道其他用户反馈(奖励)的情况下,同时选择了一批用户,因此无法应用多臂老虎机问题的许多解决方案。
四、模型任务
五、主要思想
基本基础
属性驱动的主动学习思想有四个特征:
- 明确区分1)用户是否将对新项目进行评分,以及2)用户将对新项目进行何种评分。前者可以帮助我们选择愿意为新商品评分的用户(反馈评分)。后者使我们能够利用评分分布来改善选择策略。例如,我们希望选择提供不同评分的用户来生成无偏预测。这很容易理解,因为如果我们选择均给出高评分的用户,那么经过训练的预测模型将为所有其他用户生成高偏差评分,尽管其他用户可能根本不喜欢新商品。
- 个性化选择策略,确保公平。作者基于四个准则构建用户选择策略,其中两个是个性化标准。个性化标准可确保对于具有不同属性的新商品,我们的方法选择的用户将有所不同。这样可以避免选择同一用户来对每个新项目进行评分,这会对用户体验产生负面影响。这些标准被统一建模为整数二次规划(IQP)问题,可以通过一些松弛有效地解决。
- 动态主动学习预算。在先前的主动学习研究[9],[10]中,新项目的主动学习预算(即为评分请求选择的用户数量)是固定的。但是,在实际应用中,1)一些新商品受到一小部分用户(不受欢迎)的注意,例如演员和导演不受欢迎的电影,以及2)显然,几乎所有用户(受欢迎且无争议)都喜欢某些电影,例如哈利·波特与死亡圣器:第22部分,而3)其他语言很受欢迎,但有争议,推荐者不确定用户对它们的偏好,例如尽管Taken 3很出名,但以前由其主要演员表演的电影的质量却有很大差异,因此很难预测用户对Taken 3的偏好。在第三种情况下,需要更多反馈评分的项目才能了解更多。动态主动学习预算,可以有限地分配有限的主动学习资源,从而可以提高整体预测准确性。
- 考虑E&E问题其权衡。传统的主动学习方法旨在最大化在预测阶段[11],[12]中未选择的实例上测得的性能,而与主动学习阶段中的成本无关,因为它们假定每个实例的标记成本相同。但是,在我们的主动学习阶段,我们希望为愿意对商品进行评分的用户而不是对不愿意进行评分的用户提供评分请求,因为后者会给用户体验带来负面影响。作者试图通过平衡exploitation and exploration来最大化报酬的总和。我们任务中的奖励包含两个部分,即分别处于主动学习阶段和预测阶段的用户体验。通过利用图3(b)中训练的模型中的“现有知识”(开发),我们能够选择愿意的用户在主动学习阶段中获得良好的用户体验。为了获得预测阶段的用户体验,我们希望尽可能多地学习未选定用户的偏好的“新知识”(探索),以便为他们生成准确的评分预测。请注意,选择最能满足开发需求的用户可能对探索没有最大帮助。因此,我们任务中的“开发/探索的权衡”在于我们如何优化用户选择策略,以便在主动学习阶段和预测阶段都获得相对良好的用户体验。我们的方法既考虑了这两个目标,又可以通过调整参数设置来进一步权衡这些目标。
因子分解机(FM)是用于隐因子模型的最新框架,该模型可以包含丰富的功能。FM可以对x的D个特征之间的任意顺序的嵌套特征交互进行建模。对于最多2阶的特征交互,它们的建模方式如下: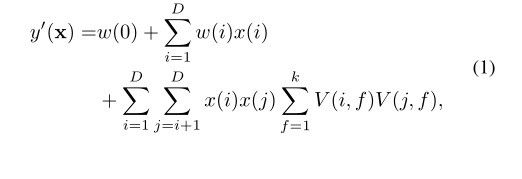
在我们的任务中,我们需要预测1)用户对某项商品的评价,以及2)用户是否对某项商品进行评价。为了使回归任务预测用户将对项目给予的评分,特征可以包含用户,项目和项目的属性,而标签即为评价。等式(1)中右侧的第一项是系统的偏差。如果w(0)大,则可能偏向于高评分值,这可能是由于系统设计的良好用户体验所致。第二个术语是一元特征的偏差,也就是说,一些乐观的用户倾向于对每个商品给予较高的评分,而某些受欢迎的物品或具有受欢迎属性的物品总是会获得较高的评分。最后一项是特征交互的偏差。许多用户只对他们真正感兴趣的某些项目(或具有某些属性的项目)给予很高的评价。对于分类任务以预测用户是否会对项目进行评级,等式(1)中每个术语的分析是相似的,除了标签现在代表用户是否对商品评分。
选择用户对新物品评分
如3.1节所述,我们首先需要仔细选择用户以对新物品 进行评分,以便尽可能多地了解。根据以下四个准则来选择用户。
进行评分,以便尽可能多地了解。根据以下四个准则来选择用户。
- 选定的用户极有可能评价。可以将其建模为分类任务。如图3(b)所示。
- 所选用户的潜在评分是多种多样的。潜在评分是用户根据的属性进行的不准确估计的评分(没有反馈,因为还没有反馈)。我们希望所选用户的潜在评分是多种多样的,因此:1)所选用户倾向于有不同的兴趣。与类似用户的评分相比,这些用户的评分将提供更多信息,并且2)根据这些用户的反馈训练的最终预测模型不会偏向固定的评分范围。为了选择具有不同潜在评分的用户,我们首先训练基于R和T的回归模型,如图3(c)所示。
- 所选用户生成的评分是客观的。对某项产品的评分是客观的,这意味着该评分近似于该项目所有评分的平均值,可以很好地评估该项目的质量[46],[47],[48]。我们倾向于选择过去总是产生客观评分的用户。然后,它们也有望产生的客观评分。
- 所选用户具有代表性。选定用户具有代表性,意味着该用户类似于未选定用户。选定的用户应具有代表性,以便从他们的反馈中可以了解有关未选定用户的偏好的更多信息。
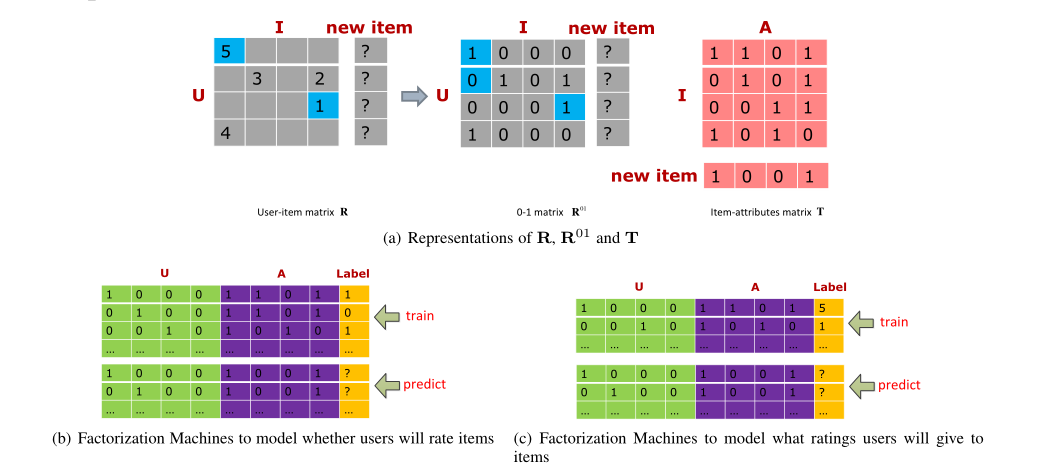
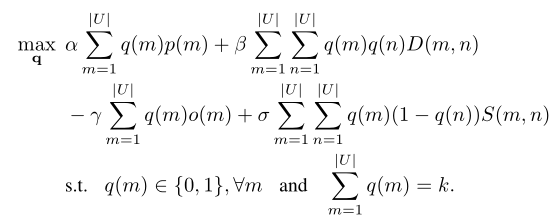

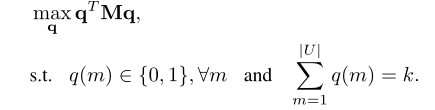

小批量物品的主动学习
如引言部分所述,在以前的主动学习作品中,每个新项目的主动学习预算都是固定的。在本文中,我们提出了一个动态的主动学习预算,以便可以有限地分配有限的主动学习资源。
我们建议将更多预算分配给具有以下两个功能的新项目。
首先,这些商品很受欢迎,这意味着许多人会愿意对它们进行评分。在主动学习阶段,由于热门项目往往会受到更多选定用户的评分,因此,如果我们要求对热门项目进行评分而不是对不受欢迎的项目进行评分,我们将获得更多的反馈评分。在预测阶段,由于热门商品还倾向于从未选择的用户那里获得更多评分,因此,更多地了解热门商品而不是不受欢迎的商品,将影响并生成针对更多评分的准确预测。这是用户是否会对项目评分的问题(标准(1)中有描述)。我们使用所有用户意愿得分的平均值来衡量它: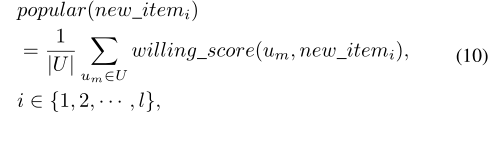
其次,这些项目是有争议的,这意味着我们不确定用户会喜欢还是不喜欢它们。对于显然将受到几乎所有用户青睐的商品,我们已经非常有信心用户会给予他们什么评价。相反,这是我们需要更多了解的有争议的项目。这是用户将对项目给予何种评分的问题(标准(2)中有描述)。我们使用潜在评分的标准偏差对其进行衡量:
每个新项目的预算得分定义为: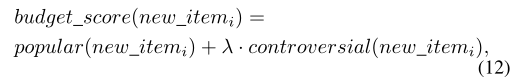
k(i)取整为整数。该等式确保了更多受欢迎和有争议的商品将获得更多预算,同时每个商品都有机会获得一些预算。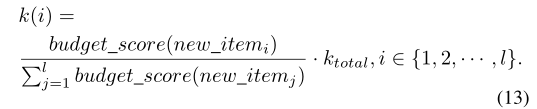
根据反馈评分进行预测
获得选定用户的反馈后,我们将使用另一个回归模型来预测未选定用户的评分。此模型中的功能不仅包含用户和项目的属性,还包含项目。这些实例包含以前的评分和新获得的反馈评分。同样,这是通过FM建模的。为了减少迭代次数并加快收敛速度,我们首先使用先前的等级对回归模型进行预训练,以获得预训练的参数。然后,当获得反馈评分时,我们将这些预先训练的参数用作初始参数,将所有先前的评分和反馈评分用作训练数据,以重新训练模型。最后,预测所有未选择用户的评分。图4显示了详细过程。首先进行预训练然后再训练的过程与贝叶斯分析[50]的想法相似。也就是说,通过对以前的项目进行预训练,我们可以了解用户对属性的偏好,并根据的属性对用户的偏好进行“事先”了解。然后,用户对的理解不一,从而使我们对的理解得到了反馈,并允许我们对用户对的偏好进行“后验”估计。
E&E问题的研究
如简介部分所述,我们的任务有两个目标,即开发(探索“现有知识”以选择愿意对新项目进行评分的用户,以便在主动学习阶段获得良好的用户体验)和探索(选择其反馈可以提供尽可能多的有关未选定用户偏好的“新知识”并为未选定用户生成准确的评分预测的用户,以便在预测阶段获得良好的用户体验)。
1)动态预算策略将更多预算分配给人们更愿意对其评分的热门商品。标准(1)鼓励更愿意为某个新项目评分的用户。因此,它们都有助于在主动学习阶段改善用户体验。 2)动态预算策略和四个标准都有助于我们了解未选择用户的偏好,并生成更准确的评分预测。因此,它们都有助于改善预测阶段的用户体验。因此,我们的方法同时考虑了这两个目标(开发和探索)。此外,我们能够调整参数设置以进一步平衡其权衡。具体而言,一旦在将所有参数分配给适当值的情况下获得了最佳的预测精度,如果我们想在主动学习阶段更加重视用户体验,我们只需要简单地增加α(标准(1)的权重) 。原因是,对标准(1)给予更大的重视会导致更高的反馈评分率。但是,增加α会破坏用于评级预测的优化参数设置,因此预测精度会降低。
六、实验评估
数据集
Movielens-IMDB:电影属性收集自http://imdbpy.sourceforge.net/,
Amazon:评分和属性分别收集自 http://jmcauley.ucsd.edu/data/amazon/links.html
和https://developer.amazon.com/
统计情况如下表: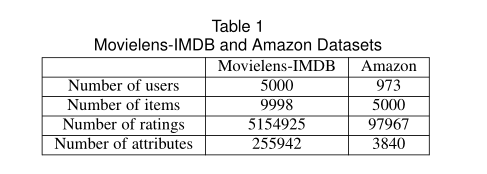
目标是对测试项目生成准确的评分预测。按照[8],[9],训练测试实验进行一次(也称为holdout51])。受[30]的启发,我们随机选择所有用户的一半作为活动选择集,其余用户组成预测集。对于所有测试项目,从主动学习阶段的主动选择集中选择用户。评分预测和评估是针对预测集中的用户执行的。
比较基准
- Hybrid-based Recommendation with Nearest Neighbor(HBRNN):该方法是基于内容的推荐和基于项目的协同过滤的组合
- Local Collective Embeddings (LCE):该方法[20]还结合了基于内容的推荐和协作过滤。与HBRNN不同,从最近邻的角度来看,HBRNN是基于混合的推荐方法。从矩阵分解的角度来看,LCE是一种基于混合的推荐方法。此外,它利用数据的多方面结构来提高性能。我们使用LCE算法的可公开获得的Matlab实现。根据[20]中的建议设置和调整参数
- Factorization Machines without Active Learning phase (FM):该方法使用分解机[41]来建模用户行为。
- Factorization Machines with Random Sampling in the Active Learning phase (FMRSAL):在此基准中,对于新项目
 ,从活动选择集中为评分请求随机选择了k个用户。由于这些用户是随机选择的,并且评分在我们的数据集中稀疏,因此反馈评分的比率预计会很低。与FM相比,性能提升可能受到限制。但是,评分请求是在不偏向任何类型的用户的情况下提供给用户的,因此在此用户选择策略中,始终没有人选择评分请求。
,从活动选择集中为评分请求随机选择了k个用户。由于这些用户是随机选择的,并且评分在我们的数据集中稀疏,因此反馈评分的比率预计会很低。与FM相比,性能提升可能受到限制。但是,评分请求是在不偏向任何类型的用户的情况下提供给用户的,因此在此用户选择策略中,始终没有人选择评分请求。 - Factorization Machines with ε-Greedy in the Active Learning phase (FM∈GAL):ε-Greedy算法来自对多臂老虎机问题的研究[33]。
- Factorization Machines with Poplar Sampling in the Active Learning phase (FMPSAL):受到[7],[28]的启发,对于新项目,选择了对训练项目评分最高的k位用户进行评分请求。由于这些用户是“经常”评分用户,因此他们也倾向于评分,这可以确保获得很高的反馈评分率。请注意,不同于我们的准则(1)(针对不同的新商品“个性化”),在此策略中选择的用户始终是相同的。
- Factorization Machines with Coverage Sampling in the Active Learning phase (FMCSAL):受到[24],[28]的启发,对于新项目,选择了与其他用户具有高度共同评价项目的k个用户进行评分请求。此策略使用的启发式方法是,用户与许多其他用户共同对同一项目进行评分,可以更好地反映其他用户的兴趣,因此,他们的评分行为对于预测其他用户的评分行为更为有用。
- Factorization Machines with Exploration Sampling in the Active Learning phase (FMESAL):受到[11],[13]中有关E&E的研究的启发,对于新项目,选择了k个用户进行评级请求,以确保选定用户代表未选定用户,同时选定用户本身具有高度多样性。
评估指标
在主动学习阶段,我们使用以下两个指标来衡量所选用户的用户体验。
percentage of feedback ratings (PFR):收到评分请求的所有用户中提供反馈评分的用户的比例。正式定义为: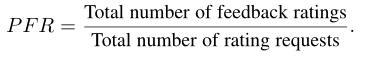
Average Selecting Times (AST):在对所有测试项目应用特定选择策略后,每个用户的平均选择时间。正式定义为: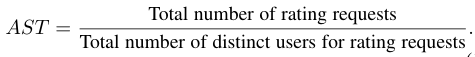
在预测阶段,使用RMSE: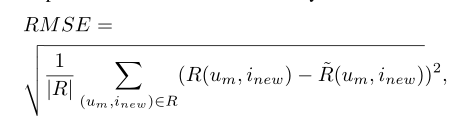
MAE: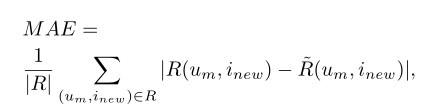
对于没有主动学习的方法,即HBRNN,LCE和FM,直接在训练项目上训练模型。对于其余的方法,给定一个新的测试项目,我们从主动学习阶段的主动选择集中选择一些用户,以查看他们是否对该测试项目具有实际评分。如果是,我们将这些实际评分视为反馈评分。在预测阶段,我们利用所有反馈评分重新训练模型。对于所有方法,均会在预测集中评估RM SE和M AE。除了评分预测之外,我们还可以模仿以下topN个推荐。首先,对于所有测试项目,我们从活动选择集中选择用户以获取反馈并预测预测集中用户的评分(对于HBRNN,LCE和FM,我们直接预测用户的评分)。其次,对于每个用户,我们选择N个(我们将N设置为10个)具有最高预测评分的测试项目(即前N个项目)作为推荐列表。最后,我们将实际评分大于3的新商品视为用户的首选商品[54]。根据推荐列表中存在的偏好物品数,它们的实际评分和排名位置来评估绩效。以下排名指标用于评估前N位推荐的效果
Precision, Recall
NDCG: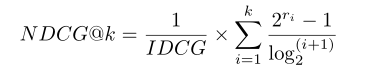
实验设置
k,α,β,γ和σ是本文的主要参数。k是用于主动学习的所选用户数。我们根据经验为每个测试项目设置k = 25,以调整其他参数。有四个参数α,β,γ和σ权衡了不同标准的重要性。实际上,它们可以乘以任意比例因子,因此恰好有三个自由参数。我们固定α=1并通过网格搜索调整其他三个自由参数。我们将RMSE用作调整指标,其中RM SE是通过对训练数据进行交叉验证来测量的(用户也分为主动选择集和预测集)。对于Movielens-IMDB数据集,最终调整后的参数为α= 1,β= 0.3,γ= 0.1,σ= 0.1。我们将使用此参数设置在所有测试项目上测得的性能视为FMFC的性能。此外,我们固定α= 1,β= 0.3,γ= 0.1,σ= 0.1,并实现FMFCDB,即我们的具有动态主动学习预算的方法。总预算ktotal(请参阅第4.2节)设置为25×l,其中l是测试项目的数量。我们将此设置下测得的性能视为FMFC-DB的性能。对于其他主动学习基准,在每次测试物品中所选用户数等于25的情况下衡量性能。实验结果
所有性能均在测试集上进行衡量。如表2和表3所示。
就RMSE和MAE而言,我们的方法(FMFC和FMFC-DB)优于其他基线,这表明我们的方法在预测阶段具有最高的预测准确性。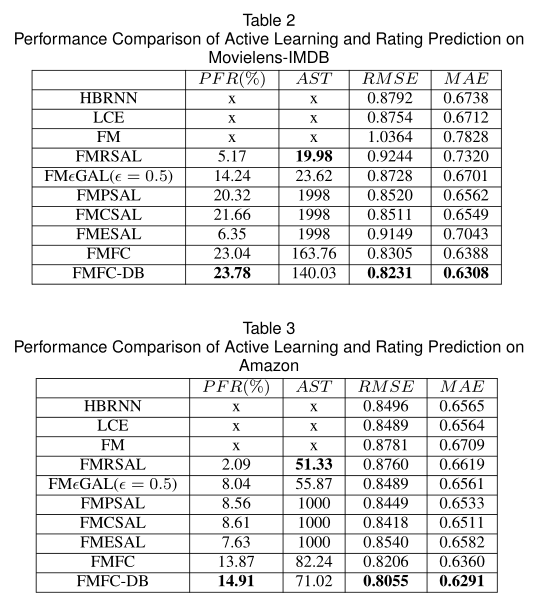
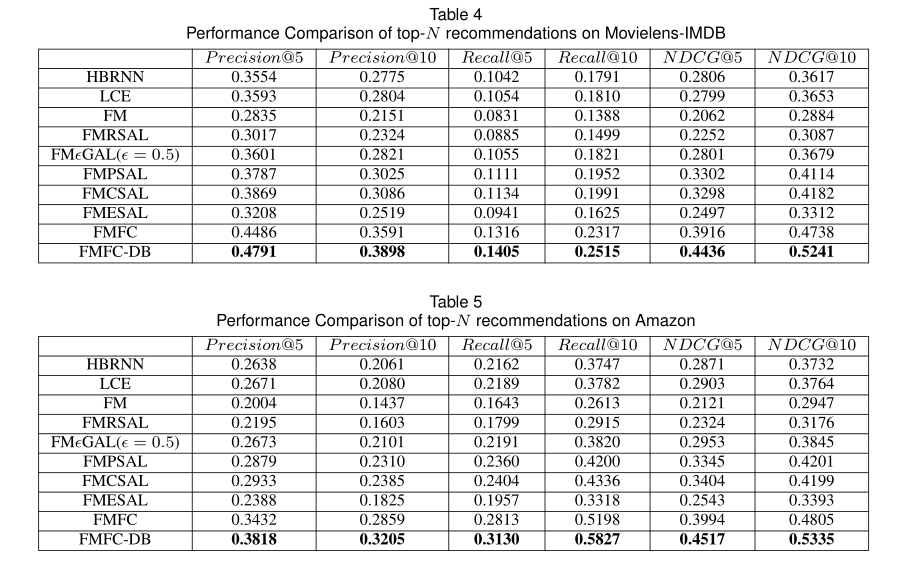
根据表4和表5,作者的方法在前N个推荐任务中也表现最佳。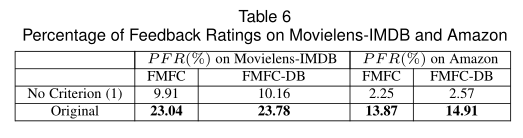
我们删除了FMFC和FMFC-DB中的准则(1),以查看PFR的变化。结果显示在表6中。在没有条件(1)的情况下,对于FMFC和FMFC-DB,PFR都急剧下降。由于较高的PFR意味着更多的选定用户对新物品进行评分,因此该结果验证了Criterion(1)的有效性。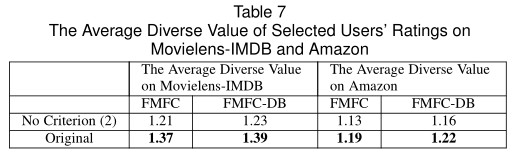
选择具有不同潜在评分的用户的目的是确保这些用户的实际评分也趋于多样化,以使最终预测模型不会偏向固定的评分范围。我们删除了FMFC和FMFC-DB中的条件(2),以查看所选用户的实际评分的平均多样性值(在等式(3)中定义)如何变化。如表7所示,在没有条件(2)的情况下,FMFC和FMFC-DB的平均多样性值均降低。结果验证了准则(2)的有效性。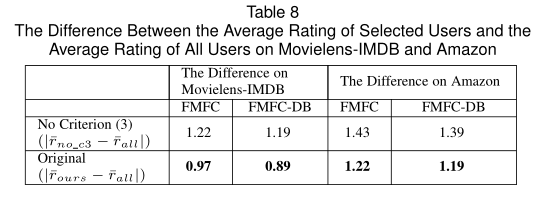
Criterion(3)的见解是让通过我们的方法选择的用户的平均评分近似于所有用户的平均评分。表8结果表明Criterion(3)实际上可以使选定用户的平均评分接近于所有用户的平均评分。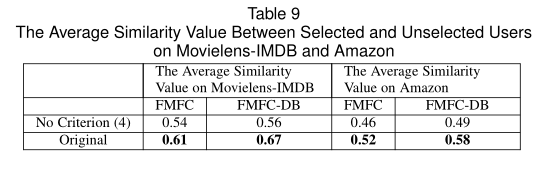
标准(4)的见解是让选定用户类似于未选定用户。我们使用/不使用条件(4)来衡量选定和未选定用户之间的平均相似度值,以验证该标准。结果显示在表9中。我们可以看到,如果没有条件(4),则平均相似度值会下降,这表明条件(4)实际上可以使选定用户与未选定用户更加相似。我们进一步验证了每个标准对最终预测性能的贡献。结果如图5所示。当我们删除每个标准时,RM SE会增加,这表明每个标准都有助于预测的改进。当我们删除准则(1)时,RMSE增幅最大,这表明该准则是影响预测改进的领域因素。 k是所选用户数。当k增加时,RMSE减小。这很容易理解,因为较大的k会导致更多的反馈等级,这将使我们对新项目有更多的了解,从而生成更准确的预测。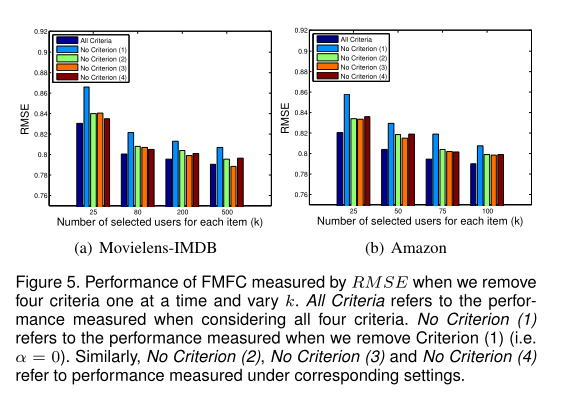
如第4.2节所述,我们使用动态预算策略来正确分配有限的主动学习资源。如图6所示,对于总预算的不同值,动态预算都有助于提高RMSE和PFR的绩效。当总预算增加时,这种改进就会变窄。这是因为提出了动态预算来解决活动学习资源有限的问题。当总预算足够时,此策略将提供较少的帮助。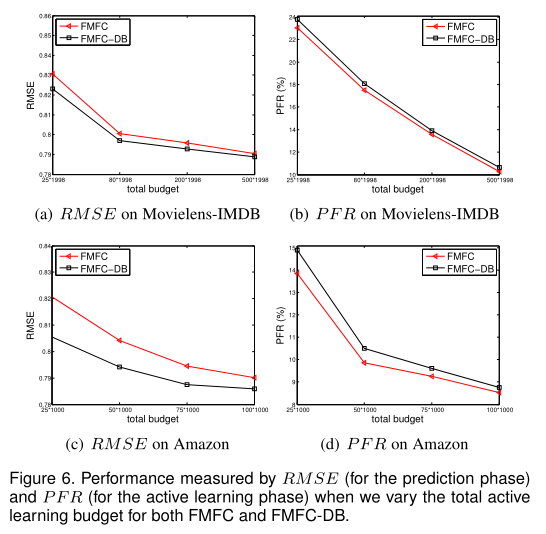
表2和表3中的结果表明,我们的方法在开发(主动学习阶段中的PFR高)和探索(预测阶段中的RMSE和MAE较低)方面都可以实现高性能。现在我们分析α(即标准(1)的权重)如何进一步平衡其权衡取舍。我们改变了α,但修复了其他调整后的参数以了解性能如何变化。如图7所示。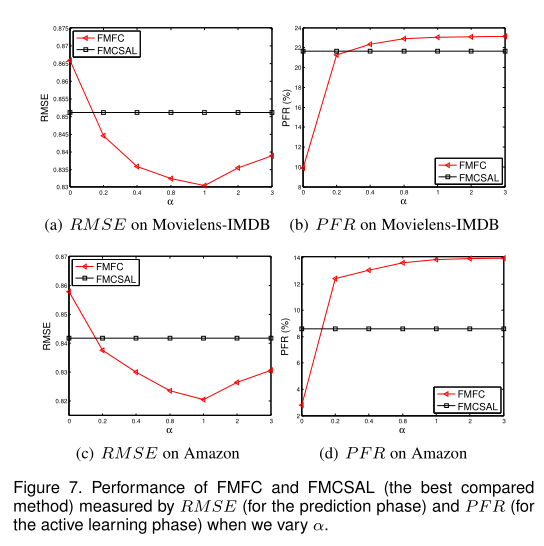
八、其他
总结
本文通过主动学习和物品属性信息,为物品冷启动问题提出了一种新颖的推荐方案。首先,我们会使用用户的历史评分和商品属性预先训练评分预测模型。其次,给定一个新项目,根据四个有用的标准选择一小部分用户对该项目进行评分。第三,通过添加反馈评分来重新训练预测模型。最后,通过重新训练的模型可以预测未选择的用户的评分。我们进一步提出了动态的主动学习预算,以适当地分配主动学习资源,这有助于提高推荐效果。动态主动学习预算的思想也可以应用于其他主动学习相关任务。我们的方法能够为处于活跃学习阶段的选定用户和处于预测阶段的未选定用户确保相对良好的用户体验。在以后的工作中,我们将探索更多其他标准来改善我们的用户选择策略。另外,本文使用的libFM是回归模型,适用于评级预测任务。我们将尝试使用排名模型扩展我们的方法,以更好地解决前N个推荐任务。

若有收获,就点个赞吧
0 人点赞
