发表在 IJCAI 2019的一篇论文,本文提出一种结合商品行为和内容信息的半参表示算法 Semi-Parametric Embedding(SPE), 旨在结合behavior-based CF 和 content-based 算法,以更好地缓解 item-item推荐的冷启动问题。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | SPE |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Semi-Parametric Embedding; behavior based; content based; item-item |
| 4 | 核心内容 | item冷启动问题 |
| 5 | 论文PDF | 2019IJCAI-Hybrid Item-Item Recommendation via Semi-Parametric Embedding.pdf |
| 6 | GitHub源码 |
二、研究动机
现代化推荐系统在多个领域内都有着积极影响,例如:电子商务、新闻报道、社交网络和数字娱乐等。在这些推荐系统中,item-item(I2I)解决的是针对给定商品 (trigger item),推荐一系列相关商品 (rec_items) 的问题。处理给定项目来推荐相关项目是基本主题之一。这是因为,一方面,I2I本身具有直接的应用程序场景,例如在电子商务平台上“猜您喜欢”、“为你推荐”;另一方面,系统可以向用户推荐与单击过的项目相似的项目,I2I 是 feeds 瀑布流等用户推荐场景的基础。
Behavior-based 的 I2I 矩阵计算通常基于商品之间以往的共同行为 (例如商品被同一个用户浏览点击过), 它在行为充分的商品上通常有较好的推荐效果。然而对很多新品较多的场景和应用上,例如优酷新视频发现场景和闲鱼这种二手电商社区,由于没有历史行为累计,商品的冷启动问题异常严重,behavior-based 算法在这些商品上的效果较差。
冷启动一直以来都是推荐系统重要的挑战之一, 常见的 content-based 方法是引入商品的内容信息,利用商品之间的文本、描述、类目等内容信息进行 I2I 相似度矩阵的计算。然而 content-based 方法涉及到商品的特征工程和相似性度量的选择,需要有相应的领域知识,另外由于非专业卖家、内容作者的积极性和专业能力不够,商品的特征信息也不够丰富甚至有误,content-based 方法的效果差强人意,且content-based的方法在有很多行为信息的场景下并不优于behavior-based CF。
为了解决冷启动问题,可以采用混合方法,结合behavior-based and conten-based,一般来说,这些方法将辅助内容信息集成到CF中,以学习有效的隐因子。尤其是,随着近年来开发的基于深度学习的嵌入方法,为每个项目提供有效的表示要容易得多。但是,现有的混合方法要么推断项目的隐变量,要么直接使用带有上下文信息的协同过滤的深化版本。很少有人尝试开发有效地平衡行为和内容信息的有效项目表示。
因此,本文提出结合商品行为和内容信息的半参表示算法 SPE (Semi-Parametric Embedding),同时学习并平衡这两个部分,以缓解 I2I 推荐中的冷启动问题。
三、评价指标
Hit Rate(HR): In-matrix HR@10, Out-of-matrix HR@10
nDCG: In-matrix NDCG@10, Out-of-matrix NDCG@10
矩阵内预测是针对在训练数据中至少观察到一次的项目进行推荐,而矩阵外预测针对在训练数据中从未观察到的冷启动项目进行推荐。
四、传统方法/相关工作
基于内容的方法利用项目的内容信息进行推荐,从而摆脱了冷启动问题。但是,设计和收集强大的上下文信息功能以获得良好的效果通常很昂贵,而且不切实际。另一方面,基于CF的方法通常会提供更令人印象深刻的推荐结果,尤其是对于行为丰富的项目,但由于对项目交互的强烈依赖,它们的性能在出现冷启动问题时会迅速下降。
因此,近年来,混合方法越来越流行,该方法将上下文与行为信息相集成以解决这些问题。混合方法可以进一步分为两类:松散耦合方法和紧密耦合方法。松散耦合方法[Melville et al。,2002; Sevil等人,2010年]利用辅助信息为CF提供特征,但评分信息无法指导特征学习。相反,紧密耦合的方法[Wang and Blei,2011; Wang et al。,2015]提供了它们之间的双向交互,并且通常优于松散耦合的交互。但是,这些现有的混合方法通常无效,特别是当评分矩阵和辅助信息非常稀疏时[Agarwal等,2011]。
最近,深度学习可能是学习有效表征的最有效方法[Hinton and Salakhutdinov,2006; Hinton等,2006]。因此,一些研究利用深度学习来获得推荐系统的有力表示,并且胜过传统系统。 [Salakhutdinov et al。,2007]使用受限玻尔兹曼机(RBM)进行协同过滤。 [Van den Oord et al。,2013]和[Wang and Wang,2014]是基于内容的方法,它们直接使用卷积神经网络(CNN)或深度置信网络(DBN)来获取内容信息的隐因子。 [Wang et al。,2015]将深度学习与混合方法相结合,提出了一种贝叶斯深度学习堆叠式降噪自动编码器(sDAE)模型,以将内容信息和评分(反馈)矩阵耦合在一起。 [Dong等人,2017]将sDAE开发为一种新的深度学习模型附加SDAE(aSDAE),并将辅助信息整合到潜在因素中以进行推荐。它们中的大多数只是通过混合内容和评分矩阵来提取深层特征表示,以同时捕获项目之间的相似性和隐式关系。从冷启动到行为丰富的项目,很少有人尝试平衡不同项目的上下文和行为信息。
五、主要思想
半参向量表示(SPE)
与CF-based的矩阵分解算法中使用行为信息建模商品向量的做法不同, 本文同时使用行为和内容信息来建模商品表示, 也即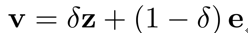
其中,  为商品的向量表示;
为商品的向量表示;  为商品的行为信息表示部分, 每个商品的行为表示各自不同;
为商品的行为信息表示部分, 每个商品的行为表示各自不同;  为内容信息表示部分, 通过特征输入
为内容信息表示部分, 通过特征输入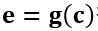 得到,
得到,  为商品的内容输入向量(商品的文本、描述、类目等);
为商品的内容输入向量(商品的文本、描述、类目等);  为两者之间平衡因子, 由当前item上的历史统计信息(商品曝光、点击次数等)决定。若当前item行为丰富, 较大, 最终的向量由 主导; 而新品 item 行为信息少, 较小,模型对行为信息的权重加大。
为两者之间平衡因子, 由当前item上的历史统计信息(商品曝光、点击次数等)决定。若当前item行为丰富, 较大, 最终的向量由 主导; 而新品 item 行为信息少, 较小,模型对行为信息的权重加大。
行为向量 和内容向量 分别为模型中非参数化向量和参数化向量, 结合两者,作者将其称作半参向量表示。
SPE 用于I2I 推荐
基于商品的向量表示, 定义相似性度量为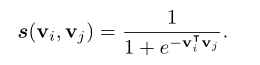
最小化目标函数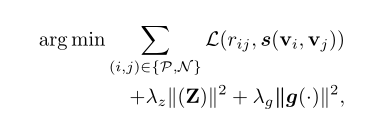
由于非专业卖家、非专业作者的积极性和专业能力不够, item 的内容特征信息不够丰富甚至缺失、错误。本文针对参数化向量表示,引入了深度学习中的多层降噪自动编码机(stacked denoise autoencoder, sDAE), 以学习更鲁棒的内容向量表示。则目标函数更新为: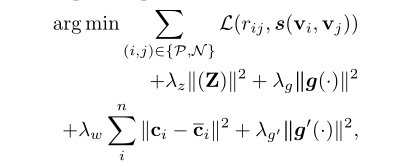
其中,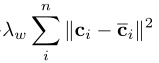 为内容特征的重构损失。
为内容特征的重构损失。
六、实验评估
数据集
Amazon
Yelp
Alibaba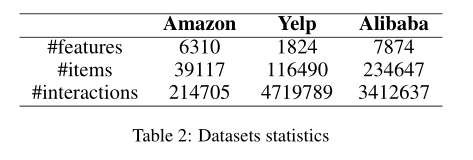
Baseline

baseline
- Content-KNN:内容K最近邻居是一种经典的基于内容的方法。对于一对项目,它们的关系通常仅通过其上下文边信息之间的距离度量来度量。在我们的实验中选择余弦相似度。
- NeuMF:神经矩阵分解[He et al。,2017]是一种流行的基于协作过滤的方法。 NeuMF将广义矩阵分解模型与深度学习相结合,以探索行为信息。
- CDL:协同深度学习[Wang等,2015]是最新的混合模型之一。它可以共同学习项目和模型交互的深层特征表示。我们做了一些小的修改,并在I2I建议中为用户端应用了堆叠式去噪自动编码器(sDAE)。
如果没有提及,所有比较的实现都采用其各自文献报道的形式。在比较不同模型的性能时,为了公平起见,将常见的超参数(如嵌入维数k和负采样率r)设置为相同的值(如果未指定,则将k设置为16,将正/负采样率设置默认为1:3)。
实验结果
在实验部分,分别将半参向量表示框架与 cf-based, content-based, hybrid 方法进行了比较, 选取的指标为 in-matrix(item 在训练集中出现过)和 out-of-matrix(item在训练集中未出现过)数据集上的HitRatio@10 和 NDCG@10。详细结果如下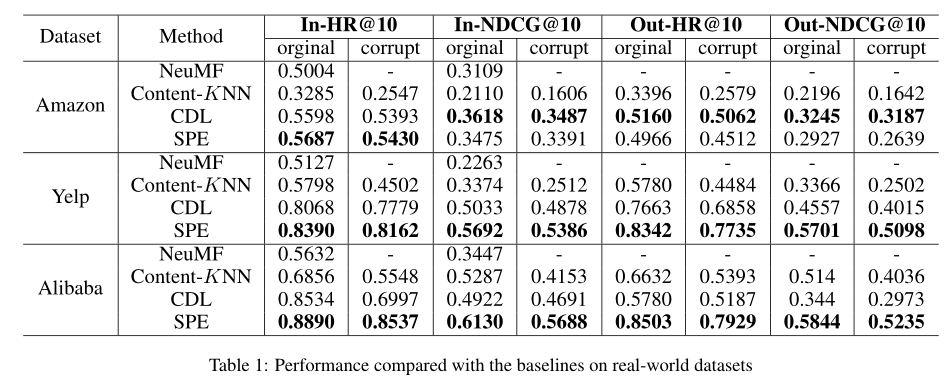
在Amazon的out-of-metrix上SPE比CDL稍差,原因可能是SPE用了比较简单的MLP导致无法更好地概括高维context特征。而CDL中用了SDAE效果更好。
SPE模型如何平衡冷启动和行为丰富项目的参数和非参数嵌入。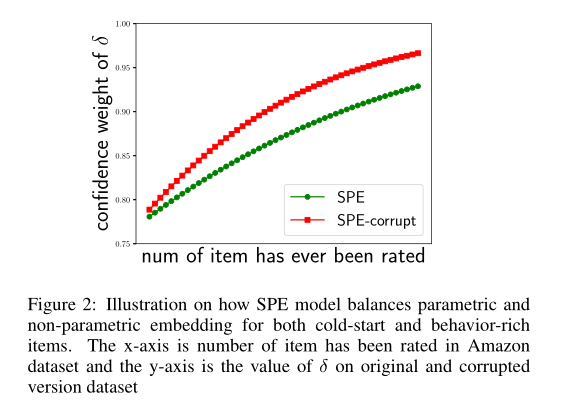
此外,实验中对 SPE 和SPE-sDAE的鲁棒性进行了对比, 论文通过对Amazon数据集中的内容特征进行随机扰动(非零值以corrupt-ratio的概率进行置零)得到不同版本的噪音数据集。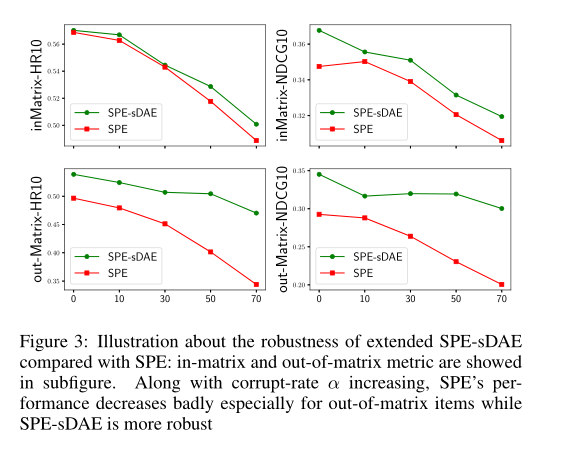
由图可知,随着扰动比率的增大,两者的指标都在下跌,但是SPE-sDAE比SPE更鲁棒,特别是在out-of-matrix的数据集上的优势更明显。
七、总结
本文提出了一种半参表示框架, 它结合商品的行为信息和内容信息,以达到在维持行为丰富 item 上表现的同时,缓解新商品上的冷启动问题。另外本文引入 sDAE 来帮助学习更强力的内容表示,以达到更鲁棒的效果。3 个真实数据集、3类对比推荐算法、4 种评价指标上的对比实验,验证了该算法的可靠性和鲁棒性。

若有收获,就点个赞吧
0 人点赞
