核心概念
索引(Index)
一个索引就是拥有相似特征的文档集合。例如,客户数据索引、产品目录索引、订单索引。一个索引由一个名字来标识(必须全部是小写字母)。在集群中科院定义任意多的索引。
ES索引的精髓:一切设计都是为了提高搜索的性能
类型(Type)
文档(Document)
一个文档是一个可被索引的基础单元,也就是一条数据。比如某一个客户的文档。文档以JSON(Javascript Object Notation)格式表示。
在一个index/type里,可以存储任意多的文档
字段(Field)
映射(Mapping)
mapping是处理数据的方式和规则方面做出一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等。这些都是映射里可以设置的,其它就是处理ES数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大。
分片(Shards)
一个索引可以存储超过单个节点限制的大量数据。比如,需要1TB的磁盘空间存放文档数据,但任一节点都没有这么大的空间。或单个节点处理搜索请求太慢,为解决这些问题,ES提供将索引划分为多份的能力。当你创建一个索引,你可以指定想要分片的数量。每个分片本身也是一个功能完善的独立索引,这个“索引”可以被放置到集群中的任何节点上。
- 允许水平分割/扩展内容容量
-
副本(Replicas)
在网络环境中,失败随时可能发生。ES允许创建分片的一份或多份拷贝(副本)
提高了可用性。副本与 源/主要(original/primiary)分片 不置于同一个节点
- 扩展吞吐量,搜索可以在所有副本上并行运行
分配(Allocation)
将分片分给某个节点的过程,包括分配主分片或副本。如果是副本,还包括从主分片复制数据的过程。这个过程是由master节点完成的。系统架构
一个运行中的 Elasticsearch 实例称为一个节点, 而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者 从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、 删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操 作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节 点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道 任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论 我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将 最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。分布式集群
单节点集群
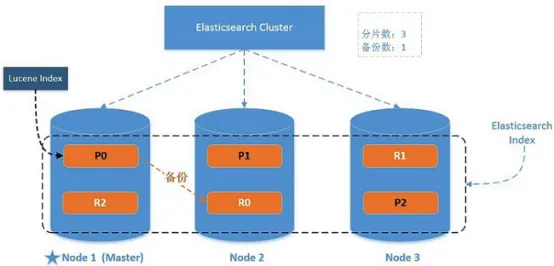
我们在包含一个空节点的集群内创建名为 users 的索引,例如分配 3 个主分片和一份副本(每个主分片拥有一个副本分片)PUT``http://localhost:9200/users{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}
默认情况下,分片1,副本数1
我们现在拥有了一个索引的单节点集群。所有的三个主分片都在node-1上
可以通过elasticsearch-head插件查看使用情况。此时健康状况为yellow3/6 表示三个主分片正常运行,但是副本没有在正常状态Unassigned,他们都没有被分配到任何节点

若有收获,就点个赞吧
0 人点赞
