源码
- 初始化容量10,装载因子0.75
- 树化最小8,回链最小6
- 树要求最小64,不够先扩容再树化
- 扩容new = old <<1
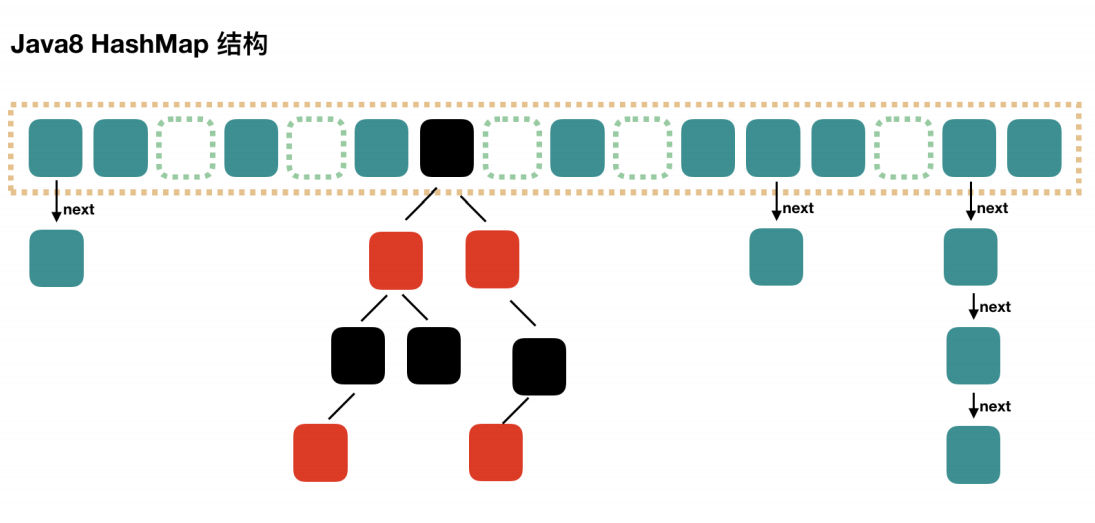
- 数据结构Node数组+链表[寻址复杂度O(N)]/红黑树[O(log(N))]
-
为什么大小是2的次方?
减少碰撞,hash设计的很大ash 值的范围值-2147483648 到 2147483647共有40亿空间,内存不能存,需要先取余。
取余是hash % length,其中! 取余(%)操作中如果除数是 2 的幂次 则等价于与其除数减⼀的与(&)操作并且位运算效率高(博客测试大约四倍),为了让位运算(n-1) & hash等于取余的值,只有length是2的次方,hash % length == (n-1)&hash
为什么能减少碰撞
2的n次方的二进制是1后面全是0,所以n次方-1就是n个1。
-
多线程操作导致的死循环
主要是rehash会造成元素间形成循环链表,JDK1.8已经解决。
hash函数
扩展
线程不安全,线程安全的是
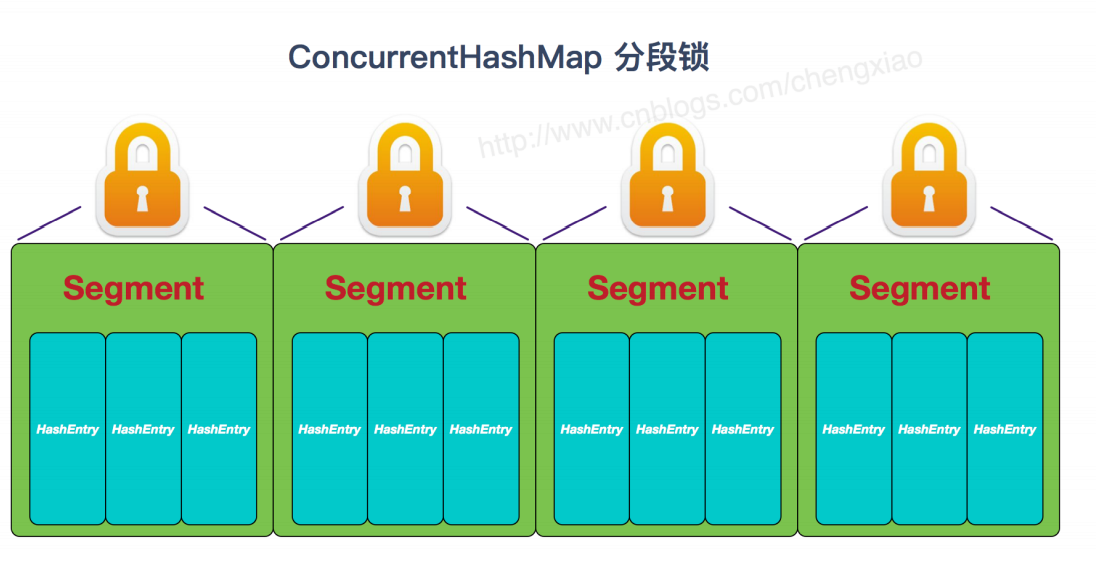
hashtable(已经不推荐)和ConcurrentHashMap底层实现
步骤
- 扩容:新建空数组,2倍大小
- rehash:遍历原数组,重新hash到新数组。
- 为什么要ReHash?
- index = HashCode(Key) & (Length - 1)下标获取与长度有关,需重新计算下标
- 非线程安全
- 7头插法,重新hash到新数组存储顺序相反,并发发生死锁。
- 8尾插法解决。8数值覆盖问题。
- map填满0.75(默认负载因子)的bucket(桶)的时候,扩容,左移1,2倍。
创建原来大小2倍的bucket数组,重新调整map大小,然后遍历原数组,将原来的对象放入新的bucket数组。
存值流程
JDK 1.8 HashMap存值流程
什么时候红黑树? 为什么红黑树?
文字梳理


开始
1.判断位桶数组table是否为空 transient Node
1.1 如果为空,则进行第一次的扩容 ,分配默认值 数组初始容量 1 << 4 =16,同时设置扩容阀值 160.75
2.利用put的key值计算hash得出插入table的索引位置
2.1判断当前的 table[索引值] 是否为null,若为空,进入3步骤
2.2 如果不为空,那么需要判断是否key值已存在
2.2.1 存在 ,直接覆盖
2.2.2 不存在,进入2.3
2.3判断当前table[索引值]下是否为链表/红黑树
2.3.1 如果是链表,开始遍历链表进行插入,
插入前计算插入后链表长度是否达到8,如果大于则转换为红黑树结构,进行key & value的插入。
如果链表长度没有达到8,那么插入时查找是否已经存在key,存在则覆盖value值;不存在则进行key & value的插入。
2.3.2 如果是红黑树,那么进行key & value的插入(存在覆盖value)
3.直接创建出新的节点,进行key & value 值插入 tab[i] = newNode(hash, key, value, null);
4.判断当前容量是否已经超越了hashmap的扩容阈值(初始容量 16 加载因子 0.75) if (++size > threshold)
结束
- 流程图

- HashMap为什么线程不安全(扩容多线程可能导致链表形成环,然后调用get方法死循环)
- CurrentHashMap为什么线程安全(分段锁)
- 哪些方法需要锁整个集合(求size的时候)

若有收获,就点个赞吧
0 人点赞
