187. 重复的DNA序列
这一题是字符串hash的入门题
朴素做法,暴力遍历以及hash表存储,主要思路就是通过一个hashMap不断地存储以s[i]结尾的长度为10的子序列,如果出现次数大于一的话,就将其添加进入一个List。
为了防止相同的子串被重复添加到答案,而又不使用常数较大的 Set 结构。我们可以规定:当且仅当该子串在之前出现过一次(加上本次,当前出现次数为两次)时,将子串加入答案。DSgRsxfy
class Solution {public List<String> findRepeatedDnaSequences(String s) {List<String> ans = new ArrayList<>();int n = s.length();Map<String, Integer> map = new HashMap<>();for (int i = 0; i + 10 <= n; i++) {String cur = s.substring(i, i + 10);int cnt = map.getOrDefault(cur, 0);// 只有第二次出现的时候才将其放入ansif (cnt == 1) ans.add(cur);map.put(cur, cnt + 1);}return ans;}}
接下来就是字符串hash的做法,直接贴三叶的题解:
这一题的做法首先是理解次方数组,我们根据代码来看:
class Solution {int N = (int)1e5+10, P = 131313;// h是对于每一个字符的特殊的值,p是一个幂次数组int[] h = new int[N], p = new int[N];public List<String> findRepeatedDnaSequences(String s) {int n = s.length();List<String> ans = new ArrayList<>();p[0] = 1;for (int i = 1; i <= n; i++) {h[i] = h[i - 1] * P + s.charAt(i - 1);// 初始化为1,可以简单的推断出实际上是一个P的幂次数组p[i] = p[i - 1] * P;}Map<Integer, Integer> map = new HashMap<>();for (int i = 1; i + 10 - 1 <= n; i++) {int j = i + 10 - 1;// 下一个注意点,这里求得的是一段字符的hash。int hash = h[j] - h[i - 1] * p[j - i + 1];int cnt = map.getOrDefault(hash, 0);if (cnt == 1) ans.add(s.substring(i - 1, i + 10 - 1));map.put(hash, cnt + 1);}return ans;}}
这一题整个思路很像一个hash算法,对于一个三叶测出来的值P=131313(这个值的特征就是质数),我们计算字符的hash值,使用的是平方偏移的思路,因为这个值会很大,就会出现溢出,到变成负数:
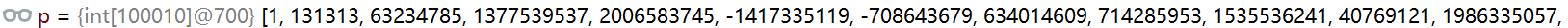
计算方法为,对于位置为i的字符来说,其hash编码为P的i次方加上其字符的int值(i为0则为P^0 = 1),此时通过一个记录P次幂的数组记录每一个位置的次幂。
另一个关键的地方就是字符串的hash的计算:
对于一个[i-1..j]的字符串字串,其hash计算为h[j] - h[i - 1] * p[j - i + 1]即末尾的j字符的hash值减去起点i的hash值乘以其幂次。
在P比较大的时候可以防止冲突。
到这里字符串hash已经比较清晰了,学习三叶的小迷妹写rust方法:
use std::collections::HashSet;
impl Solution {
// 学习一下字符串滚动哈希
// 哈希方法
// 因为题目中给出的目标字符串长度固定为10, 而构成元素只有4个: ACGT
// 我们可以用2个bit位来表示ACGT: 00 -> A, 01 -> C, 10 -> G, 11 -> T
// 然后合计20个bit来表示字符串, 可以保证不会发生冲突(是个双射), 并且可以放在一个 4字节 的 int 中
pub fn find_repeated_dna_sequences(s: String) -> Vec<String> {
if s.len() <= 10 {
// 如果原始字符串长度小于等于10, 不会存在重复字符串, 直接返回
return vec![];
}
// str_hs 存储了当前已有的字符串hash值
let mut str_hs = HashSet::with_capacity(s.len());
let s_b = s.as_bytes();
// 首先使用前9个字符初始化一下hash结果
let mut cur_hash = (0..9).fold(0, |h, i| (h << 2) | Solution::ch_2_num(s_b[i]));
let mut ans = HashSet::new();
(9..s.len()).for_each(|i| {
cur_hash = ((cur_hash << 2) | Solution::ch_2_num(s_b[i])) & 0xfffff; // 0xfffff作为掩码, 只取20位
match str_hs.contains(&cur_hash) {
true => ans.insert(s[i-9..=i].to_string()),
_ => str_hs.insert(cur_hash),
}
});
ans.drain().collect::<Vec<String>>()
}
// 辅助函数: 字符映射数字
fn ch_2_num(ch: u8) -> i32 {
match ch {
b'A' => 0,
b'C' => 1,
b'G' => 2,
_ => 3,
}
}
}
1044. 最长重复子串
直接用字符串hash既可:
class Solution {
long[] h, p;
public String longestDupSubstring(String s) {
int P = 1313131, n = s.length();
h = new long[n + 10]; p = new long[n + 10];
p[0] = 1;
for (int i = 0; i < n; i++) {
p[i + 1] = p[i] * P;
h[i + 1] = h[i] * P + s.charAt(i);
}
String ans = "";
int l = 0, r = n;
while (l < r) {
// 右二分,r=mid-1
int mid = l + r + 1 >> 1;
String t = check(s, mid);
// 如果找到的匹配字符串的长度不为0,那么找更长的
// 类似于target>=mid
if (t.length() != 0) l = mid;
else r = mid - 1;
ans = t.length() > ans.length() ? t : ans;
}
return ans;
}
String check(String s, int len) {
int n = s.length();
Set<Long> set = new HashSet<>();
for (int i = 1; i + len - 1 <= n; i++) {
int j = i + len - 1;
long cur = h[j] - h[i - 1] * p[j - i + 1];
if (set.contains(cur)) return s.substring(i - 1, j);
set.add(cur);
}
return "";
}
}

若有收获,就点个赞吧
0 人点赞
